大模型部署手记(9)LLaMa2+Chinese-LLaMA-Plus-7B+Windows+llama.cpp+中文文本补齐

【摘要】 大模型部署手记(9)LLaMa2+Chinese-LLaMA-Plus-7B+Windows+llama.cpp+中文文本补齐

1.简介:
组织机构:Meta(Facebook)
代码仓:https://github.com/facebookresearch/llama
模型:llama-2-7b、Chinese-LLaMA-Plus-7B(chinese_llama_plus_lora_7b)
下载:使用download.sh下载
硬件环境:暗影精灵7Plus
Windows版本:Windows 11家庭中文版 Insider Preview 22H2
内存 32G
GPU显卡:Nvidia GTX 3080 Laptop (16G)
在 https://bbs.huaweicloud.com/blogs/412529 一文中,张小白完成了基于原始 llama-2-7b 模型的文本补齐。这个模型只有英文问答,但是勤劳的中国人肯定不会局限于此的。
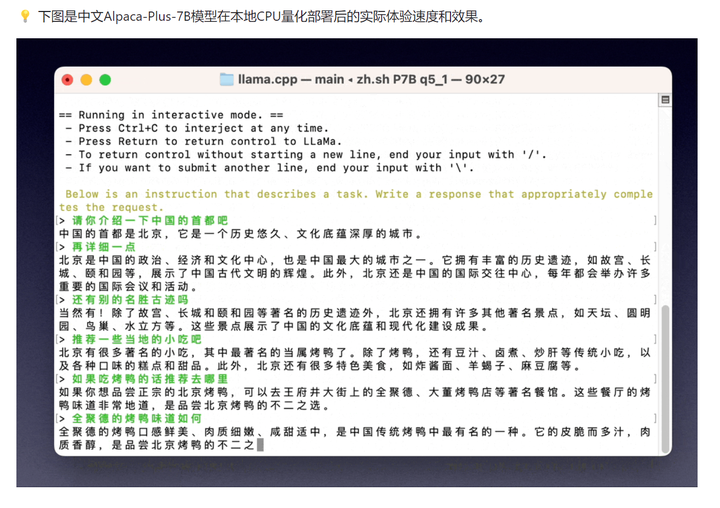
可以看到诱人的中文对话:
在这里可以看到 Chinese-LLaMA-Alpaca 的家族图谱关系:
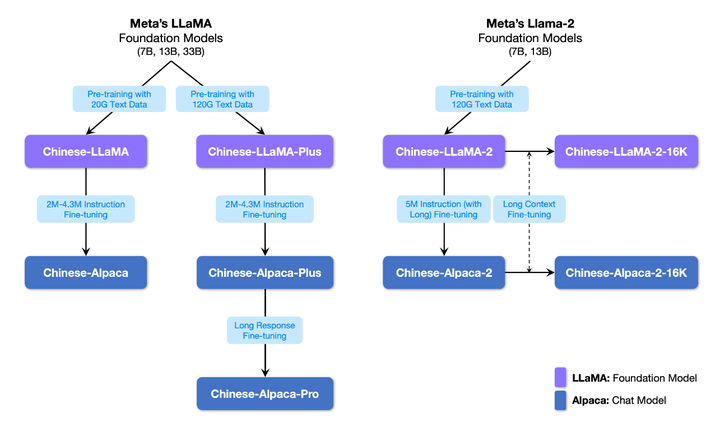
其中,LLaMA模型是基础模型,主打“文本补齐”(给定上文内容,让模型生成下文),Alpaca是对话模型,主打“文本对话”(指令理解:问答、写作、建议;多轮上下文理解:聊天)

而模型类型的命名跟手机后缀差不多,分为基础版、Plus版和Pro版。例如对于Alpaca模型,plus偏向于短回复,pro偏向于对过短的回复进行改进。从名字可以看出,可以根据自己的经济能力(显卡内存和算力)选择适当的版本。
而一个中文模型的生成过程是这样的:
1、先去Meta官网申请原版的LLaMa模型(需要到官网申请授权,并通过邮箱获取URL,然后使用download.sh下载)
2、从 https://github.com/ymcui/Chinese-LLaMA-Alpaca 提供的链接下载 原版模型对应的Lora模型
3、进行模型合并:(参考 https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/%E6%89%8B%E5%8A%A8%E6%A8%A1%E5%9E%8B%E5%90%88%E5%B9%B6%E4%B8%8E%E8%BD%AC%E6%8D%A2 )
(1)使用transformers提供的脚本convert_llama_weights_to_hf.py,将原版LLaMA模型转换为HuggingFace格式,举例如下:
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir path_to_original_llama_root_dir \
--model_size 7B \
--output_dir path_to_original_llama_hf_dir
(2)对原版LLaMA模型(HF格式)扩充中文词表,合并LoRA权重并生成全量模型权重,这时可以选择pyTorch版本权重(.pth文件)或者输出HuggingFace版本权重(.bin文件)。对于llama.cpp部署,应转为pth文件。
(a)对于基座模型,采用单LoRA权重合并方式 ( Chinese-LLaMA, Chinese-LLaMA-Plus, Chinese-Alpaca)
