一文带你速通Sentinel限流规则(流控)解读

目录
前置知识速补
- QPS每秒查询率(Query Per Second):每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。 (看来是类似于TPS,只是应用于特定场景的吞吐量)
- 吞吐量(Throughput):吞吐量是指系统在单位时间内处理请求的数量。对于无并发的应用系统而言,吞吐量与响应时间成严格的反比关系,实际上此时吞吐量就是响应时间的倒数。前面已经说过,对于单用户的系统,响应时间(或者系统响应时间和应用延迟时间)可以很好地度量系统的性能,但对于并发系统,通常需要用吞吐量作为性能指标。
- 资源: 是 Sentinel 中的核心概念之一。最常用的资源是我们代码中的 Java 方法,一段代码,或者一个接口。
基本介绍
一条限流规则主要由下面几个因素组成,我们可以组合这些元素来实现不同的限流效果:
- resource:资源名,即限流规则的作用对象
- count: 限流阈值
- grade: 限流阈值类型,QPS 或线程数
- strategy: 根据调用关系选择策略
- controlBehavior: 流量控制效果(直接拒绝、Warm Up、匀速排队)
| Field | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,资源名是限流规则的作用对象 | |
| count | 限流阈值 | |
| grade | 限流阈值类型,QPS 或线程数模式
1. QPS:每秒请求数,当前调用该api的QPS到达阈值的时候进行限流 2. 线程数:当调用该api的线程数到达阈值的时候,进行限流 |
QPS 模式 |
