AI实战营第二期 第六节 《MMDetection代码课》——笔记7

@[toc]
什么是MMDetection?
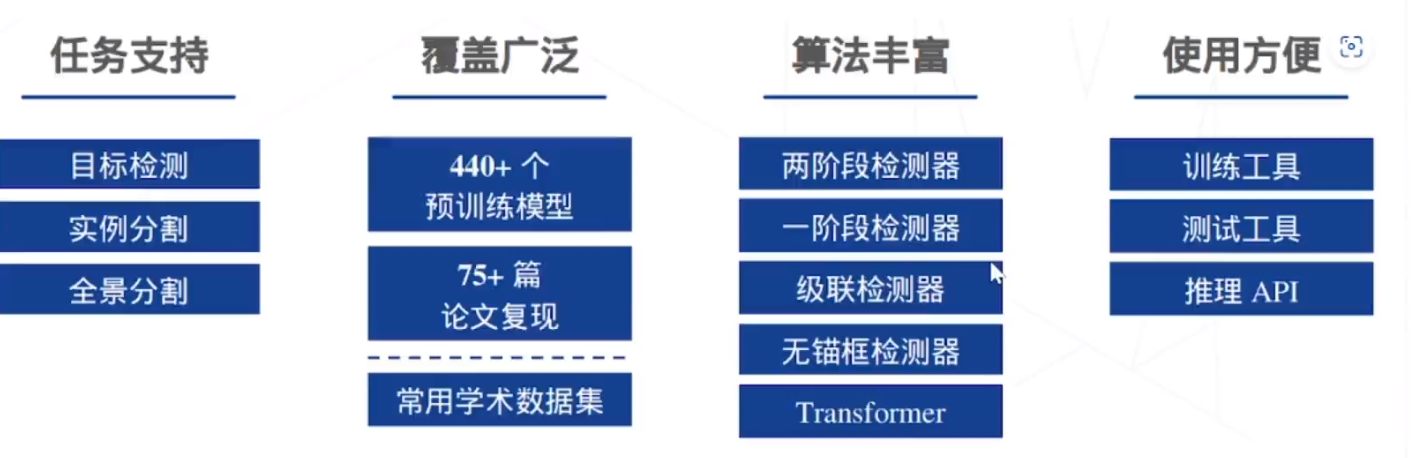
MMDetection 是被广泛使用的检测工具箱,包括了目标检侧、实例分割、全景分割等多个通用检测方向,并支持了 75+ 个主流和前沿模型, 为用户提供超过 440+ 个预训练模型, 在学术研究和工业落地中拥有广泛应用。该恇架的主要特点为:
模块化设计。MMDetection 将检测框架解耦成不同的模块组件,通过组合不同的模块组件,用户可以便捷地构建自定义的检测模型
支持多种检测任务。MMDetection 支持了各种不同的检测任务,包括目标检测,实例分割,全景分割,以及半监督目标检测。
速度快。基本的框和 mask 操作都实现了 GPU 版本,训练速度比其他代码库更快或者相当,包括 Detectron2, maskrcnn-benchmark 和 SimpleDet。
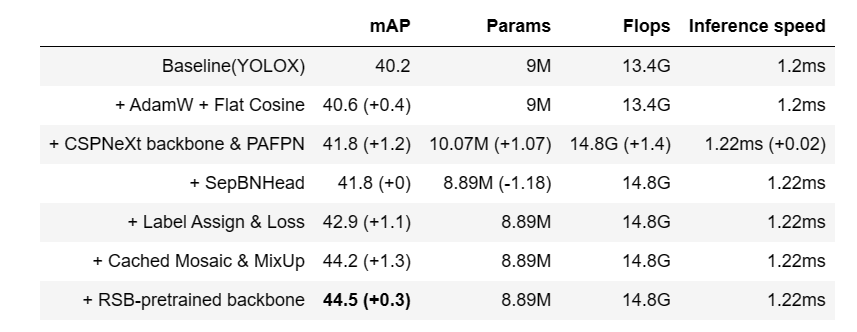
性能高。MMDetection 这个算法库源自于 COCO 2018 目标检测竞赛的冠军团队 MMDet 团队开发的代码,我们在之后持续进行了改进和提升。 新发布的 RTMDet 还在实时实例分割和旋转目标检测任务中取得了最先进的成果,同时也在目标检测模型中取得了最佳的的参数量和精度平衡。
MMDetection 这个算法库源自于 COCO 2018 目标检测竞赛的冠军团队 MMDet 团队开发的代码,我们在之后持续进行了改进和提升。 新发布的 RTMDet 还在实时实例分割和旋转目标检测任务中取得了最先进的成果,同时也在目标检测模型中取得了最佳的的参数量和精 度平衡。
MMDetection Repo: https://github.com/open-mmlab/mmdetection/
MMDetection 官方文档链接: https://mmdetection.readthedocs.io/en/latest/
下面我们将以 MMDetection 团队自研的 RTMDet 算法为例,结合一个简单的 cat 数据集来描述整个训练推理可视化过程。 本教程一共包括如下流程:
- 数据集准备和可视化
- 自定义配置文件
- 训练前可视化验证
- 模型训练
- 模型测试和推理
- 可视化分析
注意事项:为了方便大家复现,本教程配套的 Notebook 将位于 https://github.com/open-mmlab/mmdetection/tree/tutorials 处。
环境检测和安装
在开始前,需要先检测环境并安装 MMDetection 及其依赖
# Check nvcc version
!nvcc -V
# Check GCC version
!gcc --version
配置环境
# 安装 mmengine 和 mmcv 依赖
# 为了防止后续版本变更导致的代码无法运行,我们暂时锁死版本
pip install -U openmim==0.3.7
mim install mmengine==0.7.1
mim install mmcv==2.0.0
# Install mmdetection
!rm -rf mmdetection
# 为了防止后续更新导致的可能无法运行,特意新建了 tutorials 分支
git clone -b tutorials https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -e .
打印环境信息
from mmengine.utils import get_git_hash
from mmengine.utils.dl_utils import collect_env as collect_base_env
import mmdet
# 环境信息收集和打印
def collect_env():
"""Collect the information of the running environments."""
