R语言之 ggplot 2 和其他图形

文章和代码已经归档至【Github仓库:https://github.com/timerring/dive-into-AI 】或者公众号【AIShareLab】回复 R语言 也可获取。
1. 初识 ggplot2 包
ggplot2 包提供了一套基于图层语法的绘图系统,它弥补了 R 基础绘图系统里的函数缺乏一致性的缺点,将 R 的绘图功能提升到了一个全新的境界。ggplot2 中各种数据可视化的基本原则完全一致,它将数学空间映射到图形元素空间。想象有一张空白的画布,在画布上我们需要定义可视化的数据(data),以及数据变量到图形属性的映射(mapping)。
下面使用数据集 mtcars 作图。
该数据集摘自 1974 年的美国《汽车趋势》杂志,包含 32 辆汽车的燃油消耗、设计和性能等方面的 11 个指标:mpg(耗油量)、cyl(气缸数)、disp(排量)、hp(总功率)、drat(后轴比)、wt(车重)、qsec(四分之一英里用时)、vs(发动机类型)、am(传动方式)、gear(前进挡个数)和 carb(化油器个数)。我们首先来探索车重和耗油量的关系,将变量 wt 映射到 x 轴,变量 mpg 映射到 y 轴。
library(ggplot2)
p <- ggplot(data = mtcars, mapping = aes(x = wt, y = mpg))
在上面的命令里,aes 代表美学(aesthetics)元素,我们把需要映射的变量都放在这个函数中。直接运行 p 得到的只是一个空白的画布,还需要定义用什么样的图形来表示数据。 以 geom 开头的一系列函数用于指定图形元素,包括点、线、面、多边形等。下面使用点(point)这种几何对象来展示数据,结果如下图所示。
p + geom_point()
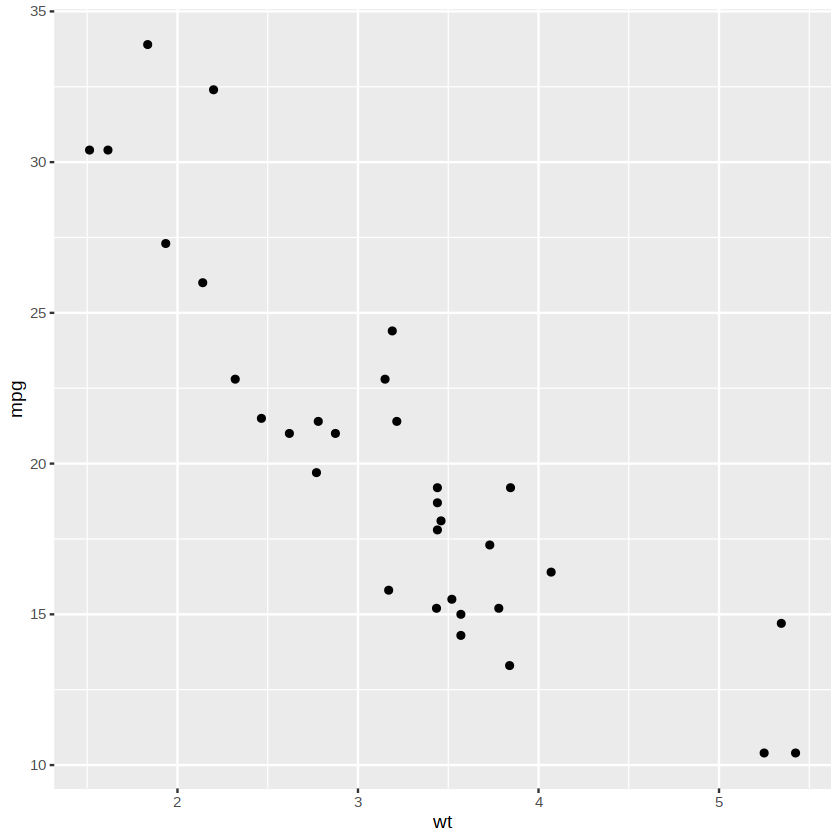
除了坐标轴,还可以把变量映射到颜色(color)、大小(size)、形状(shape)等属性。
例如,为了展示不同传动方式下车重和耗油量的关系,我们可以将变量 am 映射为颜色(下图左)或形状(下图右)。变量 am 在原数据集里是一个数值型变量(取值为 0 和 1),实质上它应该是一个分类变量,因此我们先把它转换为一个二水平的因子。
library(gridExtra)
