大模型技术的发展与实践

一、大模型的概念
大型语言模型,也称大语言模型、大模型(Large Language Model,LLM;Large Language Models,LLMs) 。
大语言模型是一种深度学习模型,特别是属于自然语言处理(NLP)的领域,一般是指包含数干亿(或更多)参数的语言模型,这些参数是在大量文本数据上训练的,例如模型GPT-3,PaLM,LLaMA等,大语言模型的目的是理解和生成自然语言,通过学习大量的文本数据来预测下一个词或生成与给定文本相关的内容。
参数可以被理解为模型学习任务所需要记住的信息,参数的数量通常与模型的复杂性和学习能力直接相关,更多的参数意味着模型可能具有更强的学习能力。
1、语言模型的发展史
语言是人类表达和交流的一种突出能力,我们在幼儿开始就学会了沟通表达,并且伴随我们一生。在很长一段时间机器无法掌握以人类的方式进行交流、创作的能力。实现让机器能够像人类一样阅读、书写和交流的能力,一直是学术界一个长期的研究课题,充满挑战。直到以chatGPT为标志性事件的大模型技术的出现,这一愿望才变得可能。大模型是语言模型发展的高级阶段,本节我们来梳理一下语言模型(Language Models,LM)的四个发展阶段,让读者可以更好地了解大模型是怎么进化出来的。
具体分成了统计语言模型、神经网络语言模型、预训练语言模型、大语言模型。
从技术上讲,语言模型是提高机器的语言智能的主要方法之一。一般来说,LM旨在对单词序列的生成概率进行建模,从而预测后面(或中间空缺的)单词的概率。LM的研究在学术界和产业界都受到了广泛的关注。
例如,最近网络上非常热火的ChatGPT技术,也是大模型的一种应用。OpenAI 的 GPT (Generative Pre-trained Transformer) 系列是大语言模型的典型代表,作为目前为止,公认最强的 GPT-4 架构,它已经被训练在数十亿的单词上。从实际应用表现来看,大语言模型具备回答各种问题、编写文章、编程、翻译等能力,如果深究其原理,LLM建立在Transformers架构之上,并在很大程度上扩展了模型的大小、预训练数据和总计算量。