env_info = collect_base_env()
env_info['MMDetection'] = f'{mmdet.__version__}+{get_git_hash()[:7]}'
return env_info
if __name__ == '__main__':
for name, val in collect_env().items():
print(f'{name}: {val}')
1 数据集准备和可视化
我们提供了一个简单的 cat 猫数据集,该数据集来自社区用户,总共包括 144 张图片,并且已经提前划分为了训练集和测试集。
# 数据集下载
!rm -rf cat_dataset*
!wget https://download.openmmlab.com/mmyolo/data/cat_dataset.zip
!unzip cat_dataset.zip -d cat_dataset && rm cat_dataset.zip

可视化数据
# 数据集可视化
import os
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
original_images = []
images = []
texts = []
plt.figure(figsize=(16, 5))
image_paths= [filename for filename in os.listdir('cat_dataset/images')][:8]
for i,filename in enumerate(image_paths):
name = os.path.splitext(filename)[0]
image = Image.open('cat_dataset/images/'+filename).convert("RGB")
plt.subplot(2, 4, i+1)
plt.imshow(image)
plt.title(f"{filename}")
plt.xticks([])
plt.yticks([])
plt.tight_layout()

我们也提供了 coco json 标注,用户可以直接使用,而无需自己重新标注。COCO Json 可视化如下所示
from pycocotools.coco import COCO
import numpy as np
import os.path as osp
from matplotlib.collections import PatchCollection
from matplotlib.patches import Polygon
def apply_exif_orientation(image):
_EXIF_ORIENT = 274
if not hasattr(image, 'getexif'):
return image
try:
exif = image.getexif()
except Exception:
exif = None
if exif is None:
return image
orientation = exif.get(_EXIF_ORIENT)
method = {
2: Image.FLIP_LEFT_RIGHT,
3: Image.ROTATE_180,
4: Image.FLIP_TOP_BOTTOM,
5: Image.TRANSPOSE,
6: Image.ROTATE_270,
7: Image.TRANSVERSE,
8: Image.ROTATE_90,
}.get(orientation)
if method is not None:
return image.transpose(method)
return image
def show_bbox_only(coco, anns, show_label_bbox=True, is_filling=True):
"""Show bounding box of annotations Only."""
