大模型部署手记(10)LLaMa2+Chinese-LLaMA-Plus-7B+Windows+llama.cpp+中英文对话

【摘要】 大模型部署手记(10)LLaMa2+Chinese-LLaMA-Plus-7B+Windows+llama.cpp+中英文对话

1.简介:
组织机构:Meta(Facebook)
代码仓:https://github.com/facebookresearch/llama
模型:llama-2-7b、llama-2-7b-chat(后来证明无法实现中文转换)、Chinese-LLaMA-Plus-7B(chinese_llama_plus_lora_7b)
下载:使用download.sh下载
硬件环境:暗影精灵7Plus
Windows版本:Windows 11家庭中文版 Insider Preview 22H2
内存 32G
GPU显卡:Nvidia GTX 3080 Laptop (16G)
在完成 https://bbs.huaweicloud.com/blogs/412529 和 https://bbs.huaweicloud.com/blogs/412535 的基础上,张小白觉得对话应该是水到渠成的事情了。
2.代码和模型下载:
关键是在前2篇的基础上,下载和制作中英文模型权重文件。
先准备下模型目录models_chat(显然最好不要用models目录)
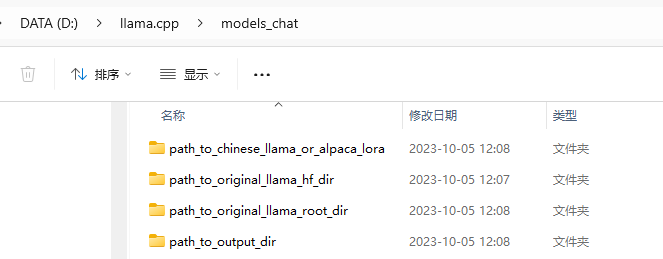
然后在该目录下创建以下几个子目录:
path_to_original_llama_root_dir 原始LLaMa
path_to_original_llama_hf_dir 转换好的HF版模型权重
path_to_output_dir 合并后的模型权重
path_to_chinese_alpaca_plus_lora 存放 Chinese-Alpaca-Pro-7B Lora模型
path_to_chinese_llama_plus_lora 存放 Chinese-LLaMA-Plus-7B Lora模型
1.原版的LLaMa模型
将 https://bbs.huaweicloud.com/blogs/412406 这篇文章中下载的 llama-2-7b-chat 模型目录下的所有文件都拷贝过来。
由于 llama-2-7b-chat 和 llama-2-7b 的 tokenizer 文件是一样的,所以也拷贝过来。
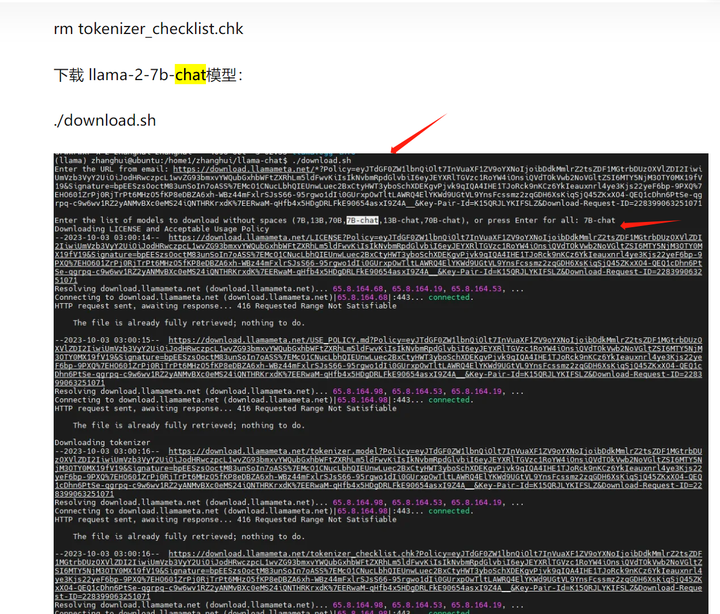
做个SHA256
certutil -hashfile models_chat\path_to_original_llama_root_dir\consolidated.00.pth sha256

结果为 6234f92a9191a4887b65a7f14a9692b4af3beffa2a26359869daf36bdf71b8d8
好像在 https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/SHA256.md 没找到。。。
这让我怀疑是不是下的不是原版模型。。。
可是我确实是用download.sh下载的啊。。。
(后来证明确实是这里有问题)
2.原版模型对应的Lora模型

解压到 D:\llama.cpp\models_chat\path_to_chinese_alpaca_plus_lora 目录:
做个SHA256
certutil -hashfile models_chat\path_to_chinese_alpaca_plus_lora\adapter_model.bin sha256
(llama) PS D:\llama.cpp> certutil -hashfile models_chat\path_to_chinese_alpaca_plus_lora\adapter_model.bin sha256 SHA256 的 models_chat\path_to_chinese_alpaca_plus_lora\adapter_model.bin 哈希: 3cd2776908c3f5efe68bf6cf0248cb0e80fb7c55a52b8406325c9f0ca37b8594 CertUtil: -hashfile 命令成功完成。
结果为:3cd2776908c3f5efe68bf6cf0248cb0e80fb7c55a52b8406325c9f0ca37b8594
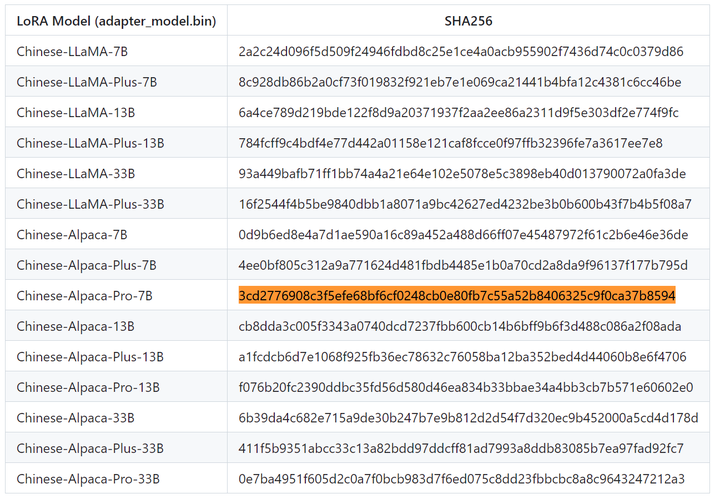
找到了。
将 models/chinese_llama_plus_lora_7b 目录下的模型复制到 D:\llama.cpp\models_chat\path_to_chinese_llama_plus_lora 目录下:
certutil -hashfile models_chat\path_to_chinese_llama_plus_lora\adapter_model.bin sha256
(llama) PS D:\llama.cpp> certutil -hashfile models_chat\path_to_chinese_llama_plus_lora\adapter_model.bin sha256 SHA256 的 models_chat\path_to_chinese_llama_plus_lora\adapter_model.bin 哈希: 8c928db86b2a0cf73f019832f921eb7e1e069ca21441b4bfa12c4381c6cc46be CertUtil: -hashfile 命令成功完成。
SHA256:8c928db86b2a0cf73f019832f921eb7e1e069ca21441b4bfa12c4381c6cc46be
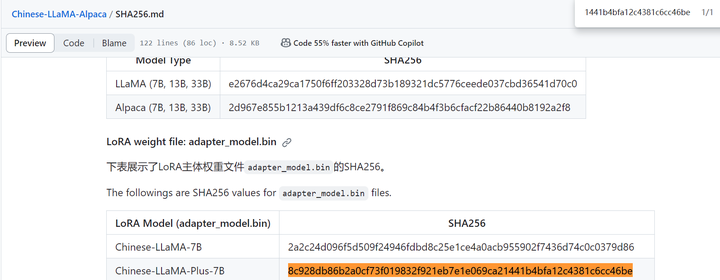
也找到了。
检查tokenizer.model的SHA256
certutil -hashfile models_chat\path_to_chinese_llama_plus_lora\tokenizer.model sha256
(llama) PS D:\llama.cpp> certutil -hashfile models_chat\path_to_chinese_llama_plus_lora\tokenizer.model sha256 SHA256 的 models_chat\path_to_chinese_llama_plus_lora\tokenizer.model 哈希: e2676d4ca29ca1750f6ff203328d73b189321dc5776ceede037cbd36541d70c0 CertUtil: -hashfile 命令成功完成。
