MMPose代码学习——笔记2

@[toc]
摘要
本节内容:
- 人体姿态估计的介绍与应用
- 2 D 姿态估计
- 自顶向下方法
- 自底向上方法
- 单阶段方法
- 基于Transformer的方法
- 3D 姿态估计
- 人体姿态估计的评估方法
- DensePose
- 人体参数化模型
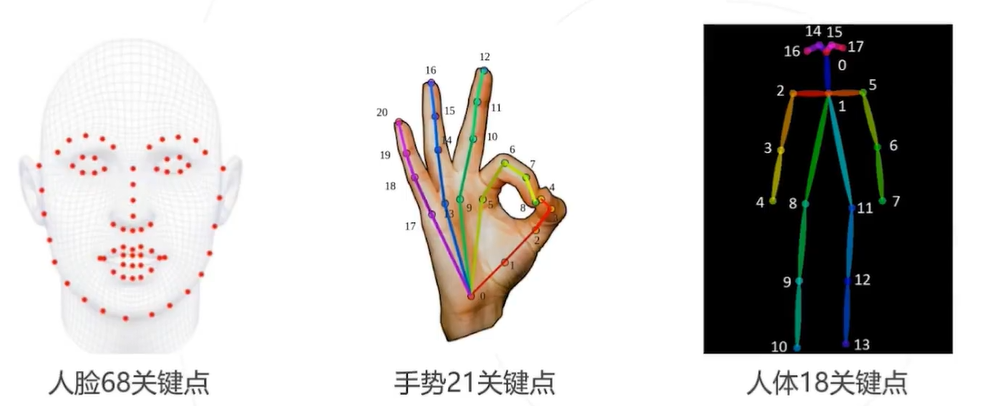
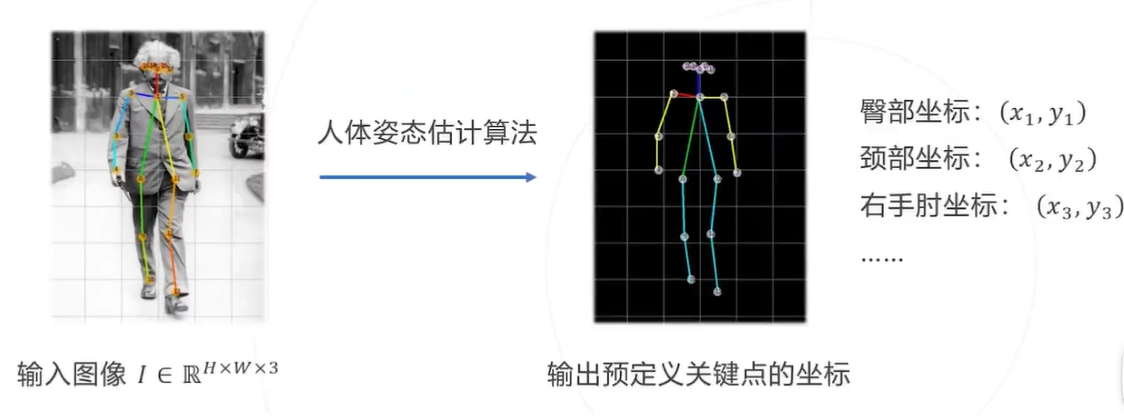
什么是人体姿态估计
从给定的图像中识别人脸、手部、身体等关键点
输入:图像 I
输出: 所有关键点的像素坐标
,这里 J 为关键点的总数,取决于具体的关键点模型.
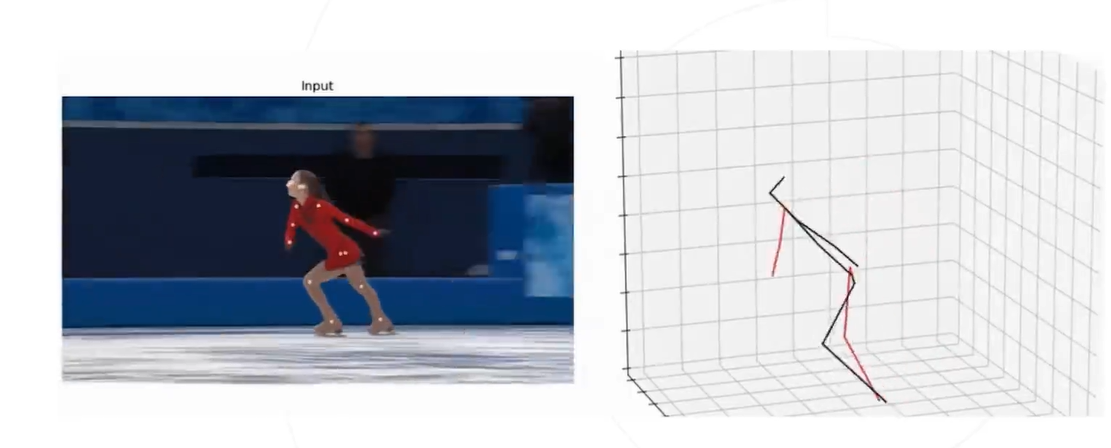
3D 姿态估计
预测人体关键点在三维空间中的坐标,可以在三维空间中还原人体的姿态
人体参数化模型
从图像或者视频中恢复出运动的3D人体模型

下游任务
1、行为识别
PoseC3D:基于人体姿态识别行为动作

2、GC动画

3、人机交互
4、动物行为分析
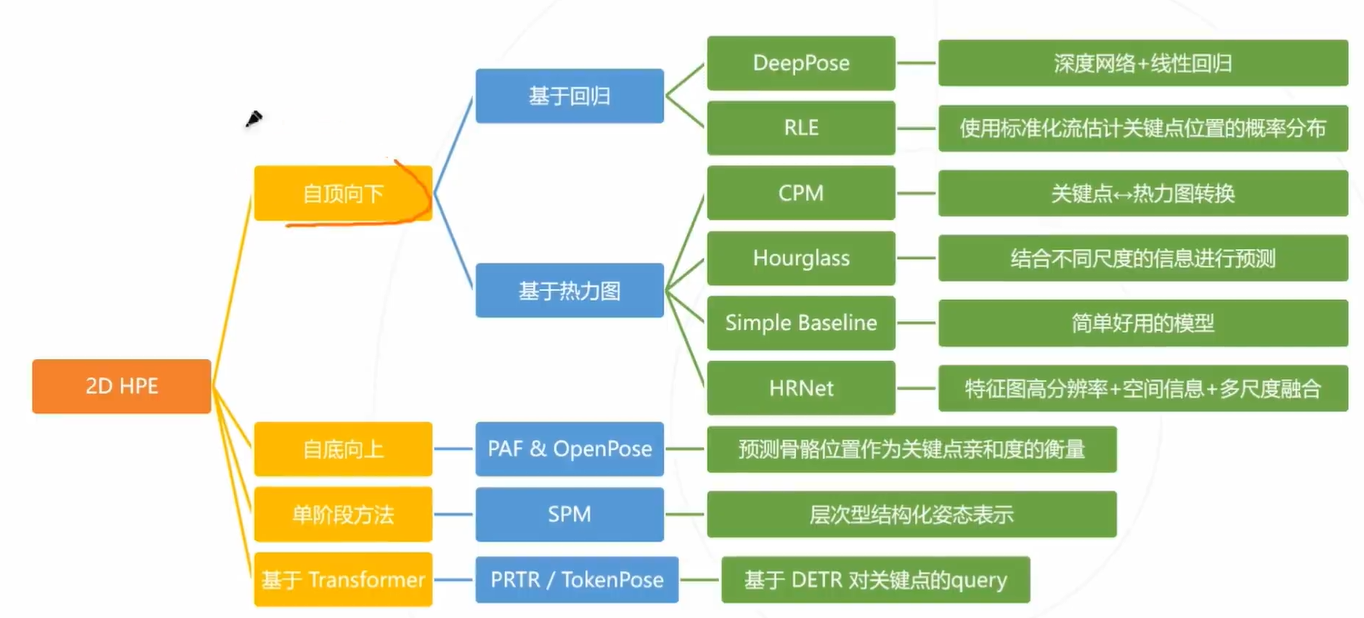
2D姿态估计
2D 人体姿态估计:在图像上定位人体关键点 (通常为人体主要关节) 的坐标