if len(anns) == 0:
return
ax = plt.gca()
ax.set_autoscale_on(False)
image2color = dict()
for cat in coco.getCatIds():
image2color[cat] = (np.random.random((1, 3)) * 0.7 + 0.3).tolist()[0]
polygons = []
colors = []
for ann in anns:
color = image2color[ann['category_id']]
bbox_x, bbox_y, bbox_w, bbox_h = ann['bbox']
poly = [[bbox_x, bbox_y], [bbox_x, bbox_y + bbox_h],
[bbox_x + bbox_w, bbox_y + bbox_h], [bbox_x + bbox_w, bbox_y]]
polygons.append(Polygon(np.array(poly).reshape((4, 2))))
colors.append(color)
if show_label_bbox:
label_bbox = dict(facecolor=color)
else:
label_bbox = None
ax.text(
bbox_x,
bbox_y,
'%s' % (coco.loadCats(ann['category_id'])[0]['name']),
color='white',
bbox=label_bbox)
if is_filling:
p = PatchCollection(
polygons, facecolor=colors, linewidths=0, alpha=0.4)
ax.add_collection(p)
p = PatchCollection(
polygons, facecolor='none', edgecolors=colors, linewidths=2)
ax.add_collection(p)
coco = COCO('cat_dataset/annotations/test.json')
image_ids = coco.getImgIds()
np.random.shuffle(image_ids)
plt.figure(figsize=(16, 5))
# 只可视化 8 张图片
for i in range(8):
image_data = coco.loadImgs(image_ids[i])[0]
image_path = osp.join('cat_dataset/images/',image_data['file_name'])
annotation_ids = coco.getAnnIds(
imgIds=image_data['id'], catIds=[], iscrowd=0)
annotations = coco.loadAnns(annotation_ids)
ax = plt.subplot(2, 4, i+1)
image = Image.open(image_path).convert("RGB")
# 这行代码很关键,否则可能图片和标签对不上
image=apply_exif_orientation(image)
ax.imshow(image)
show_bbox_only(coco, annotations)
plt.title(f"{filename}")
plt.xticks([])
plt.yticks([])
plt.tight_layout()

2 自定义配置文件
本教程采用 RTMDet 进行演示,在开始自定义配置文件前,先来了解下 RTMDet 算法。
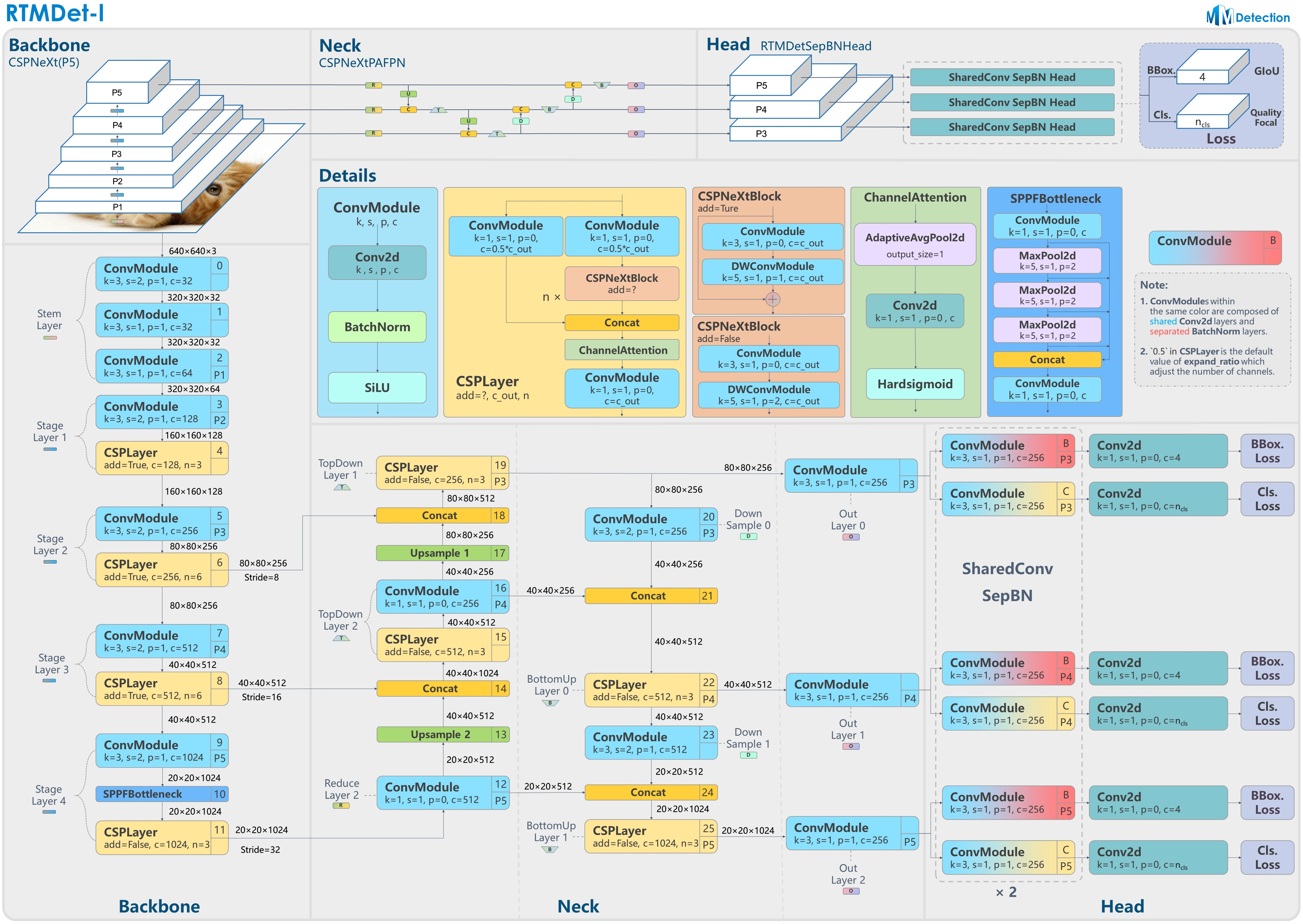
其模型架构图如上所示。RTMDet 是一个高性能低延时的检测算法,目前已经实现了目标检测、实例分割和旋转框检测任务。其简要描述为:为了获得更高效的模型架构,MMDetection 探索了一种具有骨干和 Neck 兼容容量的架构,由一个基本的构建块构成,其中包含大核深度卷积。MMDetection 进一步在动态标签分配中计算匹配成本时引入软标签,以提高准确性。结合更好的训练技巧,得到的目标检测器名为 RTMDet,在 NVIDIA 3090 GPU 上以超过 300 FPS 的速度实现了 52.8% 的 COCO AP,优于当前主流的工业检测器。RTMDet 在小/中/大/特大型模型尺寸中实现了最佳的参数-准确度权衡,适用于各种应用场景,并在实时实例分割和旋转对象检测方面取得了新的最先进性能。
论文链接:https://arxiv.org/abs/2212.07784