mtcars$am <- factor(mtcars$am)
p1 <- ggplot(data = mtcars, aes(x = wt, y = mpg, color = am)) + geom_point()
p2 <- ggplot(data = mtcars, aes(x = wt, y = mpg, shape = am)) + geom_point()
grid.arrange(p1, p2, nrow=1)

上面的图形都是原始数据的展示,有时候我们需要对原始数据进行某种归纳后作图。例如,用上图中的散点拟合曲线。
ggplot(data = mtcars, aes(x = wt, y = mpg, color = am)) + geom_smooth()

函数 geom_smooth( )里的参数 method 默认值为“loess”,即 LOESS 局部加权回归
如果想换一种拟合曲线的方法,可以改变参数 method 的值。例如,用直线回归
ggplot(data = mtcars, aes(x = wt, y = mpg, color = am)) +
geom_smooth(method = "lm")

上面两幅图中都有两条拟合线,那是因为我们将变量 am 映射成了颜色属性。如果只想显示一条平滑线,就需要在 geom_point( )函数中单独设置颜色的映射,结果如下图所示。
ggplot(data = mtcars, aes(x = wt, y = mpg)) +
geom_point(aes(color = am)) +
geom_smooth()
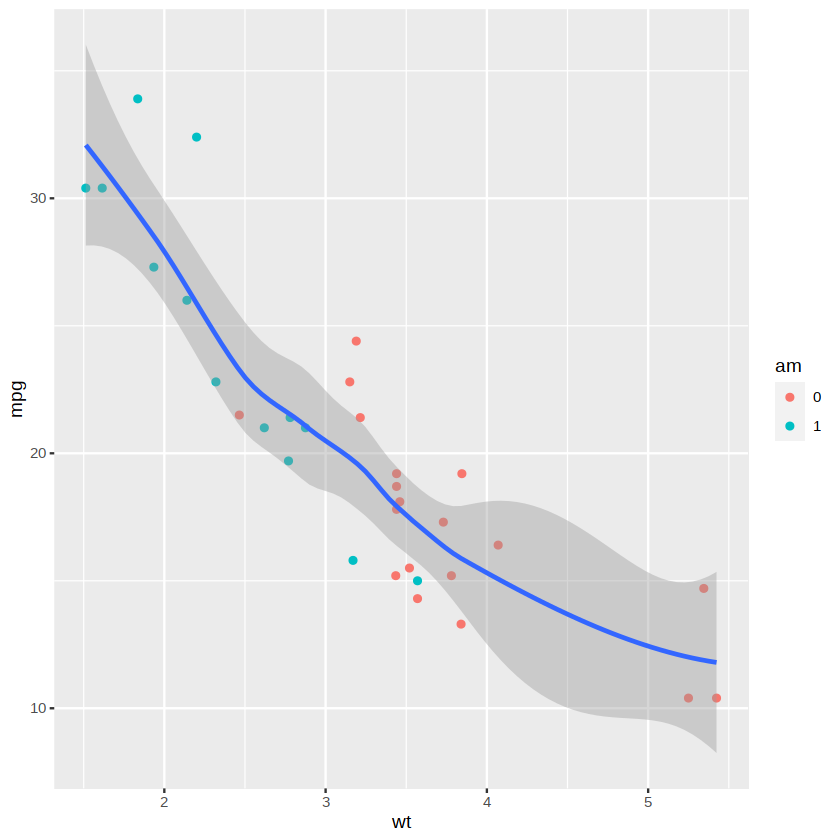
现在我们已经有了“图层”的概念了。一个图层就像是一张玻璃纸,包含各种图形元素,我们可以分别建立多个图层,然后把它们叠放在一起组成最终的显示效果。
函数 aes( ) 就像是 ggplot2 的大脑,负责美学设计,而众多的以 geom 开头的函数就像是 ggplot2 的双手,负责将这些美学设计呈现出来。ggplot2 包中有超过 30 个以 geom 开头的函数,读者可通过该包的帮助文档查看这些函数。映射只负责将变量关联到某个图形属性,并不负责具体的数值。例如,在上图中,我们将变量 am 映射到颜色,但具体使用哪种颜色是 ggplot2 自动选择的。如果想自己设定颜色,就需要使用标度(scale)函数了。
