AI实战营第二期 第七节 《语义分割与MMSegmentation》——笔记8

@[toc]
摘要

MMSegmentation 是一个基于 PyTorch 的语义分割开源工具箱。它是 OpenMMLab 项目的一部分。
main 分支代码目前支持 PyTorch 1.6 以上的版本。
代码链接:https://gitee.com/open-mmlab/mmsegmentation

主要特性
统一的基准平台。我们将各种各样的语义分割算法集成到了一个统一的工具箱,进行基准测试。
模块化设计。MMSegmentation 将分割框架解耦成不同的模块组件,通过组合不同的模块组件,用户可以便捷地构建自定义的分割模型。
丰富的即插即用的算法和模型。MMSegmentation 支持了众多主流的和最新的检测算法,例如 PSPNet,DeepLabV3,PSANet,DeepLabV3+ 等.
速度快。训练速度比其他语义分割代码库更快或者相当。


分割算法分为语义分割、实例分割和全景分割,课程讲解如下:
【课程链接】https://www.bilibili.com/video/BV1gV4y1m74P/
【讲师介绍】张子豪 OpenMMLab算法工程师
算法库主页:https://github.com/open-mmlab/mmsegmentation
代码教程:https://github.com/TommyZihao/MMSegmentation_Tutorials
课程内容:
- 语义分割的基本思路
- 深度学习下的语义分割模型
- 全卷积网络
- 空洞卷积与 DeepLab 模型
- 上下文信息与 PSPNet 模型
- 分割模型的评估方法
- 实践 MMSegmentation

案例
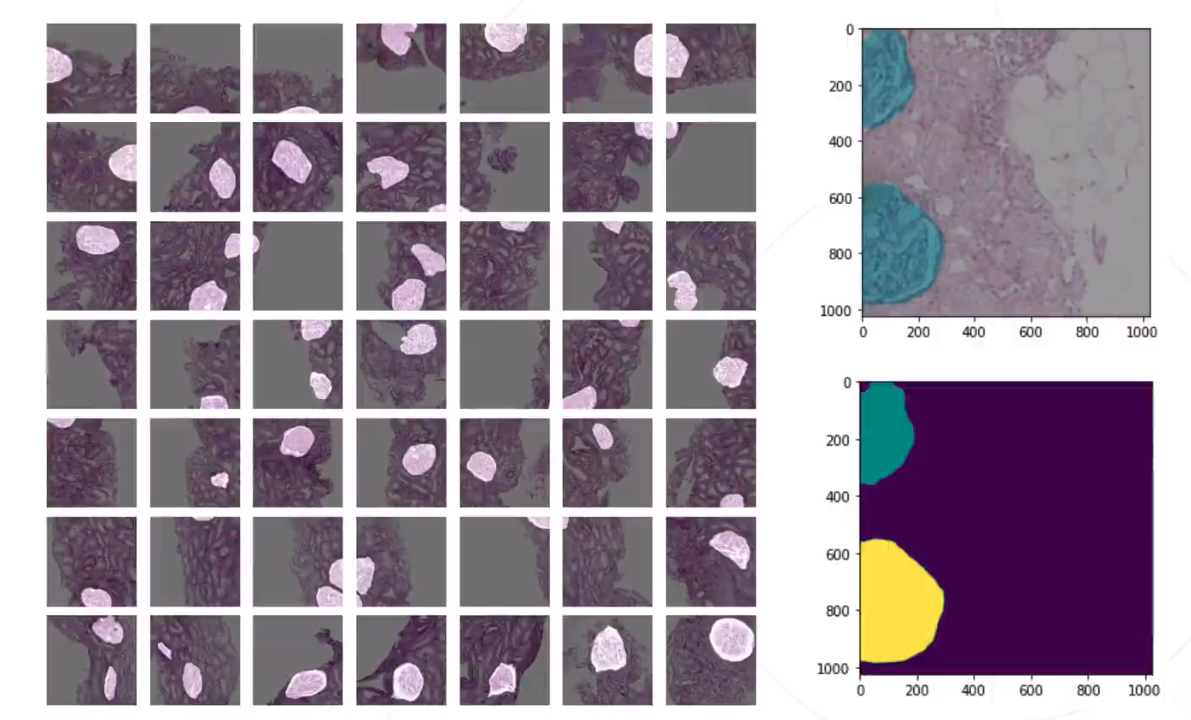
1、kaggle小鼠肾小球组织病理切片 图像分割
2、迪拜卫星遥感图像分割

3、基于MMSegmentation的钢轨裂纹分割提取


什么是语义分割

将图像按照物体的类别分割成不同的区域,或者对每个像素进行分类。
应用:无人驾驶汽车

自动驾驶车辆,会将行人,其他车辆,行车道,人行道、交通标志、房屋、草地与树木等 等按照类别在图像中分割出来,从而辅助车辆对道路的情况进行识别与认知。
应用:人像分割
将人和背景分割,实时替换视频的背景。
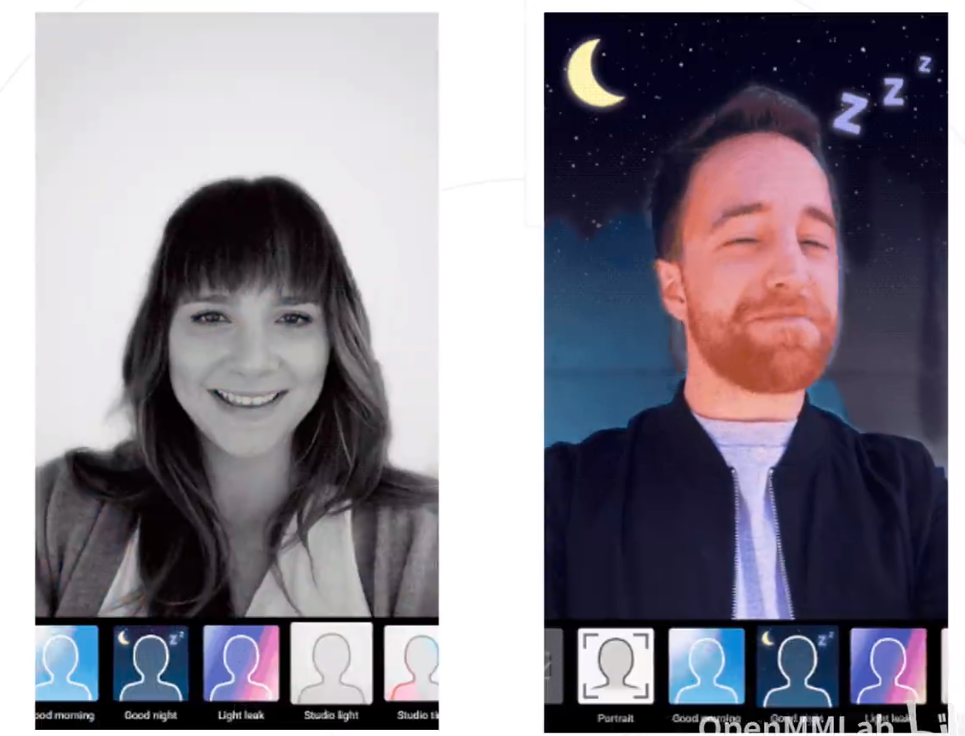
这个项目可以看我的博客:https://wanghao.blog.csdn.net/article/details/125134287,我用阿里的开源代码几乎做到了实时。
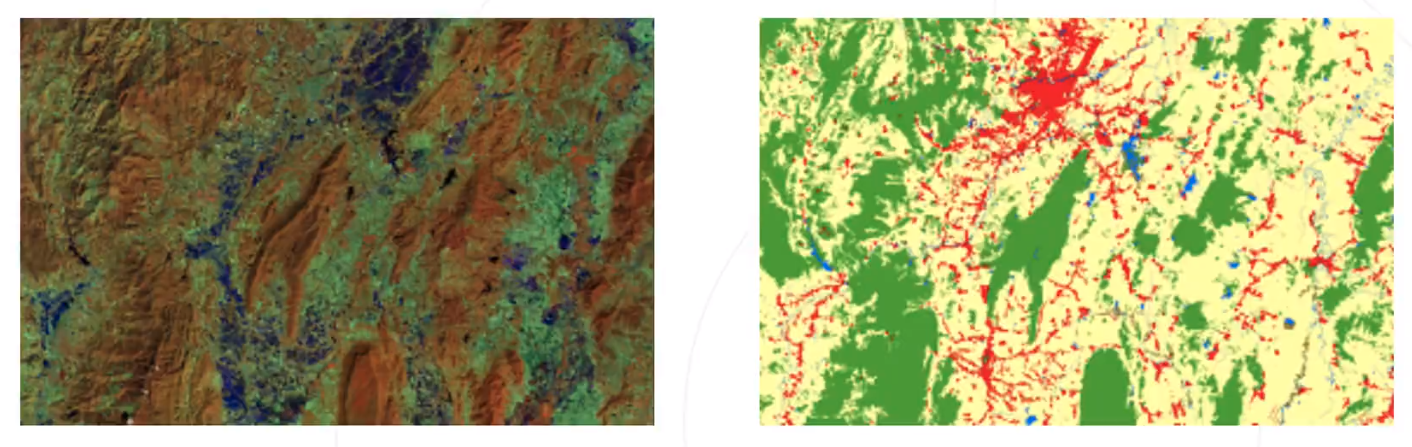
应用:智能遥感
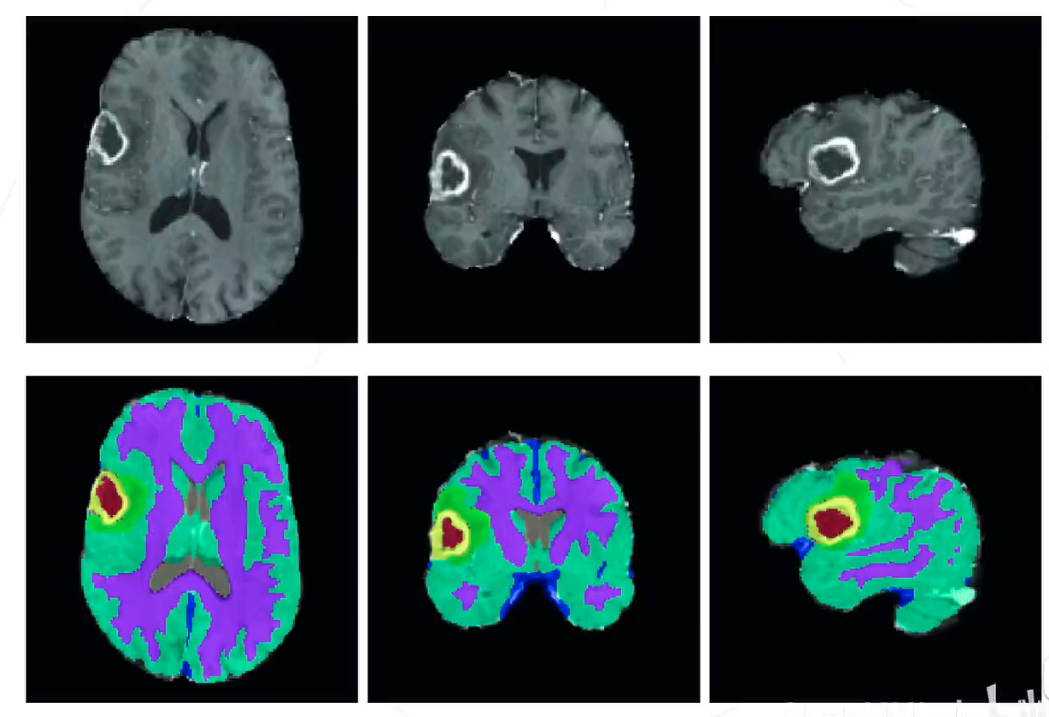
应用 : 医疗影像分析
通过图像分割技术,辅助进行 医疗诊断。如右图,识别脑部 肿瘤异物的位置。
三种分割的区别
语义分割(Semantic Segmentation):就是对一张图像上的所有像素点进行分类。(eg: FCN/Unet/Unet++/…)
实例分割(Instance Segmentation):可以理解为目标检测和语义分割的结合。(eg: Mask R-CNN/…)相对目标检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割需要标注出图上同一物体的不同个体。
全景分割(Panoptic Segmentation):可以理解为语义分割和实例分割的结合。实例分割只对图像中的object进行检测,并对检测到的object进行分割;全景分割是对图中的所有物体包括背景都要进行检测和分割。