cat 是一个单类的数据集,而 MMDetection 中提供的是 COCO 80 类配置,因此我们需要对一些重要参数通过配置来修改。
# 当前路径位于 mmdetection/tutorials, 配置将写到 mmdetection/tutorials 路径下
config_cat = """
_base_ = 'configs/rtmdet/rtmdet_tiny_8xb32-300e_coco.py'
data_root = 'cat_dataset/'
# 非常重要
metainfo = {
# 类别名,注意 classes 需要是一个 tuple,因此即使是单类,
# 你应该写成 `cat,` 很多初学者经常会在这犯错
'classes': ('cat',),
'palette': [
(220, 20, 60),
]
}
num_classes = 1
# 训练 40 epoch
max_epochs = 40
# 训练单卡 bs= 12
train_batch_size_per_gpu = 12
# 可以根据自己的电脑修改
train_num_workers = 4
# 验证集 batch size 为 1
val_batch_size_per_gpu = 1
val_num_workers = 2
# RTMDet 训练过程分成 2 个 stage,第二个 stage 会切换数据增强 pipeline
num_epochs_stage2 = 5
# batch 改变了,学习率也要跟着改变, 0.004 是 8卡x32 的学习率
base_lr = 12 * 0.004 / (32*8)
# 采用 COCO 预训练权重
load_from = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_tiny_8xb32-300e_coco/rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth' # noqa
model = dict(
# 考虑到数据集太小,且训练时间很短,我们把 backbone 完全固定
# 用户自己的数据集可能需要解冻 backbone
backbone=dict(frozen_stages=4),
# 不要忘记修改 num_classes
bbox_head=dict(dict(num_classes=num_classes)))
# 数据集不同,dataset 输入参数也不一样
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
pin_memory=False,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='annotations/trainval.json',
data_prefix=dict(img='images/')))
val_dataloader = dict(
batch_size=val_batch_size_per_gpu,
num_workers=val_num_workers,
dataset=dict(
metainfo=metainfo,
data_root=data_root,
ann_file='annotations/test.json',
data_prefix=dict(img='images/')))
test_dataloader = val_dataloader
# 默认的学习率调度器是 warmup 1000,但是 cat 数据集太小了,需要修改 为 30 iter
param_scheduler = [
dict(
type='LinearLR',
start_factor=1.0e-5,
by_epoch=False,
begin=0,
end=30),
dict(
type='CosineAnnealingLR',
eta_min=base_lr * 0.05,
begin=max_epochs // 2, # max_epoch 也改变了
end=max_epochs,
T_max=max_epochs // 2,
by_epoch=True,
convert_to_iter_based=True),
]
optim_wrapper = dict(optimizer=dict(lr=base_lr))
# 第二 stage 切换 pipeline 的 epoch 时刻也改变了
_base_.custom_hooks[1].switch_epoch = max_epochs - num_epochs_stage2
val_evaluator = dict(ann_file=data_root + 'annotations/test.json')
test_evaluator = val_evaluator