解决思路1:基于回归
将关键点检测问题建模成一个回归问题,让模型直接回归关键点的坐标,即
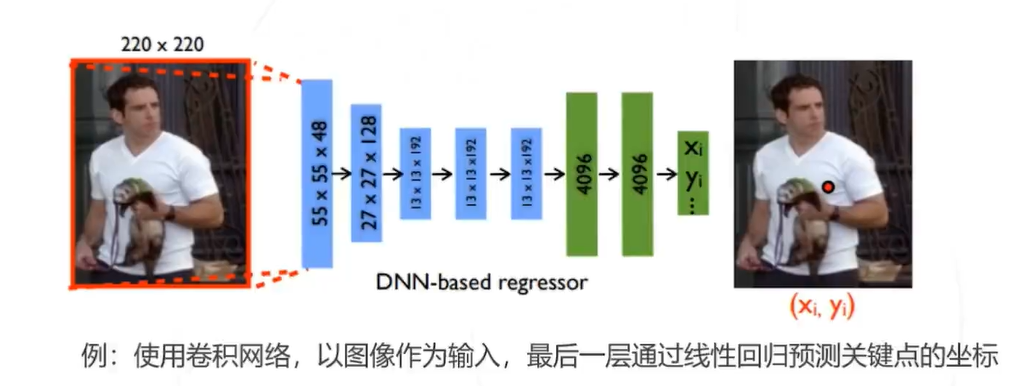
问题: 深度模型直接回归坐标有些困难,精度不是最优
基本思路2:基于热力图
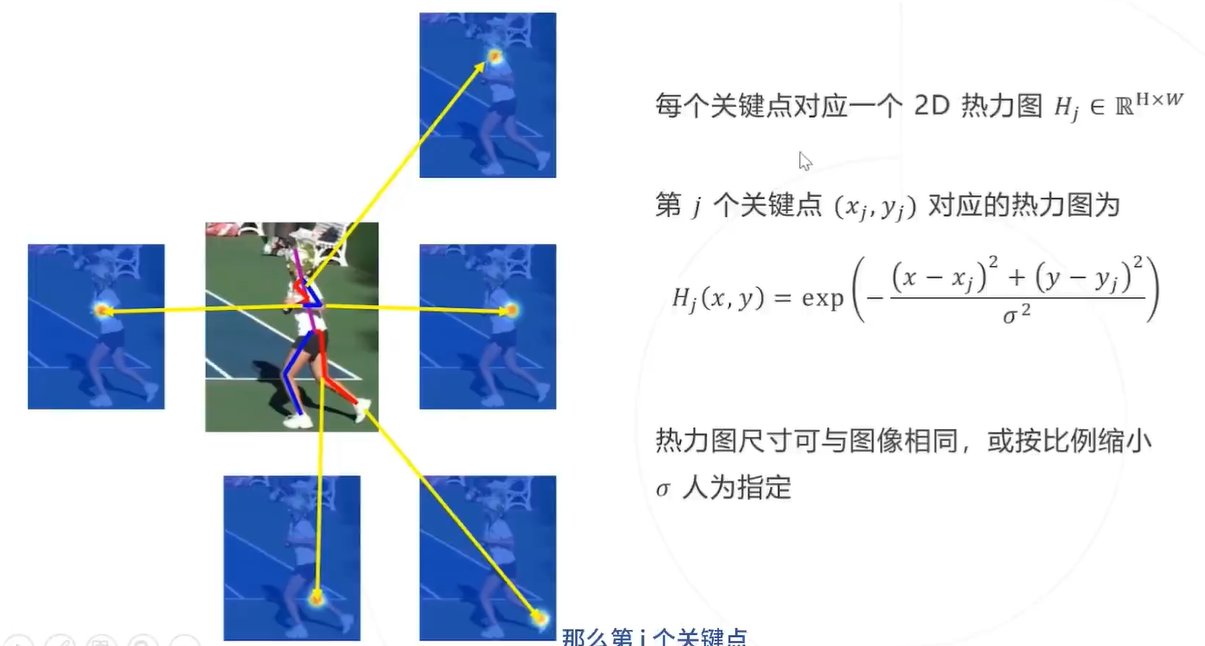
并不直接回归关键点的坐标,而是预测关键点位于每个位置的概率,即
表示关键点 j 位于
的概率为 1 , H 称为热力图,尺寸与原图 I 相同或按比例缩小
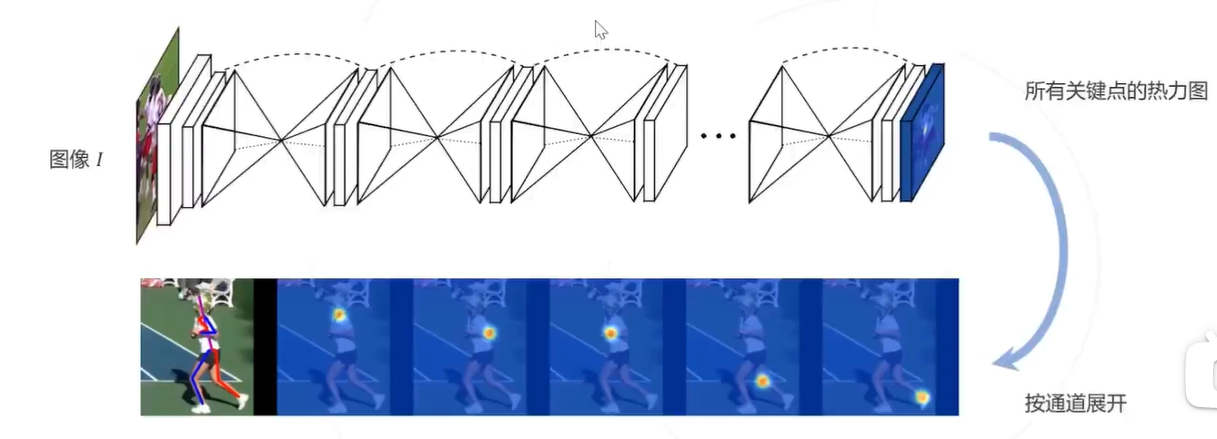
- 热力图可以基于原始关键点坐标生成,作为训练网络的监督信息
- 网络预测的热力图也可以通过求极大值等方法得到关键点的坐标
模型预测热力图比直接回归坐标相对容易,模型精度相对更高,因此主流算法更多基于热力图 但预测热力图的计算消耗大于直接回归.
使用热力图训练模型流程如下:
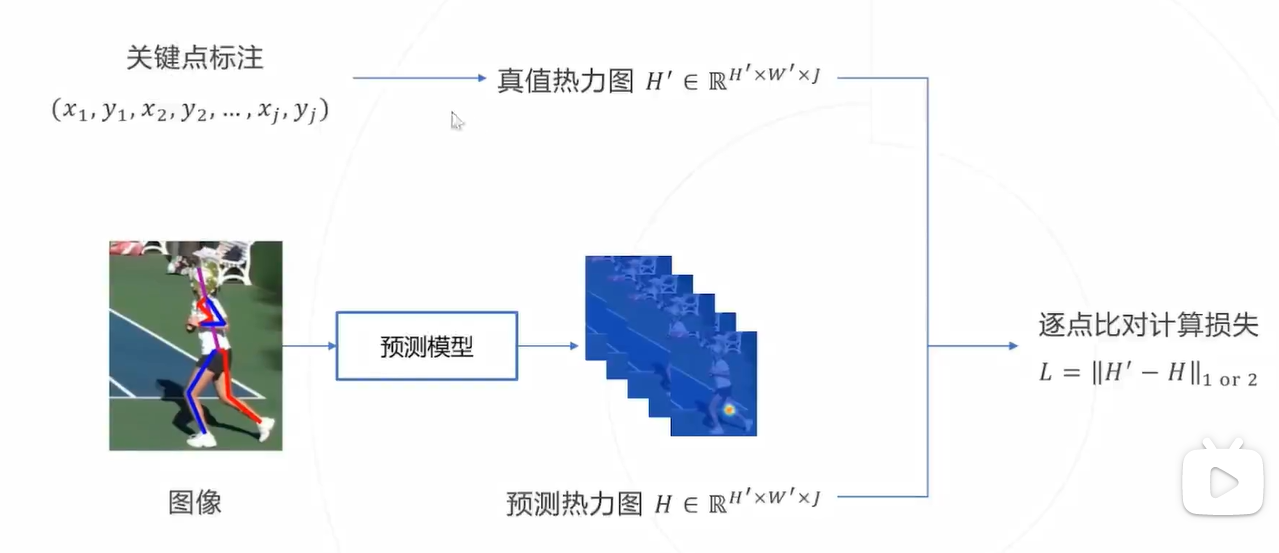
从热力图还原关键点

多人姿态估计:自顶向下方法
Step 1. 使用目标检测 算法检测出每个人体
Step 2. 基于单人图像 估计每个人的姿态

基于回归的自顶向下方法