语义分割的基本思路
按颜色分割
物体内部颜色相近,物体交界颜色变化
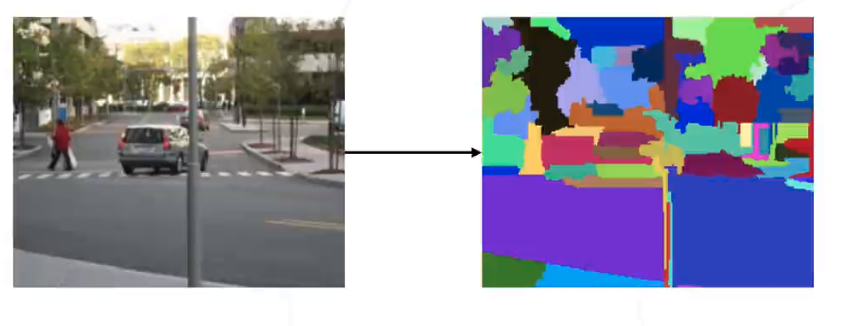
逐像素份分类
通过滑窗的方式,效率低下!
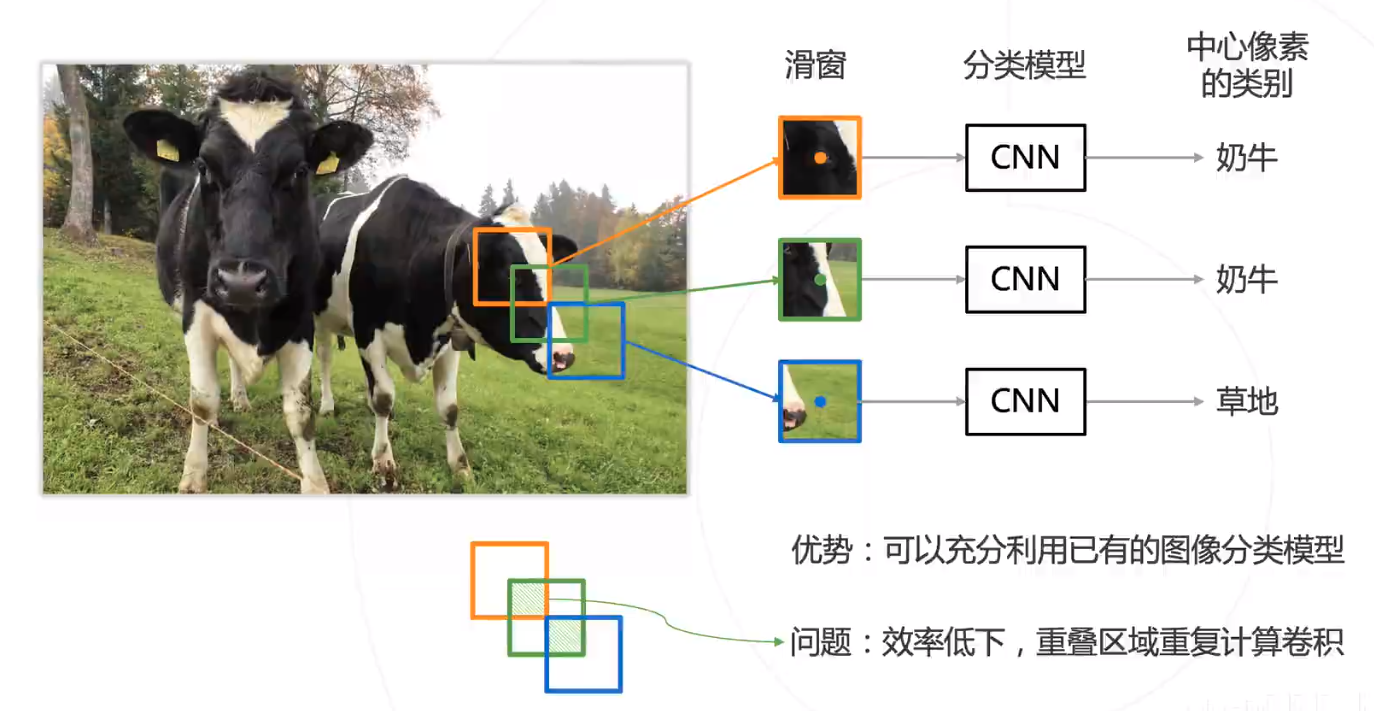
解决方法:复用卷积计算
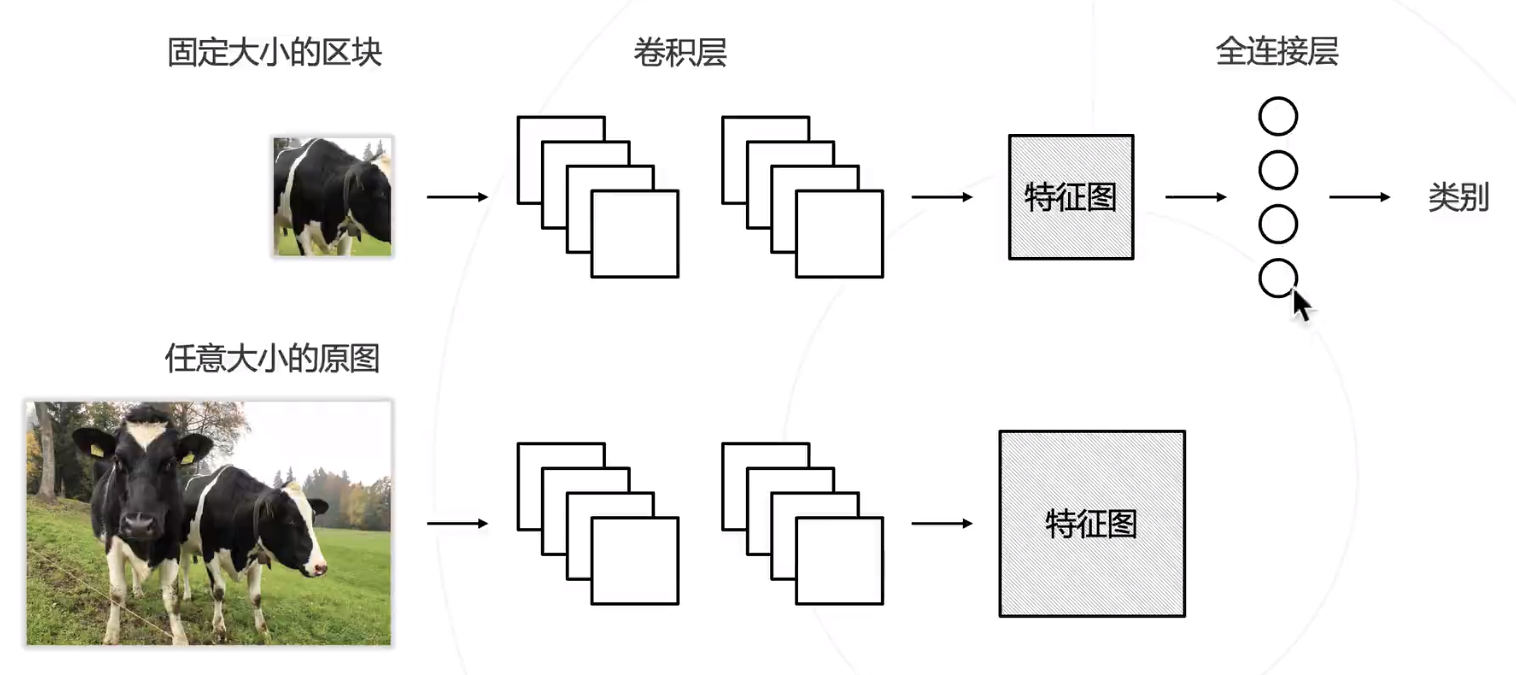
然后,将全连层卷积化
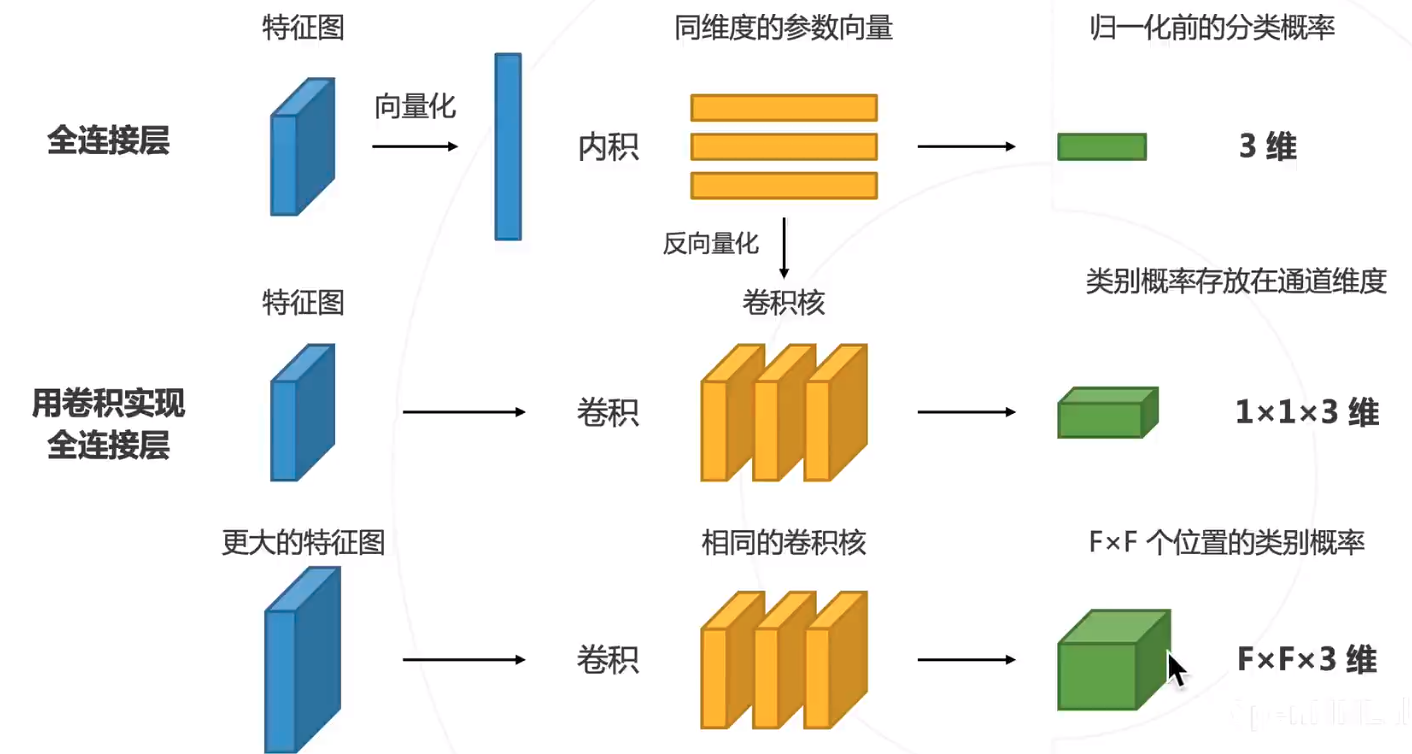
全卷积网络 Fully Convolutional Network 2015
论文链接:https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf
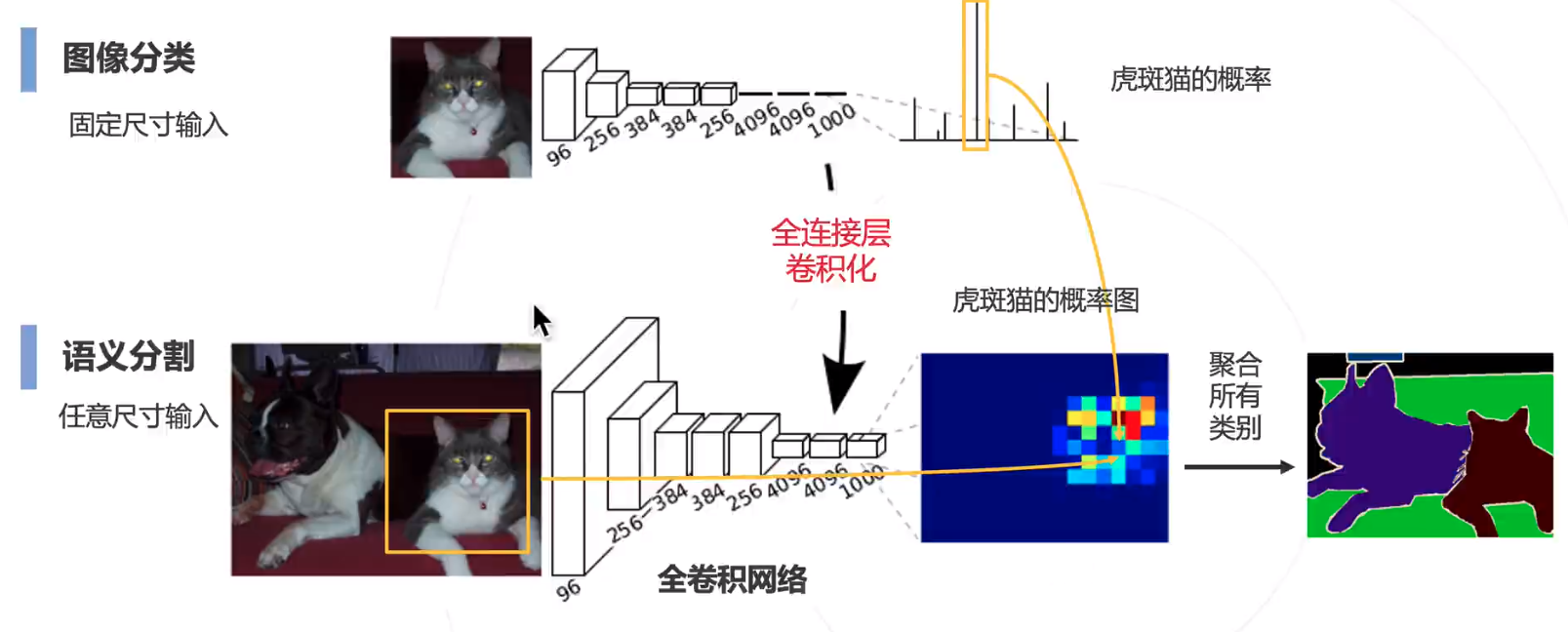
存在问题:
图像分类模型使用降采样层 (步长卷积或池化) 获得 高层次特征,导致全卷积网络输出尺寸小于原图,而分割要求同尺寸输出。解决方法如下。
解决方法 :
对预测的分割图升采样,恢复原图分辨率,升采样方案 :
- 双线性揷值
- 转置卷积 : 可学习的升采样层
双线性揷值 Bilinear Interpolation
计算过程:
已知的红色数据点与待插值得到的绿色点
假如我们想得到未知函数f在点P= (x,y) 的值,假设我们已知函数f在Q11 = (x1,y1)、Q12 = (x1,y2),Q21 = (x2,y1) 以及Q22 = (x2,y2) 四个点的值。
首先在x方向进行线性插值,得到R1和R2,然后在y方向进行线性插值,得到P.
这样就得到所要的结果f(x,y).
其中红色点Q11,Q12,Q21,Q22为已知的4个像素点.
第一步:X方向的线性插值,在Q12,Q22中插入蓝色点R2,Q11,Q21中插入蓝色点R1;
第二步 :Y方向的线性插值 ,通过第一步计算出的R1与R2在y方向上插值计算出P点。
线性插值的结果与插值的顺序无关。首先进行y方向的插值,然后进行x方向的插值,所得到的结果是一样的。双线性插值的结果与先进行哪个方向的插值无关。
如果选择一个坐标系统使得 的四个已知点坐标分别为 (0, 0)、(0, 1)、(1, 0) 和 (1, 1),那么插值公式就可以化简为
f(x,y)=f(0,0)(1-x)(1-y)+f(1,0)x(1-y)+f(0,1)(1-x)y+f(1,1)xy
在x与y方向上,z值成单调性特性的应用中,此种方法可以做外插运算,即可以求解Q1~Q4所构成的正方形以外的点的值。
双线性插值的一个显然的三维空间延伸是三线性插值。
三线性插值的方法可参看matlab中的interp3