# 一些打印设置修改
default_hooks = dict(
checkpoint=dict(interval=10, max_keep_ckpts=2, save_best='auto'), # 同时保存最好性能权重
logger=dict(type='LoggerHook', interval=5))
train_cfg = dict(max_epochs=max_epochs, val_interval=10)
"""
with open('rtmdet_tiny_1xb12-40e_cat.py', 'w') as f:
f.write(config_cat)
需要注意几个问题:
自定义数据集中最重要的是 metainfo 字段,用户在配置完成后要记得将其传给 dataset,否则不生效(有些用户在自定义数据集时候喜欢去 直接修改 coco.py 源码,这个是强烈不推荐的做法,正确做法是配置 metainfo 并传给 dataset)
如果用户 metainfo 配置不正确,通常会出现几种情况:(1) 出现 num_classes 不匹配错误 (2) loss_bbox 始终为 0 (3) 出现训练后评估结果为空等典型情况
MMDetection 提供的学习率大部分都是基于 8 卡,如果你的总 bs 不同,一定要记得缩放学习率,否则有些算法很容易出现 NAN,具体参考 https://mmdetection.readthedocs.io/zh_CN/latest/user_guides/train.html#id3
3 训练前可视化验证
我们可以采用 mmdet 提供的 tools/analysis_tools/browse_dataset.py 脚本来对训练前的 dataloader 输出进行可视化,确保数据部分没有问题。 考虑到我们仅仅想可视化前几张图片,因此下面基于 browse_dataset.py 实现一个简单版本即可。
from mmdet.registry import DATASETS, VISUALIZERS
from mmengine.config import Config
from mmengine.registry import init_default_scope
cfg = Config.fromfile('rtmdet_tiny_1xb12-40e_cat.py')
init_default_scope(cfg.get('default_scope', 'mmdet'))
dataset = DATASETS.build(cfg.train_dataloader.dataset)
visualizer = VISUALIZERS.build(cfg.visualizer)
visualizer.dataset_meta = dataset.metainfo
plt.figure(figsize=(16, 5))
# 只可视化前 8 张图片
for i in range(8):
item=dataset[i]
img = item['inputs'].permute(1, 2, 0).numpy()
data_sample = item['data_samples'].numpy()
gt_instances = data_sample.gt_instances
img_path = osp.basename(item['data_samples'].img_path)
gt_bboxes = gt_instances.get('bboxes', None)
gt_instances.bboxes = gt_bboxes.tensor
data_sample.gt_instances = gt_instances
visualizer.add_datasample(
osp.basename(img_path),
img,
data_sample,
draw_pred=False,
show=False)
drawed_image=visualizer.get_image()
plt.subplot(2, 4, i+1)
plt.imshow(drawed_image[..., [2, 1, 0]])
plt.title(f"{osp.basename(img_path)}")
plt.xticks([])
plt.yticks([])
plt.tight_layout()

4 模型训练
在验证数据流本身没有问题后,就可以开始进行训练了
python tools/train.py rtmdet_tiny_1xb12-40e_cat.py
运行完成后,会在当前路径下生成 work_dirs/rtmdet_tiny_1xb12-40e_cat 路径,内部存放了 log 和权重文件。