| limitApp | 流控针对的调用来源 | default,代表不区分调用来源 |
| strategy | 调用关系限流策略:直接、链路、关联 | 根据资源本身(直接) |
| controlBehavior | 流控效果(直接拒绝 / 排队等待 / 慢启动模式),不支持按调用关系限流 | 直接拒绝 |
同一个资源可以同时有多个限流规则。
我们可以通过代码定义流量控制规则也可以通过在sentinel控制台进行配置,下面是一个代码配置的方式:
@Service
public class TestService {
@PostConstruct
public void init(){
initFlowRule();
}
private static void initFlowRule(){
//流控规则集合
List<FlowRule> rules = new ArrayList<>();
//创建规则
FlowRule rule = new FlowRule();
//设置受保护的资源
rule.setResource("sayHello");
//设置流控规则 QPS 限流阈值类型:QPS、并发线程数
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// 设置受保护的资源的阈值
rule.setCount(2);
//设置流控手段:快速失败
rule.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_DEFAULT);
rules.add(rule);
//加载配置好的规则
FlowRuleManager.loadRules(rules);
}
@SentinelResource(value = "sayHello")
public String sayHello(String name) {
return "Hello, " + name;
}
}流控模式
在添加限流规则时,点击高级选项,可以选择三种流控模式:
- 直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
- 关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
- 链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
直接模式
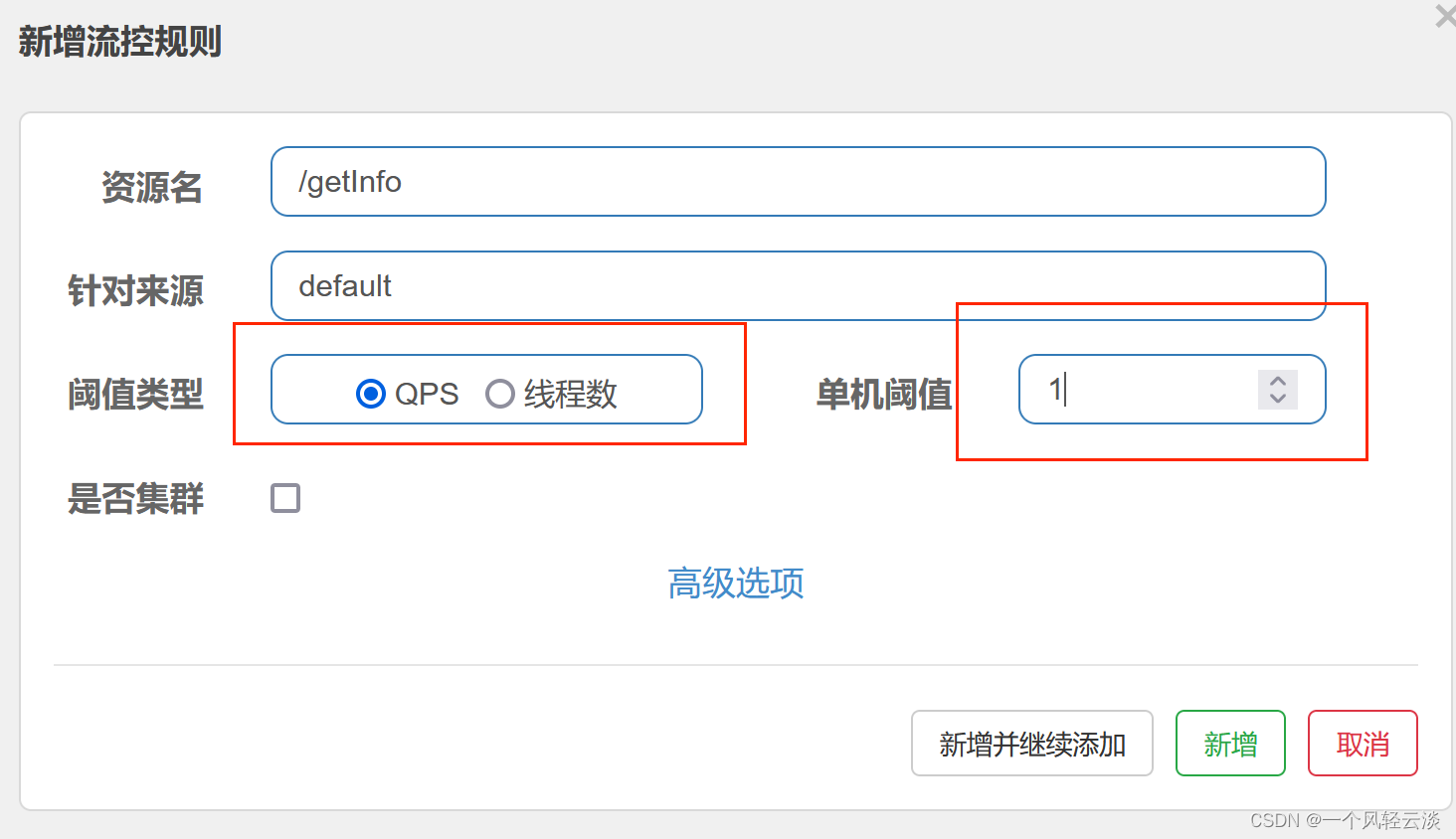
直接流控模式是最简单的模式,当指定的接口达到限流条件时开启限流。
示例:
![]()
其含义是限制 /getInfo这个资源的单机QPS为1,即每秒只允许1次请求,超出的请求会被拦截并报错。
关联模式
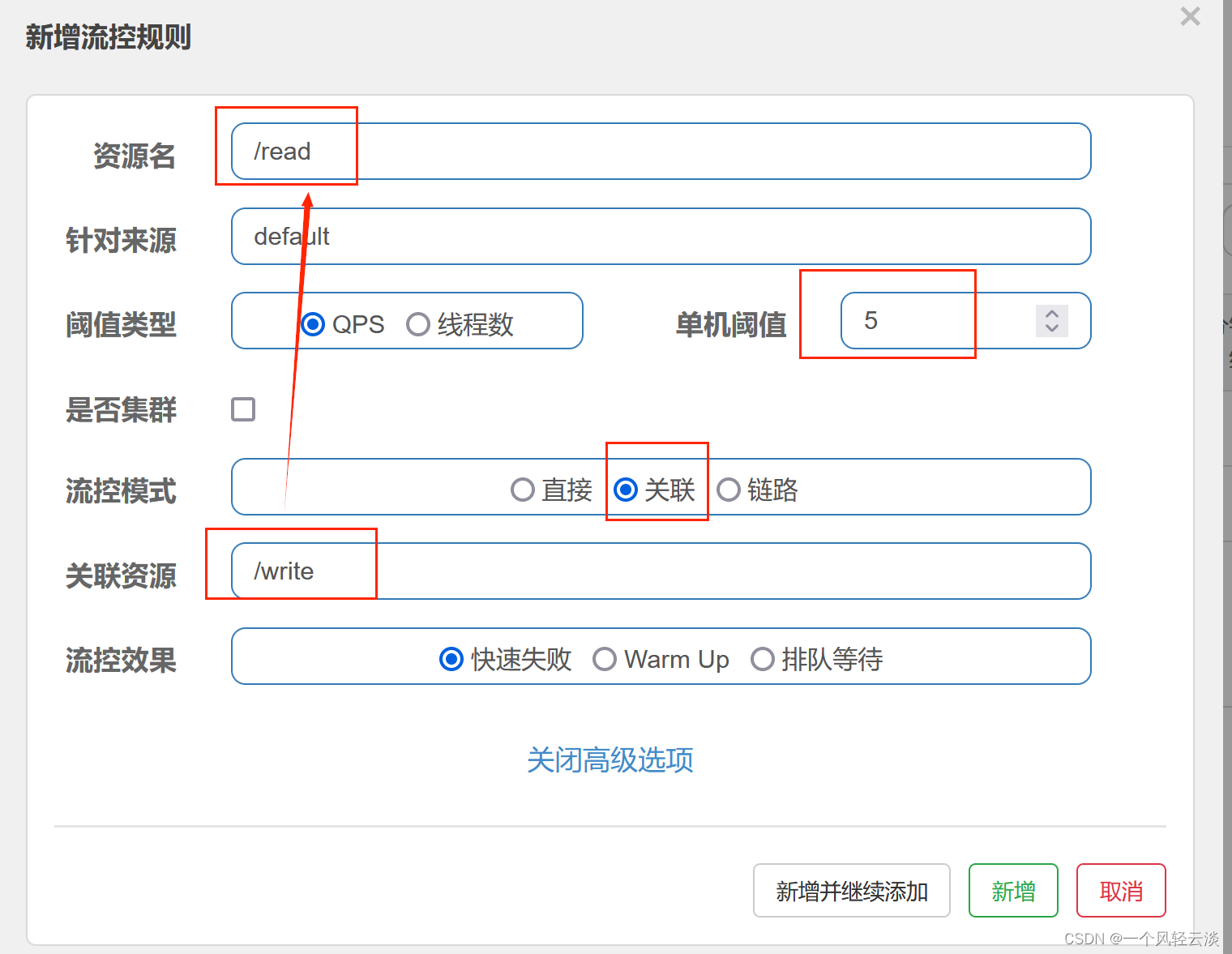
关联模式:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流。
调用关系包括调用方、被调用方;一个方法又可能会调用其它方法,形成一个调用链路的层次关系。Sentinel 通过 NodeSelectorSlot 建立不同资源间的调用的关系,并且通过 ClusterBuilderSlot 记录每个资源的实时统计信息。当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。
比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢.