python scripts/merge_llama_with_chinese_lora_low_mem.py \
--base_model path_to_original_llama_hf_dir \
--lora_model path_to_chinese_llama_or_alpaca_lora \
--output_type [pth|huggingface] \
--output_dir path_to_output_dir
(b)对于对话模型,采用多LoRA权重合并方式( Chinese-LLaMA, Chinese-LLaMA-Plus, Chinese-Alpaca)
python scripts/merge_llama_with_chinese_lora_low_mem.py \
--base_model path_to_original_llama_hf_dir \
--lora_model path_to_chinese_llama_plus_lora,path_to_chinese_alpaca_plus_lora \
--output_type [pth|huggingface] \
--output_dir path_to_output_dir
其中lora_model的模型顺序为先LLaMA,后Alpaca,比如 先LLaMA-Plus-LoRA后Alpaca-Plus/Pro-LoRA
(3)对合并后的模型进行SHA256检查
根据 https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/SHA256.md 提供的表格检查SHA256值的一致性。
windows的SHA256检查方法是:
certutil -hashfile your-model-file sha256
Linux的SHA256检查方法是:
sha256sum your-model-file
参考资料:【LLM】Windows本地CPU部署民间版中文羊驼模型(Chinese-LLaMA-Alpaca)踩坑记录 https://blog.csdn.net/qq_38238956/article/details/130113599
2.代码和模型下载:
llama.cpp 代码仓按照 https://bbs.huaweicloud.com/blogs/412529 一文的方式下载。
Chinese-LLaMA-Alpaca的代码仓:
d:
cd \
git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca
cd Chinese-LLaMA-Alpaca
1.原版的LLaMa模型
已经在 https://bbs.huaweicloud.com/blogs/412406 讲了具体步骤。
在上次的 https://bbs.huaweicloud.com/blogs/412529 一文中,原版的LLaMa-7B模型已经被放到了 D:\llama.cpp\models\7B 目录下:
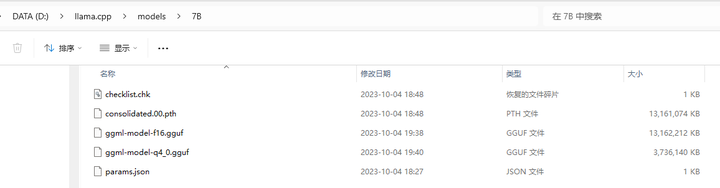
2.原版模型对应的Lora模型
根据 https://github.com/ymcui/Chinese-LLaMA-Alpaca#%E6%8E%A8%E8%8D%90%E6%A8%A1%E5%9E%8B%E4%B8%8B%E8%BD%BD 提供的 模型推荐清单,原版LLaMa-7B对应的基座模型只有 Chinese-LLaMA-Plus-7B:
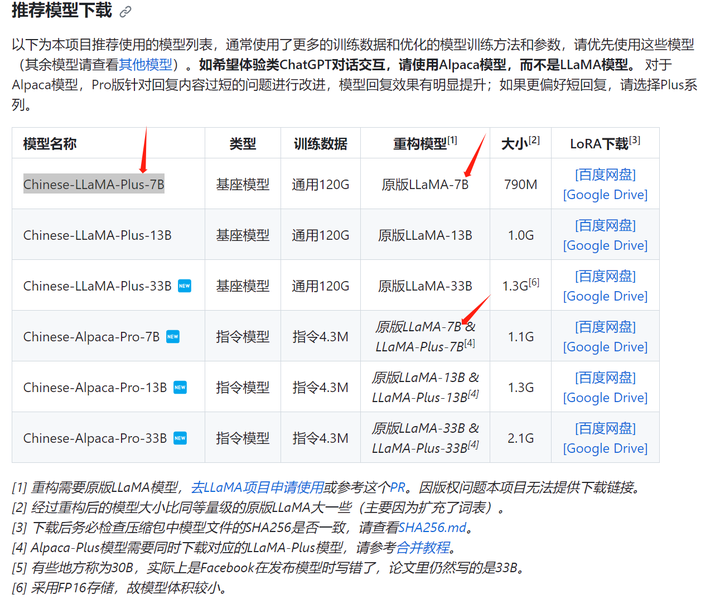
