数据采集:selenium 获取某网站CDN 商家排名信息

1写在前面
-
工作中遇到,简单整理 -
理解不足小伙伴帮忙指正
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
采集流程:
-
自动登陆 -
获取商家排名页当前页数据 -
获取总页数,和下一页对应元素 -
根据总页数 循环遍历,模拟点击下一页获取数据分页数据 -
数据汇总
from seleniumwire import webdriver
import json
import time
from selenium.webdriver.common.by import By
import pandas as pd
# 自动登陆
driver = webdriver.Chrome()
with open('C:\\Users\山河已无恙\\Documents\GitHub\\reptile_demo\\demo\\cookie.txt', 'r', encoding='u8') as f:
cookies = json.load(f)
driver.get('https://cdn.chinaz.com/')
for cookie in cookies:
driver.add_cookie(cookie)
driver.get('https://cdn.chinaz.com/')
time.sleep(6)
#CND 商家排行获取 https://cdn.chinaz.com/
CDN_Manufacturer = []
new_div_element = driver.find_element(By.CSS_SELECTOR, ".toplist-main")
div_elements = new_div_element.find_elements(By.CSS_SELECTOR, ".ullist")
#CDN_Manufacturer.extend(div_elements)
for mdn_ms in div_elements:
a_target = mdn_ms.find_element(By.CSS_SELECTOR,".tohome")
home_url = a_target.get_attribute('href')
print(mdn_ms.text)
text_temp = str(mdn_ms.text).split("\n")
CDN_Manufacturer.append({
"公司名称": text_temp[0],
"官网地址": home_url,
"经营资质": text_temp[1],
"CDN网站数量": text_temp[2],
"网站占比": text_temp[3],
"IP节点":text_temp[4],
"IP占比":text_temp[5],
})
sum_page = driver.find_element(By.XPATH,"//a[contains(@title, '尾页')]")
attribute_value = sum_page.get_attribute('val')
print(attribute_value)
for page in range(1,int(attribute_value)):
next_page = driver.find_element(By.XPATH,"//a[contains(@title, '下一页')]")
next_page.click()
time.sleep(5)
new_div_element = driver.find_element(By.CSS_SELECTOR, ".toplist-main")
div_elements = new_div_element.find_elements(By.CSS_SELECTOR, ".ullist")
#CDN_Manufacturer.extend(div_elements)
for mdn_ms in div_elements:
a_target = mdn_ms.find_element(By.CSS_SELECTOR,".tohome")
home_url = a_target.get_attribute('href')
print(mdn_ms.text)
text_temp = str(mdn_ms.text).split("\n")
CDN_Manufacturer.append({
"公司名称": text_temp[0],
"官网地址": home_url,
"经营资质": text_temp[1],
"CDN网站数量": text_temp[2],
"网站占比": text_temp[3],
"IP节点":text_temp[4],
"IP占比":text_temp[5],
})
#print(CDN_Manufacturer)
#a_list = page_element.find_elements(By.TAG_NAME,"a")
for mdn_ms in CDN_Manufacturer:
#divs = mdn_ms.find_elements(By.XPATH,"//div")
pass
df = pd.DataFrame(CDN_Manufacturer)
# 将数据保存为CSV文件
df.to_csv('CDN_Manufacturer.csv', index=False)
print("数据已保存为CSV文件")
pd 直接打印 生成结果
数据已保存为CSV文件
公司名称 官网地址 ... IP节点 IP占比
0 百度云加速 https://cloud.baidu.com/product/cdn.html ... 92100 4.7%
1 阿里云 https://www.aliyun.com/ ... 238994 12.3%
2 腾讯云 https://cloud.tencent.com/ ... 57212 2.9%
3 知道创宇云防御 https://www.yunaq.com/jsl/ ... 16333 0.8%
4 网宿 http://www.chinanetcenter.com/ ... 67683 3.5%
.. ... ... ... ... ...