以分类网络为基础,将最后一层分类改为回归,一次性预测所有 J 个关键点的坐标
通过最小化平方误差训练网络
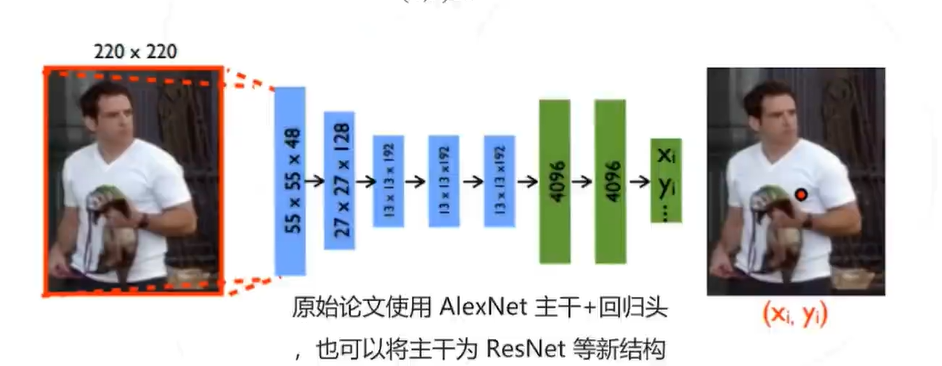
通过多级级联提高精度
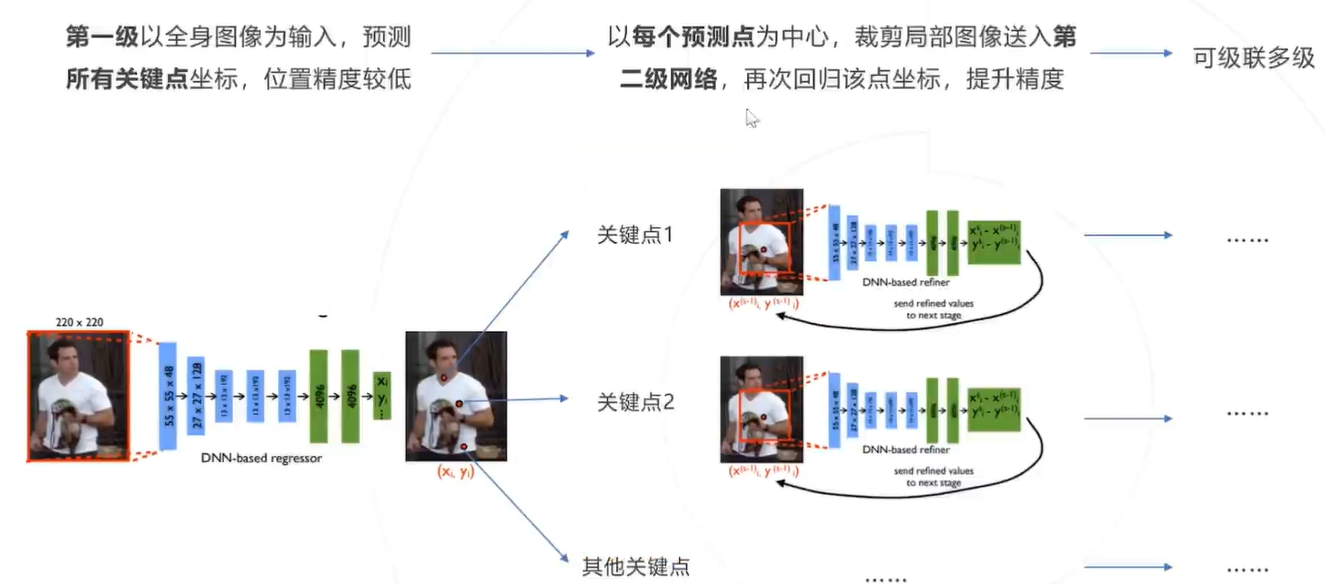
优势:
- 回归模型理论上可以达到㱙限精度,热力图方法的精度受限于特征图的空间分辨率
- 回归模型不需要维持高分辨率特征图,计算层面更高效,相比之下,热力图方法需要计算和存储高分 辨率的热力图和特征图,计算成本更高
劣势: - 图像到关键点坐标的映射高度非线性,导致回归坐标比回归热力图更难,回归方法的精度也弱于热力 图方法,因此 DeepPose 提出之后的很长一段时间内,2D 关键点预测算法主要基于热力图
例子:RLE(2021)

RLE整体设计 :
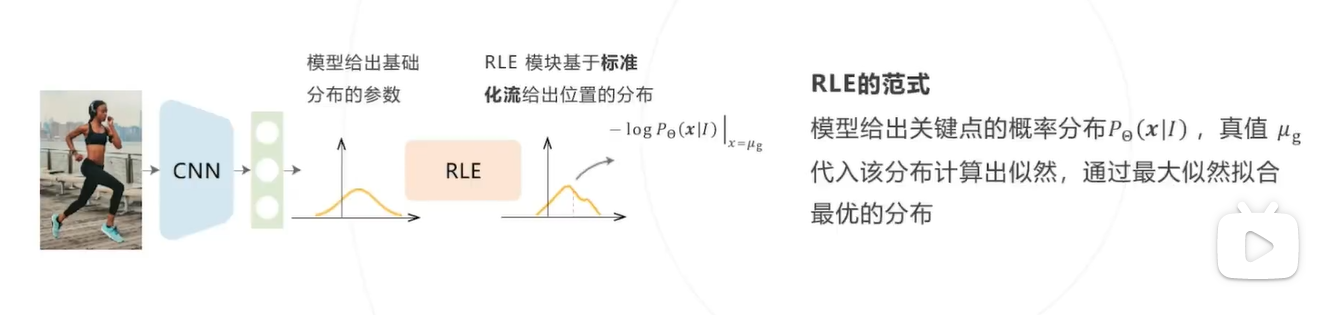
RLE 的目标是建模关键点位置的概率分布,即给定图像 I ,给出每个关键点 x 的位置分布 可以基于标准化流构建该分布,但 RLE 算法还引入了两个技巧以降低模型拟合真实分布的难度:
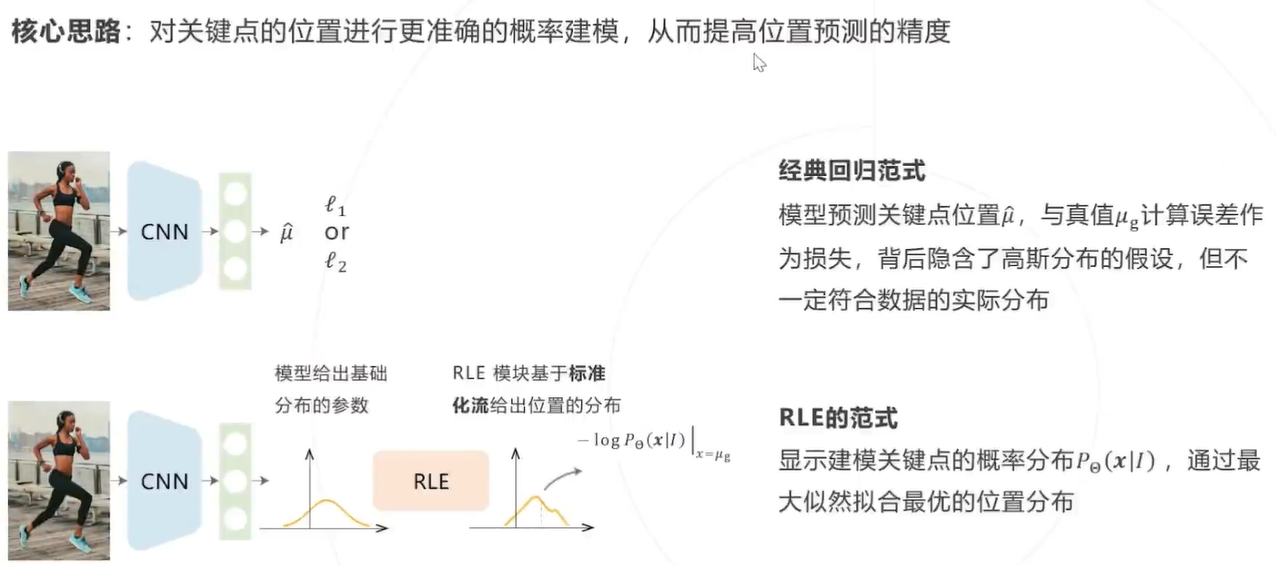
- 重参数化.