标度函数是图形细节的调节函数,好比电视机的遥控器,可以调节电视机的音量、画面、色彩等属性。ggplot2 中有种类繁多的以 scale 开头的标度函数,可用于控制图形的颜色、点的大小和形状等。例如,我们可以用下面的标度函数手动设置需要的颜色,结果如下图所示。
ggplot(data = mtcars, aes(x = wt, y = mpg)) +
geom_point(aes(color = am)) +
scale_color_manual(values = c("blue", "red")) +
geom_smooth()
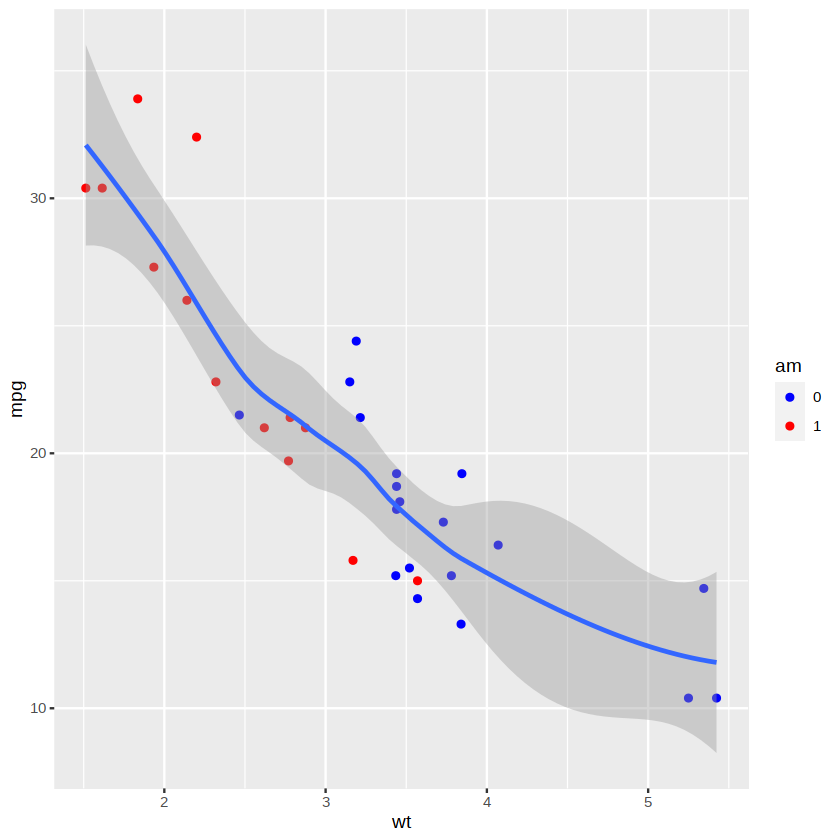
ggplot2 包还能实现 lattice 包中的分组绘图功能,即分面(facet)。分面是将整个数据按照某一个或几个分类变量分成多个子集,然后用这些子集分别作图。例如,要将上图按照变量 am 的两个水平分别展示,可以使用下面的命令。绘图结果如下图所示。
ggplot(data = mtcars, aes(x = wt, y = mpg)) +
geom_point() +
stat_smooth() +
facet_grid(~ am)

ggplot2 包中的主题(theme)函数用于定义绘图的风格,例如画布的背景。下图是一个黑白主题画布背景示例:
ggplot(data = mtcars, aes(x = wt, y = mpg)) +
geom_point(aes(color = am)) +
stat_smooth() +
theme_bw()
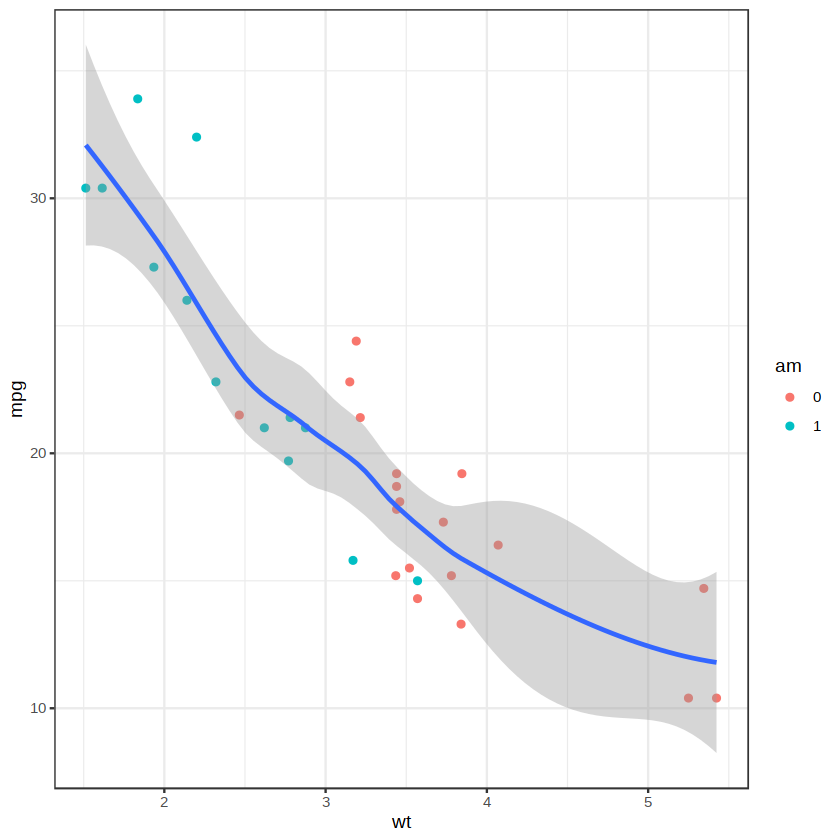
除了 ggplot2 包自带的主题,还有一些扩展包提供了多种主题风格,例如 ggthemes 包、artyfarty 包等。使用这些包之前需要先安装,感兴趣的读者可自行探索。
以上介绍了 ggplot2 包中的映射(mapping)、图形元素(geom)、标度(scale)、分面(facet)和主题(theme)等概念,并展示了它们的基本用法。接下来我们将探索用 ggplot2 包绘制常用统计图形的方法。
2.分布的特征
在探索数据的过程中,最基本的手段就是观察单个变量的取值情况。对于连续型变量,可以绘制直方图或密度曲线图。