转置卷积 Transposed Convolution,又称升卷积或者反卷积,但是在数学上和卷积不是逆运算的关系!
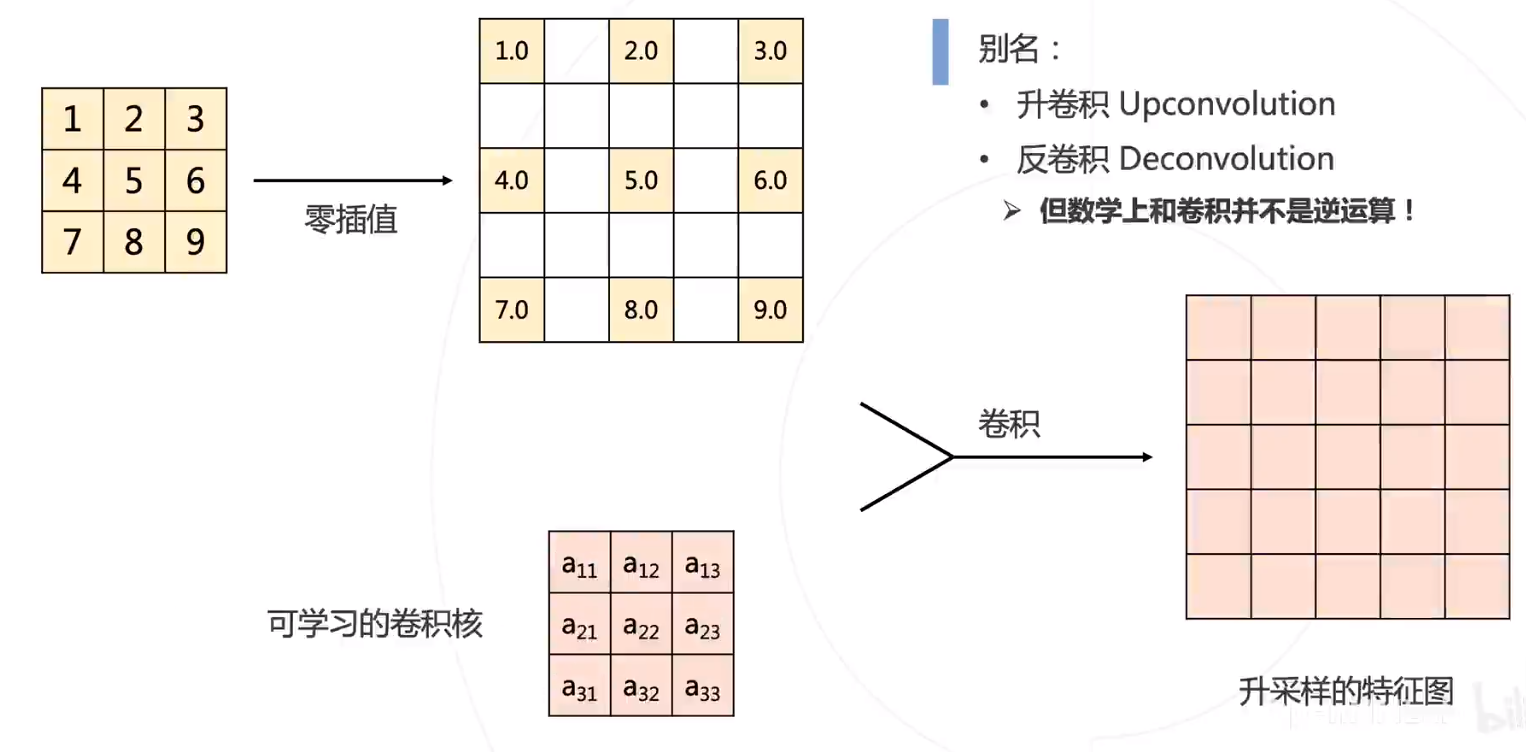
转置卷积的计算过程
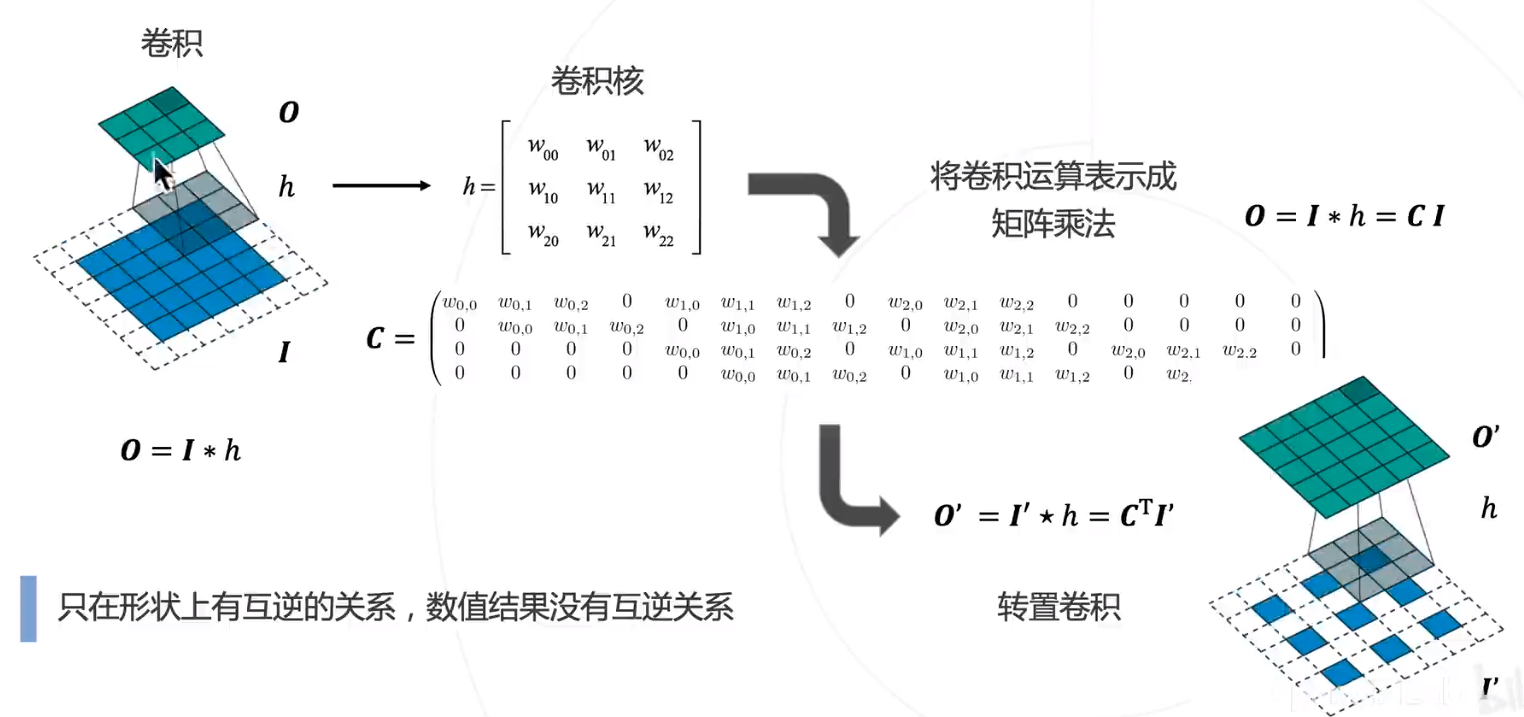
存在问题
基于顶层特征预测,再升采样 32 倍得到的预测图较为粗糙,高层特征经过多次降采样,细节丟失严重。
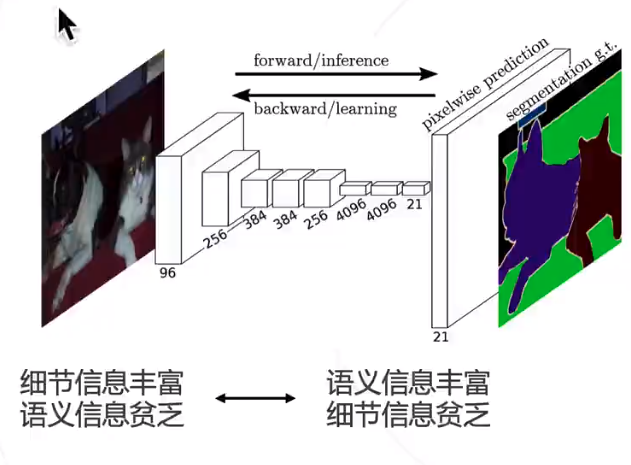
解决思路 : 结合低层次和高层次特征图。
基于多层级特征的上采样
论文链接:https://arxiv.org/abs/1411.4038
方法:基于低层次和高层次特征图分别产生类别预测,升采样到原图大小,再平均得到最终结果
核心思想:
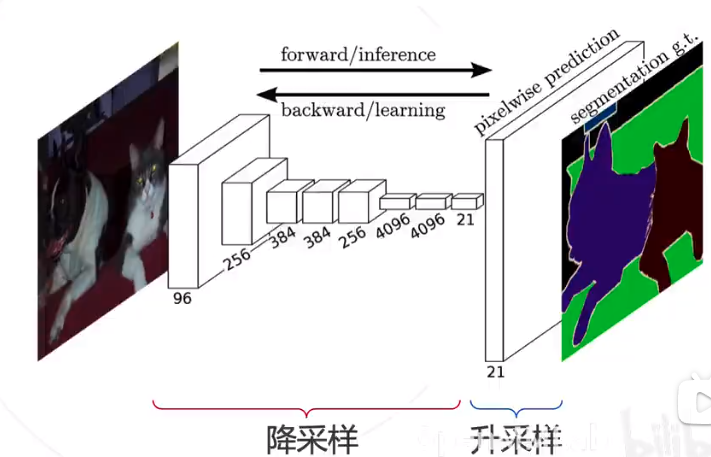
- 不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。
- 增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。
- 结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
对于FCN-32s,直接对pool5 feature进行32倍上采样获得32x upsampled feature,再对32x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。
对于FCN-16s,首先对pool5 feature进行2倍上采样获得2x upsampled feature,再把pool4 feature和2x upsampled feature逐点相加,然后对相加的feature进行16倍上采样,并softmax prediction,获得16x upsampled feature prediction。
对于FCN-8s,首先进行pool4+2x upsampled feature逐点相加,然后又进行pool3+2x upsampled逐点相加,即进行更多次特征融合。
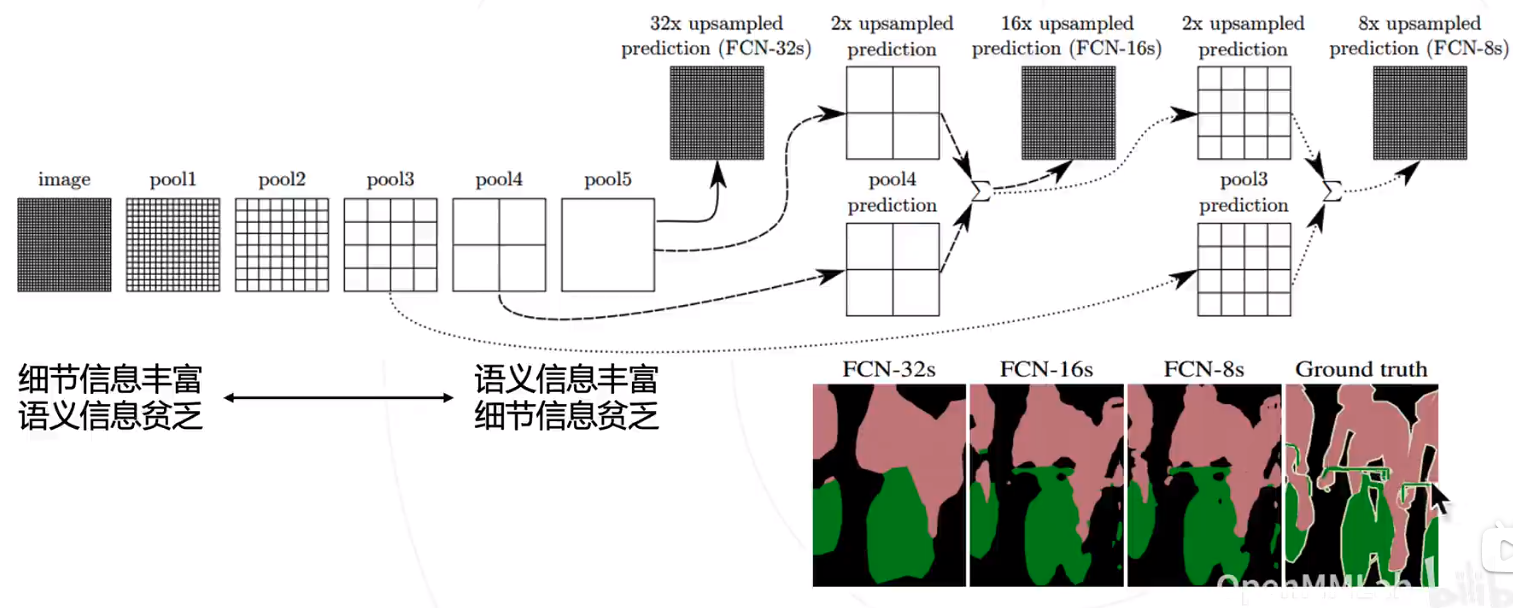
FCN缺点:
结果不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
UNet 20115
论文链接:https://arxiv.org/pdf/1505.04597.pdf
整个U-Net网络结构类似于一个大型的字母U,与FCN都是很小的分割网络,既没有使用空洞卷积,也没有后接CRF,结构简单。
计算过程:
- 首先进行Conv+Pooling下采样;
- 然后反卷积进行上采样,crop之前的低层feature map,进行融合;
- 再次上采样。
- 重复这个过程,直到获得输出388x388x2的feature map,
- 最后经过softmax获得output segment map。总体来说与FCN思路非常类似。
UNet的encoder下采样4次,一共下采样16倍,对称地,其decoder也相应上采样4次,将encoder得到的高级语义特征图恢复到原图片的分辨率。