- 残差似然函数
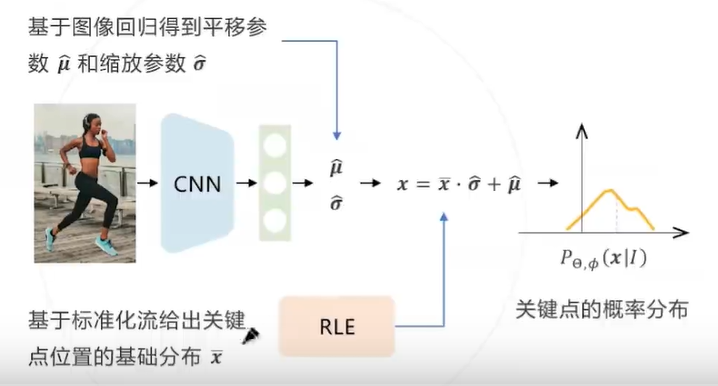
重参数化:为降低建模分布的难度,假设所有关键点的分布属于同一个位置尺度族,即所有分布由某个零均值的 基础分布通过平移缩放得来。基于这个假设,让标准化流拟合该基础分布 ,卷积网络预测平移缩放参 和
推理阶段,将卷积网络预测的平移参数 作为 关键点的预测结果,不需要推理标准化流, 保证计算高效性
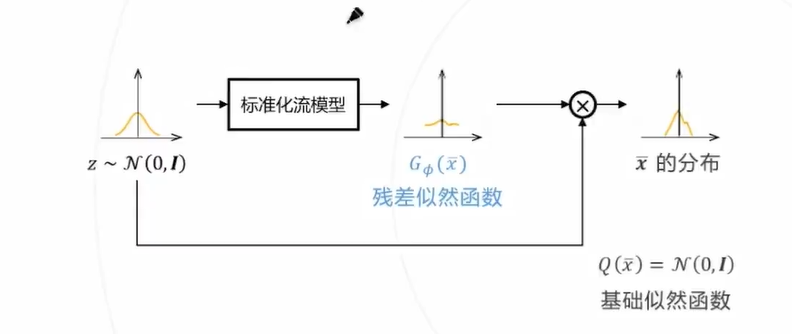
残差似然函数:
借鉴残差网络的思路,进一步假设 的概率密度为标准高斯分布 与一个变形分布 之积(或对数概率密度之和),如果 已经可以很好拟合数据,变形分布的对数退化为 0
让标准化流拟合该变形分布可以进一步降低模型训练的难度
基于热力图的自顶向下方法
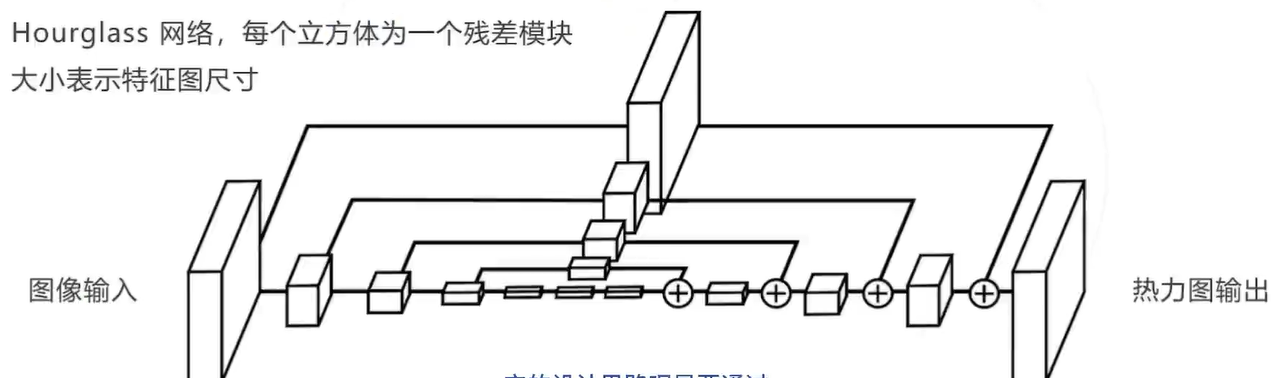
Hourglass(2016)姿态估计领域标志性工作,设计思路:准确的姿态估计需要结合不同尺度的信息:
- 局部信息 检测不同身体组件
- 全局信息 建模组件之间的关系,在大尺度变形、遮挡时也可以准确推断出姿态
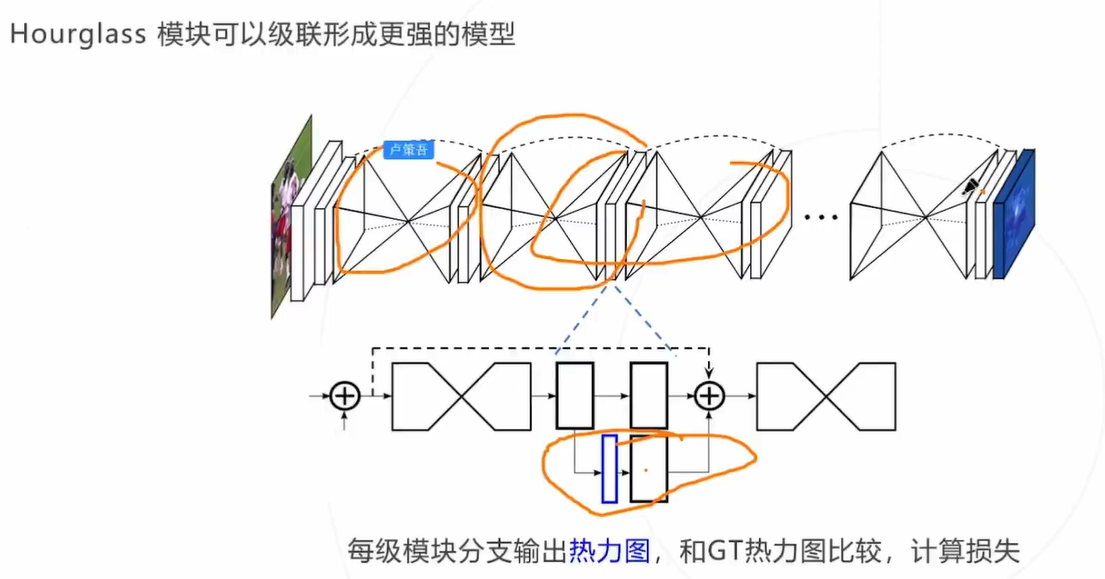
- Hourglass可以级联,形成更强大的模型
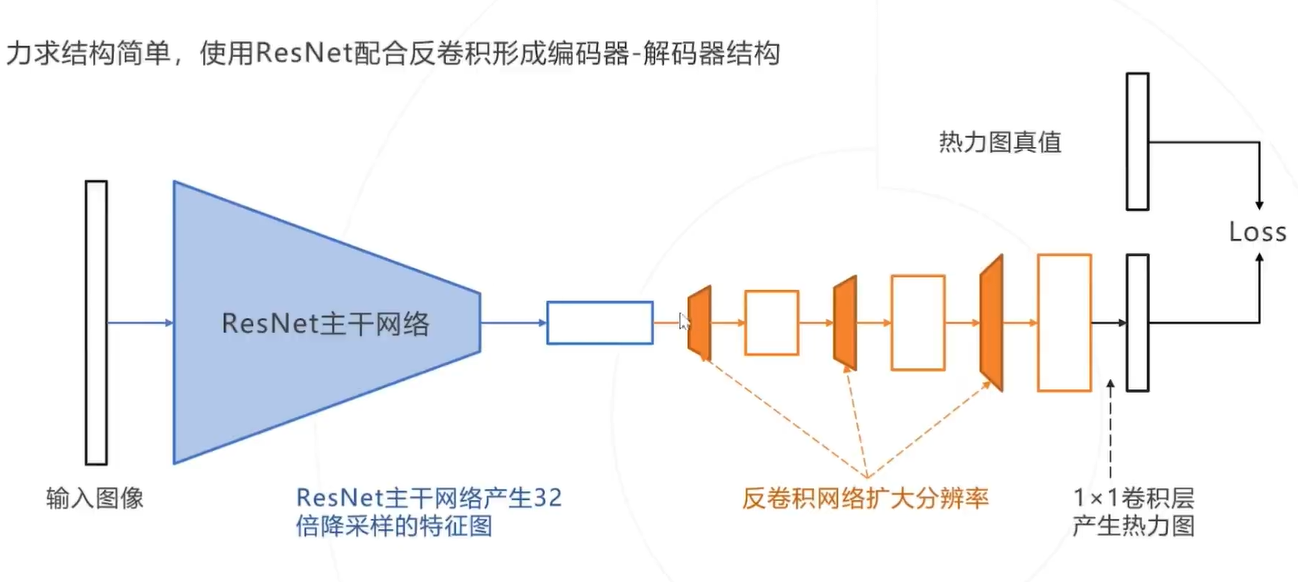
Simple Baseline:力求结构简单,使用ResNet配合反卷积形成编码器-解码器结构