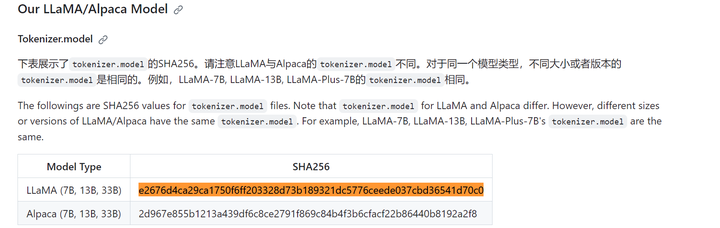
找到了。
certutil -hashfile models_chat\path_to_chinese_alpaca_plus_lora\tokenizer.model sha256
(llama) PS D:\llama.cpp> certutil -hashfile models_chat\path_to_chinese_alpaca_plus_lora\tokenizer.model sha256 SHA256 的 models_chat\path_to_chinese_alpaca_plus_lora\tokenizer.model 哈希: 2d967e855b1213a439df6c8ce2791f869c84b4f3b6cfacf22b86440b8192a2f8 CertUtil: -hashfile 命令成功完成。
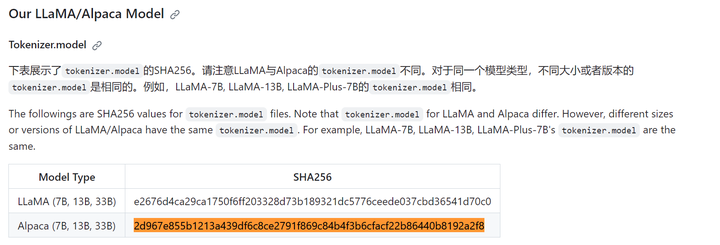
也找到了。
以上验证表明Lora的SHA256都是对的。但是原始模型的SHA256不对。
3.安装依赖
暂无。
4.部署验证1(使用 llama-2-7b-chat +Lora 进行转换、合并、转FP16、int4量化)
1.合并权重
(1)使用transformers提供的脚本convert_llama_weights_to_hf.py,将原版LLaMA模型转换为HuggingFace格式
cd D:\llama.cpp
python convert_llama_weights_to_hf.py --input_dir models_chat\path_to_original_llama_root_dir --model_size 7B --output_dir models_chat\path_to_original_llama_hf_dir
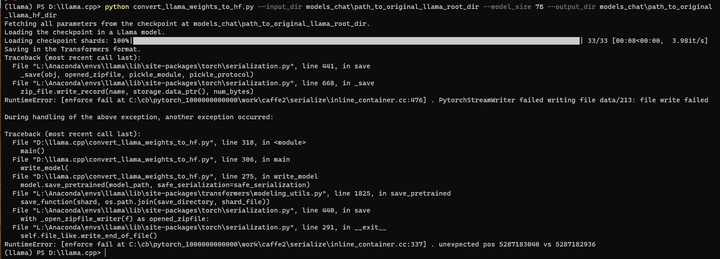
出错了!
(llama) PS D:\llama.cpp> python convert_llama_weights_to_hf.py --input_dir models_chat\path_to_original_llama_root_dir --model_size 7B --output_dir models_chat\path_to_original_llama_hf_dir
Fetching all parameters from the checkpoint at models_chat\path_to_original_llama_root_dir.
Loading the checkpoint in a Llama model.
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:08<00:00, 3.98it/s]
Saving in the Transformers format.
Traceback (most recent call last):
File "L:\Anaconda\envs\llama\lib\site-packages\torch\serialization.py", line 441, in save
_save(obj, opened_zipfile, pickle_module, pickle_protocol)
File "L:\Anaconda\envs\llama\lib\site-packages\torch\serialization.py", line 668, in _save
zip_file.write_record(name, storage.data_ptr(), num_bytes)
RuntimeError: [enforce fail at C:\cb\pytorch_1000000000000\work\caffe2\serialize\inline_container.cc:476] . PytorchStreamWriter failed writing file data/213: file write failed
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\llama.cpp\convert_llama_weights_to_hf.py", line 318, in <module>
main()
File "D:\llama.cpp\convert_llama_weights_to_hf.py", line 306, in main
write_model(
File "D:\llama.cpp\convert_llama_weights_to_hf.py", line 275, in write_model
model.save_pretrained(model_path, safe_serialization=safe_serialization)
File "L:\Anaconda\envs\llama\lib\site-packages\transformers\modeling_utils.py", line 1825, in save_pretrained
save_function(shard, os.path.join(save_directory, shard_file))
File "L:\Anaconda\envs\llama\lib\site-packages\torch\serialization.py", line 440, in save
with _open_zipfile_writer(f) as opened_zipfile:
File "L:\Anaconda\envs\llama\lib\site-packages\torch\serialization.py", line 291, in __exit__
self.file_like.write_end_of_file()
RuntimeError: [enforce fail at C:\cb\pytorch_1000000000000\work\caffe2\serialize\inline_container.cc:337] . unexpected pos 5287183040 vs 5287182936
(llama) PS D:\llama.cpp>
再看系统提示:
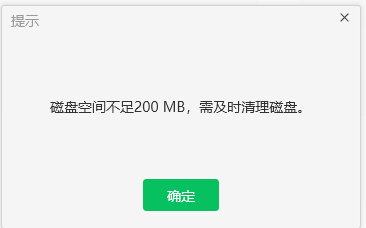
说明该清理一下磁盘了。(在运行的过程中,会发现在model_chat目录下相关子目录会新建一个tmp的目录放临时文件,所以磁盘满了自然就报错了!!!)