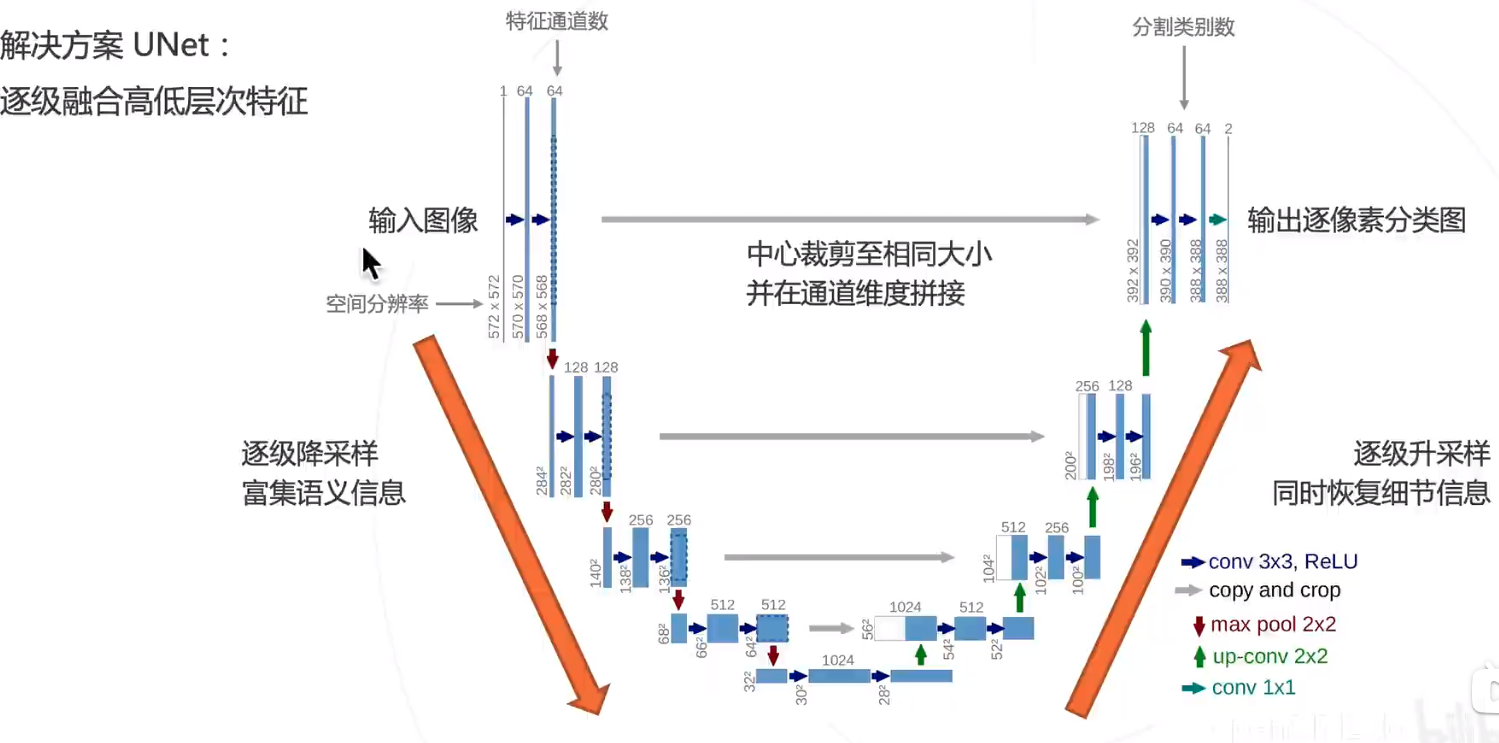
特征融合方式:
- FCN采用的是逐点相加,对应tensorflow的tf.add()函数
- U-Net采用的是channel维度拼接融合,对应tensorflow的tf.concat()函数
PSPNet 2016
论文链接:https://arxiv.org/abs/1612.01105
作者在ADE20K数据集上进行实验时,主要发现有如下3个问题:
- 错误匹配,FCN模型把水里的船预测成汽车,但是汽车是不会在水上的。因此,作者认为FCN缺乏收集上下文能力,导致了分类错误。
- 作者发现相似的标签会导致一些奇怪的错误,比如earth和field,mountain和hill,wall,house,building和skyscraper。FCN模型会出现混淆。
- 小目标的丢失问题,像一些路灯、信号牌这种小物体,很难被FCN所发现。相反的,一些特别大的物体预测中,在感受野不够大的情况下,往往会丢失一部分信息,导致预测不连续。
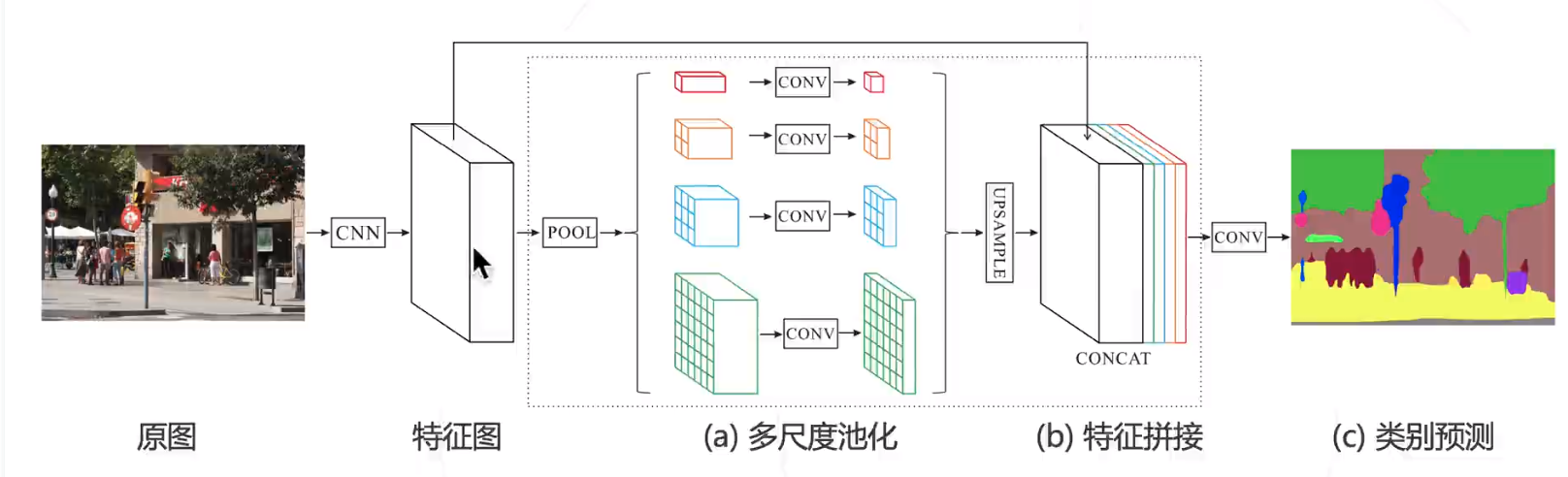
为了解决这些问题,作者提出了Pyramid Pooling Module。
在深层网络中,感受野的大小大致上体现了模型能获得的上下文新消息。尽管在理论上Resnet的感受野已经大于图像尺寸,但是实际上会小得多。这就导致了很多网络不能充分的将上下文信息结合起来,于是作者就提出了一种全局的先验方法-全局平均池化。
在PPM模块中并联了四个不同大小的全局池化层,将原始的feature map池化生成不同级别的特征图,经过卷积和上采样恢复到原始大小。这种操作聚合了多尺度的图像特征,生成了一个“hierarchical global prior”,融合了不同尺度和不同子区域之间的信息。最后,这个先验信息再和原始特征图进行相加,输入到最后的卷积模块完成预测。
pspnet的核心就是PPM模块。其网络架构十分简单,backbone为resnet网络,将原始图像下采样8倍成特征图,特征图输入到PPM模块,并与其输出相加,最后经过卷积和8倍双线性差值上采样得到结果如下图:。
DeepLab系列
DeepLab 是语义分割的又一系列工作,其主要贡献为:
- 使用空洞卷积解决网络中的下采样问题
- 使用条件随机场 CRF 作为后处理手段,精细化分割图
- 使用多尺度的空洞卷积 ( ASPP 模块) 捕捉上下文信息
DeepLab v1 发表于 2014 年,后于 2016、2017、2018 年提出 v2、v3、v3+ 版本。
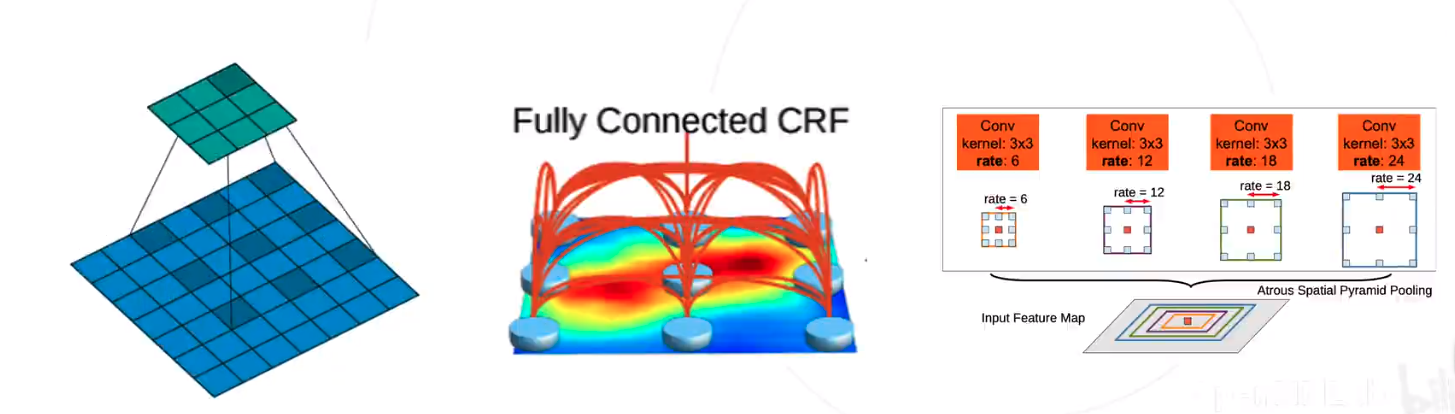
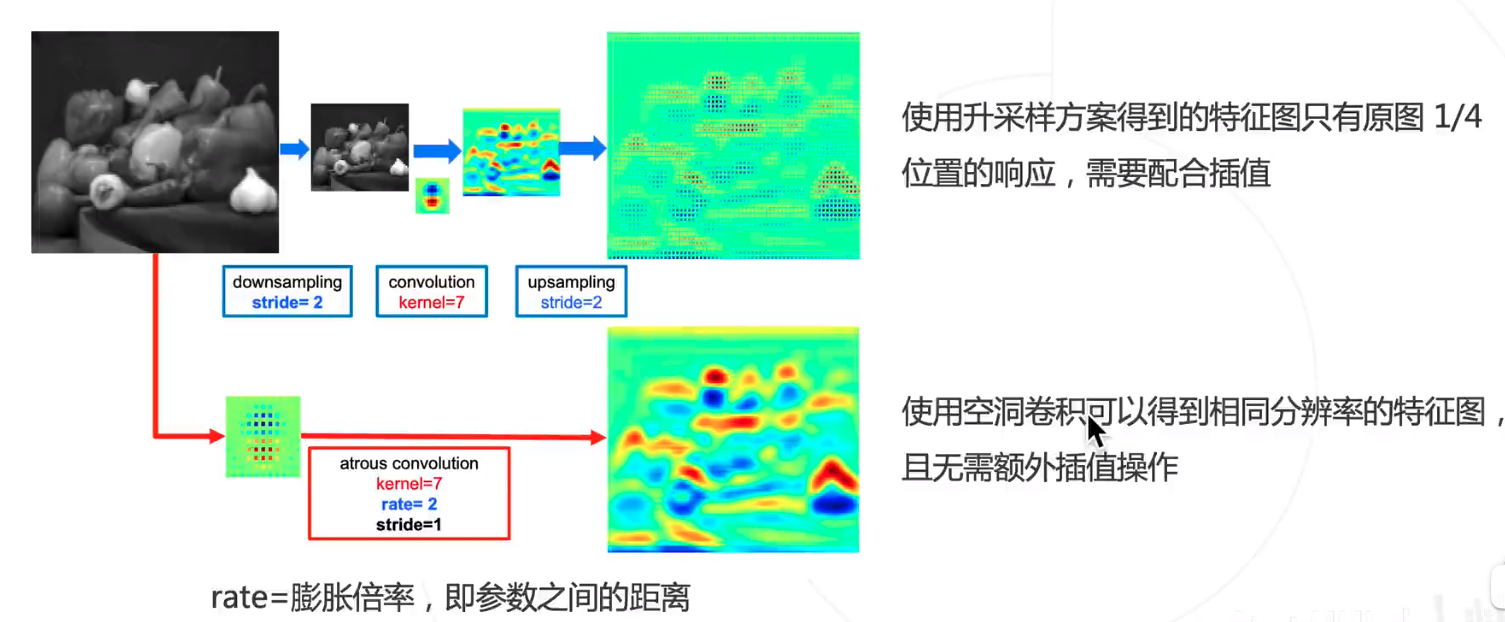
空洞卷积解决下采样问题
图像分类模型中的下采样层使输出尺寸变小
如果将池化层和卷积中的步长去掉 :
- 可以减少下采样的次数 ;
- 特征图就会变大,需要对应增大卷积核,以维持相同的感受野,但会增加大量参数
- 使用空洞卷积 ( Dilated Convolution/Atrous Convolution ),在不增加参数的情况下增大感受野