HRNet核心思路:在下采样时通过保留原分辨率分支来保持网络全过程特征图的高分辨率与空间位置信息, 并设计了独特的网络结构实现不同分辨率的多尺度特征融合。
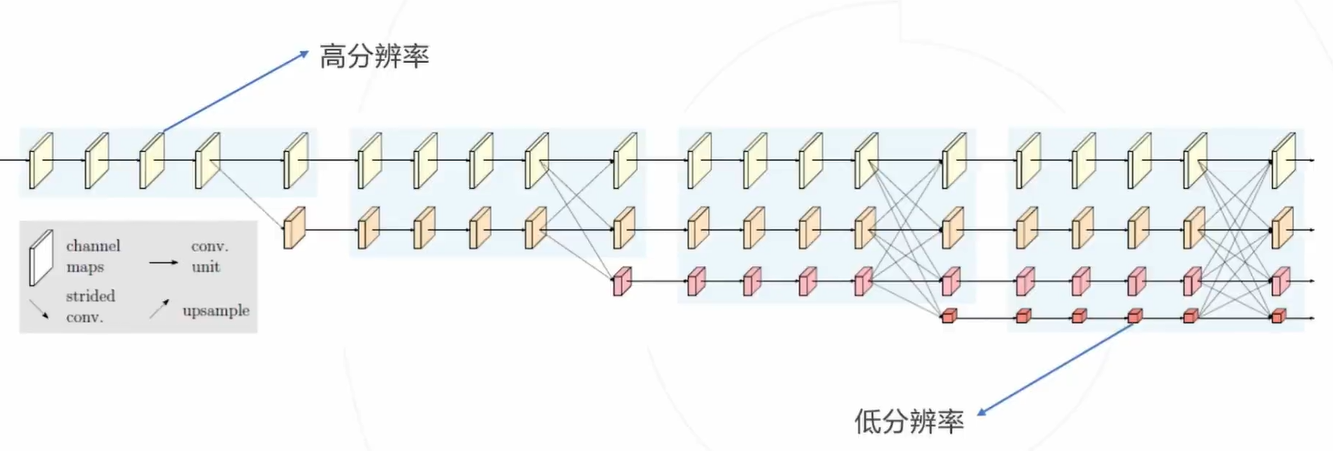
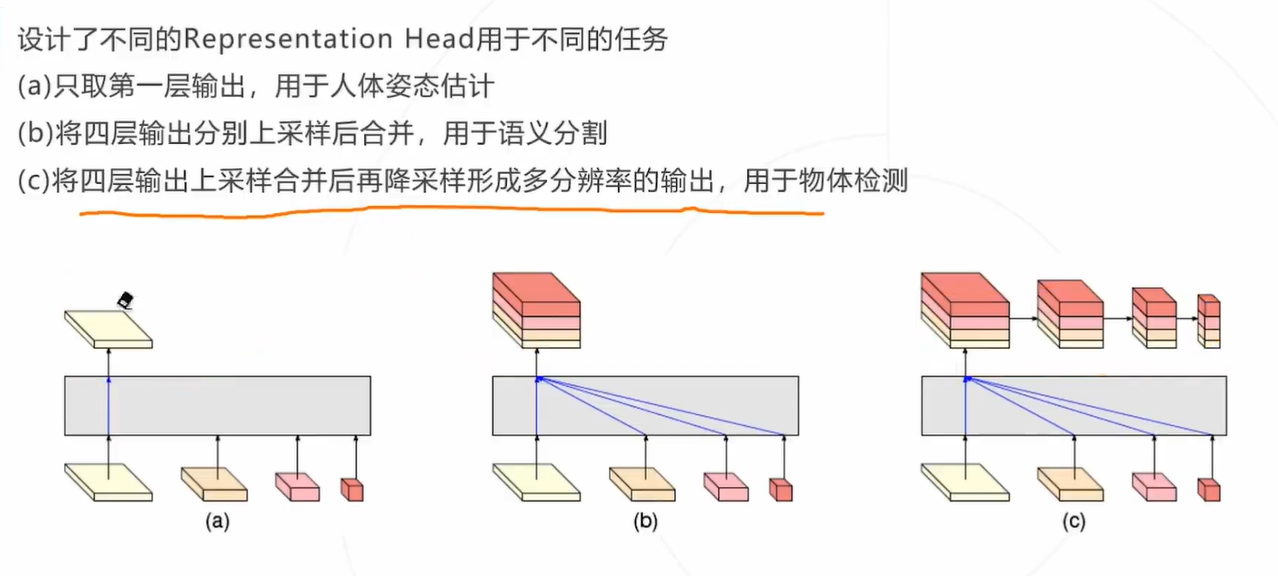
多人姿态估计:自底向上方法
Step 1. 使用关键点模型 检测出所有人体关键点
Step 2. 基于位置关系或其他辅助 信息将关键点组合成不同的人

单阶段方法
SPM:SPM首次提出了人体姿态估计的单阶段解决方案,在取得速度优势的同时,也取得了不逊色于二阶段方 法的检测率。并且该方法可以直接从2D图像扩展到3D图像的人体姿态估计。
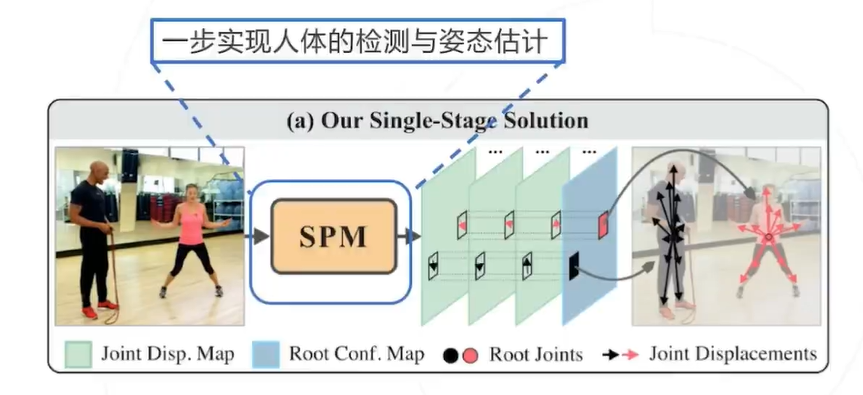
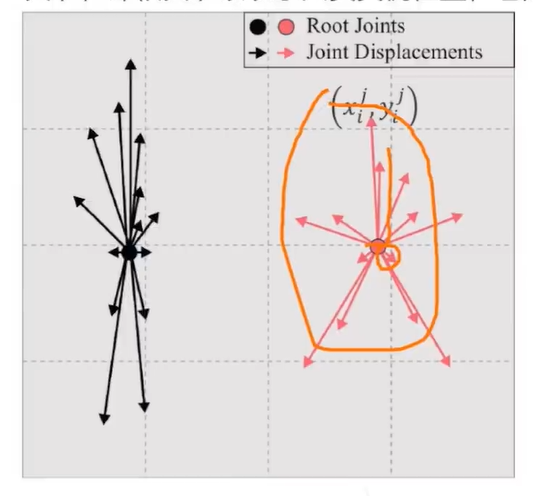
SPR:为了统一人体实例和身体关节的位置信息,为多人姿势估计提供单阶段解决方案,SPR引入了一个辅助 关节,即根关节以表示人员实例位置,它是唯一标识关节。
基于Transformer的方法
PRTP:人体姿态估计和物体检测有一定相似性,都涉及对图像内容的定位 在 DETR 中 query 通过注意力机制逐渐聚焦到特定物体上 姿态估计可模仿 DETR:让 query 逐渐聚焦到特定人体关键点上.
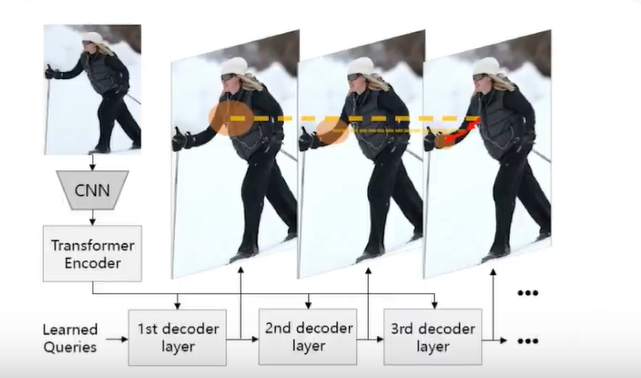
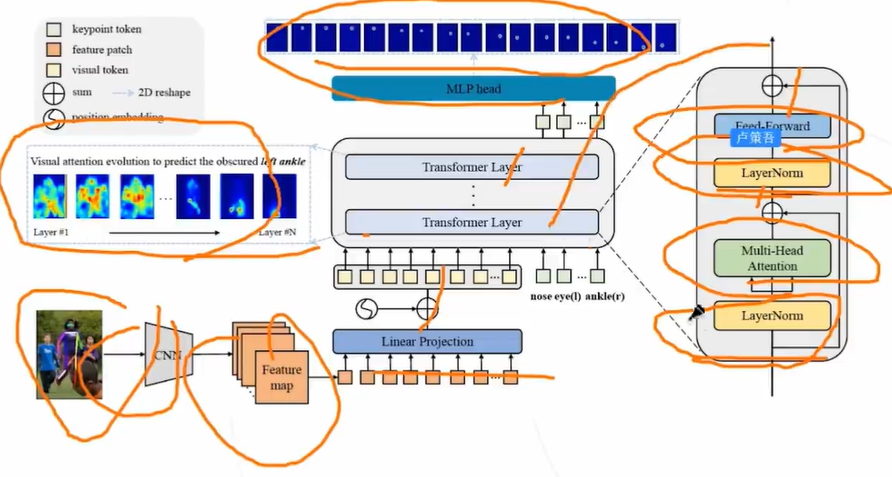