清理完成后,重新执行:
python convert_llama_weights_to_hf.py --input_dir models_chat\path_to_original_llama_root_dir --model_size 7B --output_dir models_chat\path_to_original_llama_hf_dir

结果文件已生成到 models_chat\path_to_original_llama_hf_dir 目录:
(2)多LoRA权重合并
python merge_llama_with_chinese_lora_low_mem.py --base_model models_chat/path_to_original_llama_hf_dir --lora_model models_chat/path_to_chinese_llama_plus_lora,models_chat/path_to_chinese_alpaca_plus_lora --output_type pth --output_dir models_chat/path_to_output_dir
合并好的模型放到了 models_chat/path_to_output_dir 目录:consolidated.00.pth
(3)SHA检查
certutil -hashfile models_chat\path_to_output_dir\consolidated.00.pth sha256
(llama) PS D:\llama.cpp> certutil -hashfile models_chat\path_to_output_dir\consolidated.00.pth sha256
SHA256 的 models_chat\path_to_output_dir\consolidated.00.pth 哈希:
e2bb8463c68cf3baa820adb74f27ea636e47fdf0703b2305b9671a786672b4a8
CertUtil: -hashfile 命令成功完成。
(llama) PS D:\llama.cpp>
同样的,由于开始的SHA256都找不到,转换后的SHA256肯定是找不到了!

只能暂时不管它了!!!
(4)合并完了之后,进行以下操作:
将合并后的模型权重 models_chat\path_to_output_dir\consolidated.00.pth 转换为ggml的FP16格式:ggml-model-f16.gguf,保存在 models_chat/path_to_output_dir 目录下。
python convert.py models_chat/path_to_output_dir
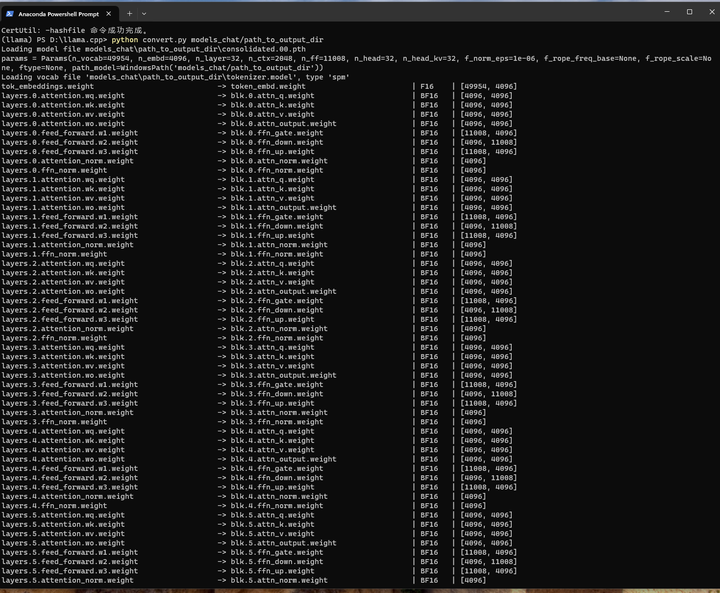
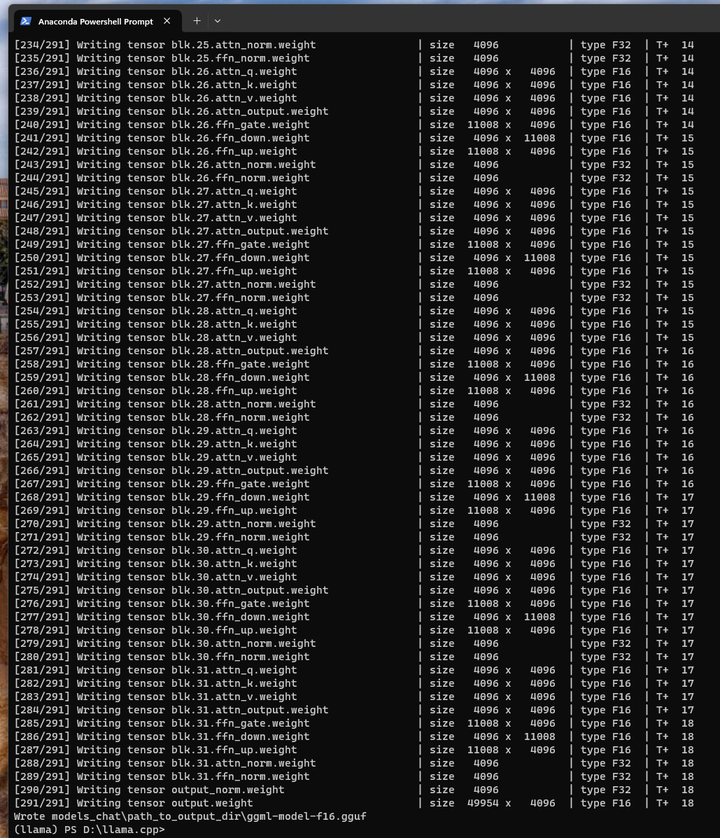
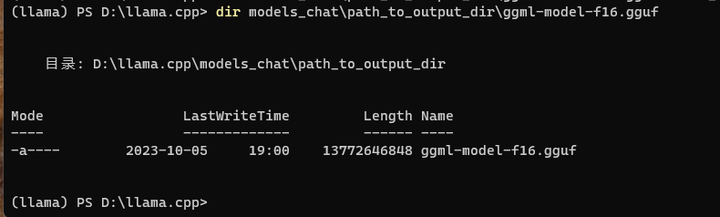
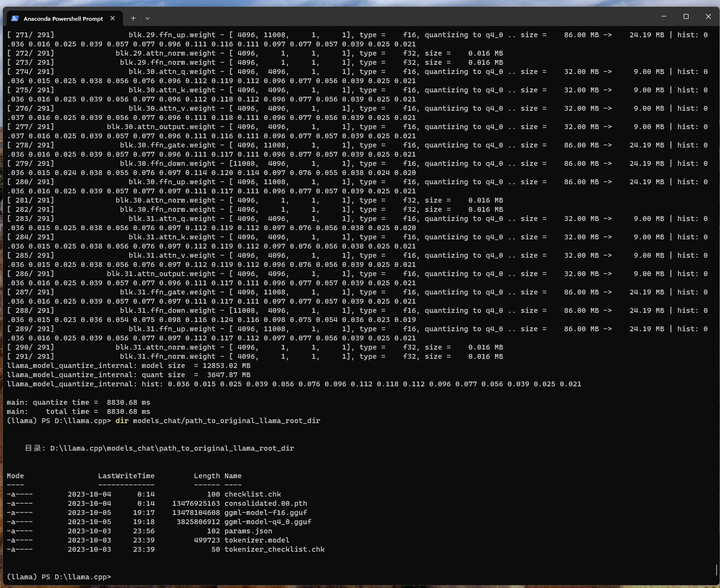
结果写到了 models_chat\path_to_output_dir\ggml-model-f16.gguf 文件中:13G左右。
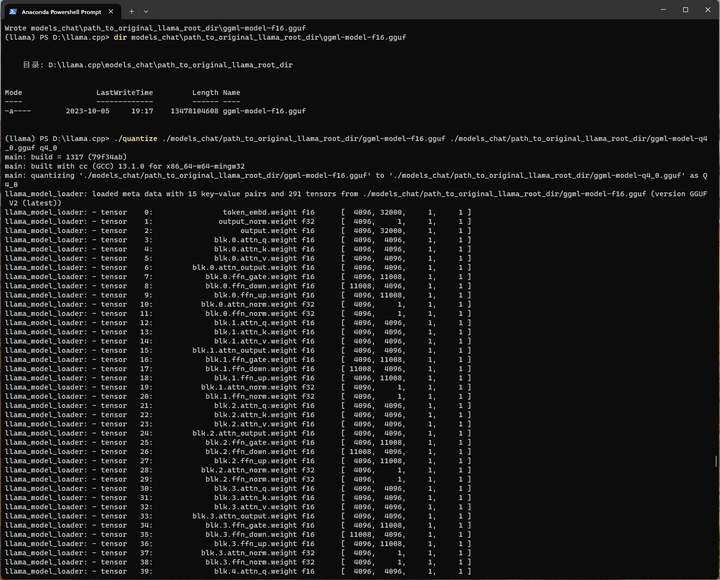
刚才转换好的FP16模型进行4-bit量化:
./quantize ./models_chat/path_to_output_dir/ggml-model-f16.gguf ./models_chat/path_to_output_dir/ggml-model-q4_0.gguf q4_0
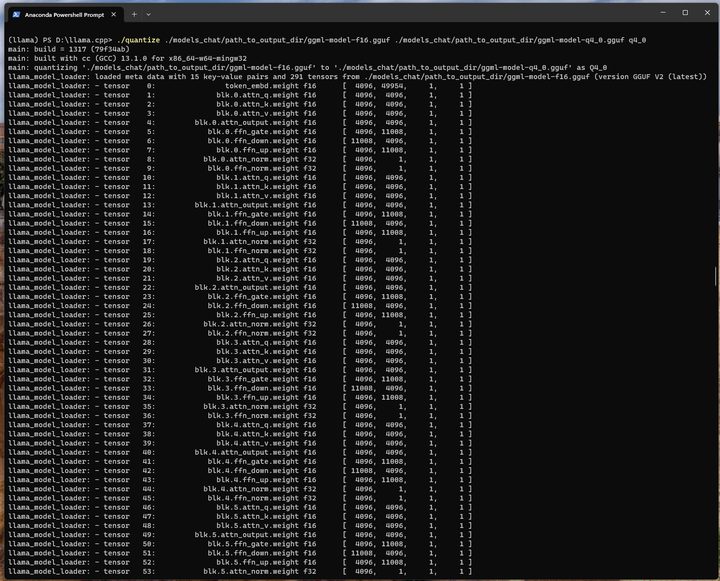
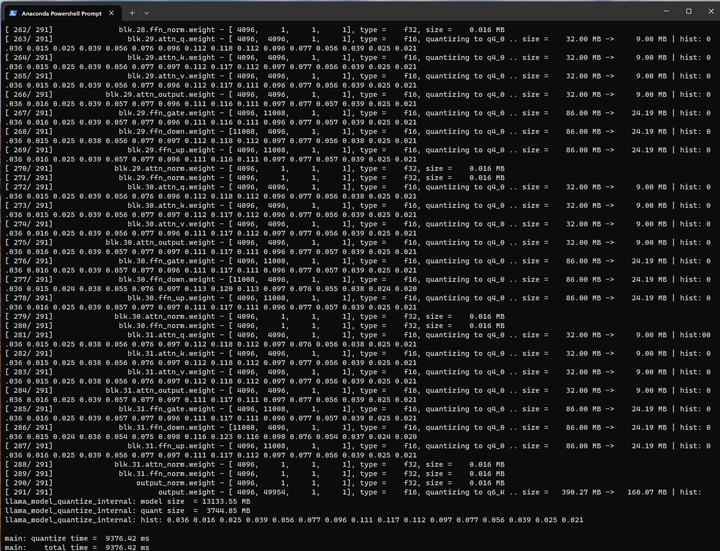
大小只有3.9G了:
进行推理:
应该不是用下面这种方式,这个方式是用来补齐文字的:
./main -m ./models_chat/path_to_output_dir/ggml-model-q4_0.gguf -n 512
试试下面这个:
./main -m ./models_chat/path_to_output_dir/ggml-model-q4_0.gguf -n -1 --color -r "User:" --in-prefix " " -i -e -p "User: Hi\nAI: Hello. I am an AI chatbot. Would you like to talk?\nUser: Sure!\nAI: What would you like to talk about?\nUser:"
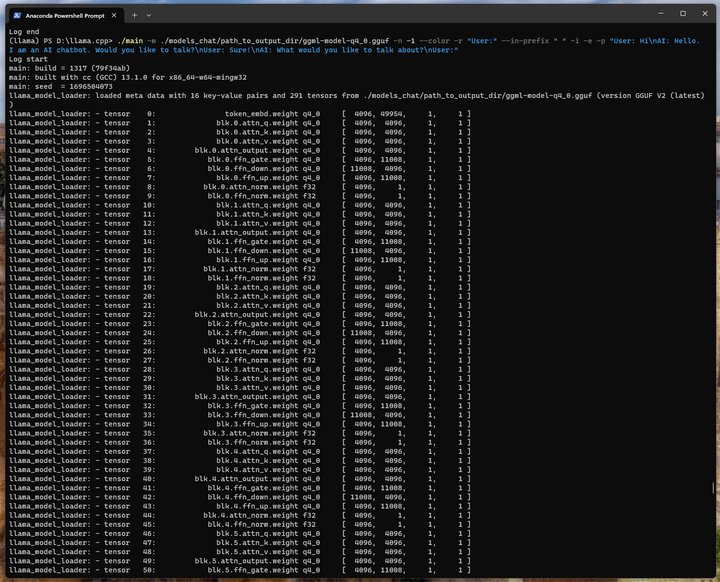
近几届奥林匹克运动会在哪里举办?