可以这么通俗的理解:如果一个模型"足够大",那它就可以称为大模型。
2、OpenAI大模型发展历程
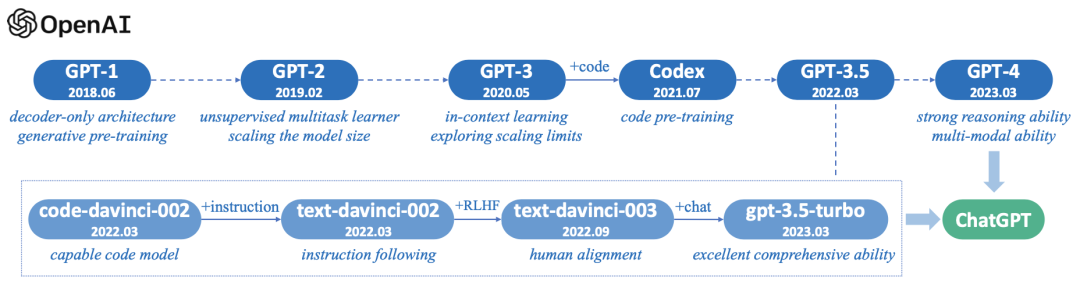
关于OpenAI网上的介绍非常多了,大家应该也比较熟悉了,我这里不过多说明,这一小节重点讲一下GPT系列的发展历程。GPT系列大体经历了如下6个发展阶段(下图上一行),最新的版本是GPT-4,目前一直在迭代优化中。下图第二行是基于GPT-3.5的一系列迭代版本(大家如果购买过openAI的大模型账号并进行过相关开发,应该是知道这些名字的),这个版本被大家熟知是2022年11月30日发布的chatGPT,目前chatGPT一直在优化中,GPT-4中的能力也逐步融入到了chatGPT中,chatGPT是一个不断进化的系统。
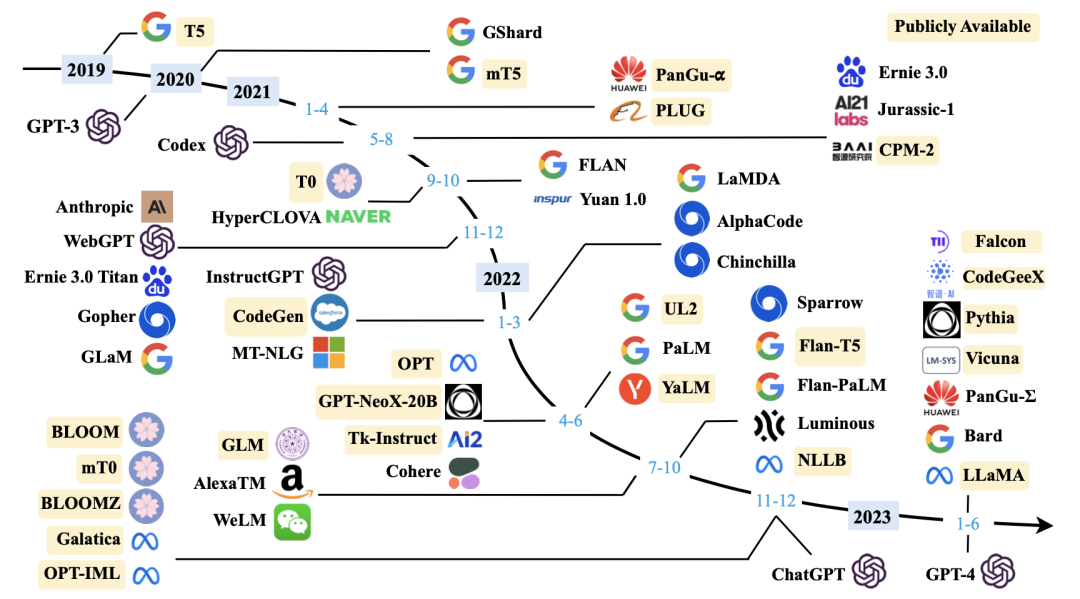
除了OpenAI外,国内外还有非常多的公司参与大模型赛道(国内的报道可以参考晚点发布的「大模型创业潮:狂飙 180 天」,见参考文献15,不过大模型发展太快了,一天一个样,可能等读者看到时,又有新的创业公司加入大模型挑战赛了,或者有更先进、更厉害的模型出现了),下面图2是截止到2023年6月底国内外重要的大模型的发展脉络。
3、预训练技术
其中k是上下文窗口的大小,条件概率P使用参数为θ的神经网络建模。这些参数使用随机梯度下降法进行训练。一般用多层Transformer解码器(见参考文献20)作为语言模型(即P),它是Transformer的变体。

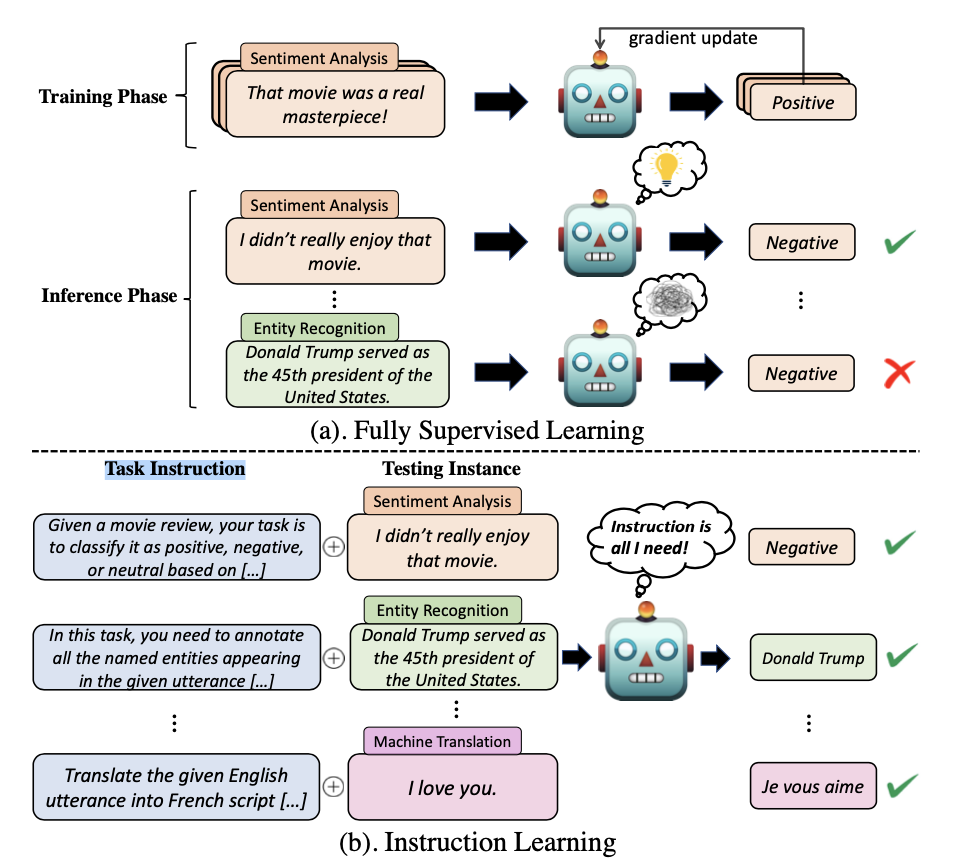
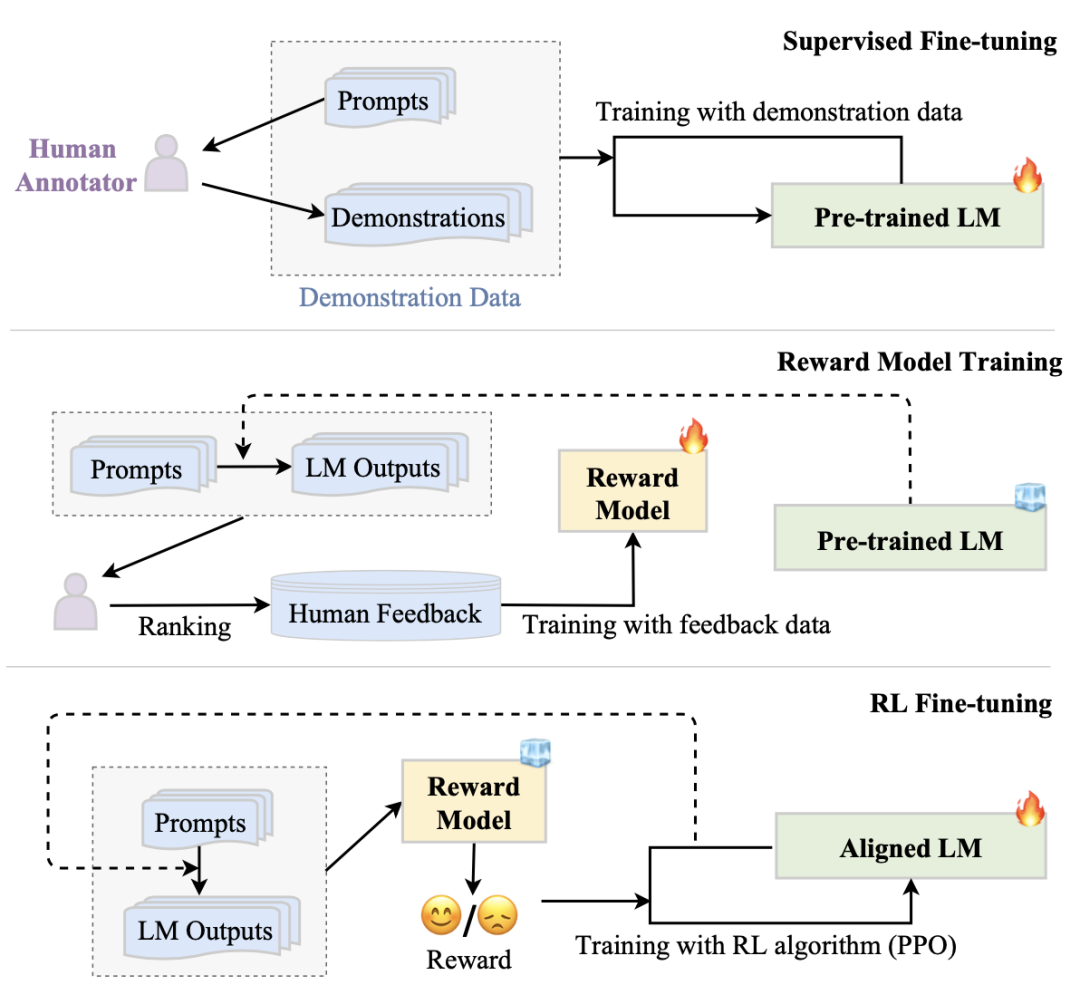
3.1指令微调
