大数据_Hadoop介绍_分布式系统架构

大家好,我是北山啦,好久不见,Nice to meet you,本文将记录学习Hadoop生态圈相关知识。
大数据时代
大数据是指无法在一定时间范围内通过常用软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产
大数据时代的特征5V

应用场景,包括电商领域中的推荐以及金融方面中的个人信用评估,交通领域中拥堵预测,导航最优规划等等,https://beishan.blog.csdn.net/

大数据场景下:海量数据如何存储以及海量数据如何计算?
这里涉及到分布式、集群的概念
海量数据如何存储以及海量数据如何计算

Hadoop

Hadoop概述

侠义上Hadoop指的是Apache软件基金会的一款开源软件
允许用户使用简单的编程模型实现跨机器集群对海量数据进行分布式计算处理
==Hadoop核心组件==
HDFS:分布式文件存储系统,解决海量数据存储
YARN:集群资源管理和任务调度框架,解决资源任务调度
MapReduce:分布式计算框架,解决海量计算

广义上Hadoop指的是围绕Hadoop打造的大数据生态圈

Hadoop特性优点

Hadoop国内外应用
Hadoop最先应用于国内外的互联网公司,外国的例如:Yahoo、Facebook、IBM。国内的例如:BAT以及华为
Hadoop的成功在于它的通用性以及简单
精确区分做说什么和怎么做,做什么属于业务问题,怎么做属于技术问题,用户负责业务,Hadoop负责技术
Hadoop发行版本
分为开源社区版以及商业发行版

开源社区版本:https://hadoop.apache.org/
商业发行版本:https://www.cloudera.com/products/open-source/apache-hadoop.html

截至目前,Hadoop以及发展到了3.x版本,Hadoop1.0时,包括HDFS(分布式文件存储)和MapReduce(资源管理和分布式数据处理),到2.0,将MapReduce(分布式数据处理)进行拆分,引入新的组件YARN(集群资源管理、任务调度)

Hadoop3.0架构组件和Hadoop2.0类似,3.0着重于性能优化

Hadoop集群整体概述
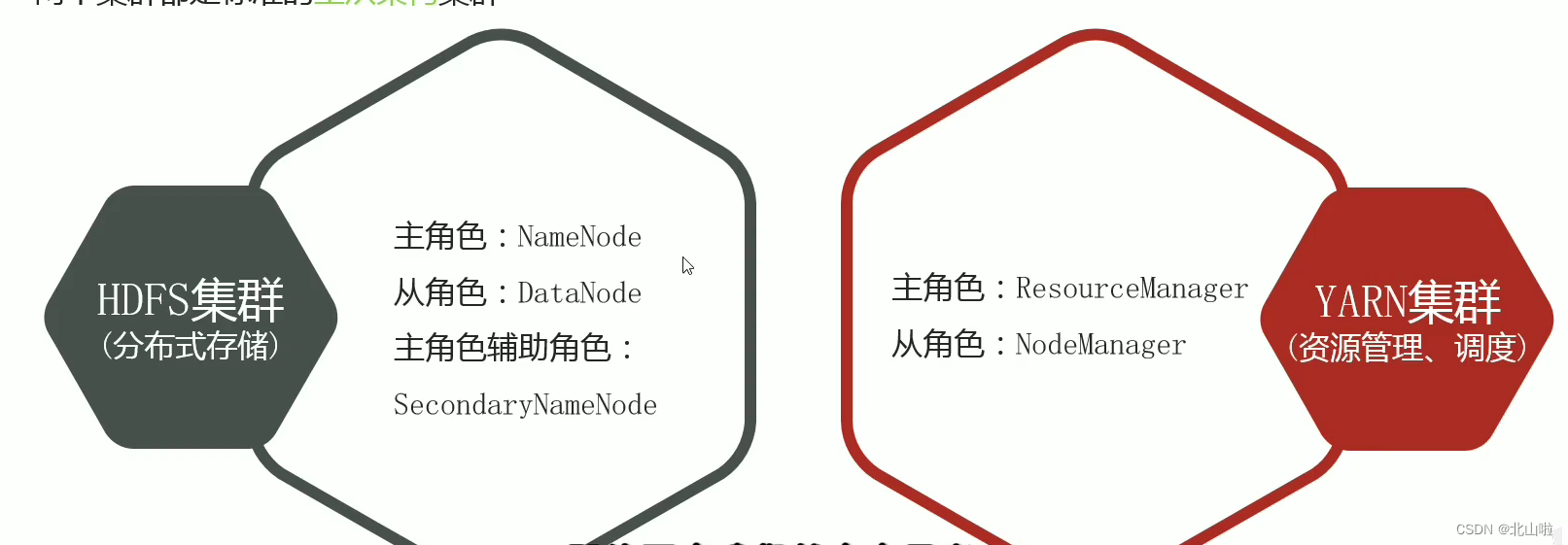
- Hadoop集群包括两个集群:HDFS集群、YARN集群
- 两个集群在逻辑上分离通常物理上在一起
- 两个集群都是标准的主从架构集群
MapReduce是计算框架、代码层面的组件 没有集群之说
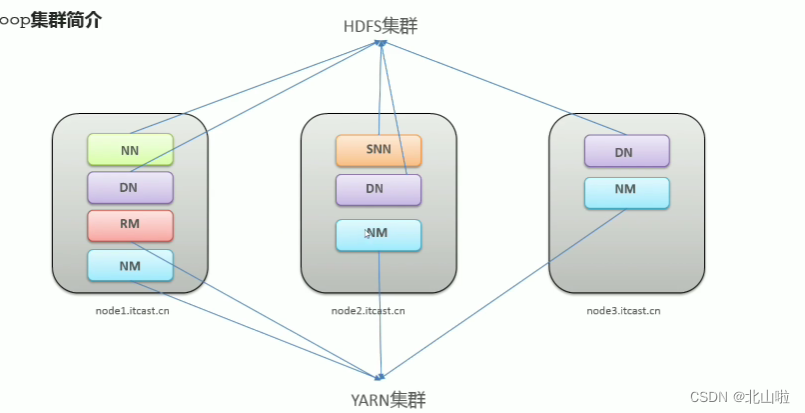
两个集群在逻辑上分离通常物理上在一起,可以从下图中理解
HDFS集群由一主(NN即NameNode)三从(DN即DataNode)+一个秘书(SNN即Secondary NameNode)构成
YARN集群由RM即Resource Manager和NM即Node Manager构成
Hadoop集群 = HDFS集群 + YARN集群
- 逻辑上分离,指他们之间互相没有依赖
- 物理上一起,指进程部署在同一台机器上

- 点赞
- 收藏
- 关注作者
评论(0)