可以发现最佳性能为第 30 epoch 时候,性能为 85.2 mAP (注: 由于训练 epoch 很短,因此多次运行可能 mAP 会有 3~4 个点的差异)。
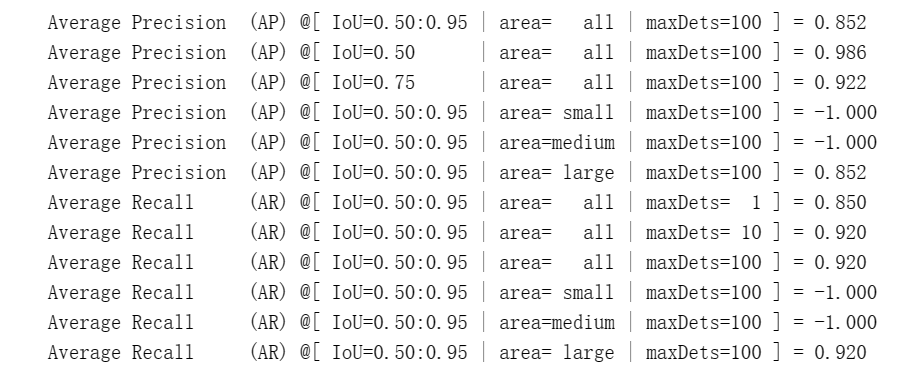
5 模型测试和推理
如果你想离线测试,则可以使用我们提供的 test.py 脚本
python tools/test.py rtmdet_tiny_1xb12-40e_cat.py work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth
在测试阶段,你可以设置 --show-dir 将测试图片的真实值和预测值保存下来,然后进行深入分析。
!python tools/test.py rtmdet_tiny_1xb12-40e_cat.py work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth --show-dir results
会在 work_dir/rtmdet_tiny_1xb12-40e_cat/当前时间戳/results/ 下生成测试图片,下面对前 8 张图片进行可视化
# 数据集可视化
import os
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
plt.figure(figsize=(20, 20))
# 你如果重新跑,这个时间戳是不一样的,需要自己修改
root_path='work_dirs/rtmdet_tiny_1xb12-40e_cat/20230517_120933/results/'
image_paths= [filename for filename in os.listdir(root_path)][:4]
for i,filename in enumerate(image_paths):
name = os.path.splitext(filename)[0]
image = Image.open(root_path+filename).convert("RGB")
plt.subplot(4, 1, i+1)
plt.imshow(image)
plt.title(f"{filename}")
plt.xticks([])
plt.yticks([])
plt.tight_layout()

左边显示的是标注框,右边显示的是预测框。
实际上 MMDetection 支持多种可视化后端,例如 TensorBoard 和 WandB,默认情况下是将图片保存到本地,用户只需要修改可视化部分配置即可轻松切换。如下所示
以下配置只需要加到 rtmdet_tiny_1xb12-40e_cat.py 配置最后即可
(1) 同时使用本地和 WandB 后端
visualizer = dict(vis_backends = [dict(type=‘LocalVisBackend’), dict(type=‘WandbVisBackend’)])
(2) 仅仅使用 TensorBoard 后端
visualizer = dict(vis_backends = [dict(type=‘TensorboardVisBackend’)])
修改配置后重新运行 test.py 即可在 WandB 和 TensorBoard 前端界面查看 图片和 log 等。
如果想对单张图片进行推理,你可以直接使用 mmdetection/demo/image_demo.py 脚本
!python demo/image_demo.py cat_dataset/images/IMG_20211102_003429.jpg rtmdet_tiny_1xb12-40e_cat.py --weights work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth
Image.open('outputs/vis/IMG_20211102_003429.jpg')

6 可视化分析
可视化分析包括特征图可视化以及类似 Grad CAM 等可视化分析手段。不过由于 MMDetection 中还没有实现,我们可以直接采用 MMYOLO 中提供的功能和脚本。MMYOLO 是基于 MMDetection 开发,并且此案有了统一的代码组织形式,因此 MMDetection 配置可以直接在 MMYOLO 中使用,无需更改配置。
MMYOLO 环境和依赖安装
!pwd
%cd ../
!rm -rf mmyolo
# 为了防止后续更新导致的可能无法运行,特意新建了 tutorials 分支
!git clone -b tutorials https://github.com/open-mmlab/mmyolo.git
%cd mmyolo
%pip install -e .