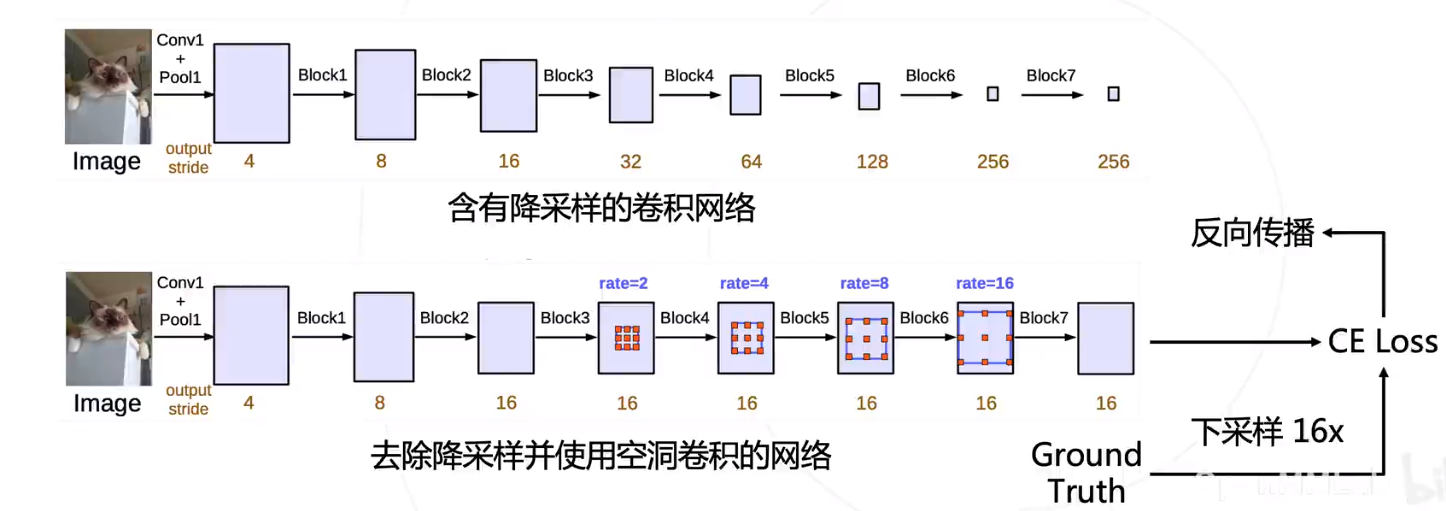
DeepLab模型
DeepLab 在图像分类网络的基础上做了修改 :
- 去除分类模型中的后半部分的下采样层
- 后续的卷积层改为膨胀卷积,并且逐步增加rate来维持原网络的感受野
条件随机场 Conditional Random Field, CRF
模型直接输出的分割图较为粗䊁,尤其在物体边界处不能产生很好的分割结果。
DeepLab v1&v2 使用条件随机场 (CRF) 作为后处理手段,结合原图颜色信息和神经网络预测的类 别得到精细化分割结果。
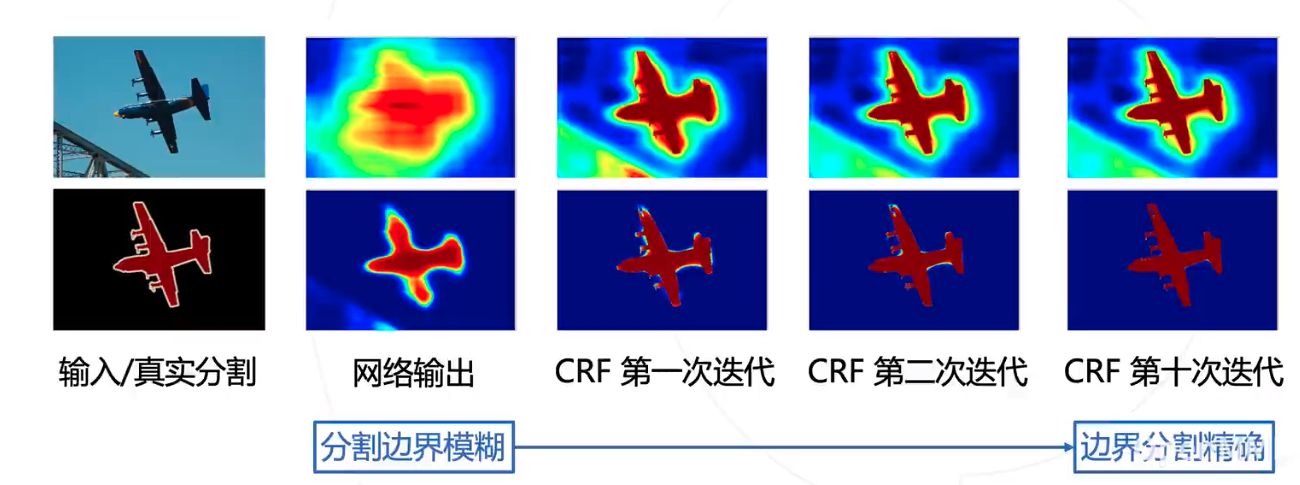
CRF 是一种概率模型。DeepLab 使用 CRF 对分割结果进行建模,用能量函数用来表示分割结 果优劣,通过最小化能量函数获得更好的分割结果。

