自动化测试中几种常见验证码的处理方式及如何实现?

【摘要】 UI自动化测试时,需要对验证码进行识别处理,有很多方式,每种方式都有自己的特点,以下是一些常用处理方法,仅供参考。 1 去掉验证码从自动化的本质上来讲,主要是提升测试效率等,但是为了去研究验证码以及提升验证码的识别效率,是需要投入比较大的时间的;去掉验证码无疑是最简单的方式,而且对于开发而言这样做,工作量也不是很大;但是建议在测试环境使用,生产环境禁用,因为存在安全问题。 2 设置万能码这个...
UI自动化测试时,需要对验证码进行识别处理,有很多方式,每种方式都有自己的特点,以下是一些常用处理方法,仅供参考。
1 去掉验证码
- 从自动化的本质上来讲,主要是提升测试效率等,但是为了去研究验证码以及提升验证码的识别效率,是需要投入比较大的时间的;
- 去掉验证码无疑是最简单的方式,而且对于开发而言这样做,工作量也不是很大;
- 但是建议在测试环境使用,生产环境禁用,因为存在安全问题。
2 设置万能码
- 这个是笔者刚开始做自动化时首选的一个处理方法;
- 因为既测试到了验证码的功能,而且也不用投入太大的精力去研究如何进行验证码识别;
- 另外对于开发来说,内置一个万能验证码也是非常简单的事情;
- 对于写自动化脚本的人来说也是非常的方便,效率也高;
- 但这个万能验证码仅限相关人员知道,避免存在安全隐患。
3 保留一个资源
- 有点验证码实则就是图片资源;
- 其实就是在制定的文件夹资源库中随机抽取一张,那么只需要将服务器上的所有图片删除,仅保留一张即可;
- 说白了就相当于固定验证码。
4 光学字符识别
- 其实就是通过
Python-tesseract模块来只能识别图片中的验证码; Python-tesseract是光学字符识别Tesseract OCR的python封装类;- 其能够读取大部分常规图片文件,比如
JPG、GIF、PNG、TIFF等; - 这个笔者也尝试过,因为现在的图片验证码越来越复杂,其实有时候识别率并不高;
- 下边我们尝试着使用一下。
4.1 识别对象
- 我们收集了几个图片验证码(来源于网络,仅供参考):从左到右依次是
image01.jpg-image04.jpg:


4.2 pytesseract安装
- 直接使用命令安装即可:
pip install pytesseract
4.3 Pillow安装
- 直接使用命令:
pip install Pillow
4.4 OCR安装
- 直接在下载即可:OCR官网;
- 选择对应的版本下载即可:
- 按照提示安装完成:
- 配置环境变量,将其根目录添加到
path环境变量中:
4.5 识别原理
- 基本思路是通过图片降噪、图片切割等,输出图像文本;
- 图片降噪就是将图片中一些不需要的信息去除,比如背景、干扰像素、干扰线等。
- 如果验证码是彩色的背景,其实就是把每个像素放在五维空间,即
X、Y、R、G、B; X、Y是像素的二维平面坐标,RGB代表像素所对应的颜色。
4.6 处理过程
4.6.1 转灰度处理
- 导入需要的包:
from PIL import Image
- 打开需要分析的图像:
image = Image.open("./image01.jpg")
- 将彩色图像转化为灰度图像(
RGB转为HSI色彩空间),采用L分量:
# 彩色转灰度
img_01 = image.convert("L")
img_01.show()
- 以上完整代码为(使用
image01.jpg):
# -*- coding:utf-8 -*-
# 作者:虫无涯
# 日期:2023/11/14
# 文件名称:test_tesseract.py
# 作用:OCR验证码识别
# 联系:VX(NoamaNelson)
# 博客:https://blog.csdn.net/NoamaNelson
# 导入Image包
from PIL import Image
# 打开图像
image = Image.open("./image01.jpg")
# 彩色转灰度
img_01 = image.convert("L")
img_01.show()
- 转灰度后图像如下:

4.6.2 二值化处理
- 图像分割常用的方法就是二值化处理;
- 二值化处理就是二值化图像时,将大于某个临界灰度值的像素灰度设置为灰度的极大值,把小于这个值的像素灰度设为灰度的极小值,取值范围一般为
0-1; - 二值化算法不同,可分固定阈值和自适应阈值,比如这个固定阈值如下(使用
image02.jpg):
# -*- coding:utf-8 -*-
# 作者:虫无涯
# 日期:2023/11/14
# 文件名称:test_tesseract.py
# 作用:OCR验证码识别
# 联系:VX(NoamaNelson)
# 博客:https://blog.csdn.net/NoamaNelson
# 导入Image包
from PIL import Image
# 打开图像
image = Image.open("./image02.jpg")
# 二值化处理
img_02 = image.point(lambda x:0 if x<143 else 255)
img_02.show()
- 二值化后的效果:

- 我们结合前两种方法,把
image03.jpg先灰度再二值化处理后输出对应的文字:
# -*- coding:utf-8 -*-
# 作者:虫无涯
# 日期:2023/11/14
# 文件名称:test_tesseract.py
# 作用:OCR验证码识别
# 联系:VX(NoamaNelson)
# 博客:https://blog.csdn.net/NoamaNelson
# 导入Image包
from PIL import Image
from pytesseract import pytesseract
# 打开图像
image = Image.open("./image03.jpg")
# 灰度处理
img_new = image.convert("L")
# 二值化处理
img_03 = img_new.point(lambda x:0 if x<143 else 255)
img_03.show()
out_img = pytesseract.image_to_string(img_03)
print(out_img)
image03.jpg原图和处理后效果:
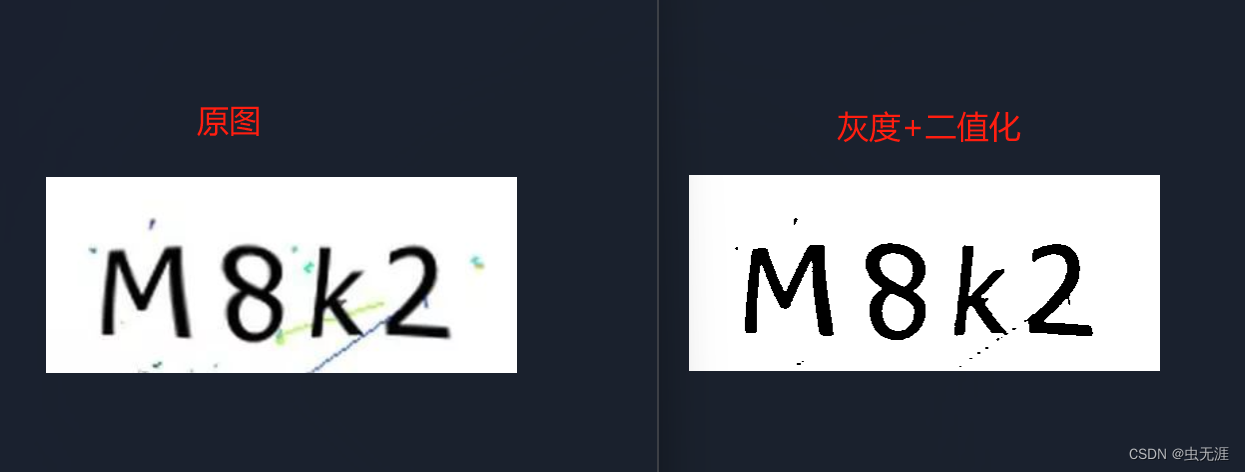
- 结果输出:

4.6.3 图像增强
- 为了排除更多的干扰,我们可以使用将图片增强显示,或者将图片转成黑白;
- 我们在以上代码继续添加:
from PIL import ImageEnhance
img_enh = ImageEnhance.Contrast(img_03)
img_enh01 = img_enh.enhance(4)
img_enh01 .show()
out_img = pytesseract.image_to_string(img_enh01)

4.6.4 完整代码
- 我们使用
image04.jpg输出完整代码:
# -*- coding:utf-8 -*-
# 作者:虫无涯
# 日期:2023/11/14
# 文件名称:test_tesseract.py
# 作用:OCR验证码识别
# 联系:VX(NoamaNelson)
# 博客:https://blog.csdn.net/NoamaNelson
# 导入Image包
from PIL import Image
from pytesseract import pytesseract
from PIL import ImageEnhance
# 打开图像
image = Image.open("./image04.jpg")
# 灰度处理
img_new = image.convert("L")
# 二值化处理
img_04 = img_new.point(lambda x:0 if x<143 else 255)
# 图像增强
img_enh = ImageEnhance.Contrast(img_04)
img_enh01 = img_enh.enhance(4)
# 处理后图片
img_enh01.show()
# 提取图片文字
out_img = pytesseract.image_to_string(img_enh01)
print(out_img)
- 处理前后的效果:

5 打码平台
- 另外我们可以通过打码平台来实现图片文字提取,比如超人、图鉴、斐斐等等;
- 比如图鉴平台,可以参考它的开发文档;

6 记录cookie
- 通过添加登录成功时所携带的
cookie来跳过登录; - 在
selenium中使用add_cookie()方法将用户名和密码等登录信息写入浏览器的cookie中,再次登录时直接读取浏览器cookie即可。 - 此处代码省略后续添加。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)