!pwd
特征图可视化
MMYOLO 中,将使用 MMEngine 提供的 Visualizer 可视化器进行特征图可视化,其具备如下功能:
支持基础绘图接口以及特征图可视化。
支持选择模型中的不同层来得到特征图,包含 squeeze_mean , select_max , topk 三种显示方式,用户还可以使用 arrangement 自定义特征图显示的布局方式。
你可以调用 demo/featmap_vis_demo.py 来简单快捷地得到可视化结果,为了方便理解,将其主要参数的功能梳理如下:
img:选择要用于特征图可视化的图片,支持单张图片或者图片路径列表。
config:选择算法的配置文件。
checkpoint:选择对应算法的权重文件。
–out-file:将得到的特征图保存到本地,并指定路径和文件名。
–device:指定用于推理图片的硬件,–device cuda:0 表示使用第 1 张 GPU 推理,–device cpu 表示用 CPU 推理。
–score-thr:设置检测框的置信度阈值,只有置信度高于这个值的框才会显示。
–preview-model:可以预览模型,方便用户理解模型的特征层结构。
–target-layers:对指定层获取可视化的特征图。
可以单独输出某个层的特征图,例如: --target-layers backbone , --target-layers neck , --target-layers backbone.stage4 等。
参数为列表时,也可以同时输出多个层的特征图,例如: --target-layers backbone.stage4 neck 表示同时输出 backbone 的 stage4 层和 neck 的三层一共四层特征图。
–channel-reduction:输入的 Tensor 一般是包括多个通道的,channel_reduction 参数可以将多个通道压缩为单通道,然后和图片进行叠加显示,有以下三个参数可以设置:
squeeze_mean:将输入的 C 维度采用 mean 函数压缩为一个通道,输出维度变成 (1, H, W)。
select_max:将输入先在空间维度 sum,维度变成 (C, ),然后选择值最大的通道。
None:表示不需要压缩,此时可以通过 topk 参数可选择激活度最高的 topk 个特征图显示。
–topk:只有在 channel_reduction 参数为 None 的情况下, topk 参数才会生效,其会按照激活度排序选择 topk 个通道,然后和图片进行叠加显示,并且此时会通过 --arrangement 参数指定显示的布局,该参数表示为一个数组,两个数字需要以空格分开,例如: --topk 5 --arrangement 2 3 表示以 2行 3列 显示激活度排序最高的 5 张特征图, --topk 7 --arrangement 3 3 表示以 3行 3列 显示激活度排序最高的 7 张特征图。
如果 topk 不是 -1,则会按照激活度排序选择 topk 个通道显示。
如果 topk = -1,此时通道 C 必须是 1 或者 3 表示输入数据是图片,否则报错提示用户应该设置 channel_reduction 来压缩通道。
考虑到输入的特征图通常非常小,函数默认将特征图进行上采样后方便进行可视化。
注意:当图片和特征图尺度不一样时候,draw_featmap 函数会自动进行上采样对齐。如果你的图片在推理过程中前处理存在类似 Pad 的操作此时得到的特征图也是 Pad 过的,那么直接上采样就可能会出现不对齐问题。
我们计划采用 cat_dataset/images/IMG_20211024_223313.jpg 图片进行后续可视化分析,不过由于这张图片分辨率过大,会导致程序奔溃,因此我们先将其缩放处理。
import cv2
img = cv2.imread('../mmdetection/cat_dataset/images/IMG_20211024_223313.jpg')
h,w=img.shape[:2]
resized_img = cv2.resize(img, (640, 640))
cv2.imwrite('resized_image.jpg', resized_img)
1. 可视化 backbone 输出的 3 个通道
!python demo/featmap_vis_demo.py \
resized_image.jpg \
../mmdetection/rtmdet_tiny_1xb12-40e_cat.py \
../mmdetection/work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth \
--target-layers backbone \
--channel-reduction squeeze_mean
Image.open('output/resized_image.jpg')

2. 可视化 neck 输出的 3 个通道
!python demo/featmap_vis_demo.py \
resized_image.jpg \
../mmdetection/rtmdet_tiny_1xb12-40e_cat.py \
../mmdetection/work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth \
--target-layers neck \
--channel-reduction squeeze_mean
Image.open('output/resized_image.jpg')


Grad-Based CAM 可视化
由于目标检测的特殊性,这里实际上可视化的并不是 CAM 而是 Grad Box AM。使用前需要先安装 grad-cam 库
(a) 查看 neck 输出的最小输出特征图的 Grad CAM
!python demo/boxam_vis_demo.py \
resized_image.jpg \
../mmdetection/rtmdet_tiny_1xb12-40e_cat.py \
../mmdetection/work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth \
--target-layer neck.out_convs[2]
Image.open('output/resized_image.jpg')

可以看出效果较好
(b) 查看 neck 输出的最大输出特征图的 Grad CAM
!python demo/boxam_vis_demo.py \
resized_image.jpg \
../mmdetection/rtmdet_tiny_1xb12-40e_cat.py \
../mmdetection/work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth \
--target-layer neck.out_convs[0]
Image.open('output/resized_image.jpg')

可以发现由于大物体不会在该层预测,因此梯度可视化是 0,符合预期。
检测新趋势
随着 ChatGPT 等的 LLM 飞速发展,传统的目标检测也逐渐发展为传统的封闭类别集合检测和自然语言相结合的开放类别检测(当然还有其他非常多结合检测的新方向)。典型的方向如:
Open-Vocabulary Object Detection,即开放词汇目标检测,给定图片和类别词汇表,检测所有物体
Grounding Object Detection,即给定图片和文本描述,预测文本中所提到的在图片中的物体位置
大家可以多关注这个新方向和新趋势。该方向的典型算法为 GLIP, 目前(2023.6)在 MMDetection 的 dev-3.x 中已经支持,其检测效果演示如下(如果你感兴趣,可以自己跑一下):
(1) 图片+ 语言描述:bench.car

上述输入的是固定类别名,因此等价于 Open-Vocabulary Object Detection。如果将类别名设置为 COCO 全部类别,那么其实就可以转变了常规的目标检测算法。
(2) 图片+ 语言描述:There are a lot of cars here.