空间金字塔池化 Atrous Spatial Pyramid Pooling ASPP
PSPNet 使用不同尺度的池化来获取不同尺度的上下文信息
DeepLab v2 & v3 使用不同尺度的空洞卷积达到类似的效果
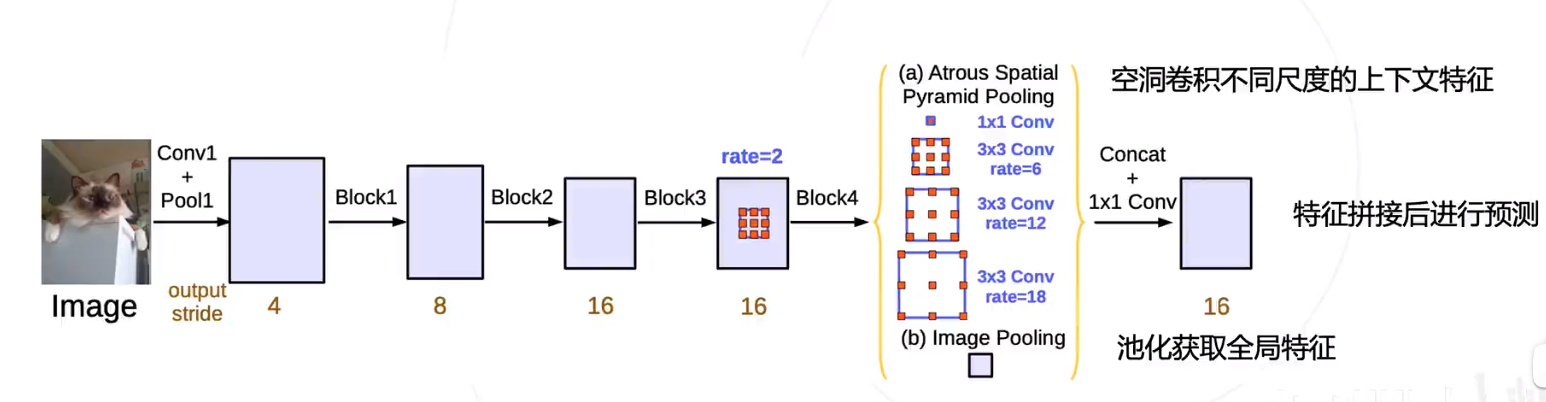
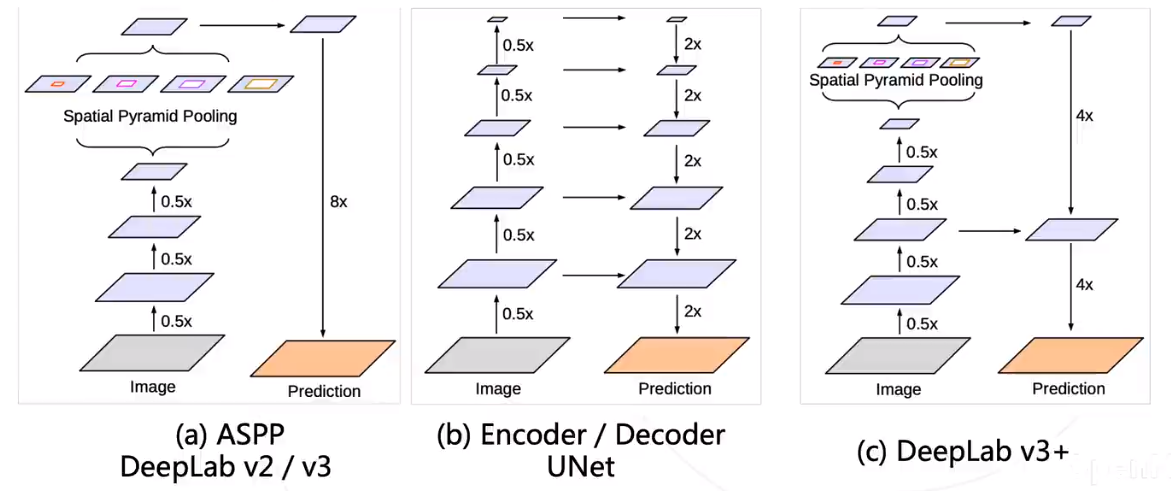
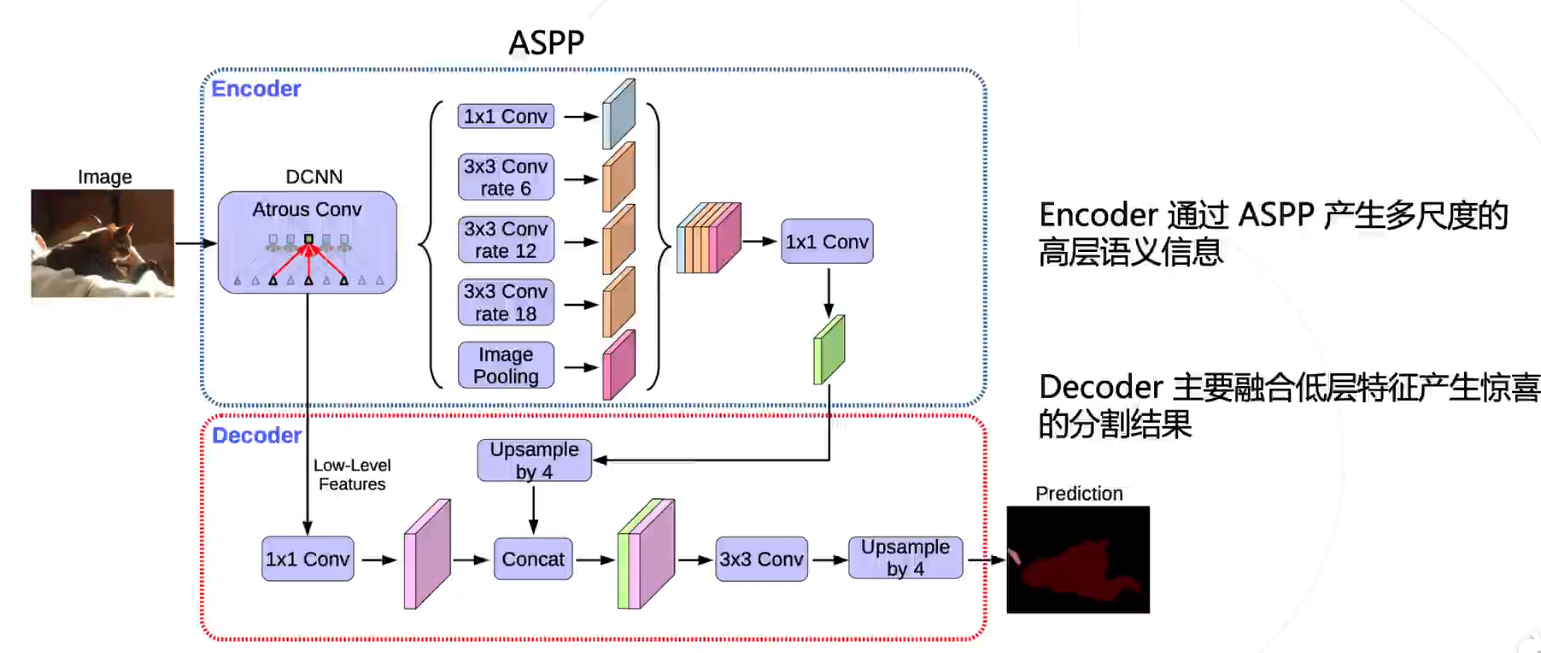
DeepLab V3+
- DeepLab v2 / v3 模型使用 ASPP 捕捉上下文特征
- Encoder / Decoder 结构 (如 UNet ) 在上采样过程中融入低层次的特征图,以获得更精细的分割图
- DeepLab v3+ 将两种思路融合,在原有模型结构上增加了一个简单的 decoder 结构
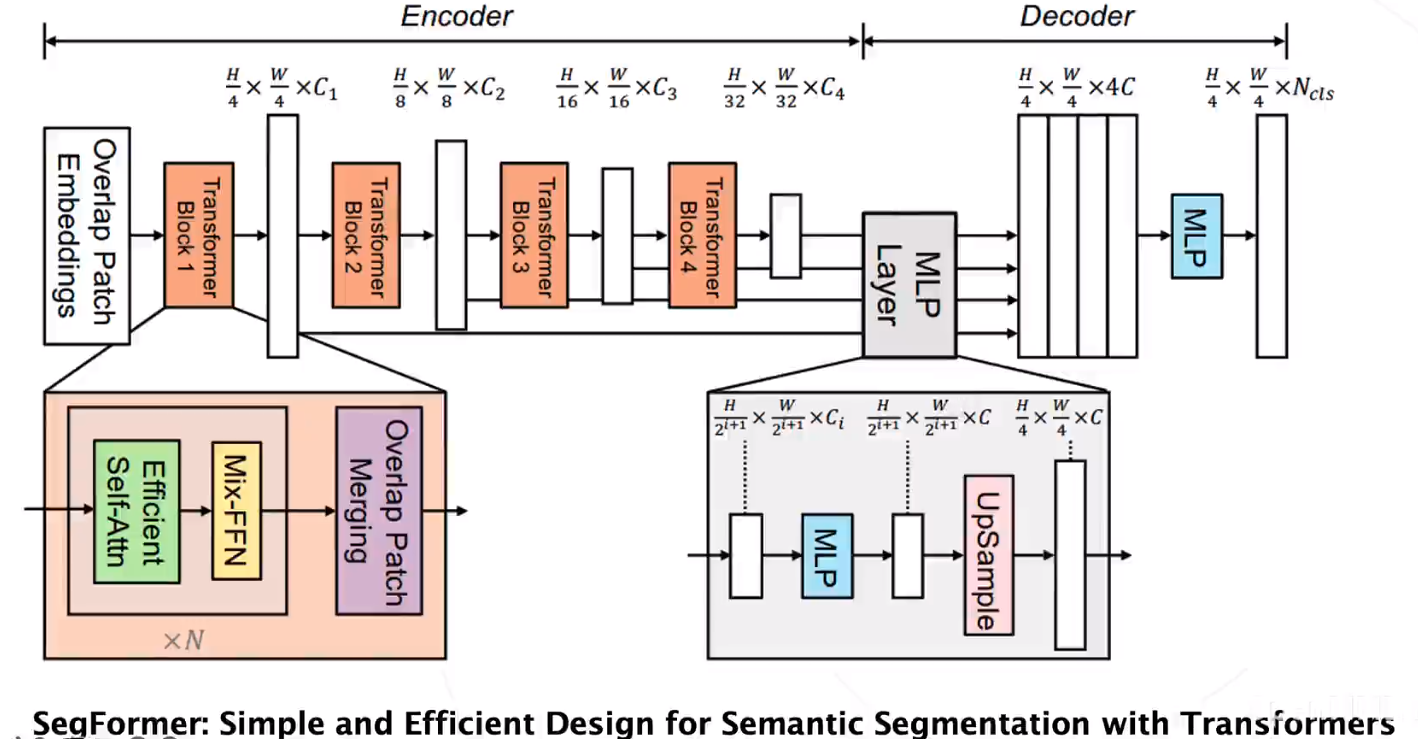
SegFormer
论文链接:https://arxiv.org/abs/2105.15203
SegFormer主要包含2个模块:
(1)Encoder:分层的Transformer产生高分辨率低级特征和低分辨率的细节特征;
(2)Decoder:轻量级的全MLP解码器融合多级特征得到语义分割结果。
K-Net
论文链接:https://arxiv.org/abs/2106.14855
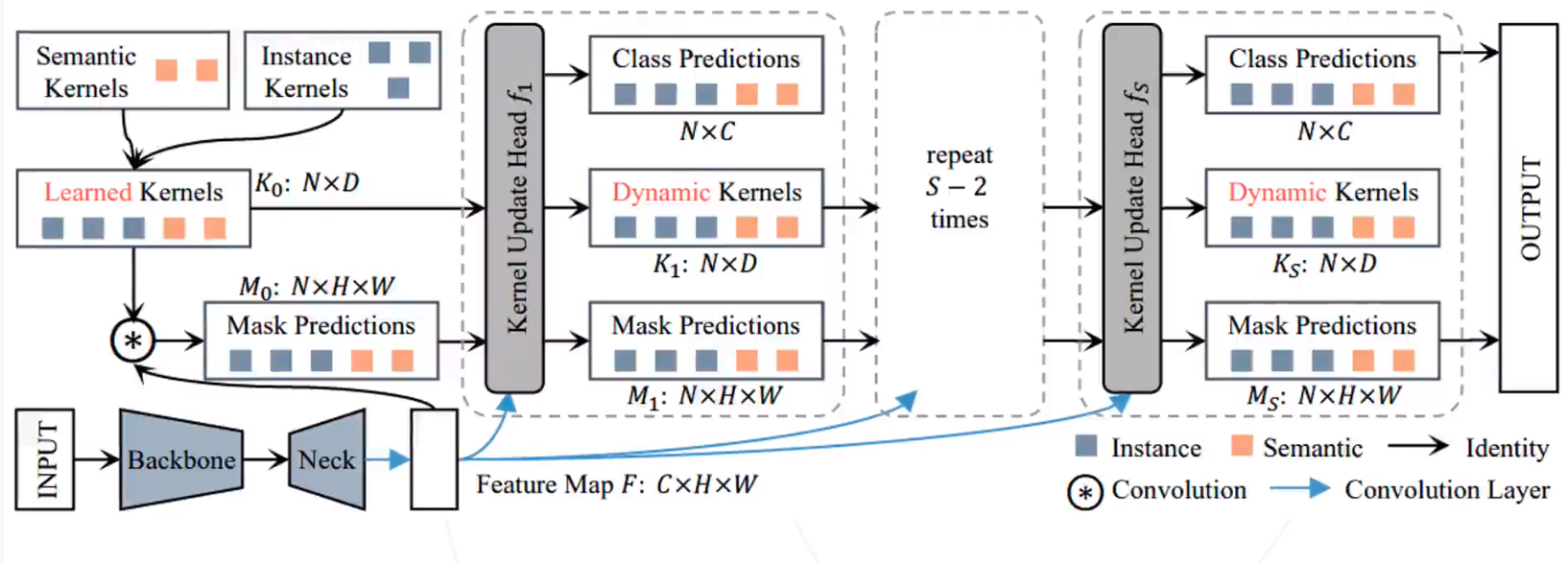
K-Net:针对语义分割、实例分割和全景分割三个任务,K-Net提出了一种基于动态内核的分割模型,为每个任务分配不同的核来实现多任务统一。
MaskFormer
论文链接:https://arxiv.org/abs/2107.06278
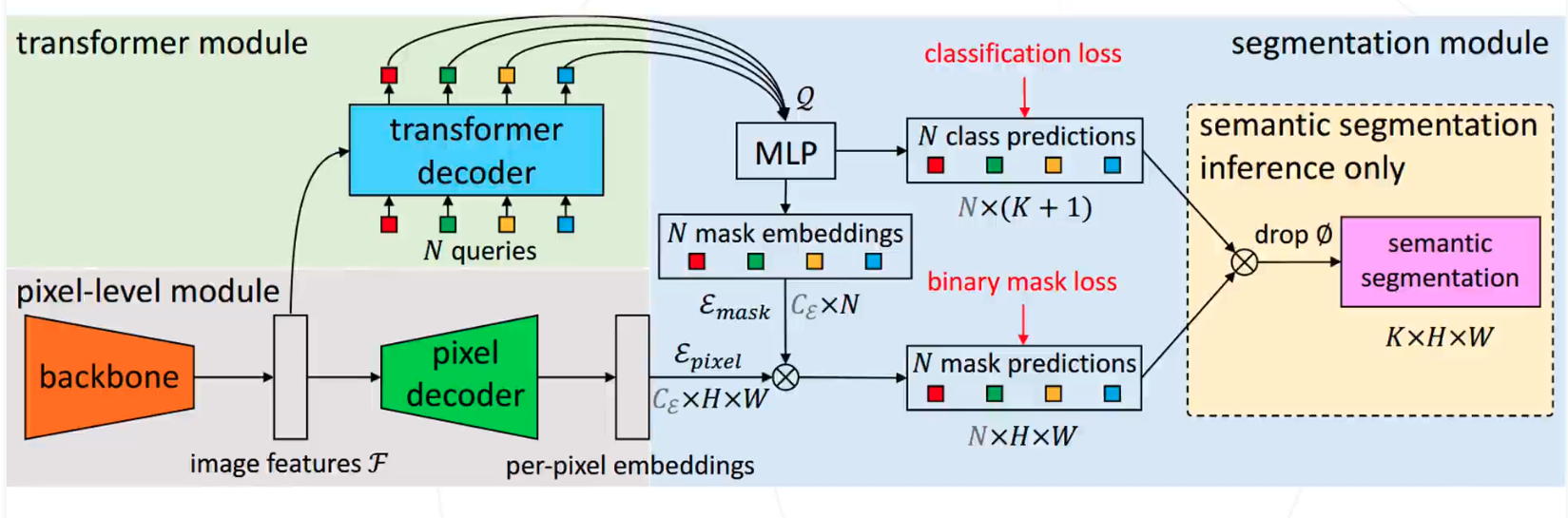
Mask2Former
论文链接:https://arxiv.org/abs/2112.01527
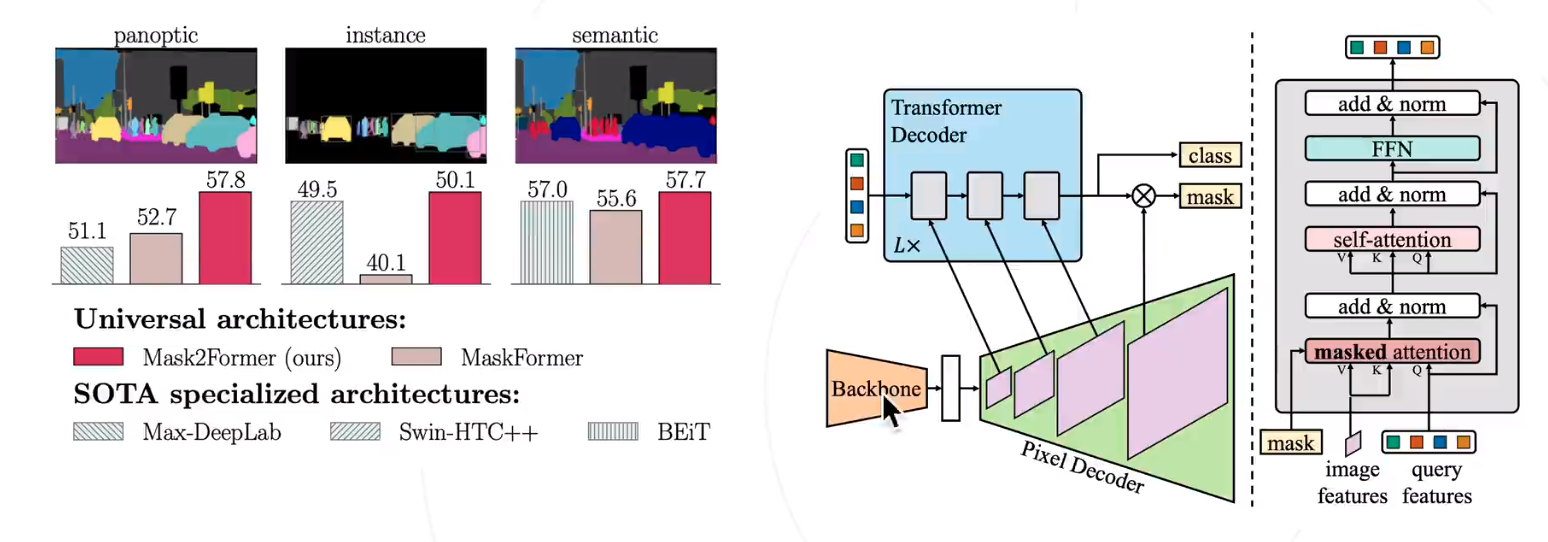
SAM
论文翻译:https://blog.csdn.net/m0_47867638/article/details/130303685