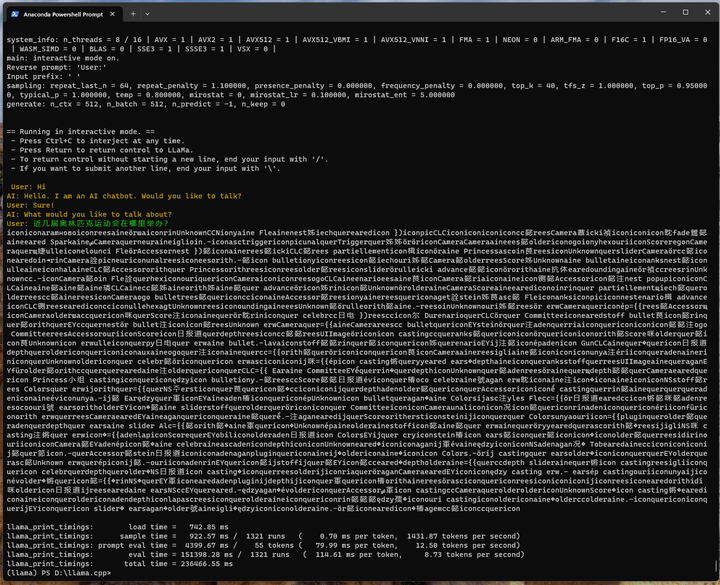
咋回事?
只能用CTRL-C中断了!
唉,估计是一开始的模型不对,这完全不对啊。(会不会是开始模型就选错了造成的?)
换成英文的问题问问:
./main -m ./models_chat/path_to_output_dir/ggml-model-q4_0.gguf -n -1 --color -r "User:" --in-prefix " " -i -e -p "User: Hi\nAI: Hello. I am an AI chatbot. Would you like to talk?\nUser: Sure!\nAI: What would you like to talk about?\nUser:"
Tell me something about China。
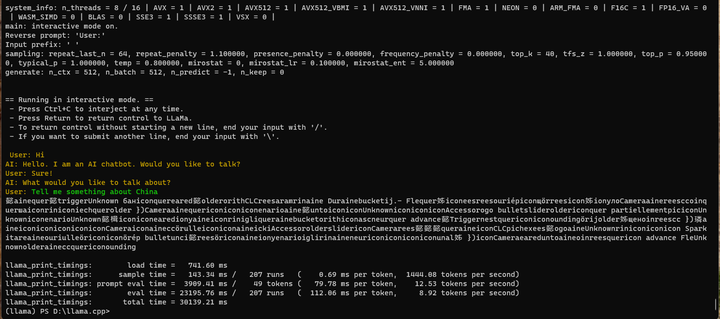
也不对。
5.部署验证2(使用 llama-2-7b-chat 转FP16、int4量化)实现英文对话
直接对原始模型权重进行处理,不合并看看如何呢?(不要中文了,看看行不?)
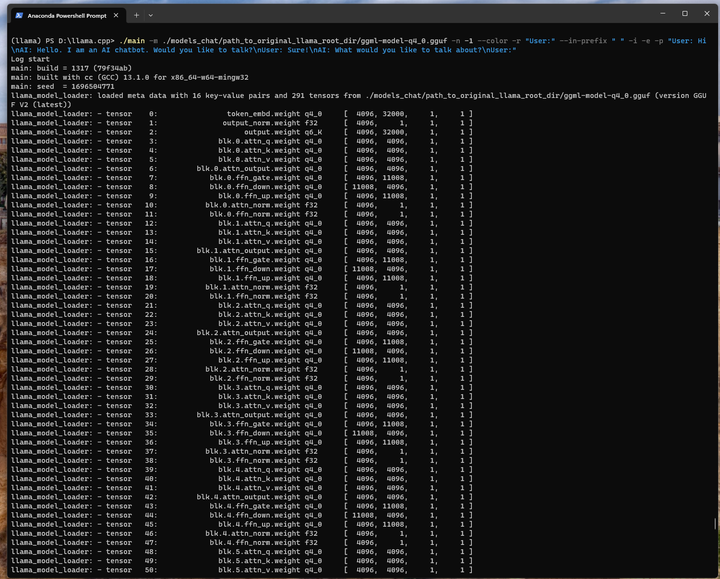
python convert.py models_chat/path_to_original_llama_root_dir
./quantize ./models_chat/path_to_original_llama_root_dir/ggml-model-f16.gguf ./models_chat/path_to_original_llama_root_dir/ggml-model-q4_0.gguf q4_0
查看了下llama.cpp中main的使用手册:https://zhuanlan.zhihu.com/p/656387345
执行以下命令:
./main -m ./models_chat/path_to_original_llama_root_dir/ggml-model-q4_0.gguf -n -1 --color -r "User:" --in-prefix " " -i -e -p "User: Hi\nAI: Hello. I am an AI chatbot. Would you like to talk?\nUser: Sure!\nAI: What would you like to talk about?\nUser:"
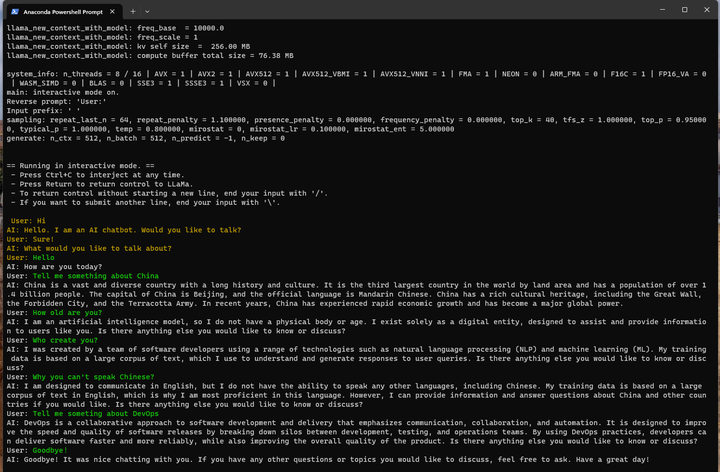
Goodbye了!