上述输入是自然语言描述,因此等价于 Grounding Object Detection
当然随着 ChatGPT 的强大功能,一个模型可以完成非常多不可思议的事情,在视觉领域大家也开始倾向于研究大一统模型,例如通用图像分割模型,一个模型可以实现封闭集和开放集语义分割、实例分割、全景分割、图像描述等等任务,典型的如 X-Decoder
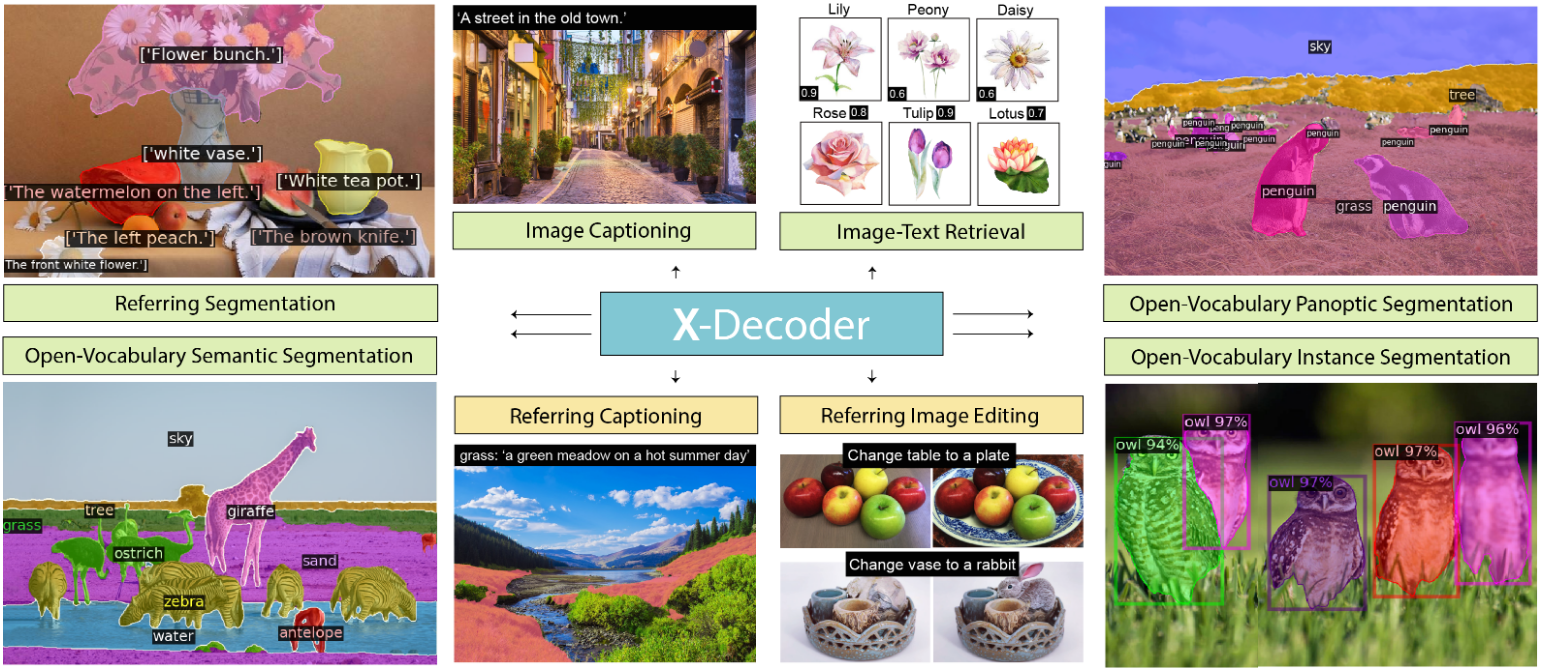
目前 MMDetection 也在支持该算法。后续 MMDetection 会重点支持多模态算法,欢迎有志之士来共同参与!
总结
本教程提供了从数据到推理的全流程,并进行了详细的可视化分析,最后简单分析和探讨了下目标检测新的发展趋势。希望本文对你有帮助!!!

- 点赞
- 收藏
- 关注作者
评论(0)