点击链接 https://pan.baidu.com/s/1zvyX9FN-WSRDdrtMARxxfw?pwd=2gtr 下载百度网盘的压缩包:chinese-alpaca-lora-7b.zip

将其解压到D:\llama.cpp\models 目录:注意由于zip不带目录,使用压缩软件解压时要选择 解压到chinese-alpaca-lora-7b
3.安装依赖
cd Chinese-LLaMA-Alpaca
其中合并的脚本merge_llama_with_chinese_lora.py 在 D:\Chinese-LLaMA-Alpaca\scripts 目录下:
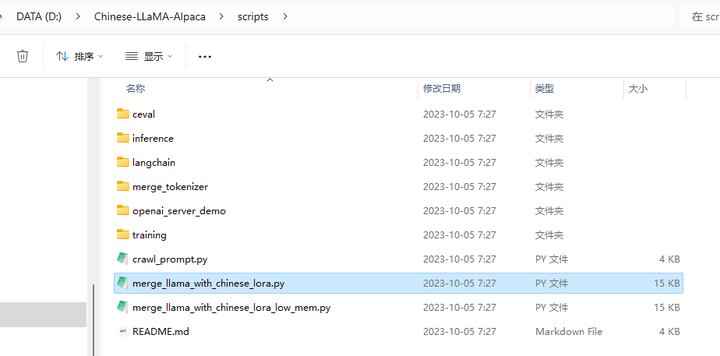
可将其复制到 d:\llama.cpp 目录:
将 scripts/merge_llama_with_chinese_lora_low_mem.py 文件也复制过来:
保存到 d:\llama.cpp 目录
4.部署验证
打开Anaconda Powershell Prompt
conda activate llama
在models目录下,创建以下几个目录:
- path_to_original_llama_hf_dir 转换好的HF版模型权重
- path_to_output_dir 合并后的模型权重
- 7B目录相当于 path_to_original_llama_root_dir
- chinese_llama_plus_lora_7b 目录相当于 path_to_chinese_llama_or_alpaca_lora
在7B目录下,上次是将 原始模型转换成了 ggml-model-f16.gguf,并int4量化成了 ggml-model-q4_0.gguf
(1)使用transformers提供的脚本convert_llama_weights_to_hf.py,将原版LLaMA模型转换为HuggingFace格式
cd D:\llama.cpp
python convert_llama_weights_to_hf.py --input_dir models/7B --model_size 7B --output_dir path_to_original_llama_hf_dir
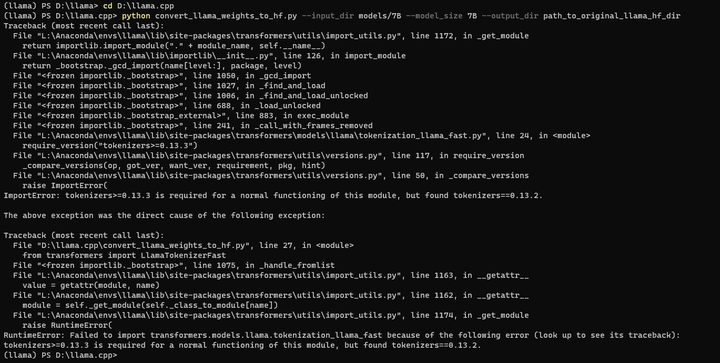
pip install tokenizers==0.13.3
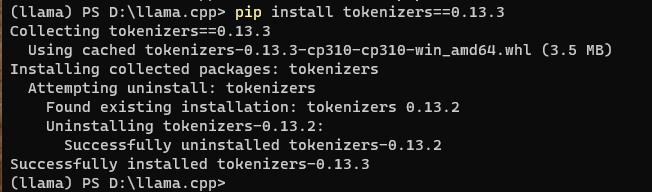
再来:
python convert_llama_weights_to_hf.py --input_dir models/7B --model_size 7B --output_dir path_to_original_llama_hf_dir
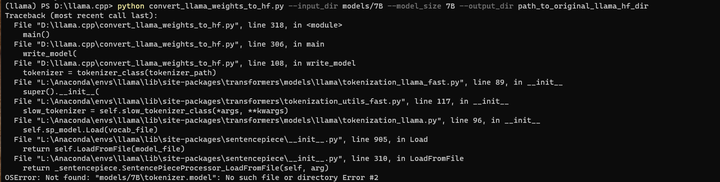
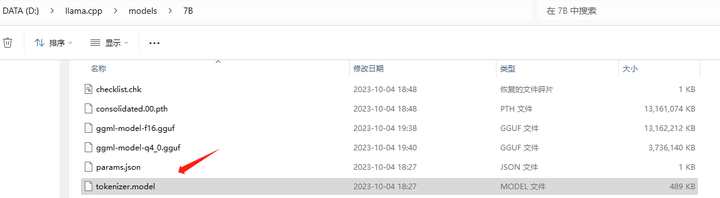
将7B上层目录的 tokenizer.model 复制到 models/7B目录下:
再来:
python convert_llama_weights_to_hf.py --input_dir models/7B --model_size 7B --output_dir path_to_original_llama_hf_dir
这个需要耐心等待一会儿。

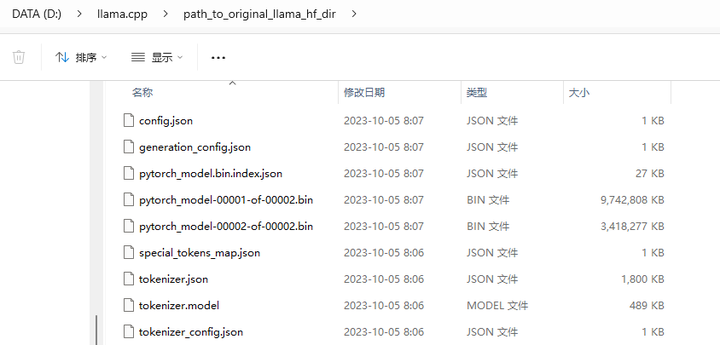
不好意思,目的目录应该是 models/path_to_original_llama_hf_dir
将结果挪过去吧!