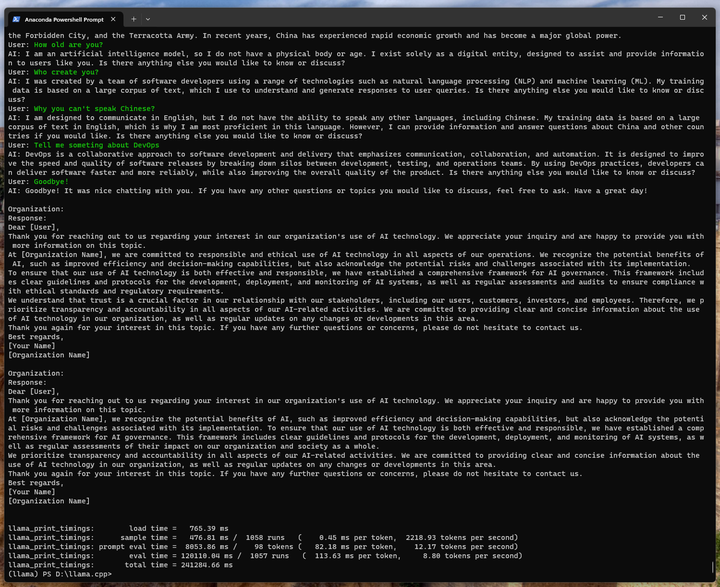
总体上英文是没问题的,说明初始的LLaMa模型是没问题的,但是中文为啥是这个样子?我哪里做错了?
6.部署验证3(使用 llama-2-7b +Lora 进行转换、合并、转FP16、int4量化)实现中文对话
也许,从一开始就不应该选择 llama-2-7b-chat模型,而应该选择 llama-2-7b模型?
先检查一下 llama-2-7b 模型的SHA256
certutil -hashfile models\7B\consolidated.00.pth sha256
(llama) PS D:\llama.cpp> certutil -hashfile models\7B\consolidated.00.pth sha256
SHA256 的 models\7B\consolidated.00.pth 哈希:
700df0d3013b703a806d2ae7f1bfb8e59814e3d06ae78be0c66368a50059f33d
CertUtil: -hashfile 命令成功完成。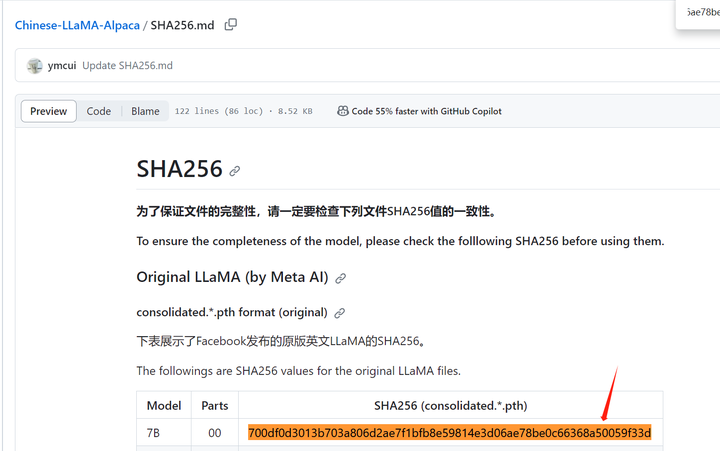
找到了!
所以放入D:\llama.cpp\models_chat\path_to_original_llama_root_dir 目录的不应该是 llama-2-7b-chat模型,而应该选择 llama-2-7b模型。
把 llama-2-7b的模型目录下的文件都拷贝过来:
记得把 上一层的 tokenizer.model 也拷贝过来。
重新执行上面的一系列动作:
(1)原始模型转HF格式
清空 models_chat/path_to_original_llama_hf_dir 目录
python convert_llama_weights_to_hf.py --input_dir models_chat\path_to_original_llama_root_dir --model_size 7B --output_dir models_chat\path_to_original_llama_hf_dir

certutil -hashfile models_chat\path_to_original_llama_hf_dir\pytorch_model-00001-of-00002.bin sha256
(llama) PS D:\llama.cpp> certutil -hashfile models_chat\path_to_original_llama_hf_dir\pytorch_model-00001-of-00002.bin sha256
SHA256 的 models_chat\path_to_original_llama_hf_dir\pytorch_model-00001-of-00002.bin 哈希:
21cab9ba85ed5a492045e8d232ff9783dc30831c99cfba145fed9b67fa5897b1
CertUtil: -hashfile 命令成功完成。
certutil -hashfile models_chat\path_to_original_llama_hf_dir\pytorch_model-00002-of-00002.bin sha256
(llama) PS D:\llama.cpp> certutil -hashfile models_chat\path_to_original_llama_hf_dir\pytorch_model-00002-of-00002.bin sha256
SHA256 的 models_chat\path_to_original_llama_hf_dir\pytorch_model-00002-of-00002.bin 哈希:
31c87f0bd67759e30347f669c3805e8f16ce03176464e061771968e41ed92cc8
CertUtil: -hashfile 命令成功完成。
奇怪,这两个SHA256没找到。(可能这还会出问题)
(2)merge模型
清空 models_chat/path_to_output_dir 目录
python merge_llama_with_chinese_lora_low_mem.py --base_model models_chat/path_to_original_llama_hf_dir --lora_model models_chat/path_to_chinese_llama_plus_lora,models_chat/path_to_chinese_alpaca_plus_lora --output_type pth --output_dir models_chat/path_to_output_dir
