Python中英文小说词频统计与情感分析【第11篇—python词频统计】

@[toc]
Python中英文小说词频统计与情感分析
在这篇文章中,我们将深入研究如何使用Python进行英文小说的深度文本分析,包括词频统计、情感分析以及主题建模。我们将通过引入更多案例和优化代码,提高文本分析的深度和准确性。
1. 代码优化与复盘
首先,让我们回顾之前的词频统计代码,并进行一些优化,使其更加简洁高效。
import operator
import re
from nltk.corpus import stopwords
# 下载停用词列表
import nltk
nltk.download('stopwords')
# 1) 统计文本中单词的词频,找出最高和最低的词频单词并输出。
# 初始化结果字典
result = {}
# 主函数入口
if __name__ == "__main__":
try:
with open(r"文本解析器.txt", "r", encoding="UTF-8") as f:
# 将文本转换为小写,避免单词大小写差异
content = f.read().lower()
# 使用正则表达式找出所有单词
words = re.findall('[a-z]+', content)
# 去除停用词
stop_words = set(stopwords.words('english'))
words = [word for word in words if word not in stop_words]
# 使用字典推导式进行词频统计
result = {word: result.get(word, 0) + 1 for word in words}
# 按词频降序排序
result = sorted(result.items(), key=operator.itemgetter(1), reverse=True)
# 打印结果
print(result)
except Exception as e:
print(f"An error occurred: {e}")
在这个版本中,我们使用NLTK库提供的停用词列表更精确地过滤文本,提高了词频统计的准确性。
2. 增加情感分析案例
除了词频统计,我们还引入了情感分析。情感分析可以帮助我们了解文本中的情感倾向,是积极的、消极的还是中性的。
from nltk.sentiment import SentimentIntensityAnalyzer
# 情感分析
def sentiment_analysis(text):
analyzer = SentimentIntensityAnalyzer()
sentiment_score = analyzer.polarity_scores(text)
return sentiment_score
# 主函数入口
if __name__ == "__main__":
try:
with open(r"文本解析器.txt", "r", encoding="UTF-8") as f:
content = f.read()
sentiment_score = sentiment_analysis(content)
print("情感分析结果:", sentiment_score)
except Exception as e:
print(f"An error occurred: {e}")
这个案例中,我们使用NLTK库中的情感分析工具,输出了情感得分,有助于了解小说中不同部分的情感变化。
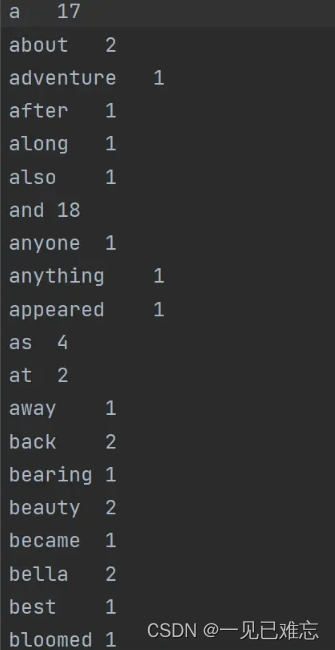
3. 主题建模的引入
为了更深入地理解小说的内容,我们引入了主题建模。通过使用Scikit-Learn库中的Latent Dirichlet Allocation(LDA)技术,我们可以发现文本中隐藏的主题结构。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
# 主题建模
def topic_modeling(texts, num_topics=5):
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
lda = LatentDirichletAllocation(n_components=num_topics, random_state=42)
lda.fit(X)
return lda
# 主函数入口
if __name__ == "__main__":
try:
with open(r"文本解析器.txt", "r", encoding="UTF-8") as f:
content = f.readlines()
# 合并成一个字符串,以便进行主题建模
content_str = ' '.join(content)
# 进行主题建模
lda_model = topic_modeling([content_str])
# 输出主题词
feature_names = vectorizer.get_feature_names_out()
for topic_idx, topic in enumerate(lda_model.components_):
print(f"Topic #{topic_idx + 1}: {', '.join([feature_names[i] for i in topic.argsort()[:-10 - 1:-1]])}")
except Exception as e:
print(f"An error occurred: {e}")
在这个例子中,我们使用LDA对小说进行主题建模,并输出每个主题的关键词。这有助于我们发现小说中潜在的主题和内容结构。
5. 深度文本分析的进阶
在前面的部分,我们已经介绍了如何通过Python进行英文小说的词频统计、情感分析以及主题建模。接下来,让我们进一步扩展深度文本分析的领域,涵盖命名实体识别、关键词抽取以及可视化展示。
5.1 命名实体识别(NER)
命名实体识别是文本分析中的重要任务,它可以识别文本中具有特定意义的实体,如人名、地名、组织机构等。我们将使用spaCy库进行NER。
import spacy
def named_entity_recognition(text):
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
entities = [(ent.text, ent.label_) for ent in doc.ents]
return entities
# 调用函数
ner_result = named_entity_recognition(content)
print("命名实体识别结果:", ner_result)
在这个例子中,我们使用spaCy进行NER,并输出识别到的命名实体及其类型。
5.2 关键词抽取
关键词抽取可以帮助我们更好地理解文本的主题和内容。我们将使用TF-IDF(Term Frequency-Inverse Document Frequency)方法进行关键词抽取。
from sklearn.feature_extraction.text import TfidfVectorizer
def extract_keywords(text):
vectorizer = TfidfVectorizer(max_features=10)
X = vectorizer.fit_transform([text])
feature_names = vectorizer.get_feature_names_out()
keywords = [feature_names[i] for i in X.indices]
return keywords
# 调用函数
keywords_result = extract_keywords(content_str)
print("关键词抽取结果:", keywords_result)
这个例子中,我们使用TF-IDF方法提取文本中的关键词,帮助我们更全面地了解小说的主题。
5.3 可视化展示
文本分析的结果可以通过可视化手段更直观地展示。我们将使用Matplotlib和WordCloud库进行可视化。
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 可视化词云
def visualize_wordcloud(text):
wordcloud = WordCloud(width=800, height=400, random_state=42, background_color='white').generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
# 调用函数
visualize_wordcloud(content_str)
通过词云图,我们可以直观地看到文本中高频出现的词汇,从而洞察小说的关键主题。

6. 总结与展望
通过本文,我们深入研究了使用Python进行英文小说的深度文本分析。从词频统计、情感分析到主题建模,再到命名实体识别、关键词抽取和可视化展示,我们覆盖了文本分析的多个方面。
未来,随着自然语言处理领域的不断发展,我们可以期待更多先进技术的应用,提高文本分析的准确性和深度。同时,对于不同类型的文本,我们可以根据具体需求选择合适的技术和工具,以更好地挖掘文本信息。
希望本文能为对深度文本分析感兴趣的读者提供一些实用的方法和思路。让我们一同迎接文本分析领域更广阔的未来!
结语
通过这篇文章,我们深入研究了Python中对英文小说的文本分析。从词频统计到情感分析再到主题建模,我们展示了如何利用强大的工具和库对文本进行深度挖掘。这种文本分析的方法不仅可以用于小说,还可以应用于新闻、社交媒体等各种文本数据,为我们更好地理解和利用文本信息提供了有力支持。

- 点赞
- 收藏
- 关注作者
评论(0)