mv path_to_original_llama_hf_dir/* models/path_to_original_llama_hf_dir/
rmdir path_to_original_llama_hf_dir

(2)单LoRA权重合并
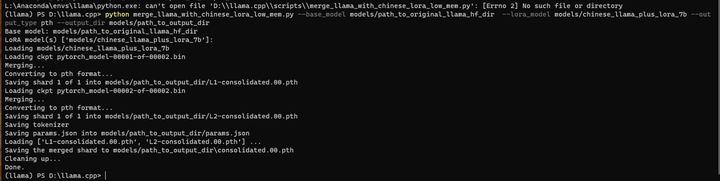
python merge_llama_with_chinese_lora_low_mem.py --base_model models/path_to_original_llama_hf_dir --lora_model models/chinese_llama_plus_lora_7b --output_type pth --output_dir models/path_to_output_dir
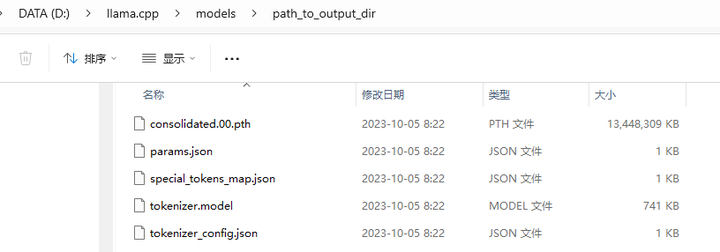
合并好的模型放到了 models/path_to_output_dir 目录:
(3)SHA检查
certutil -hashfile models\path_to_output_dir\consolidated.00.pth sha256

找不到这个SHA256值。。。
原版pth的SHA256:
certutil -hashfile models\7B\consolidated.00.pth sha256

这个SHA256可以找到:
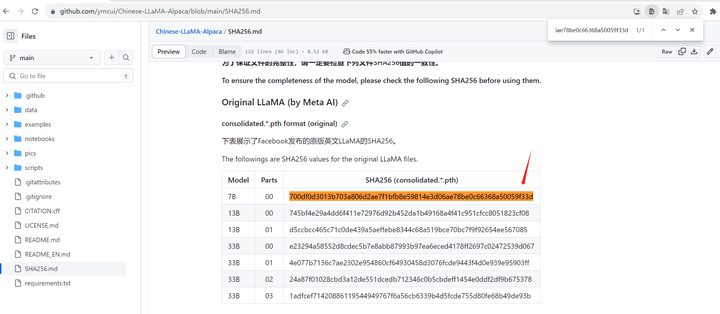
Lora Tokenizer.model SHA256:
certutil -hashfile models\chinese_llama_plus_lora_7b\tokenizer.model sha256
(llama) PS D:\llama.cpp> certutil -hashfile models\chinese_llama_plus_lora_7b\tokenizer.model sha256
SHA256 的 models\chinese_llama_plus_lora_7b\tokenizer.model 哈希:
e2676d4ca29ca1750f6ff203328d73b189321dc5776ceede037cbd36541d70c0
CertUtil: -hashfile 命令成功完成。
(llama) PS D:\llama.cpp>
这个SHA256可以找到:
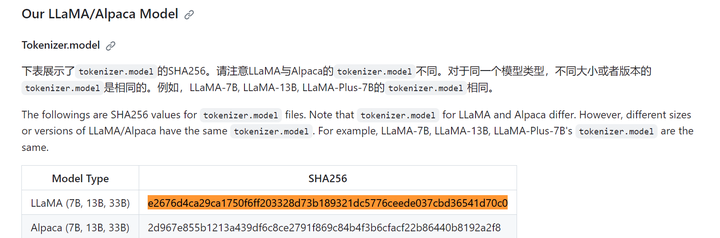
Lora权重 adapter_model.bin SHA256:
certutil -hashfile models\chinese_llama_plus_lora_7b\adapter_model.bin sha256
(llama) PS D:\llama.cpp> certutil -hashfile models\chinese_llama_plus_lora_7b\adapter_model.bin sha256
SHA256 的 models\chinese_llama_plus_lora_7b\adapter_model.bin 哈希:
8c928db86b2a0cf73f019832f921eb7e1e069ca21441b4bfa12c4381c6cc46be
CertUtil: -hashfile 命令成功完成。
(llama) PS D:\llama.cpp>
这个SHA256可以找到:
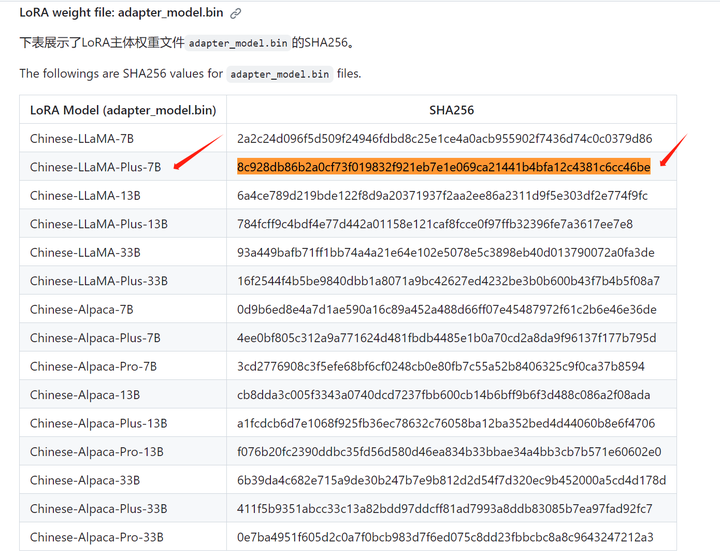
那就是合并之后的模型权重文件不对吗?张小白也不知道。。。
(4)合并完了之后,进行以下操作:
将合并后的模型权重 models\path_to_output_dir\consolidated.00.pth 转换为ggml的FP16格式:ggml-model-f16.gguf,保存在 models/path_to_output_dir 目录下。
python convert.py models/path_to_output_dir
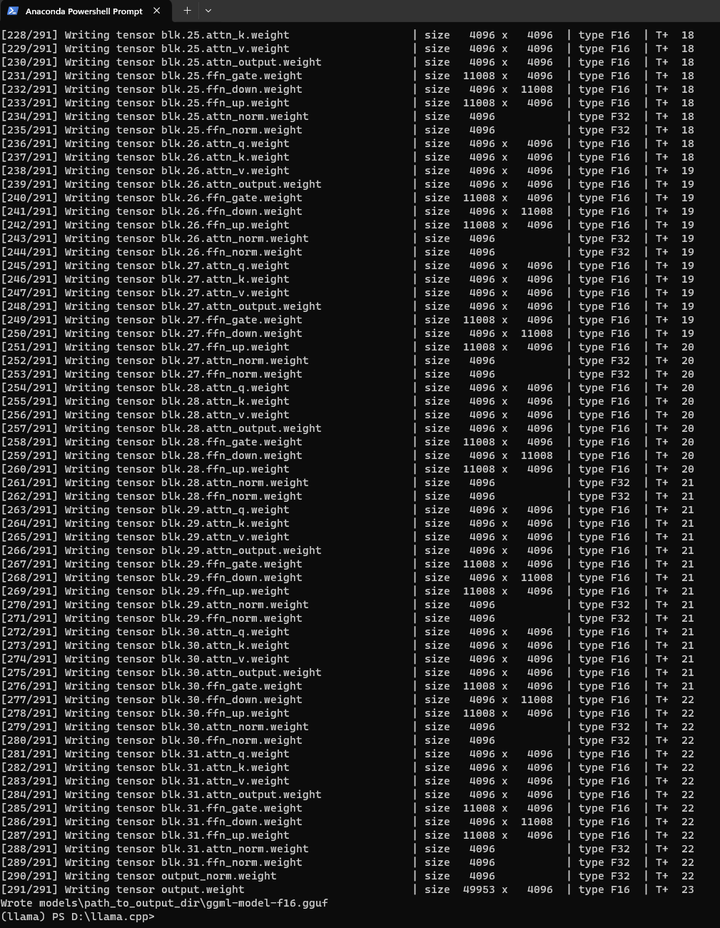
结果写到了 models\path_to_output_dir\ggml-model-f16.gguf 文件中:13G左右。
刚才转换好的FP16模型进行4-bit量化:
./quantize ./models/path_to_output_dir/ggml-model-f16.gguf ./models/path_to_output_dir/ggml-model-q4_0.gguf q4_0
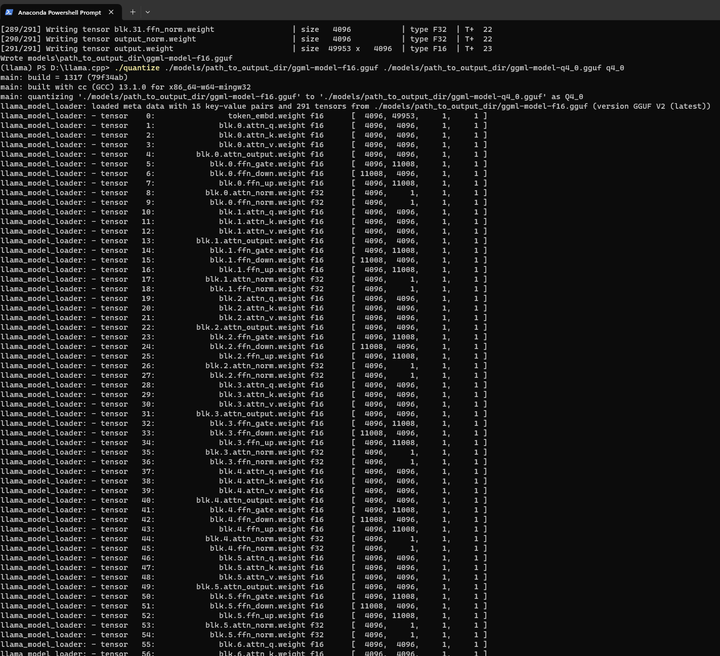
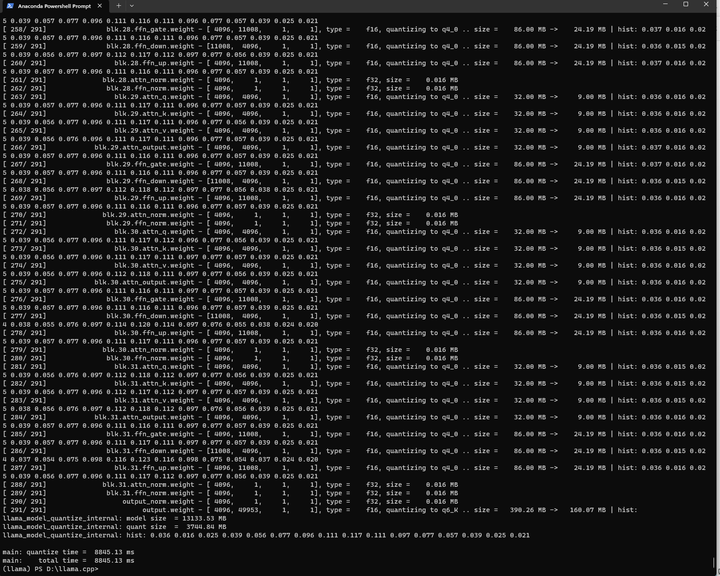
大小只有3.8G了。
进行推理:
./main -m ./models/path_to_output_dir/ggml-model-q4_0.gguf -n 512 --prompt "我给大家介绍一下加拿大"
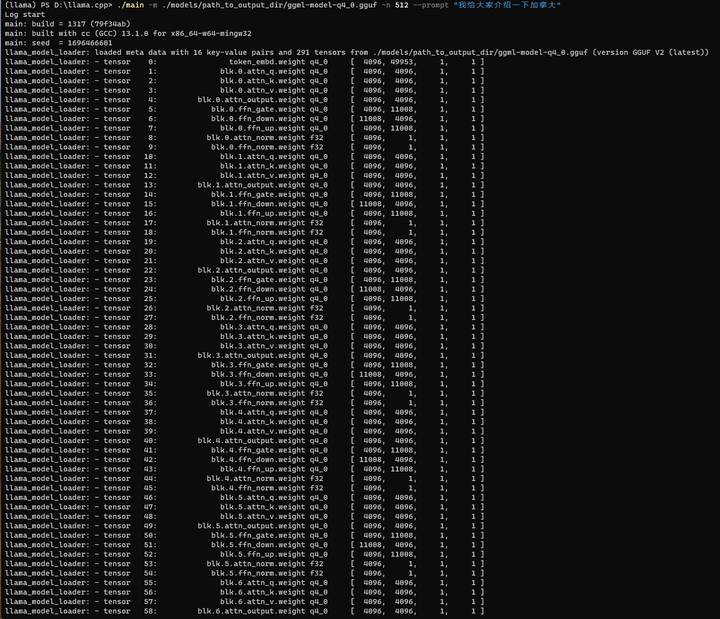
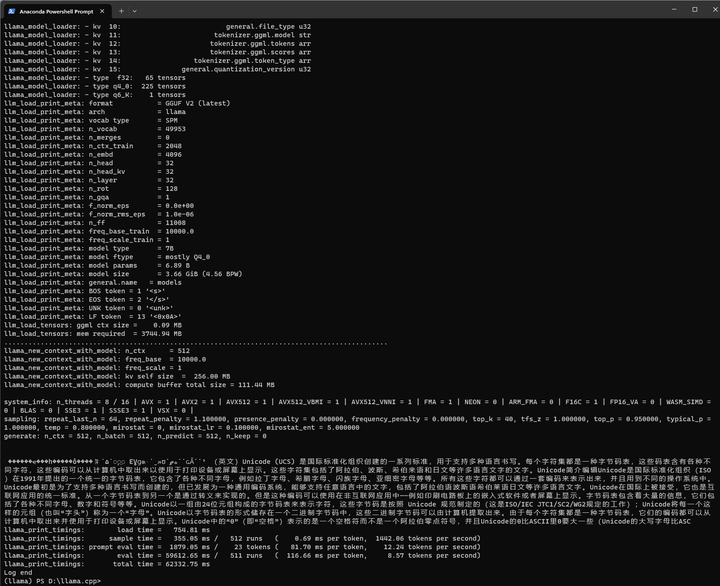
好像有点不大对头。但是中文确实生成了。