下面用之前提及的 MASS 包里的数据集anorexia 作图。先加载数据并建立新变量 wt.change(体重改变量,单位:lb)。
data(anorexia, package = "MASS")
anorexia$wt.change <- anorexia$Postwt - anorexia$Prewt
接下来,用 ggplot2 包绘制变量 wt.change 的直方图,代码如下:
library(ggplot2)
p1 <- ggplot(anorexia, aes(x = wt.change)) +
geom_histogram(binwidth = 2, fill = "skyblue", color = "black") +
labs(x = "Weight change (lbs)") +
theme_bw()
p1
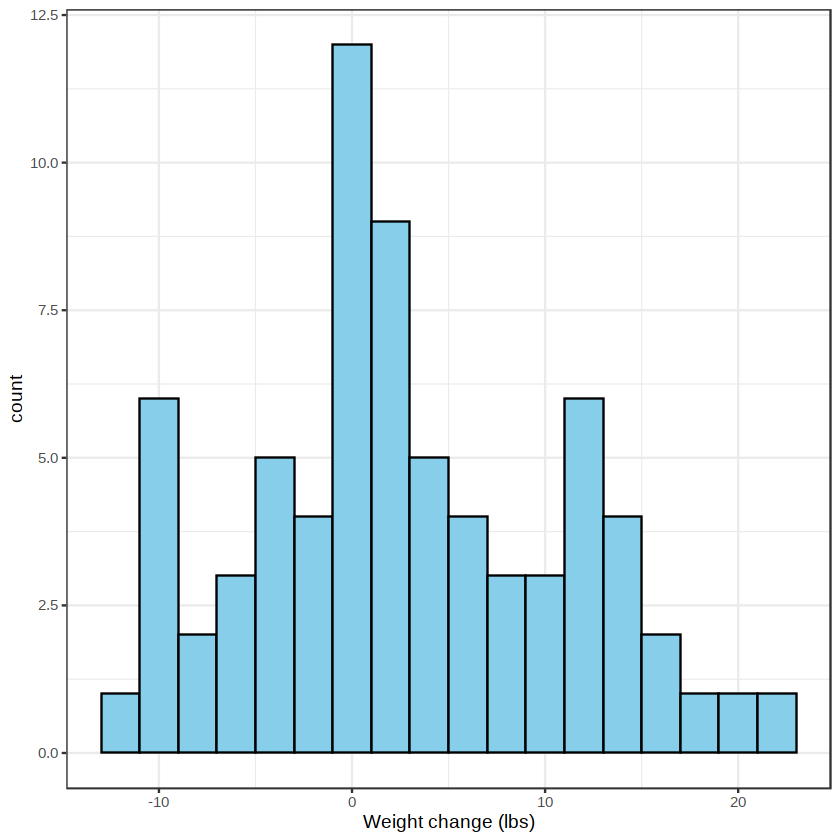
其中,参数 binwidth 用于设置组距,默认值为全距除以 30,在作图时可以尝试设置不同参数值以得到比较满意的结果。参数 fill 用于设置填充色。参数 color 用于设置矩形边框的颜色。我们还可以将直方图和密度曲线同时展示,如下图所示。
p2 <- ggplot(anorexia, aes(x = wt.change, y = ..density..)) +
geom_histogram(binwidth = 2, fill = "skyblue", color = "black") +
stat_density(geom = "line",linetype = "dashed", size = 1) +
labs(x = "Weight change (lbs)") +
theme_bw()
p2

其中,“y = …density…”用于设定 y 轴为频率(密度),stat_density( )是一种用于计算密度估计曲线的统计变换。
密度曲线还能用于对不同数据的分布进行比较。例如,要比较不同治疗方式下体重改变量的分布,输入下面的代码:
p3 <- ggplot(anorexia, aes(x = wt.change, color = Treat, linetype = Treat)) +
stat_density(geom = "line", size = 1) +
