Redis之布隆过滤器(Bloom Filter)解读

目录
引进前言
在实际开发中,会遇到很多要判断一个元素是否在某个集合中的业务场景,类似于垃圾邮件的识别,恶意ip地址的访问,缓存穿透等情况。类似于缓存穿透这种情况,有许多的解决方法,如:redis存储null值等,而对于垃圾邮件的识别,恶意ip地址的访问,我们也可以直接用 HashMap 去存储恶意ip地址以及垃圾邮件,然后每次访问时去检索一下对应集合中是否有相同数据。
这种思路对于数据量小的项目来说是没有问题的,但是对于大数据量的项目,如,垃圾邮件出现有十几二十万,恶意ip地址出现有上百万,或者从几十亿电话中检索出指定的电话是否在等操作,那么这十几亿的数据就会占据大几G的空间,这个时候就可以考虑一下布隆过滤器了。
网页URL的去重,垃圾邮件的判别,集合重复元素的判别,查询加速(比如基于key-value的存储系统)、数据库防止查询击穿, 使用BloomFilter来减少不存在的行或列的磁盘查找。
隆过滤器定义
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。

![]()
一句话就是:由一个初始值为零的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素。
布隆过滤器可以用于查询一个元素是否存在于一个集合当中,查询结果为以下二者之一:
- 这个元素可能存在于这个集合当中。
- 这个元素一定不存在于这个集合当中。
隆过滤器原理
当一个元素被加入集合时,通过 K 个 Hash 函数将这个元素映射成一个位阵列(Bit array)中的 K 个点,把它们置为 1。检索时,只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了。
插入key时
使用多个hash函数对key进行hash运算得到多个整数索引值,对位数组长度进行取模运算得到多个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
例如,我们添加一个字符串wmyskxz,对字符串进行多次hash(key) → 取模运行→ 得到坑位

查找key时
将这个key的多个位置上的值取出来,只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。(也就是有,不一定有,无,就一定无)
比如我们在 add 了字符串wmyskxz数据之后,很明显下面1/3/5 这几个位置的 1 是因为第一次添加的 wmyskxz 而导致的。
此时我们查询一个没添加过的不存在的字符串inexistent-key,它有可能计算后坑位也是1/3/5 ,这就是误判了
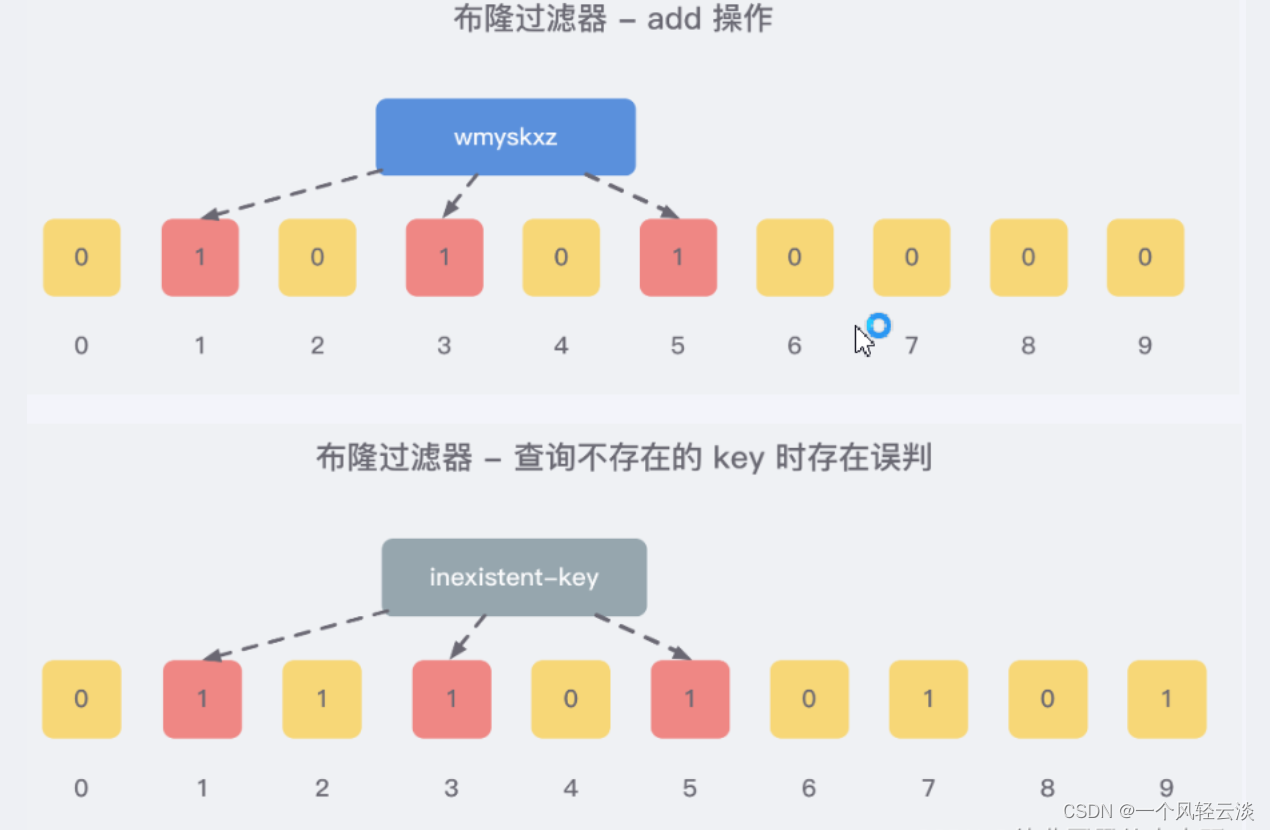
显然的,插入数据越多,1的位数越多,误报的概率越大。当实际元素数量超过初始化数量时,应该对布隆过滤器进行重建,重新分配一个 size更大的过滤器,再将所有的历史元素批量add进行
布隆过滤器优缺点
优点:高效插入和查询,内存占用空间少。相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外, Hash函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。 布隆过滤器可以表示全集,其它任何数据结构都不能。
缺点 不能删除元素。 (因为删掉元素会导致误判率增加,因为hash冲突同一个位置可能存的东西是多个共有的,你删除一个元素的同时可能也把其它的删除了) 存在误判(不同的数据可能出来相同的hash值)
布隆过滤器的使用场景
①.解决缓存穿透的问题
- 缓存穿透是什么 一般情况下,先查询缓存redis是否有该条数据,缓存中没有时,再查询数据库 当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。
- 缓存透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库 可以使用布隆过滤器解决缓存穿透的问题 把已存在数据的key存在布隆过滤器中,相当于redis前面挡着一个布隆过滤器。
- 当有新的请求时,先到布隆过滤器中查询是否存在: 如果布隆过滤器中不存在该条数据则直接返回; 如果布隆过滤器中已存在,才去查询缓存redis,如果redis里没查询到则穿透到Mysql数据库
②. 黑名单校验
- 发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件
- 假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案 把所有黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可
布谷鸟过滤器(了解)
①. 为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世。论文《Cuckoo Filter:Better Than Bloom》
②. 作者将布谷鸟过滤器和布隆过滤器进行了深入的对比。相比布谷鸟过滤器而言布隆过滤器有以下不足:查询性能弱、空间利用效率低、不支持反向操作(删除)以及不支持计数

- 点赞
- 收藏
- 关注作者
评论(0)