./main -m ./models/path_to_output_dir/ggml-model-q4_0.gguf -n 128 --prompt "Tell me something about Canada"
我知道了,提示词可能需要是是英文。
结果如下:
Tell me something about Canada Day. 我说... 加拿大的节日!Canada Day是2011年4月29日,为庆祝加拿大的国家日。在各省市与英联邦国家之间,节日日期会因各省市的不同而有所差异;因此,各省市也有不同的名称来表示该节日,例如:阿尔伯塔省的“NationalDay”、安大略省的“CanadaDay”等。每年4月29日在各省市庆祝加拿大国家日的时候,都会举行各种娱乐活动、庆典活动、游行活动 等等,以示对国家的重视与喜爱。而在4月29
放长一点:
./main -m ./models/path_to_output_dir/ggml-model-q4_0.gguf -n 512 --prompt "Tell me something about Canada"
结果如下:
Tell me something about Canada (Canada) (2016-04-23) [已完结] 故事背景是二战时的日本,有位年事已高的老人,名叫小林。他以一种特殊的方式记起了自己的生活,这个老男人的记忆和想象 是如此丰富、奇幻又如此可信!小林说:“我从那时起就生活在我的记忆里。”故事中老… 无题书评(2015-11-23) 作者: 阿尔布雷思·希茨 出版社: 四川文艺 语言: 中文 简体字 初版:2012年04月 / 新版:2015年09月 本书以1925-1950年间发生在中国上海及长江中游地区,对中国历史和文化的研究者而言,无疑是一个极富史料价值的宝库。本书共分五卷,第一卷《白俄罗斯》、第二卷《克里木》、第三卷《… 无题书评(2015-11-23) 作者: 周天仇 / 高培夫 出版社: 上海人民 语言: 中国语系 (包括汉语、繁体中文、粤语、吴语等) 小说《北京,我爱你》是中国作家周天仇和歌手高培夫的合作作品。这是继2013年两人共同出版的小说《中国大… 无题书评(2015-11-23) 作者: 艾伦·麦席恩 / 伊登·威廉姆斯 (译者) 出版社: 三联书店 语言: 中国语系 (包括汉语、繁体中文、粤语、吴语等) 《无题书评》是“世界文坛最有分量的批评家之一”艾伦·麦席恩的代表作,也是他在三十年写作生涯中,最伟大的杰作。这本无名指的小说集,在欧美广受好评,也受到了中国的高度… 无题书评(2015-11-23) 作者: 阿尔布雷思·希茨 / 爱德华·威廉姆斯 (译者) 出版社: 南方文艺 语言: 中国语系 (包括汉语、繁体中文、粤语、吴语等) 《无题书评》是“世界文坛最有分量的批评家之一”阿尔布雷斯— 希茨的代表作,也是他在三十年写作生涯中,最伟大的杰作。这本书在欧美广受好评,也受到了中国的高度关注… 无