labs(x = "Weight change (lbs)") +
theme_bw()
p3
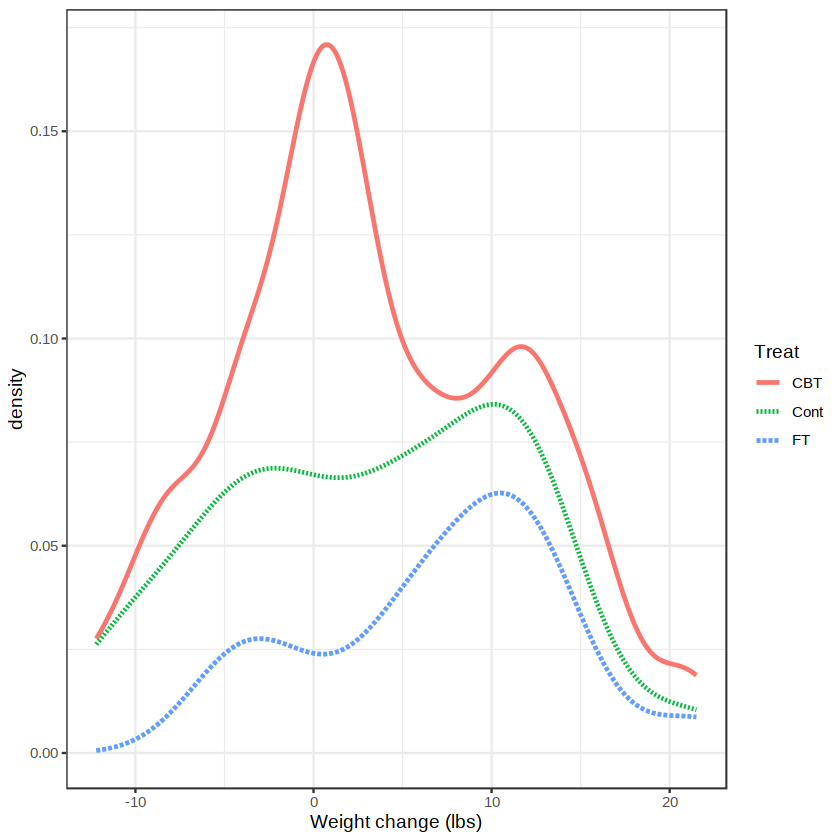
上面的命令先将变量 Treat 映射为颜色和线型,再画出 3 种治疗方式下的体重改变量 wt.change 的密度曲线,如上图所示。
除了直方图和密度曲线图,箱线图也经常用于展示数值型变量的分布,尤其多用于各组之间分布的比较。例如:
p4 <- ggplot(anorexia, aes(x= Treat, y = wt.change)) +
geom_boxplot() +
theme_bw()
p4

从上图可以看出,FT 组的体重改变量要高于其他两组,但是差异的显著性需要经过统计学检验才能得出结论。
ggpubr 包提供了在平行箱线图上添加组间比较的统计学差异的功能。该包是一个 ggplot2 的衍生包,可以生成用于论文发表的统计图形,值得医学研究工作者探索。下面在上图的基础上添加组间均值比较的统计学差异。
library(ggpubr)
my_comparisons <- list(c("CBT", "Cont"), c("CBT", "FT"), c("Cont", "FT"))
p5 <- ggplot(anorexia, aes(x= Treat, y = wt.change)) +
geom_boxplot() +
stat_compare_means(comparisons = my_comparisons,
method = "t.test",
color = "blue") +
theme_bw()
p5

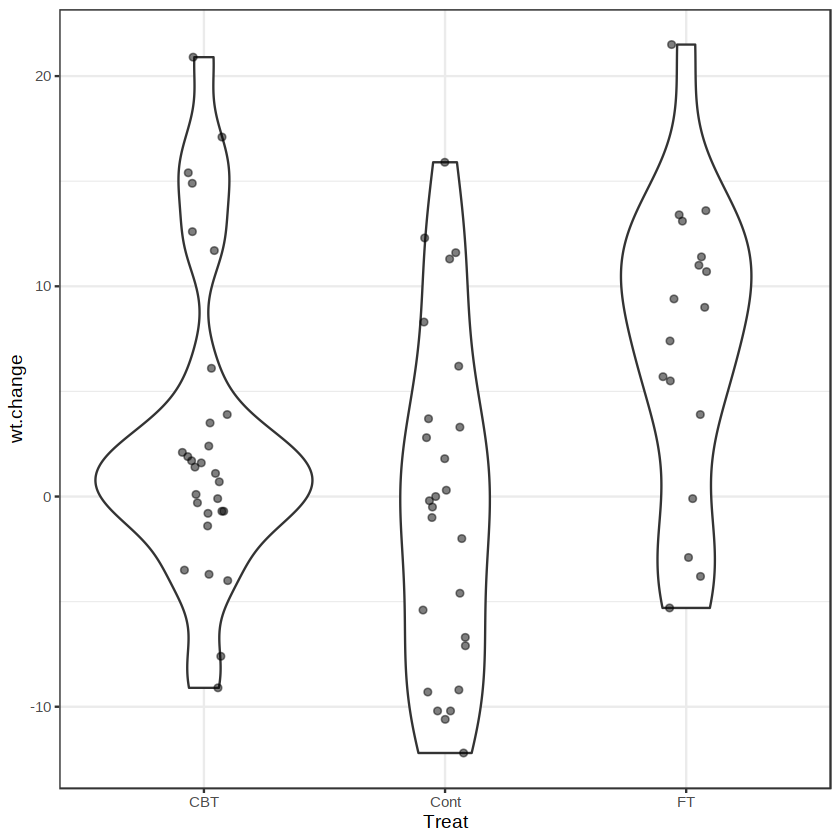
上图中的 p 值是用 t 检验进行组间两两比较得到的。另外,我们还可以用 ggplot2 绘制与上图相似的小提琴图,结果如下图所示。
p6 <- ggplot(anorexia, aes(x= Treat, y = wt.change)) +
geom_violin() +
geom_point(position = position_jitter(0.1), alpha = 0.5) +
theme_bw()
p6
3.比例的构成