TokenPose:将视觉 token 和 关键点 token 一起送入 encoder 可以同时从图像中学习外观视觉表现和关键点间的 约束关系
分类模型 ViT 也使用类似方法,将一个分类 token 和visual token 一起做自注意力
小结
3D姿态估计
通过给定的图像预测人体关键点在三维空间中的坐标,可以在三维空间中还原人体的姿态
输入: 图像
输出: 所有人的所有关键点的空间坐标
,这里 N 为图中总人数, J 为关键点总数

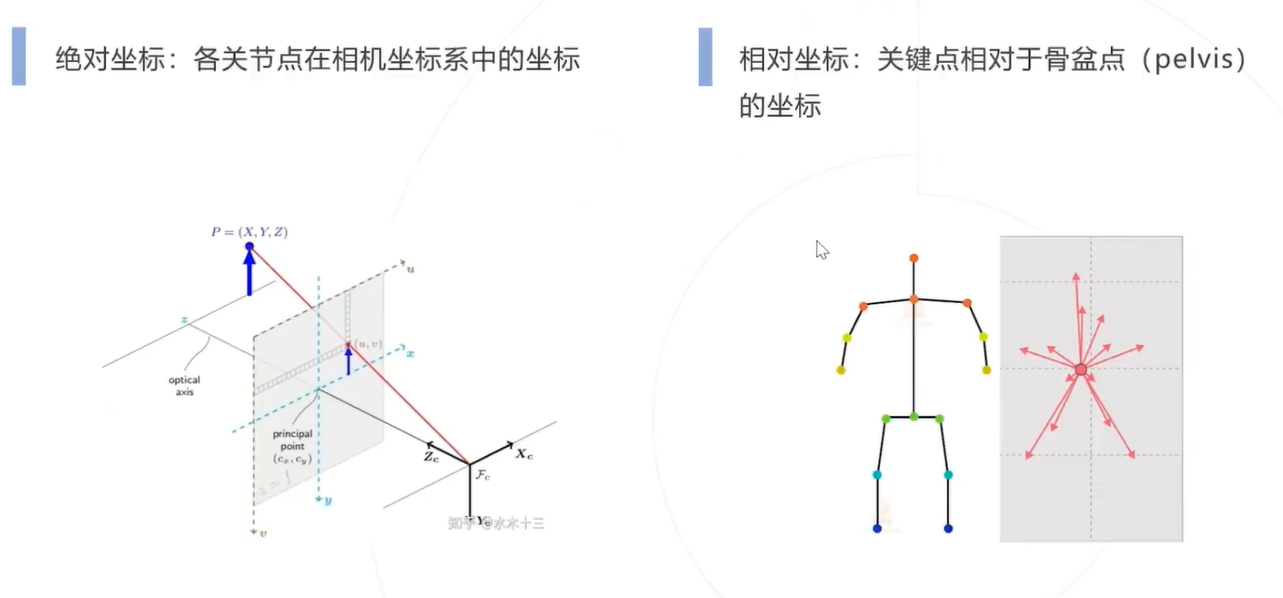
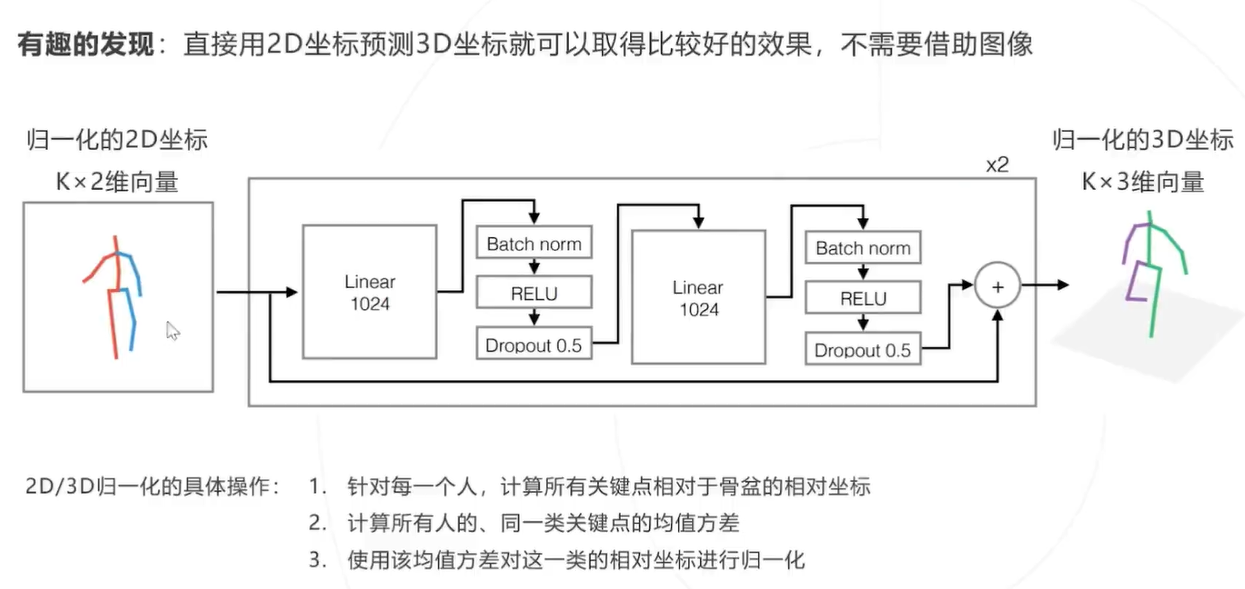
绝对坐标和相对坐标
思路1:直接预测
直接基于从 2D 图像回归 3D 坐标,但 2D 图像不包含深度,这是一个病态问题 实际上隐式借助了语义特征或人体的刚性实现了 3D 姿态的推理。
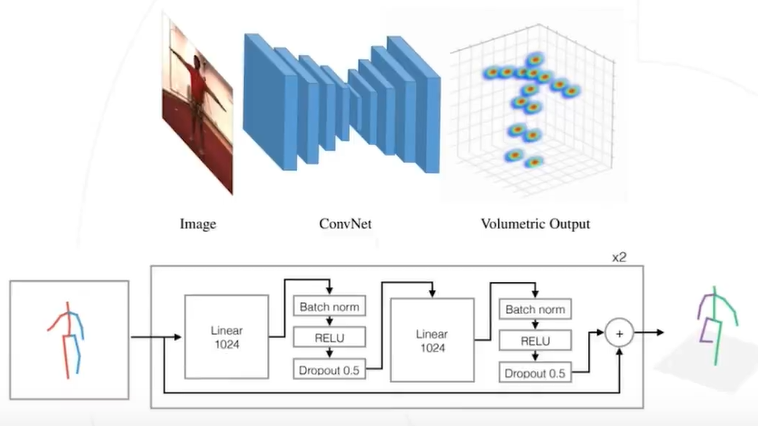
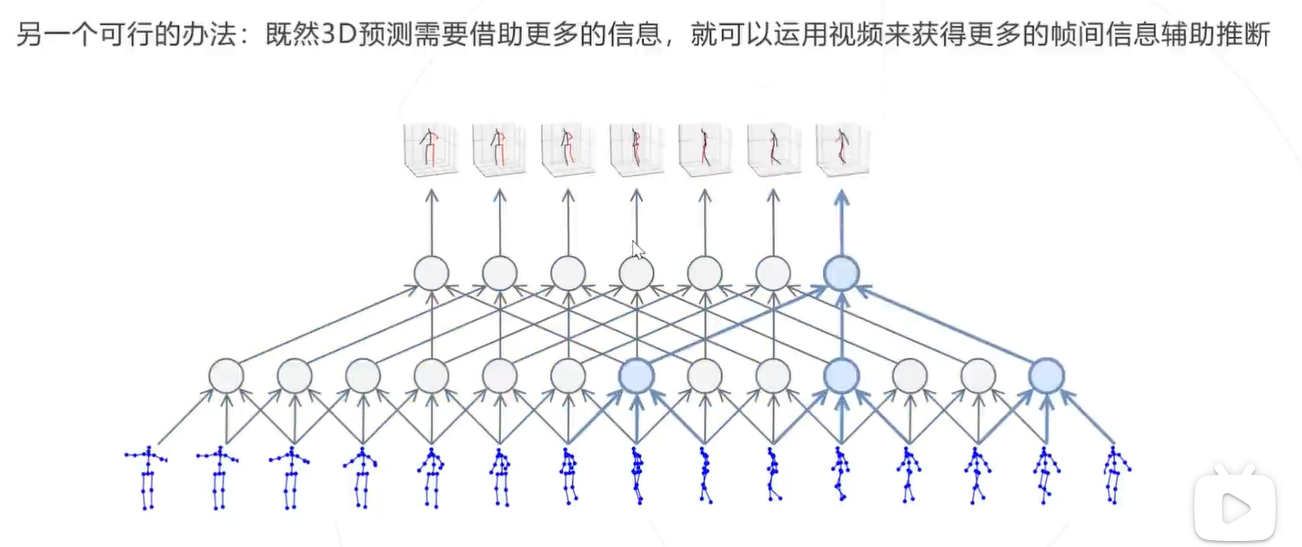
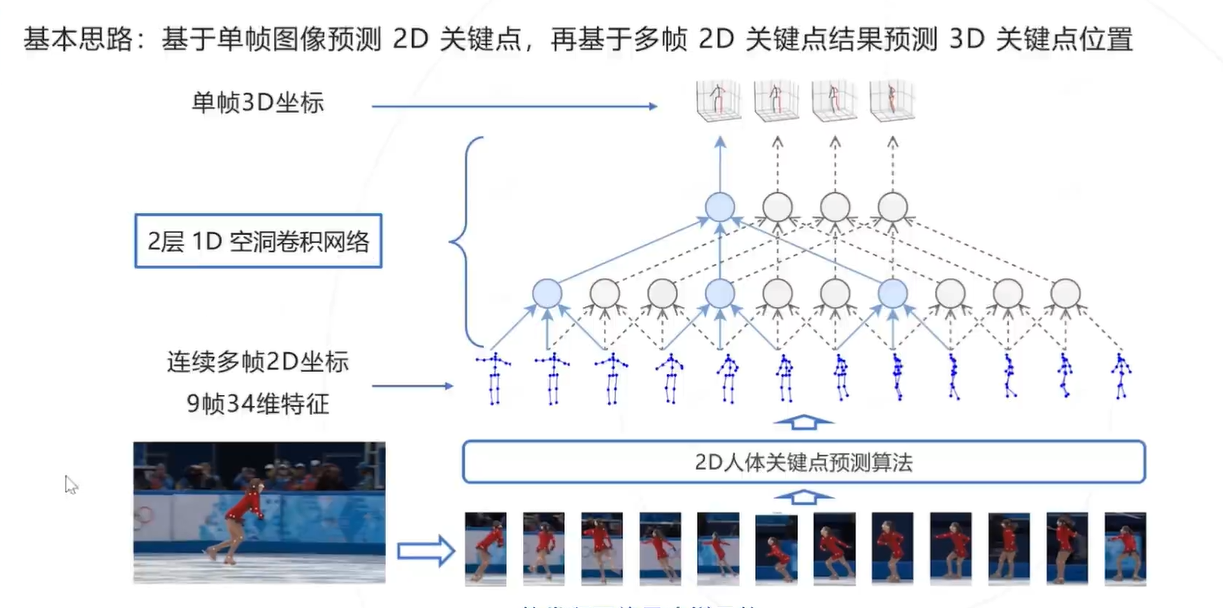
思路2:利用视频信息
Simple Baseline 3D
Video Pose3D
评估指标
PCP: P C P 以肢体的检出率作为评价指标
考虑每个人的左右大臂、小臂、大腿、小腿共计
个肢体
如果两个预测关节位置和真实肢体关节位置之间的距离小于等于肢体长度的一半,则认为肢体已检测到 且是正确的部分。
PDJ 以关节点的位置精度作为评价指标