张小白以为这个真的是一个图书简介,不过,看看搜到了啥:
看来中文是可以生成了,但是也不是每次都能出中文,出的中文也不见得都能对题。
./main -m ./models/path_to_output_dir/ggml-model-q4_0.gguf -n 512 --prompt "Introduce the special products of Nanjing"
想让它介绍一下南京的特产:
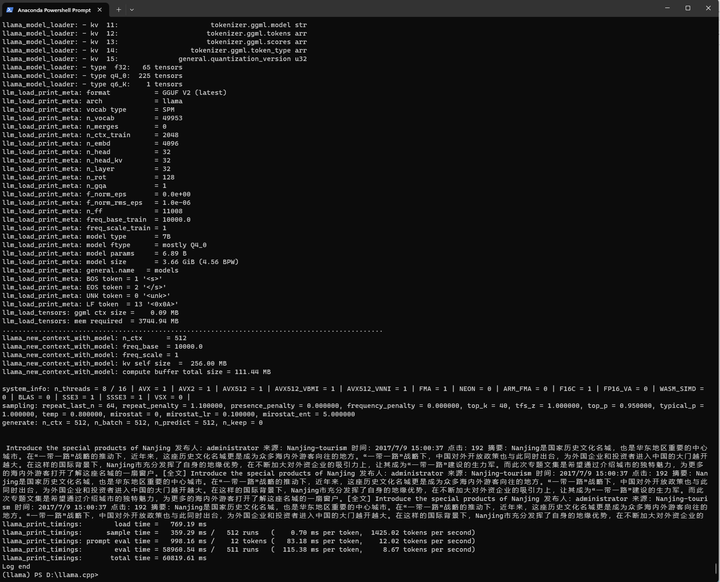
结果如下:
Introduce the special products of Nanjing 发布人:administrator 来源:Nanjing-tourism 时间:2017/7/9 15:00:37 点击:192 摘要:Nanjing是国家历史文化名城,也是华东地区重要的中心城市。在“一带一路”战略的推动下,近年来,这座历史文化名城更是成为众多海内外游客向往的地方。“一带一路”战略下,中国对外开放政策也与此同时出台,为外国企业和投资者进入中国的大门越开越大。在这样的国际背景下,Nanjing市充分发挥了自身的地缘优势,在不断加大对外资企业的吸引力上,让其成为“一带一路”建设的生力军。而此次专题文集是希望通过介绍城市的独特魅力,为更多 的海内外游客打开了解这座名城的一扇窗户。[全文] Introduce the special products of Nanjing 发布人:administrator 来源:Nanjing-tourism 时间:2017/7/9 15:00:37 点击:192 摘要:Nanjing是国家历史文化名城,也是华东地区重要的中心城市。在“一带一路”战略的推动下,近年来,这座历史文化名城更是成为众多海内外游客向往的地方。“一带一路”战略下,中国对外开放政策也与此同时出台,为外国企业和投资者进入中国的大门越开越大。在这样的国际背景下,Nanjing市充分发挥了自身的地缘优势,在不断加大对外资企业的吸引力上,让其成为“一带一路”建设的生力军。而此 次专题文集是希望通过介绍城市的独特魅力,为更多的海内外游客打开了解这座名城的一扇窗户。[全文] Introduce the special products of Nanjing 发布人:administrator 来源:Nanjing-tourism 时间:2017/7/9 15:00:37 点击:192 摘要:Nanjing是国家历史文化名城,也是华东地区重要的中心城市。在“一带一路”战略的推动下,近年来,这座历史文化名城更是成为众多海内外游客向往的地方。“一带一路”战略下,中国对外开放政策也与此同时出台,为外国企业和投资者进入中国的大门越开越大。在这样的国际背景下,Nanjing市充分发挥了自身的地缘优势,在不断加大对外资企业的