许多数据会涉及比例的问题,提取比例信息能使我们了解各个组成部分对于整体的重要性。比例的构成常用条形图展示,例如:
library(vcd)
data(Arthritis)
ggplot(Arthritis, aes(x = Treatment, fill = Improved)) +
geom_bar(color = "black") +
scale_fill_brewer() +
theme_bw()

上图被称为叠加条形图,是为了在一幅图中同时展现多个变量,图中的纵坐标是计数的绝对大小。但有时候我们更希望观察相对比例,这可以通过将参数 position 设为“fill”来实现,结果如下图所示。
ggplot(Arthritis, aes(x = Treatment, fill = Improved)) +
geom_bar(color = "black", position = "fill") +
scale_fill_brewer() +
theme_bw()
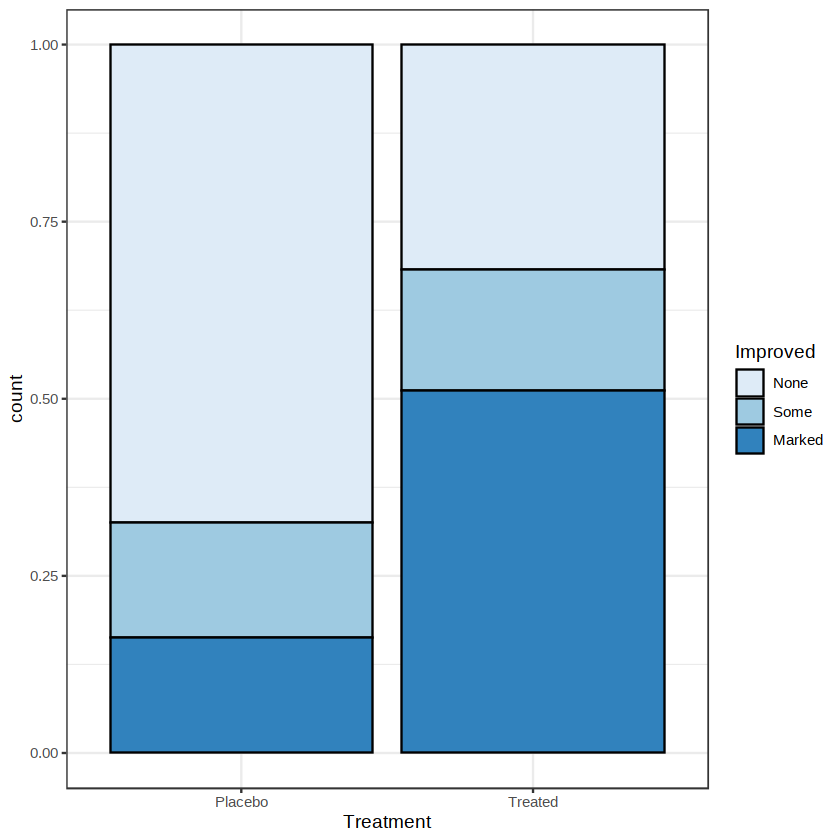
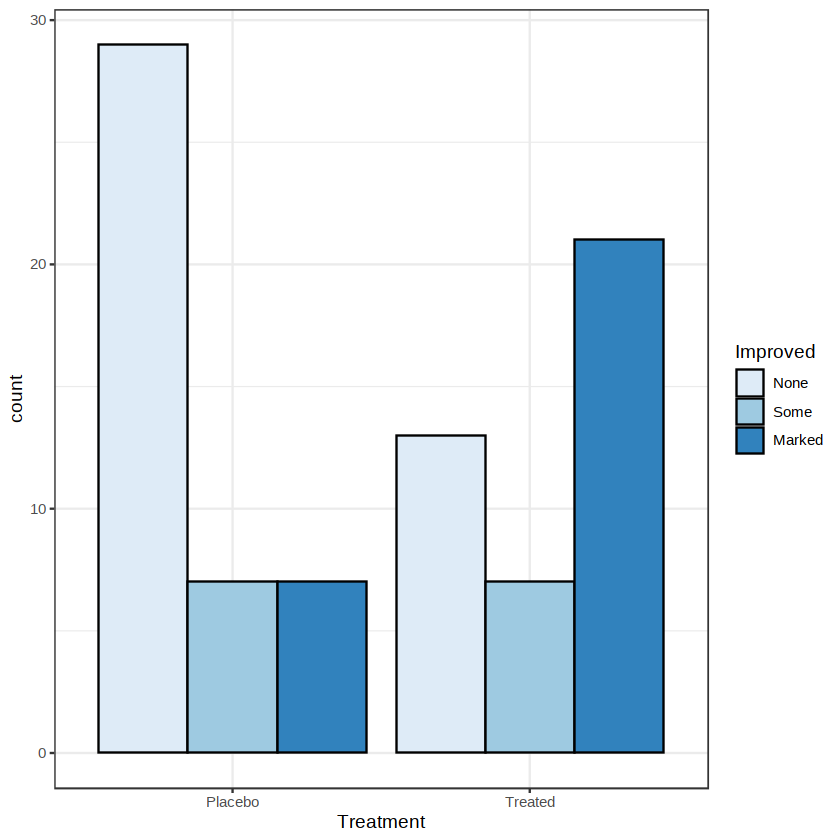
我们还可以把参数 position 设为“dodge”来将条形图并排放置,如下图所示。
ggplot(Arthritis, aes(x = Treatment, fill = Improved)) +
geom_bar(color = "black", position = "dodge") +
scale_fill_brewer() +
theme_bw()
4.用函数 ggsave( )保存图形
函数 ggsave( )专门用于保存 ggplot2 包绘制的图形,该函数可以导出多种不同格式的图片。例如:
p <- ggplot(mtcars, aes(wt, mpg)) + geom_point()
ggsave("myplot.png", p)
ggsave("myplot.pdf", p)
上面的命令先创建了一幅散点图并把结果保存为 p,然后用函数 ggsave( )分别把这幅图形保存为 png 和 pdf 格式的文件。打开当前工作目录就可以看到这两个文件。
如果要把图片用于出版物中,我们可以对图片的尺寸和分辨率等进行设置。例如,把上面的图形对象 p 保存为 tiff 格式,并设置图片的长和宽分别为 12cm 和 15cm,分辨率为 500 dpi,代码如下:
ggsave("myplot.tiff", width = 15, height = 12, units = "cm", dpi = 500)
2. 其他图形
2.1 金字塔图
金字塔图是一种背靠背式的条形图,常用于展示研究人群的人口结构,所以也称为人口金字塔图。DescTools 包里的 PlotPyramid( ) 函数,以及 epiDisplay 包里的 pyramid( )函数都可以用来绘制金字塔图。下面以 epiDisplay 包里的数据集 Oswego 为例绘制金字塔图,这里需要用到数据集里的两个变量 age 和 sex。
options(warn = -1)
library(epiDisplay)
data(Oswego)
pyramid(Oswego$age, Oswego$sex, col.gender = c(2, 4), bar.label = TRUE)

上图展示的是不同性别下各个年龄组的频数分布。函数 pyramid( )里有很多参数可以用于控制图形的细节展示,读者请查看该函数的帮助文档并尝试改变不同的参数设置以得到满意的输出效果。
2.2 横向堆栈条形图
在做流行病学调查时,经常需要在问卷上设置很多选择题。对于一组问题,可以使用 sjPlot 包里的函数 plot_stackfrq( ) 对不同选项的比例进行可视化。下面以该包里的数据集 efc 为例作图,这里需要用到其中的 9 个变量,它们分别对应问卷里的 9 个选择题。运行下面代码前请先安装 sjPlot 包。
library(sjPlot)
data(efc)
names(efc)
head(efc)
qdata <- dplyr::select(efc, c82cop1:c90cop9)
plot_stackfrq(qdata)

绘图结果如上图所示,我们可以从图中获取每个问题的表述、回答的人数、不同选项的选择的百分比等信息。
sjPlot 包里汇集了很多用于可视化流行病学和社会科学领域的数据的函数。使用这些函数能够轻松地绘制出既美观又实用的统计图形,值得读者进一步探索。
3.3 热图