指令微调通常更有效,因为只有中等数量的样本用于训练。由于指令微调是一个有监督的训练过程,其优化在几个方面与预训练不同,例如训练目标(比如序列到序列的loss)和优化配置参数(比如较小的批大小和学习率)。
3.2对齐微调
研究表明,人类对齐能在一定程度上损害了LLM的一般能力(即为了实现人类对齐,让LLM在其它任务上的表现变差),相关文献称之为对齐税(alignment tax)。
二、ChatGPT的出现
自2022年11月30日OpenAI发布chatGPT以来,大模型技术掀起了新一轮人工智能浪潮。chatGPT在各个领域(包括对话、摘要、内容生成、问题解答、识图、数学计算与推理、代码编写等)取得了比之前算法好得多的成绩,很多方面都超越了人类专家的水平,特别是对话交流具备了一定的共情能力,这让AI领域的工作者和普通大众相信AGI(Artificial General Intelligence,通用人工智能)时代马上就要来临了。
GPT,全称"Generative Pre-training Transformer",是一个由OpenAI开发的自然语言处理(NLP)的模型。它的主要目标是理解和生成人类的自然语言。通过对大规模文本数据进行预训练,GPT模型能学习到语言的各种模式,如语法、句法、一词多义等,以及一些基础的世界知识。
总的来说,它通过预训练和生成技术,以及Transformer的自注意力机制,来理解和生成人类的自然语言。

GPT-3是一个特别的大模型,因为它有1750亿个参数。这些参数使得GPT-3在处理语言任务时表现出强大的能力,例如:理解和生成自然语言文本、进行有深度和上下文的对话等。所以,可以说GPT-3是大模型的一个具体应用,显示了大模型的强大能力和可能性。
三、大模型的应用场景
大模型被专家、学者一致认为可能是第四次AI革命的“导火索”,极有可能推动AGI时代的到来。
既然大家都这么看好大模型技术,那么大模型的价值体现在什么地方呢?我们可以从大模型能够解决什么问题的角度出发,梳理大模型对个人生活、对企业运营、对社会发展可能带来的影响和革新,因此本节我们重点讲解个5大模型具有颠覆性的应用场景。
