新零售供应链,尝试使用GaussDB链接场与货【华为云GaussDB:与数据库同行的日子】

新零售供应链的关键:场与货的链接
零售是整个供应链中的最后一环,也是十分关键的一环。
商品的供应链是一个包含多个步骤的完整链路,从商品的设想到销售,基本上可以归纳为设计→制造→供应链→商家→消费者。如图1-1:
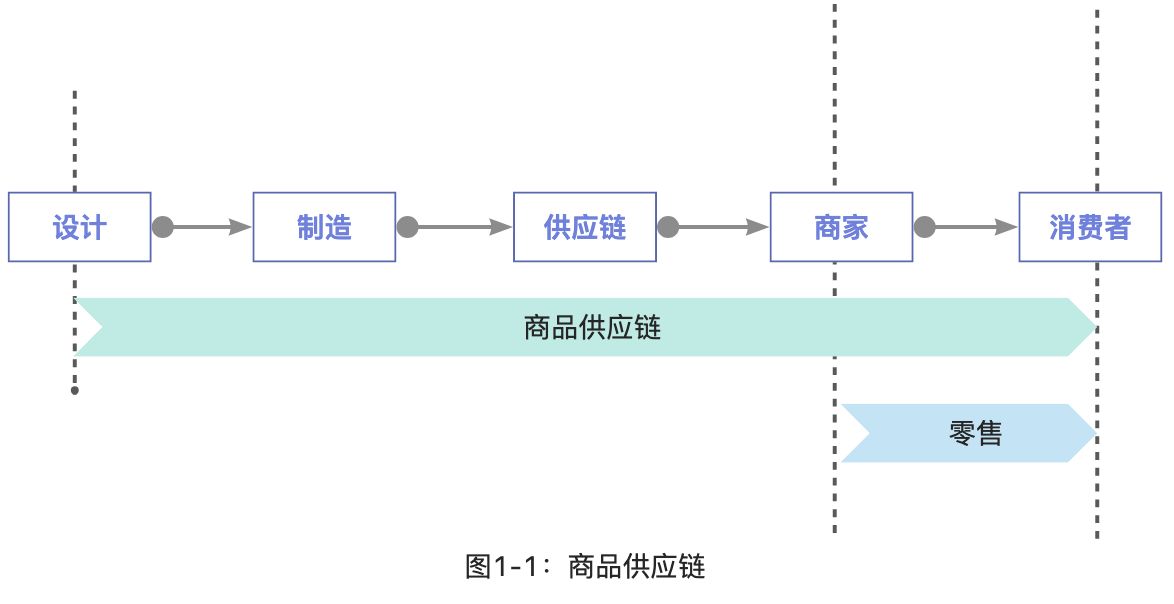
在这个完整链路中,有很多需要关注的地方。
比如,商品制造出来,正在到消费者手中,可以有不同的路径。商家可以大型的商超,也可以是地摊形式的小商贩。某天,你下班的路上,便可以随手购买一束鲜花;也可以在休息日,专门去花店购买一捧精心包装的花束;甚至可以在线上鲜花店铺,订购鲜花,可能不用出门,隔天鲜花就送到了你的手上。
在比如,商场进购货物,可以找经销商进货;也可以反过来,经销商找商场租柜台卖货物。
无论何种形式,商品想要到达消费者的手中,都需要经过“零售”的场。
新零售的“场”
零售作为链路的末端,势必要经过“场”,而新零售中“场”也不再是传统中所见的实体或地摊,互联网技术的支持逐渐成为一种新的常见的“场”。
线上商场,可以缩短消费者到“场”的距离,也可以缩短人到货的距离,不但可以很方便的找到自己需要的商品,同时可以查看到商品的各种信息,比如是否有存货、是否有促销活动、商品评价等等。
我为何钟意GaussDB
在说明“我为何钟意GaussDB”之前,先来简单介绍一下我们目前的业务场景。
场与货
链接场与货的基础是数据,主要为商场的货物信息。
每日的商场货物信息是实时更新的,所以有一套业务数据的维护规则。这是一个较为复杂的工程,我们今天只探讨部分功能:按照日期生成业务数据。
生成业务数据
我们的业务数据的建库、建表以及数据生成,主要是通过导入脚本完成的。具体步骤如下:
- 步骤1:创建数据库good。
- 步骤2:生成业务数据
首先修改我们application.properties的相关配置,通过修改业务日期的配置进而生成不同日期的业务数据。
#业务日期
mock.creat-at=2023-12-19
#是否重置
mock.clear=1
#生成商品个数
mock.good.count=500
#生成商品的大类数量
mock.good.large-category-type=20
#生成商品的中类数量
mock.good.middle-category-type=48
#生成商品的小类数量
mock.good.small-category-type=200
#是否有促销活动
mock.activity.promo-flag=1
#每件商品最多可购数量
mock.cart.good-max-count=99
#今日发放优惠券数量
mock.order.coupon-count=5执行以下命令生成2023-12-19的数据:
java -jar good-mock-db-SNAPSHOT.jar以上是业务数据生成的局部功能,实际的操作会更复杂,数据量会更加庞大。我需要更加稳定的技术能力。
分治法
为了满足在数据查询、数据管理方面等方面的高要求,我们一直在寻找更佳方案。
在计算机科学中,有一种很重要的算法叫做“分治法”。它的实现原理是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
于是乎,采用“将庞大的数据整体进行了切分”的方式,十分利于数据的管理、查找和维护。
GaussDB的“分区表”特性,正是在“分治法”的基础上,提供了更高效的数据运维管理方式。
GaussDB的大容量数据库
表分区技术
华为云的官网,详细介绍了表分区技术最主要的三个方面的能力:
- 提升大容量数据场景查询效率:由于表内数据按照分区键进行逻辑分区,查询结果可以通过访问分区的子集而不是整个表来实现。这种分区剪枝技术可以提供数量级的性能增益。