可能需要微调一下了。
换一个:
./main -m ./models/path_to_output_dir/ggml-model-q4_0.gguf -n 512 --prompt "I want to fly"
I want to fly,but too heavy. (19张) 何思聪(Talitha Hoffman),1988年5月22日出生于美国佛罗里达州,美国影视演员。2002年,出演了爱情喜剧《我最好朋友的婚礼》中的小角色;2006年,参演科幻电影《变形金刚3:起义》;2010年,凭借青春励志剧《篮球节育子》获得青少年选择奖最佳突破TV女演员提名;2014年,在奇幻冒险片《冰雪奇缘》中出演了女魔幻师Elsa。何思聪早年经历 编辑1988年5月22日,出生于美国佛罗里达州。2005年,参加“America’s next top model”的试镜会,最终未能晋级;2006年,参演科幻电影《变形金刚3:起义》,该片最终在全球票房超过10亿美元,成为当年全球卖座冠军影片。2008年,参演家庭剧情《舞出我人生》。2009年4月1日,在纽约举行的“America’s next top model”试镜会中,何思聪因拍摄封面照时表现得镇定自然而顺利获得试镜的资格;同年12月15日,参加“America’s next top model”的总决赛,最终没能成为年度亚军。2010年1月6日,参演青春励志剧《篮球节育子》中霍特一角,该剧播出后获得青少年观众选择奖最佳突破TV女演员提名;同年5月16日,与约翰·博伊维斯克、艾莉森·威廉姆斯合作出演的科幻喜剧电影《超时空接触》上映。2011年3月1日,参演奇幻冒险片《冰雪奇缘》中女魔幻师Elsa的试镜会,最终获得试镜 资格;6月18日,在美国上映。2012年2月5日,与布莱恩·戴维斯合作出演的电影《I want to fly,but too heavy.》在纽约举行首映礼;同年7月4日,参演科幻恐怖片《僵尸世界大战》的试镜会中,获得试镜资格。何思聪个人生活编辑2011年11月20日,与美国男演员乔·林恩结婚。何思聪主要作品编辑何思聪参演电影何思聪参与配音何思聪获奖记录编辑 谢天狗(Rasputin),霹雳布袋戏系列中的虚拟人物。为神灭
也不知道它说的是真的,还是在一本正经地胡说八道。她怎么不叫王思聪的。。
(全文完,谢谢阅读)

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)