1、内容生成
我们这里的内容生成是广义的,包括文本、图片、视频、音频、代码等,以及对文本内容进行总结、从图片或者视频中提取信息等都属于此范畴。内容生成应该是大模型最直接的应用场景,我们从下面5个场景展开说明。
-
文本生成在这个领域,影响最大的是文字工作者,比如自媒体、编辑、文秘、作家等。目前大模型生成的内容还不能直接拿来用,需要人工进行审核、调整,修改不当的地方。大模型是文字工作者最好的帮手,可以给创作者提供思路,创作原型,因此可以极大地提升创作效率。
-
内容摘要内容摘要的应用场景还是挺多的。对于文本进行摘要可以帮忙读者更快了解文章的主题,从而决定值不值得全部看一遍。另外,对于科研工作者,利用摘要的能力,可以极大提高文献阅读效率。
-
图片生成目前大模型可以基于一段文字描述生成图片,还可以生成相似图片,以及对图片进行风格迁移。这里面比较有名的是midjourney(公司)、stable diffusion(开源项目)等。下面图就是之前走红网络的、midjourney生成的中国情侣的照片(图片来源于midjourney的大模型生成程序),大家可以看到图片细节是非常逼真的。

大模型生成图片的应用价值非常大,比如文章配图、文内关键段落配图、电影电视剧海报图、广告宣传图、电商的物料图等。大模型对以绘画为职业的人冲击非常大,像游戏公司之前有很多插画师,现在基本都可以用大模型来替代了,之前国内就报道过有家游戏公司裁掉了大量的游戏插画师。
-
视频生成大模型的视频生成能力,可以基于一段文本描述生成逼真的视频,目前生成的视频的时长和清晰度还待优化。
视频生成领域的应用价值,相信读者可以感知到,比如创意、宣传、教学、影视、游戏等领域都可以从视频自动生成中获得极大的生产力。
-
代码生成大模型基于代码数据训练后,具备了代码纠错、找bug、自动写代码的能力。这对于程序员的生产力提升是不言而喻的,GitHub网站上30%新代码是在AI编程工具Copilot(大模型)帮助下完成的。未来随着大模型代码能力的增强,对初中级程序员是致命打击,很多编程工作可能都被机器替代了。但是资深程序员、架构师不会受影响。