通常考虑头、肩、时、腕、臀、膝、踝几个关键点,如果预测关节和真实关节之间的距离在躯干直径的 某个比例范围内,则认为检测到检测到了关节。并且可以通过改变该比例,可以获得不同程度的定位精 度的检测率。
PCK以关键点的检测精度作为评价指标
如果预测关节和真实关节之间的距离在某个阈值(可变)内,则认为检测到的关键点是正确的。在2D 与3D (PCK3D) 任务中均可使用。
PCK阈值通常是根据对象的比例设置的,对象的比例封闭在边界框内。例如,阈值可以是: PCKh@0.5 阈值=头部骨骼链接的 阈值=0.2*躯干直径;有时也以 作为阈值
OKS based mAP以关键点相似度 (OKS) 作为评价指标计算mAP,OKS是MS COCO竞赛指定的关键点 评价指标,其定义为
其中:
- 是 和预测关键点之间的欧氏距离
- s 是对象分割区域面积的平方根
- k 是控制衰减的关键点常量
- 是一个可见性标志,可以是0、1或2,分别表示末标记、标记但不可见、可见并标记
- 由于OKS可以用于计算距离 ( 0-1 之间),所以它可以显示预测关键点与真实关键点之间的距离。
Dense Pose 人体表面参数化

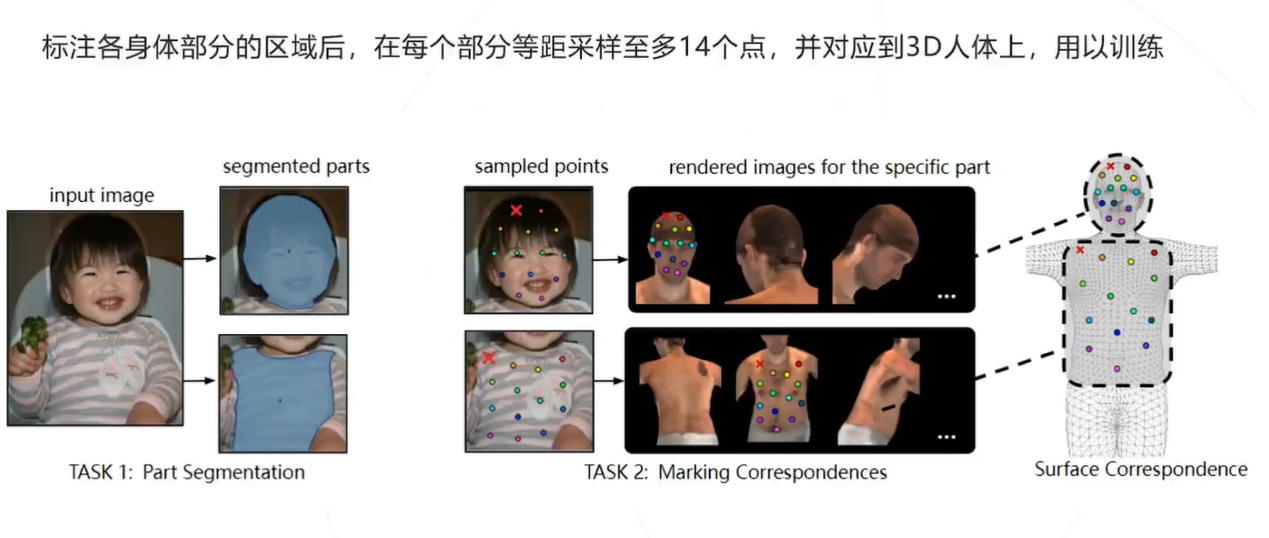
标注方法
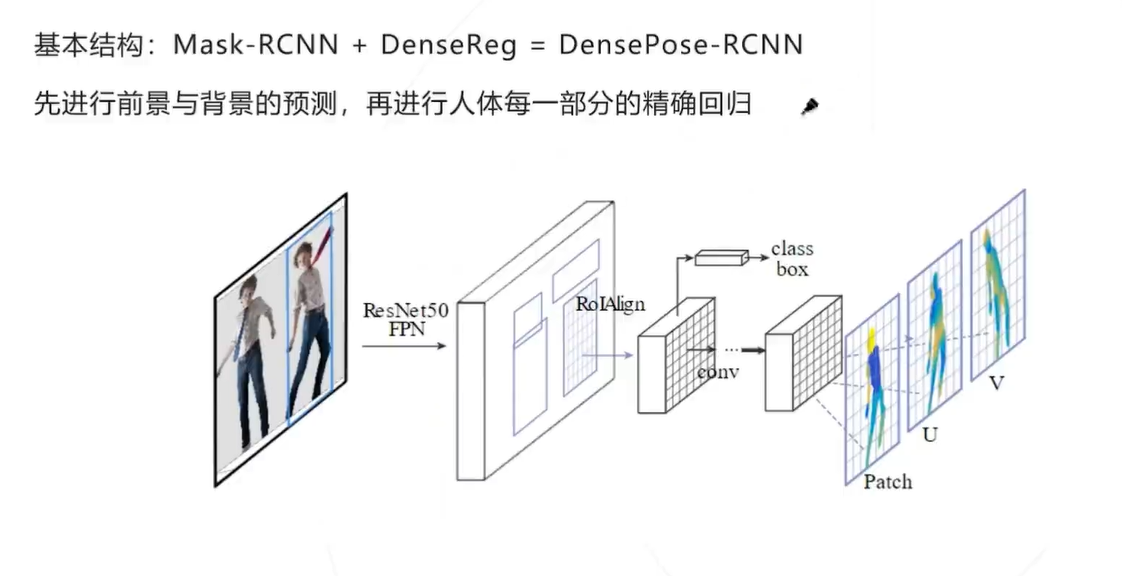
网络结构
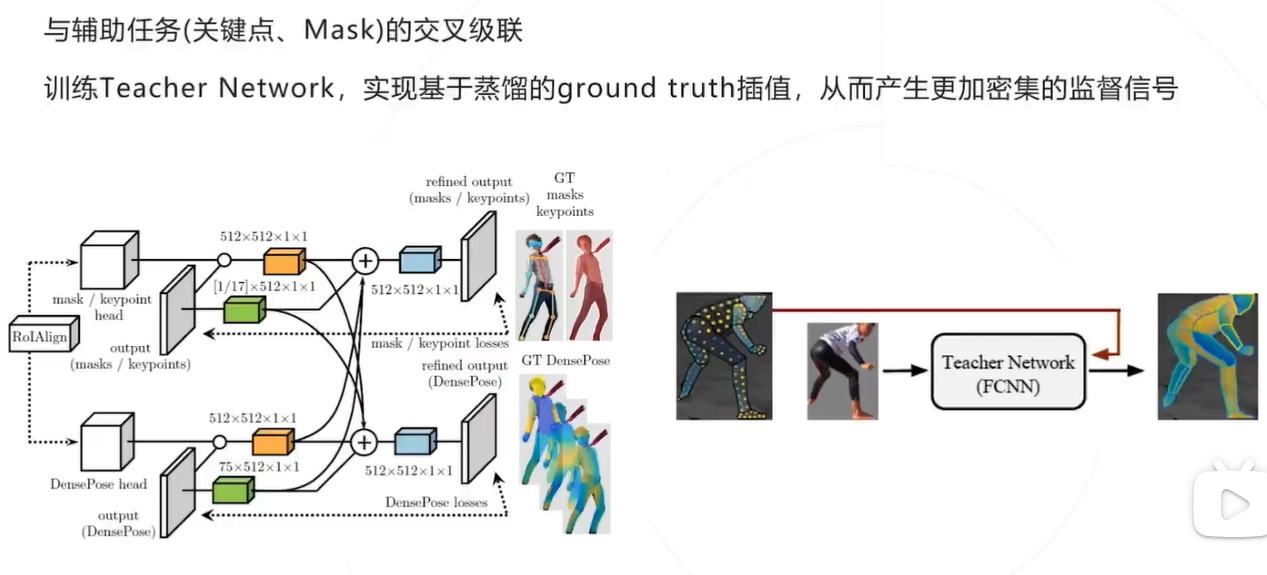
改进设计
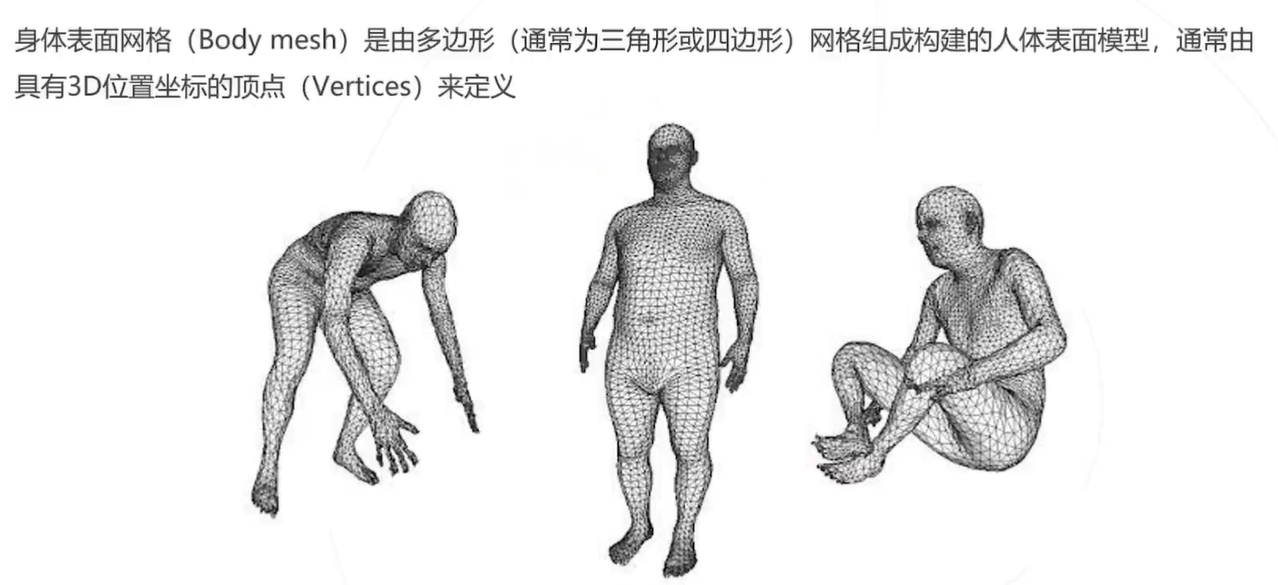
身体表面网络
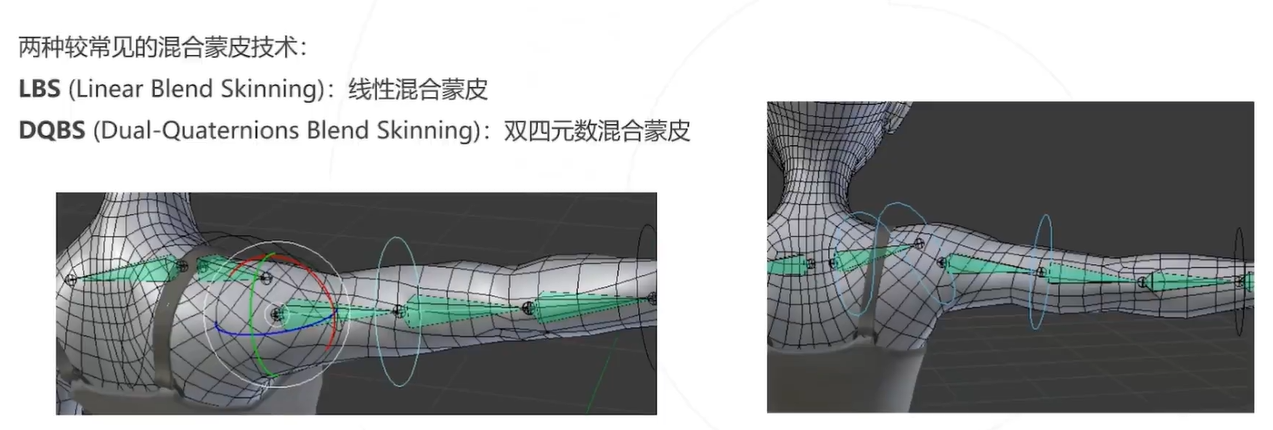