示例:
![]()
当/write资源访问量触发阈值(也就是5时)时,就会对/read资源限流,避免影响/write资源。
链路模式
链路模式:只针对从指定链路访问到本资源的请求做统计,判断是否超过阈值。
假设现在某公司开发了一个单机的电商系统,为了满足完成“下订单”的业务,程序代码会依次执行订单创建方法->减少库存方法->微信支付方法->短信发送方法。方法像链条一样从前向后依次执行,这种执行的链条被称为调用链路在。
比如某个微服务中 /get接口,会被 /pay接口调用。在另一个业务,List 接口也会被 /shop接口调用。
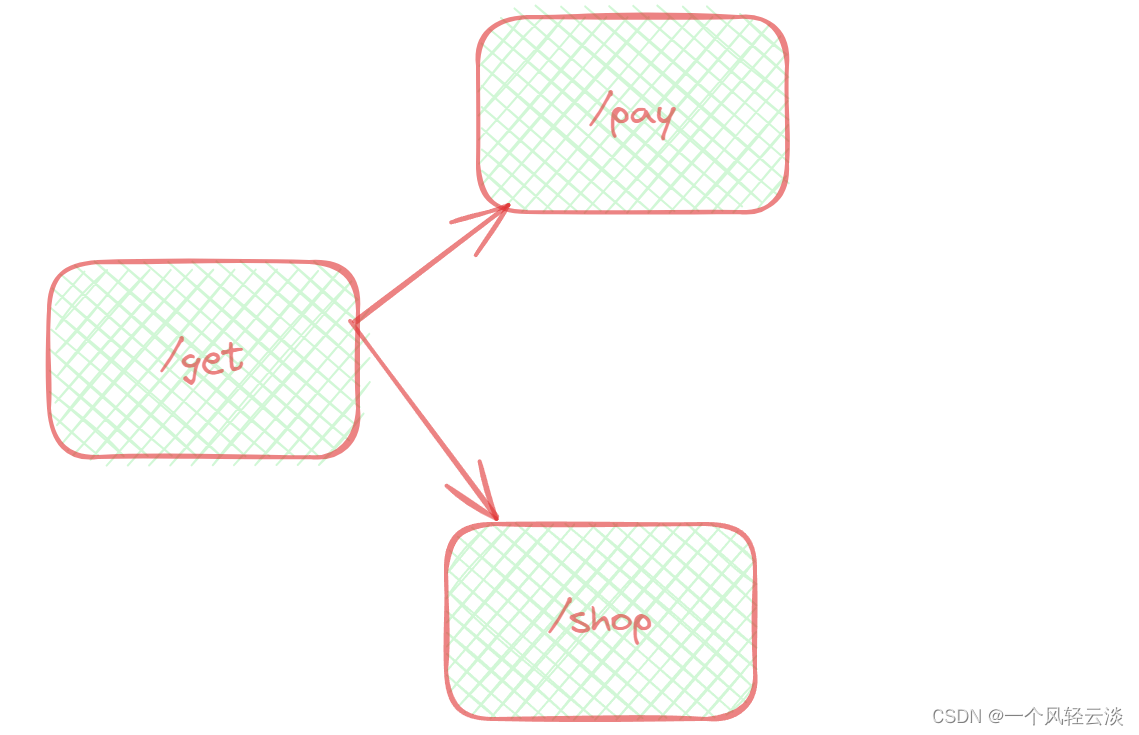
![]()
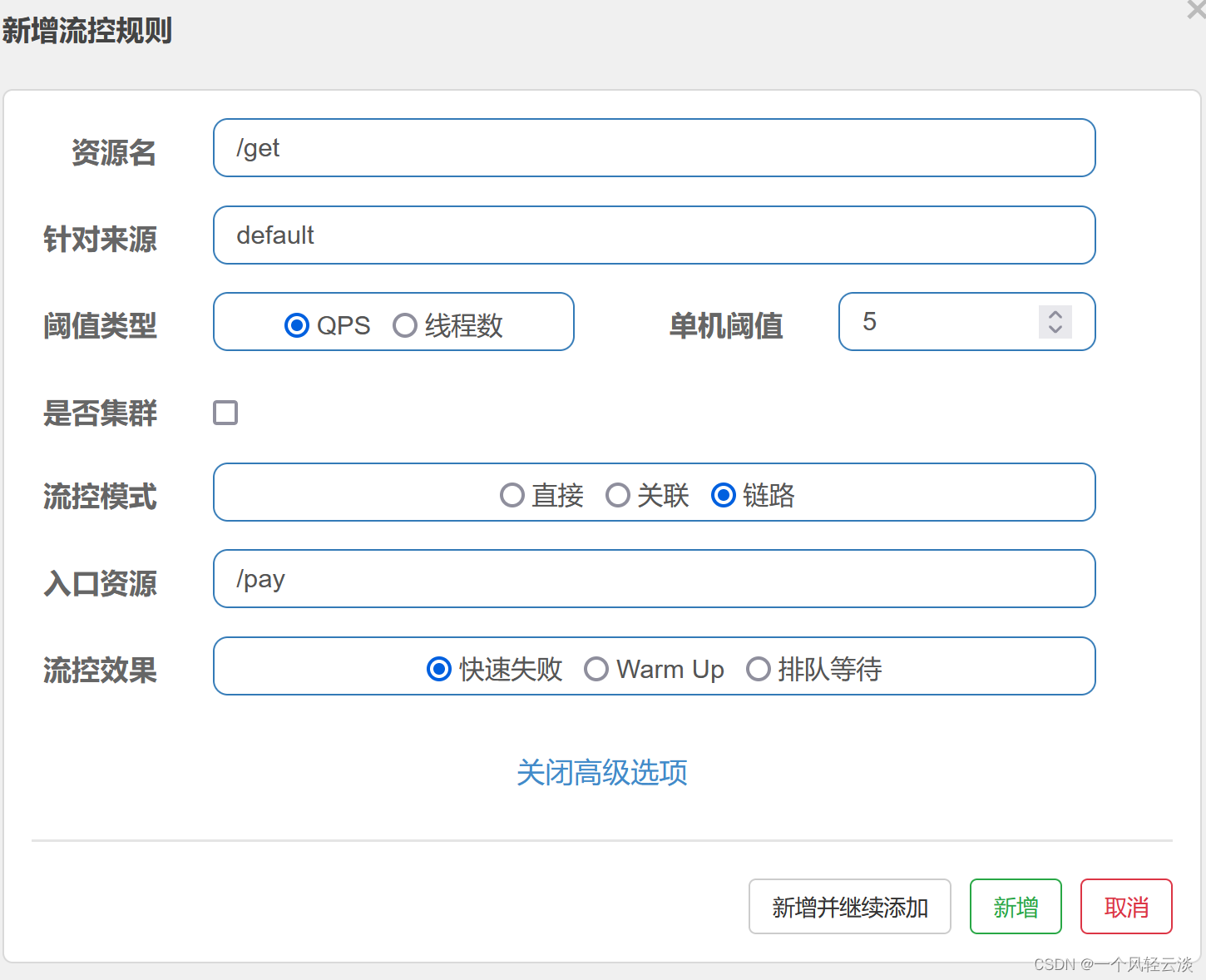