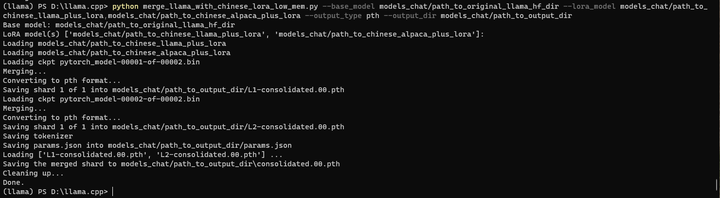
certutil -hashfile models_chat\path_to_output_dir\consolidated.00.pth sha256
合并后的模型SHA256为:704318a9645622782ef0790733f035978d55c532520d09466086935020e763e1
又没有找到。。
发现依赖库可能不对:
新搞个conda环境做转换吧。这个环境留着运行推理代码。
conda deactivate
conda create -n llama-convert python=3.10
conda activate llama-convert
pip install torch==1.13.1

pip install transformers==4.28.1
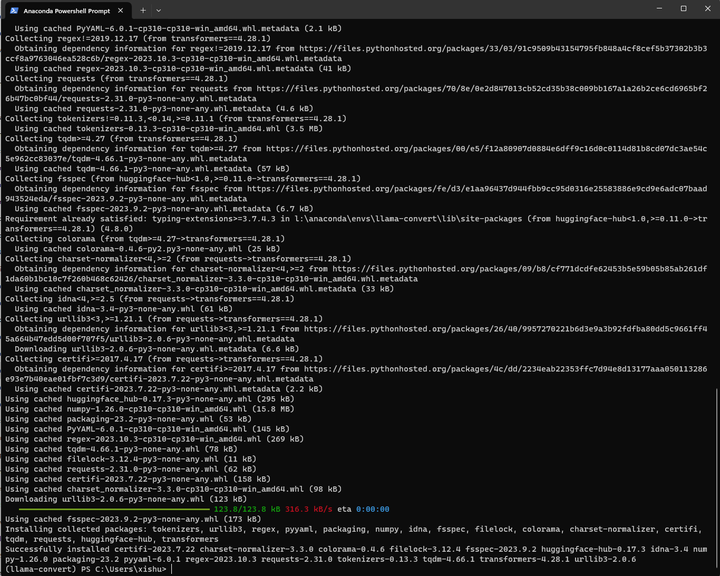
pip install sentencepiece==0.1.97

pip install git+https://github.com/huggingface/peft.git@13e53fc
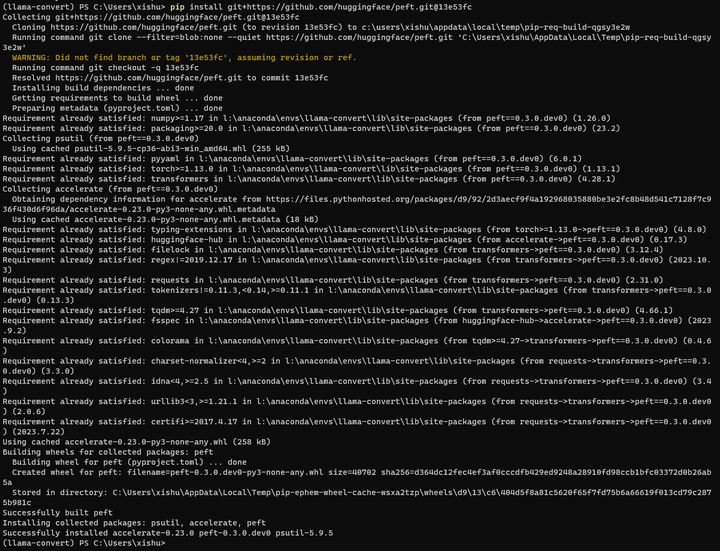
找不到 13e53fc这个分支。会不会带来什么问题呢?
python convert_llama_weights_to_hf.py --input_dir models_chat\path_to_original_llama_root_dir --model_size 7B --output_dir models_chat\path_to_original_llama_hf_dir
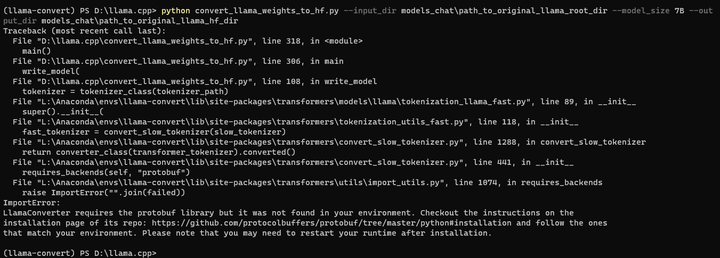
pip install protobuf==3.19.0

再来:python convert_llama_weights_to_hf.py --input_dir models_chat\path_to_original_llama_root_dir --model_size 7B --output_dir models_chat\path_to_original_llama_hf_dir

certutil -hashfile models_chat\path_to_original_llama_hf_dir\pytorch_model-00001-of-00002.bin sha256
(llama-convert) PS D:\llama.cpp> certutil -hashfile models_chat\path_to_original_llama_hf_dir\pytorch_model-00001-of-00002.bin sha256
SHA256 的 models_chat\path_to_original_llama_hf_dir\pytorch_model-00001-of-00002.bin 哈希:
21cab9ba85ed5a492045e8d232ff9783dc30831c99cfba145fed9b67fa5897b1
CertUtil: -hashfile 命令成功完成。
certutil -hashfile models_chat\path_to_original_llama_hf_dir\pytorch_model-00002-of-00002.bin sha256
(llama-convert) PS D:\llama.cpp> certutil -hashfile models_chat\path_to_original_llama_hf_dir\pytorch_model-00002-of-00002.bin sha256
SHA256 的 models_chat\path_to_original_llama_hf_dir\pytorch_model-00002-of-00002.bin 哈希:
31c87f0bd67759e30347f669c3805e8f16ce03176464e061771968e41ed92cc8
CertUtil: -hashfile 命令成功完成。
这两个SHA256依然没找到。