热图(heatmap)是将一个矩阵中的元素数值用不同颜色表达,并对矩阵的行或列进行层次聚类的一种颜色图。通过热图,我们不仅可以直接观察矩阵中的数值分布状况,还可以知道聚类的结果。关于聚类分析的进一步介绍参见第 10 章。热图经常运用在生物信息学数据分析中。以 RNA-seq 为例,热图可以直观地呈现多样本或多个基因的全局表达量的变化,还可以呈现多样本或多个基因表达量的聚类关系。
stats 包里的函数 heatmap( )可用于制作热图。下面以数据集 mtcars 为例介绍该函数的用法。由于该数据集里变量的测量尺度有较大差异,我们首先需要用函数 scale( )把变量标准化。标准化后的变量组成的矩阵可以作为函数 heatmap( )的输入,绘图结果如下图所示。
data(mtcars)
dat <- scale(mtcars)
class(dat)
heatmap(dat)

3.4 三维散点图
前面提到的图形都是二维的,如果想对 3 个数值型变量的关系进行可视化,可以使用 scatterplot3d 包的 scatterplot3d( )函数,使用前请先安装该包。
函数 scatterplot3d( ) 提供的参数选项包括设置图形符号、突出显示、角度、颜色、线条、坐标轴和网格线等。下面以 datasets 包里的数据集 trees 为例说明此函数的用法。该数据集包含 3 个数值型变量 Girth、Height 和Volume。我们分别以这 3 个变量为坐标轴绘制三维散点图,结果如下图所示。
library(scatterplot3d)
data(trees)
scatterplot3d(trees, type = "h", highlight.3d = TRUE, angle = 55, pch = 16)

上面函数 scatterplot3d( )中的参数 type 用于设置绘图的类型,默认为“p”(点),这里设为“h”,显示垂线段。参数 angle 用于设置 x 轴和 y 轴的角度。需要注意的是,用静态的三维散点图描述 3 个变量之间的关系时,可能会受到观察角度的影响。
3.5 小结
其他一些专门的图形,例如散点图矩阵、相关图、正态 QQ 图、生存曲线、聚类图、碎石图、ROC 曲线和 Meta 分析森林图等,将会在后续章节中结合统计分析方法陆续介绍。在 R 的应用中,可视化是一个非常活跃的领域,新的包层出不穷。网站 The R Graph Gallery 收集了各种新颖的图形以及相应的示例代码,值得对可视化感兴趣的读者关注。

- 点赞
- 收藏
- 关注作者
评论(0)