但如果按下图配置,将入口资源设为“/pay”,则只会针对 pay接口的调用链路生效。当访问 pay接口的QPS 超过 1 时,get接口就会被限流。而另一条链路从 shop接口到get接口的链路则不会受到任何影响。
![]()
链路模式与关联模式最大的区别是 /get接口与 /pay接口必须是在同一个调用链路中才会限流,而关联模式是任意两个资源只要设置关联就可以进行限流。
流控效果
直接失败
快速失败是指流量当过限流阈值后,直接返回响应并抛出 BlockException,快速失败是最常用的处理形式。
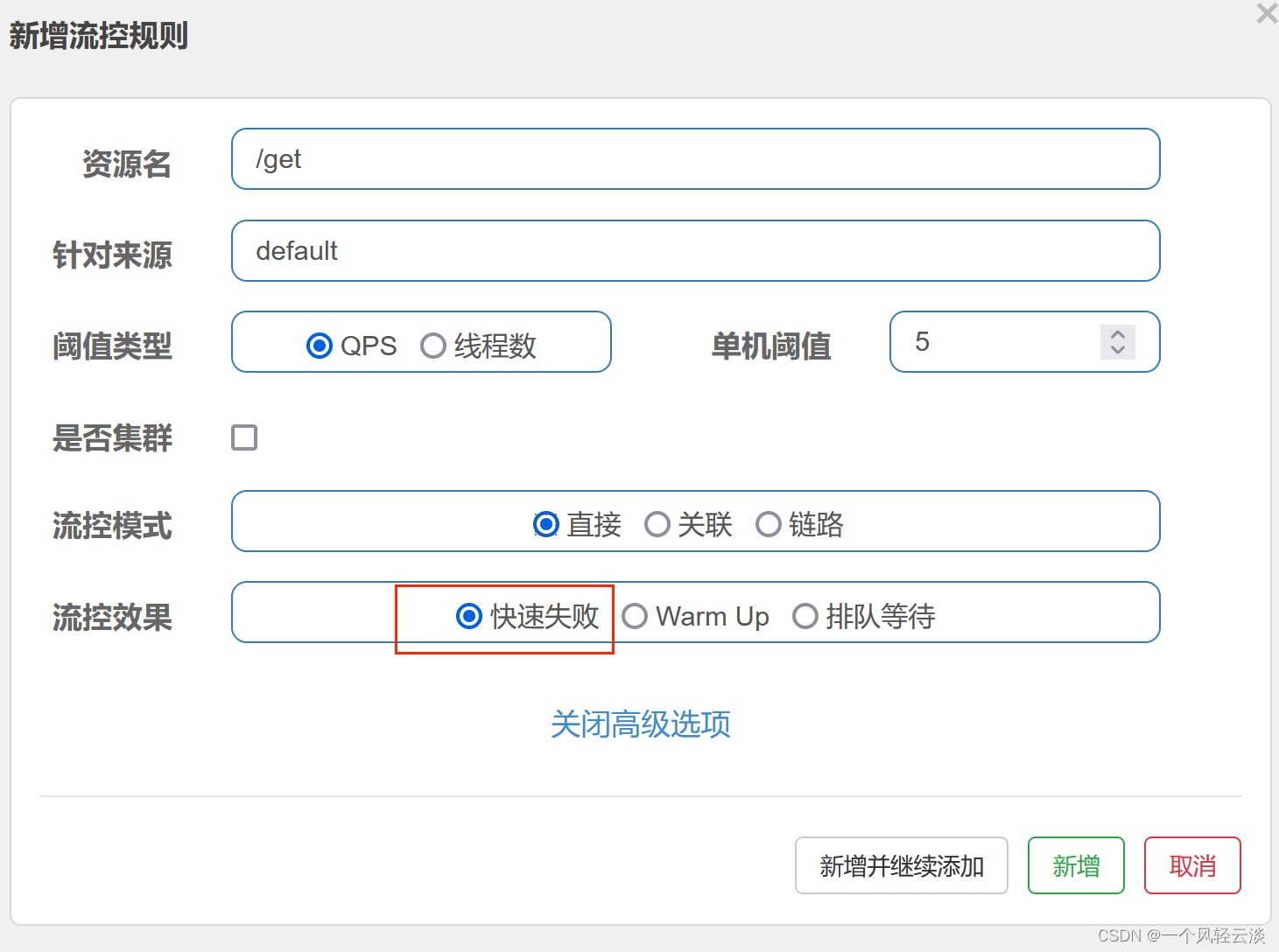
![]()
Warm Up(预热)