- 降低运维与查询的并发操作影响:降低DML语句、DDL语句并发场景的相互影响,在对一些大数据量以时间维度进行分区的场景下会明显受益。例如,新数据分区进行入库、实时点查操作,老数据分区进行数据清洗、分区合并等运维性质操作。
- 提供大容量场景下灵活的数据运维管理方式:由于分区表从物理上对不同分区的数据做了表文件层面的隔离,每个分区可以具有单独的物理属性,如启用或禁用压缩、物理存储设置和表空间。同时它支持数据管理操作,如数据加载、索引创建和重建,以及分区级别的备份和恢复,而不是对整个表进行操作,从而减少了操作时间。
分区策略之范围分区
GaussDB的分区策略主要有:范围分区、哈希分区、列表分区。
其中范围分区是根据为每个分区建立的分区键的值范围将数据映射到分区。通常在以时间维度(Date、Time Stamp)描述数据场景中使用。也正好符合我们的业务场景需要。
范围分区有两种语法格式:VALUES LESS THAN的语法格式和START END语法格式。其中VALUES LESS THAN的语法格式,范围分区策略的分区键最多支持16列。
来看一个我们单列分区键示例:
CREATE TABLE range_sales
(
good_id INT4 NOT NULL,
large_categor_type INT4,
middle_categor_type INT4,
small_categor_type INT4,
creat_at DATE,
good_max_count INT4,
good_count INT4,
order_coupon_count INT4
)
PARTITION BY RANGE (time)
(
PARTITION date_202301 VALUES LESS THAN ('2023-01-01'),
PARTITION date_202302 VALUES LESS THAN ('2023-02-01'),
…
PARTITION date_202311 VALUES LESS THAN ('2023-11-01'),
PARTITION date_202312 VALUES LESS THAN ('2023-12-01'),
);其中date_202301表示2023年1月的分区,将包含分区键值从2023年1月1日到2020年1月31日的数据。
其他功能
除了分区策略,GaussDB的分区表特性还提供了其他优秀功能。
1、分区表查询优化
包括分区剪枝和分区索引。
分区表静态剪枝,可在优化器阶段将对indexscan、bitmap indexscan、indexonlyscan等算子中包含的检索条件作为剪枝条件,完成分区的筛选。
2、分区表相关内置工具函数
包括前置建表相关信息和工具函数。节省了开发者的工作量。
3、分区表运维管理
包括新增分区、删除分区、交换分区、清空分区、分割分区、合并分区、移动分区、重命名分区、分区表行迁移、分区表索引重建/不可用等功能,基本上包含了所有可进行操,十分齐全详尽。
总结
对于数据库的容量庞大、数据多样化的场景,GaussDB给予了很好的支持。
通过分区表对分区键进行谓词查询的方式,对数据查找方面的提供了极大的帮助;此外数据生命周期管理(DLM)提供了灵活性的支持,基本上完成了确定在数据生命周期的任何时间点存储数据的最合适和最经济高效的介质,最大限度在确保易用性的同时,实现了有效的数据生命周期的成本优化。
以上特点,十分贴合我们新零售供应链中,对于场与货链接中,大容量数据库需要的业务场景。
未来我会继续摸索华为云GaussDB的功能。
作者:非职业「传道授业解惑」的开发者叶一一
简介:「趣学前端」、「CSS畅想」系列作者,华夏美食、国漫、古风重度爱好者,刑侦、无限流小说初级玩家。
如果看完文章有所收获,欢迎点赞👍 | 收藏⭐️ | 留言📝。
我正在参加【有奖征文 第28期】华为云GaussDB:与数据库同行的日子!
https://bbs.huaweicloud.com/blogs/415547

- 点赞
- 收藏
- 关注作者
评论(0)