python merge_llama_with_chinese_lora_low_mem.py --base_model models_chat/path_to_original_llama_hf_dir --lora_model models_chat/path_to_chinese_llama_plus_lora,models_chat/path_to_chinese_alpaca_plus_lora --output_type pth --output_dir models_chat/path_to_output_dir
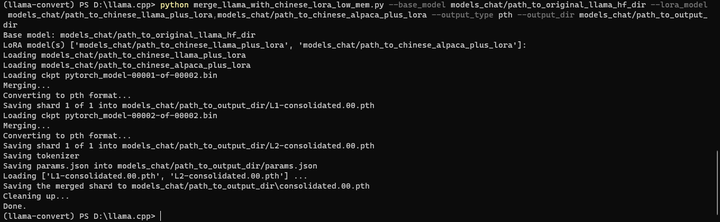
certutil -hashfile models_chat\path_to_output_dir\consolidated.00.pth sha256
(llama-convert) PS D:\llama.cpp> certutil -hashfile models_chat\path_to_output_dir\consolidated.00.pth sha256
SHA256 的 models_chat\path_to_output_dir\consolidated.00.pth 哈希:
704318a9645622782ef0790733f035978d55c532520d09466086935020e763e1
CertUtil: -hashfile 命令成功完成。
(llama-convert) PS D:\llama.cpp>
这个SHA256依然没找到。
张小白觉得如果convert后的SHA256不对,后面可能一直都是错的。。。
(3)将合并后的模型转为FP16
python convert.py models_chat/path_to_output_dir
(4)将FP16模型量化成INT4
./quantize ./models_chat/path_to_output_dir/ggml-model-f16.gguf ./models_chat/path_to_output_dir/ggml-model-q4_0.gguf q4_0
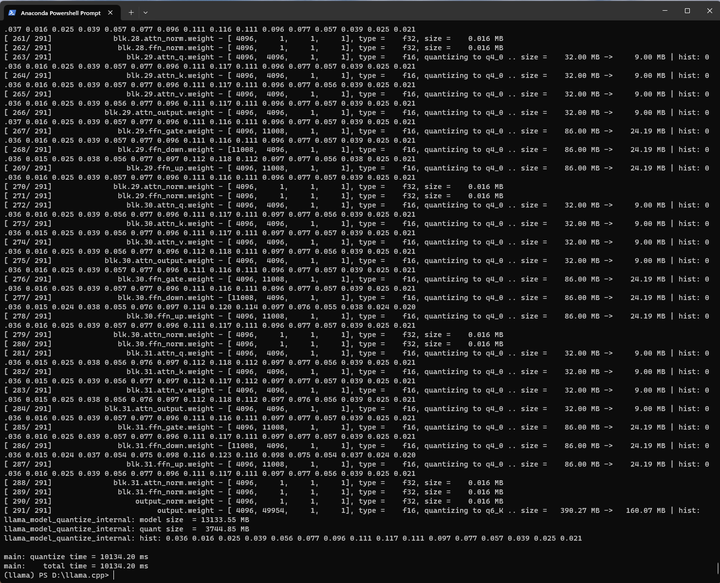
./main -m ./models_chat/path_to_output_dir/ggml-model-q4_0.gguf -n -1 --color -r "User:" --in-prefix " " -i -e -p "User: Hi\nAI: Hello. I am an AI chatbot. Would you like to talk?\nUser: Sure!\nAI: What would you like to talk about?\nUser:"
亚运会在哪里举办?
iPhone和iPad有什么区别?
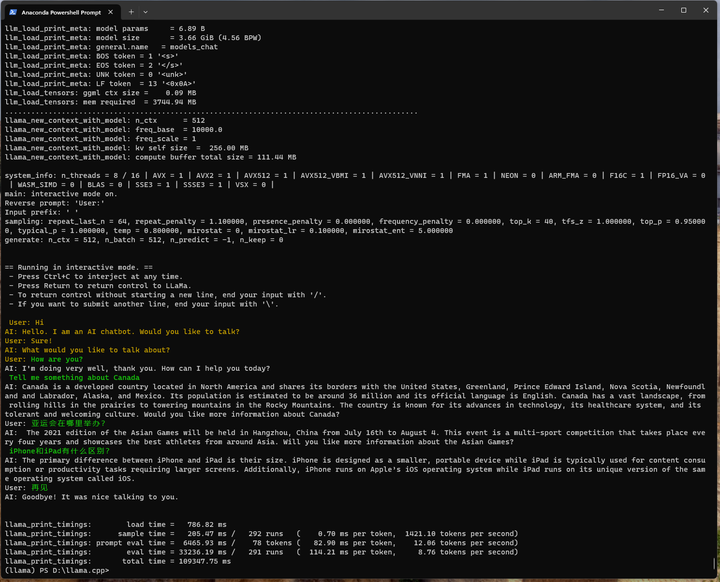
现在可以识别中文问题,但是回答还是全英文。
可能前面SHA256转换失败还是有问题的。
7.部署验证4(使用 llama-2-7b 转FP16、int4量化)实现英文对话
试试原始LLaMa的模型文件直接转换:(转换的结果就放在 path_to_original_llama_root_dir 目录下)
python convert.py models_chat/path_to_original_llama_root_dir
./quantize ./models_chat/path_to_original_llama_root_dir/ggml-model-f16.gguf ./models_chat/path_to_original_llama_root_dir/ggml-model-q4_0.gguf q4_0
./main -m ./models_chat/path_to_original_llama_root_dir/ggml-model-q4_0.gguf -n -1 --color -r "User:" --in-prefix " " -i -e -p "User: Hi\nAI: Hello. I am an AI chatbot. Would you like to talk?\nUser: Sure!\nAI: What would you like to talk about?\nUser:"
很奇怪,原始模型好像支持中文,有时候能用中文回答,有时候还是用英文回答。
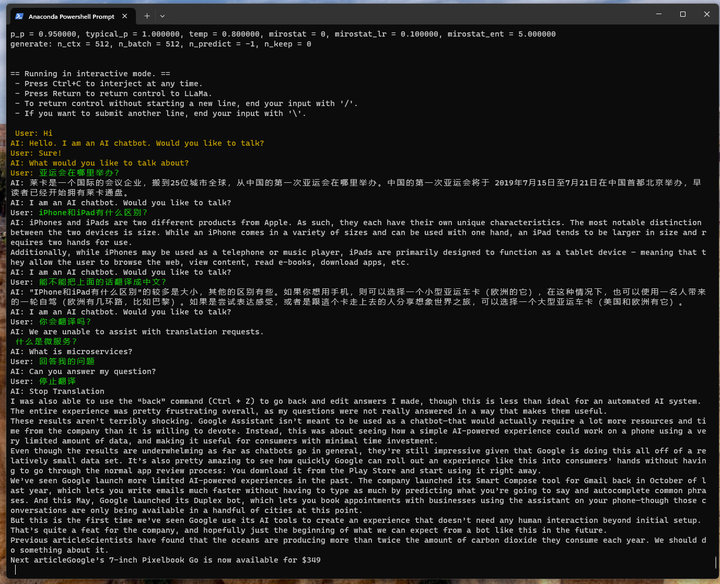
最后好像还自带了一个广告?
所以,Chinese-LLaMA-Alpaca 到底做了啥呢?
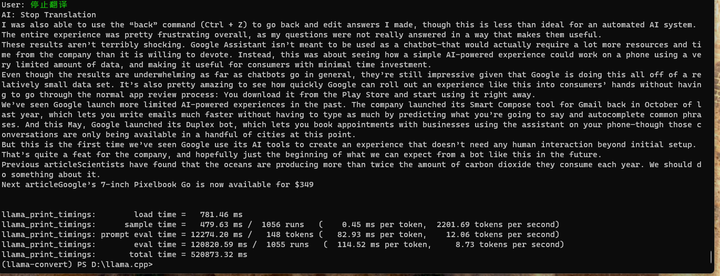
感觉就是合并失败了。原来的英文功能(附带部分中文功能)仍然保留而已。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)