阈值一般是一个微服务能承担的最大QPS,但是一个服务刚刚启动时,一切资源尚未初始化(冷启动),如果直接将QPS跑到最大值,可能导致服务瞬间宕机。
warm up也叫预热模式,是应对服务冷启动的一种方案。Warm Up 用于应对瞬时大并发流量冲击。请求阈值初始值是 maxThreshold / coldFactor,持续指定时长后,逐渐提高到maxThreshold值。而coldFactor的默认值是3。
例如:List 接口平时单机阈值 QPS 处于低水位:默认为 1000/3 (冷加载因子)≈333,当瞬时大流量进来,10 秒钟内将 QPS 阈值逐渐拉升至 1000,为系统留出缓冲时间,预防突发性系统崩溃。预热10秒后,慢慢将阈值升至1000。刚开始刷/;List,会出现默认错误,预热时间到了后,阈值增加,没超过阈值刷新,请求正常。
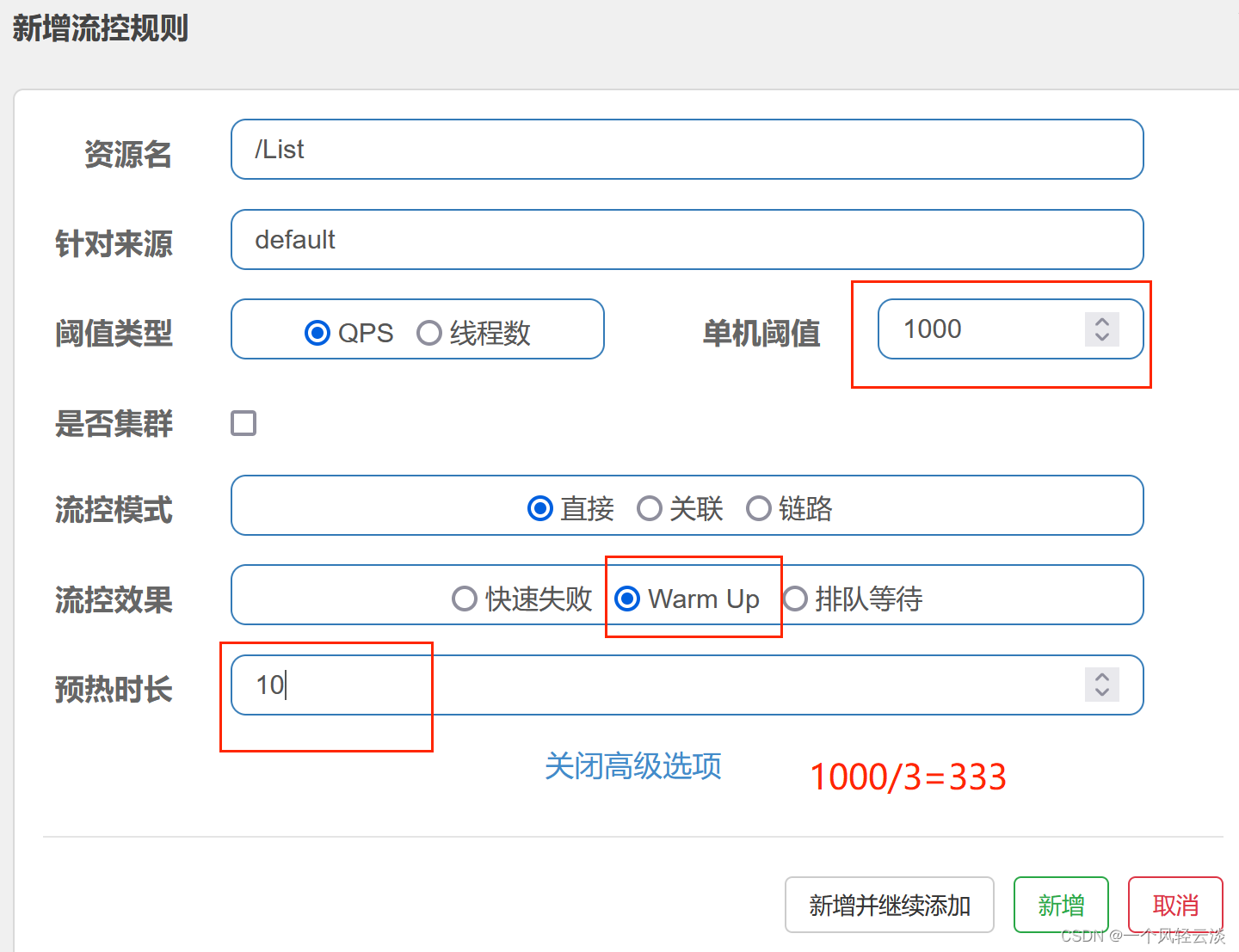
![]()
排队等待
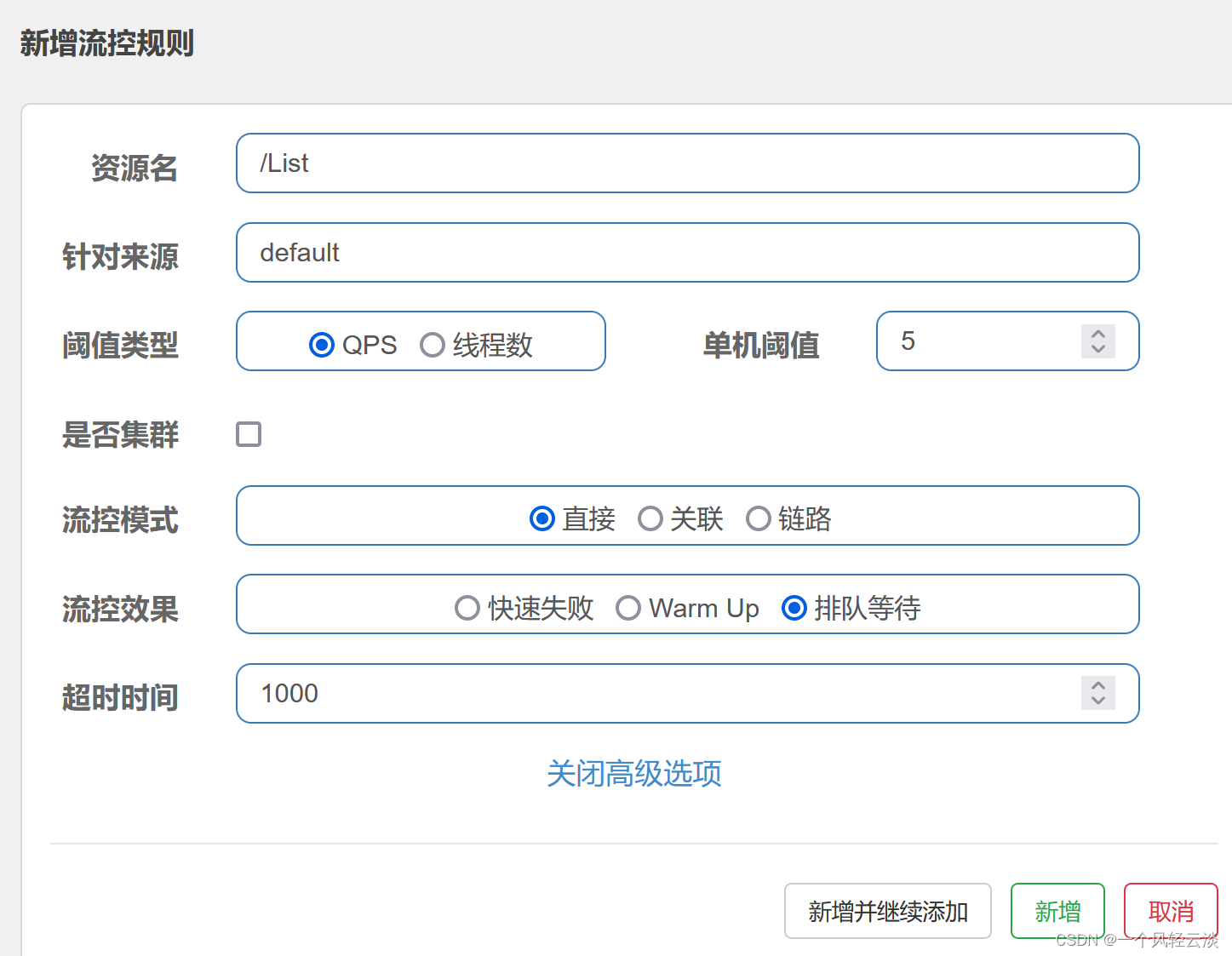
当请求超过QPS阈值时,快速失败和warm up 会拒绝新的请求并抛出异常。而排队等待则是让所有请求进入一个队列中,然后按照阈值允许的时间间隔依次执行。后来的请求必须等待前面执行完成,如果请求预期的等待时间超出最大时长,则会被拒绝。
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
Sentinel会以固定的间隔时间让请求通过, 访问资源。当请求到来的时候,如果当前请求距离上个通过的请求通过的时间间隔不小于预设值,则让当前请求通过;否则,计算当前请求的预期通过时间,如果该请求的预期通过时间小于规则预设的 timeout 时间,则该请求会等待直到预设时间到来通过;反之,则马上抛出阻塞异常。
工作原理:
例如:QPS = 5,意味着每200ms处理一个队列中的请求;timeout = 2000,意味着预期等待时长超过2000ms的请求会被拒绝并抛出异常。
那什么叫做预期等待时长呢?
比如现在一下子来了12 个请求,因为每200ms执行一个请求,那么:
-
第6个请求的预期等待时长 = 200 * (6 - 1) = 1000ms
-
第12个请求的预期等待时长 = 200 * (12-1) = 2200ms
也就是第12个请求会被拒绝,其他请求会进入等待队列
![]()

- 点赞
- 收藏
- 关注作者
评论(0)