OpenMMLab的Playground就是基于SAM的标注工具!
评估
比较预测和真值

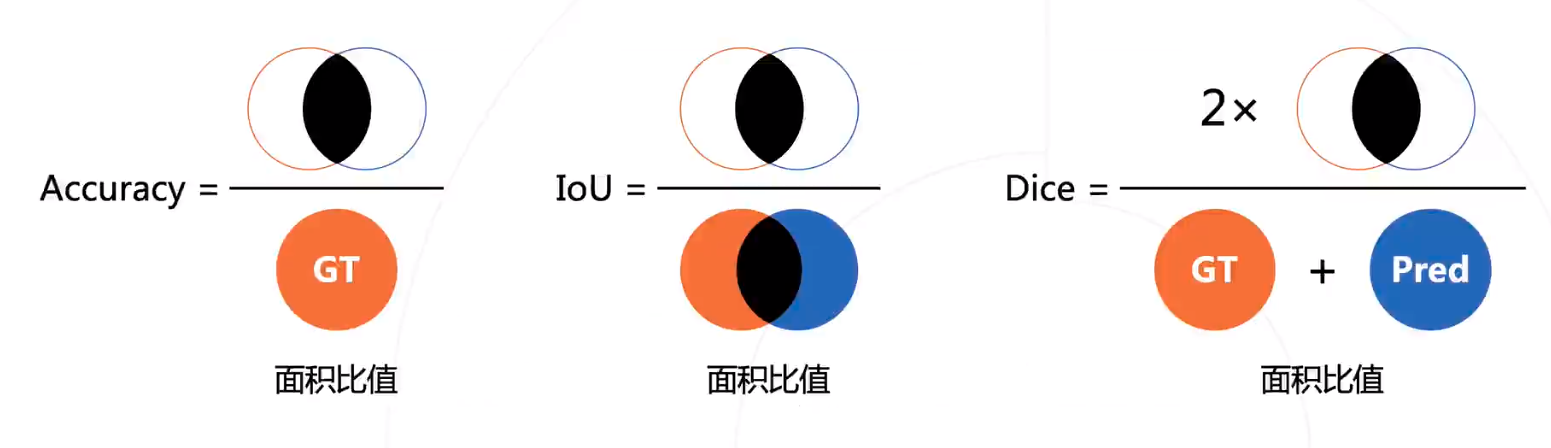
评估指标
- Jaccard(IoU)
用于比较有限样本集之间的相似性与差异性。Jaccard值越大, 样本相似度越高。
- Dice相似系数
一种集合相似度度量指标, 通常用于计算两个样本的相似度, 值的范围0 1, 分割结果最好时值为 1 , 最差时值为 0 。Dice相似系数对mask的内部填充比较敏感。

- 点赞
- 收藏
- 关注作者
评论(0)