67 睿江CDN http://www.efly.cc/ ... 1 <0.1
68 领智云画科 http://www.linkingcloud.com/ ... 6 <0.1
69 郑州珑凌 http://www.lonlife.cn/ ... 1 <0.1
70 中国联合网络 http://www.wocloud.cn/ ... 2 <0.1
71 极兔云CDN https://www.jitucdn.com/ ... 9 <0.1
数据可视化
通过 pyecharts 对数据做简单可视化
def to_echarts(CDN_Manufacturer):
from pyecharts.charts import Bar
from pyecharts import options as opts
# 内置主题类型可查看 pyecharts.globals.ThemeType
from pyecharts.globals import ThemeType
xaxis = [ cdn["公司名称"] for cdn in CDN_Manufacturer ][:10]
yaxis1 = [ cdn["CDN网站数量"] for cdn in CDN_Manufacturer ][:10]
yaxis2 = [ cdn["IP节点"] for cdn in CDN_Manufacturer ][:10]
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add_xaxis(xaxis)
.add_yaxis("CDN网站数量", yaxis1)
.add_yaxis("IP节点", yaxis2)
.set_global_opts(title_opts=opts.TitleOpts(title="主标题", subtitle="副标题"))
)
bar.render()
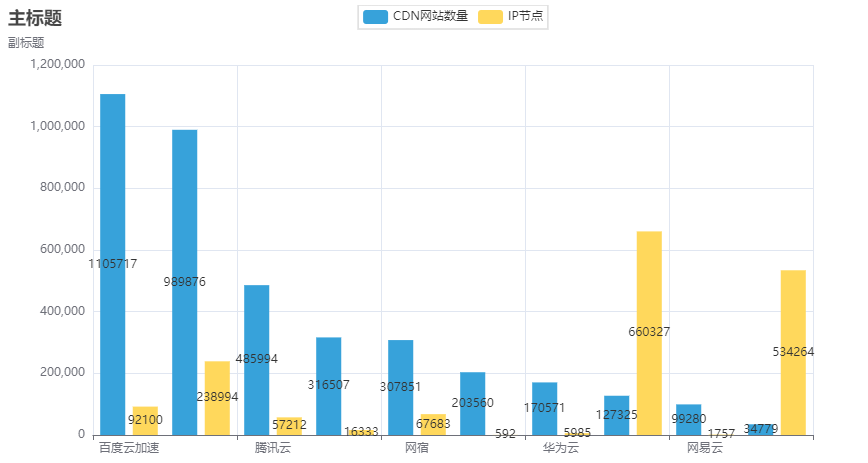 在这里插入图片描述
在这里插入图片描述
也可以考虑其他一些可视化工具
Matplotlib:Matplotlib 是 Python 中最常用的数据可视化库之一,提供了广泛的绘图功能,包括折线图、散点图、柱状图、饼图等。它可以用于创建静态图表和交互式图形,并且可以高度定制。
Seaborn:Seaborn 是基于 Matplotlib 的统计数据可视化库,专注于统计图表和信息可视化。Seaborn 提供了更高级的统计图表类型,并具有更好的默认样式和颜色主题。
Plotly:Plotly 是一个交互式可视化库,可创建高度定制化的图表和可视化界面。Plotly 提供了丰富的图表类型,包括折线图、散点图、柱状图、热力图等,并支持创建交互式的仪表盘和可视化应用。
Bokeh:Bokeh 是一个用于创建交互式图表和可视化的库,具有强大的绘图能力和跨平台的支持。Bokeh 可以生成 HTML、JavaScript 和 WebGL,从而实现跨浏览器和跨设备的可视化。
Altair:Altair 是一个声明式的数据可视化库,使用简单的 Python 语法生成可视化图表。Altair 基于 Vega-Lite 规范,具有清晰的语法和简洁的API。
2博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告
<pyecharts: https://pyecharts.org/#/zh-cn/quickstart>
<Matplotlib: https://github.com/matplotlib/matplotlib>
<Seaborn: https://github.com/seaborn/seaborn>
<Plotly: https://github.com/plotly/plotly.py>
<Bokeh: https://github.com/bokeh/bokeh>
<Altair: https://github.com/altair-viz/altair>
© 2018-2023 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)

- 点赞
- 收藏
- 关注作者
评论(0)