ChatGPT是一种特定的GPT应用,GPT是一种大模型,而大模型是一类具有大量参数的深度学习模型。
2、模型演示
Prompt:您好,请帮我解释一下什么是人工智能?

四、为什么需要学习使用开源大模型
首先,目前GPT大模型的使用受到国内外的双重限制,这对于用户的操作空间产生了较大影响。此外,保证数据安全性对于企业来说至关重要,使用GPT大模型可能会存在数据泄露等安全隐患,这无疑增加了使用风险。
其次,在经济层面,使用GPT大模型通常是按量计费的,如果需要大规模使用,就需要支付相对较高的费用。这对于需要控制成本的企业来说,无疑增加了其运营压力。
再次,GPT大模型虽然可以进行微调,但是无法从训练语料层面进行定制化训练。这可能会导致中文对话显得稍显生硬,不够自然,无法满足一些特定需求。
因此,学习并使用开源大模型具有很大的必要性。它们不仅可以帮助我们避免上述问题,还可以根据我们的具体需求进行定制化训练,从而更好地满足我们的需求。
五、总结与体会
我们对大模型相关的发展历史、openAI技术的发展脉络、当前国内外主流的大语言模型进行了简单的介绍,同时针对大模型区别于之前模型的核心技术原理进行了简单讲解,本章提到的预训练、指令微调、对齐微调、上下文学习、思维链提示、规划等核心技术读者需要了解。相信通过本章的讲解,读者大致了解了大模型相关的知识。
在最后一节从内容生成、问题解答、互动式对话、生产力工具/企业服务、搜索推荐等5个维度介绍了大模型能够赋能的领域和应用场景。未来大模型一定会革新所有的行业和场景的。读者需要对大模型相关的技术及行业、场景应用保持敏感,在工作中要将大模型相关的技术用起来。
未来的生活和发展已经离不开大模型,这将会带来更大的科技发展和改变,我们需要掌握并熟练使用大模型的工具,让我们的工作和生活变得更加高效和充实。

- 点赞
- 收藏
- 关注作者
评论(0)