混合蒙皮技术是一种使身体表面网格 (Body mesh) 随内在的骨骼结构形变的方法。当骨骼结构发生变化时, 特定关节点 (Joint) 的位置变化对人体表面不同顶点 (Vertex) 的位置变化有不同影响,在混合蒙皮技术里,这 种影响是由不同的权重实现的
SMPLify算法流程
将Mesh的估计问题转化为一个优化问题,包含如下两个优化目标:
- SMPL模型投影回图像应符合2D关键点的位置
- SMPL模型满足一定的人体姿态和形态上的约束
将两个要求合并为一个优化目标,即可求解出给定图像所对应的SMPL模型
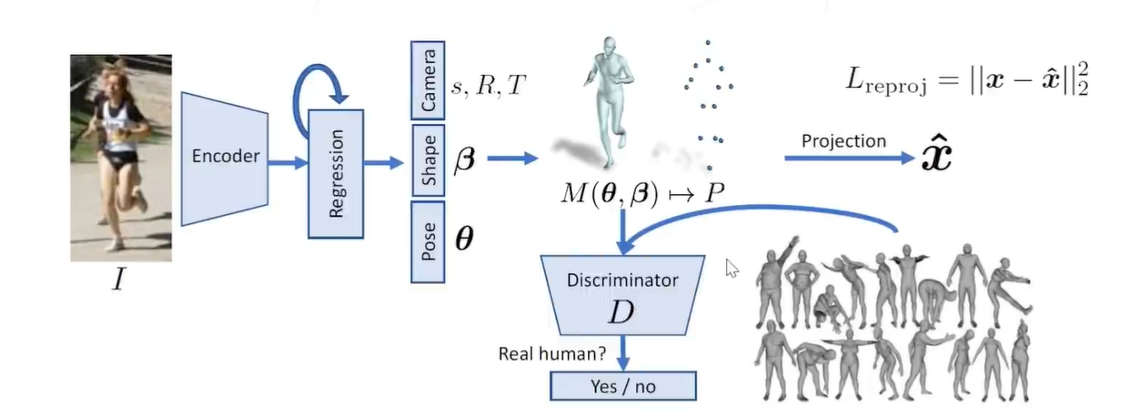
HMR:基于深度学习模型,从图像直接估计 SMPL 模型参数,从而重建人体表面网格 该模型可在只有2D标注的情况下进行训练。


算法设计:
3. 使用卷积网络提取图像特征,再回归得到 SMPL 模型参数
、以及缩放、旋转、平移参数 s, R, T
4. 将 SMPL 模型投影回图像,计算 2D 关键点位置的回归损失
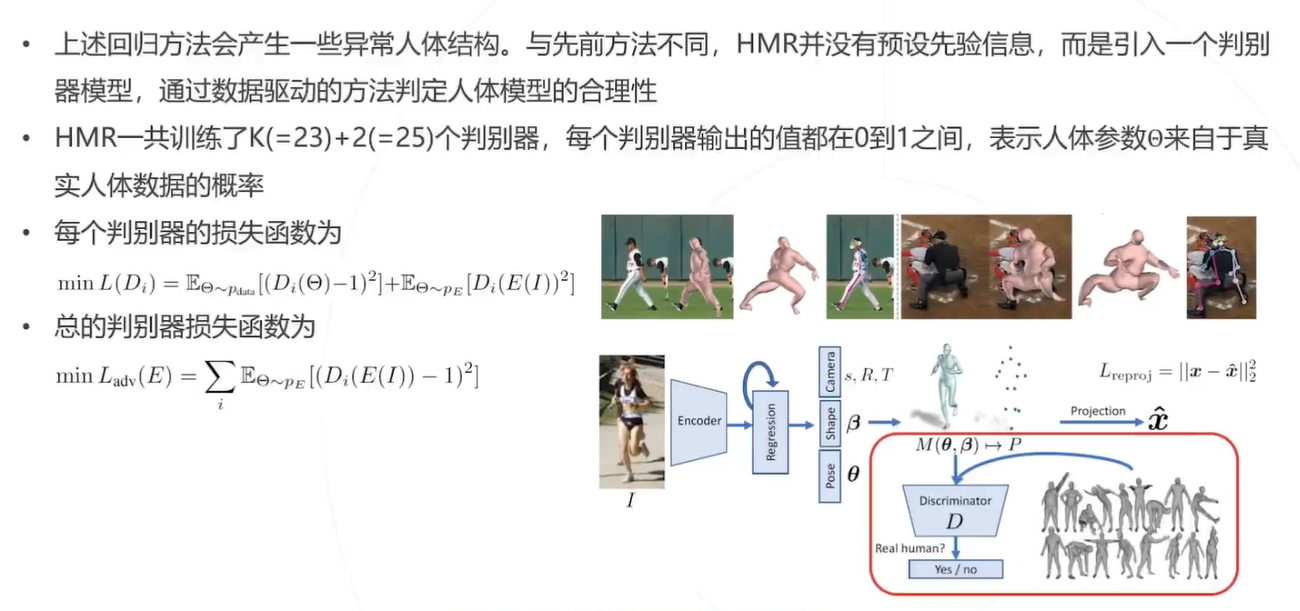
5. 仿照 GAN,引入一个判别器模型,判断估计出的人体模型是否真实
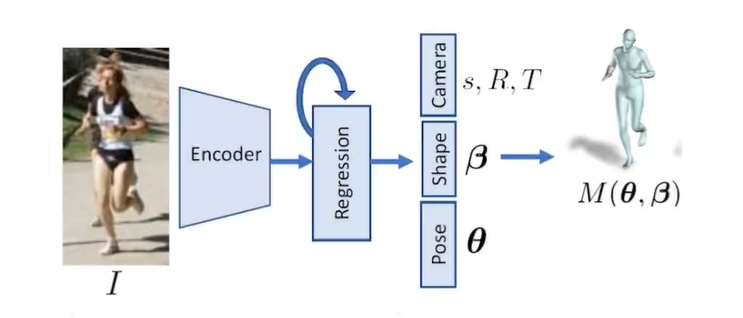
回归模型设计
编码器使用 ResNet-50 模型,采用迭代回归方式,预测:
6. SMPL 模型的姿态参数
和形态参数
7. 弱透视相机模型的,缩放参数
、平移参数
完整参数集合
引入判别
总结


- 点赞
- 收藏
- 关注作者
评论(0)