java 正则表达式总结

目录
一、简介
正则表达式,全称Regular Expression,有时简写为regexp,RegExp或RE。正则表达式是java提供的一种用于处理文本相关问题的技术(目前很多编程语言都支持正则表达式,且语法规则类似),它通过简单字符串对“指定格式”的描述,来匹配全文中满足该格式的字符串。简单来说,正则表达式就是对字符串执行模式匹配的技术,一个正则表达式就是用某种模式去匹配字符串的一个公式。
二、源码分析
1.简单实例 :
现有一段文字如下:
DBUtils中常用的类和接口如下——
1111.QueryRunner类 : 该类封装了SQL的执行,并且是线程安全的;可以实现增删查改,并且支持批处理。
2222.ResultSetHandler接口 : 该接口用于处理java.sql.ResultSet,将数据按照要求转换为另一种格式。常见实现类如下 :
3333.ArrayHandler : 将结果集中的第一行数据转换成对象数组。
4444.ArrayListHandler : 将结果集中的每一行数据转换成对象数组,再存入List中。
5555.BeanHandler : 将结果集中的第一行数据封装到一个对应的JavaBean实例中(适用于返回单条记录的情况)。
6666.BeanListHandler : 将结果集中的每一行数据都封装到对应的JavaBean实例中,再存放到List集合中。
7777.ColumnListHandler : 将结果集中某一列的数据存放到List中。
8888.KeyedHandler(name) : 将结果集中的每行数据都封装到Map里,然后将所有的map再单独存放到一个map中,其key为指定的key。
9999.MapHandler : 将结果集中的第一行数据封装到一个Map里,key是列名,value就是对应的值。
1010.1010.MapListHandler : 将结果集中的每一行数据都封装到Map里,再存入List。
1111.1111.ScalarHandler : 将结果集中的一列映射为一个Object对象,适用于返回单行单列的情况。
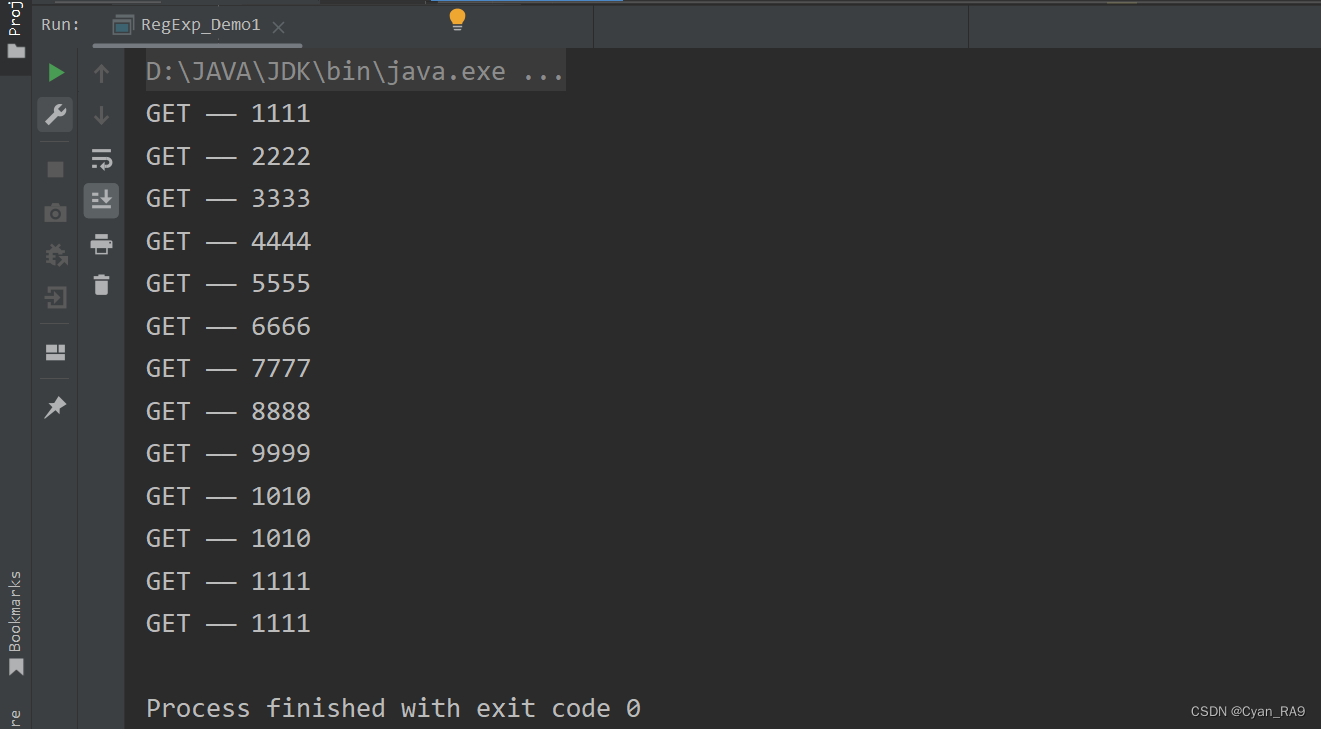
现要求用Java程序,找出这段文字中的四位数字。
使用正则表达式实现,以RegExp_Demo1类为演示类,代码如下 :
package csdn.advanced.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class RegExp_Demo1 {
public static void main(String[] args) {
//需要操作的内容如下 :
String text =
"DBUtils中常用的类和接口如下——\n" +
"1111.QueryRunner类 : 该类封装了SQL的执行,并且是线程安全的;可以实现增删查改,并且支持批处理。\n" +
"\n" +
"2222.ResultSetHandler接口 : 该接口用于处理java.sql.ResultSet,将数据按照要求转换为另一种格式。常见实现类如下 : \n" +
"\n" +
"3333.ArrayHandler : 将结果集中的第一行数据转换成对象数组。\n" +
"\n" +
"4444.ArrayListHandler : 将结果集中的每一行数据转换成对象数组,再存入List中。\n" +
"\n" +
"5555.BeanHandler : 将结果集中的第一行数据封装到一个对应的JavaBean实例中(适用于返回单条记录的情况)。\n" +
"\n" +
"6666.BeanListHandler : 将结果集中的每一行数据都封装到对应的JavaBean实例中,再存放到List集合中。\n" +
"\n" +
"7777.ColumnListHandler : 将结果集中某一列的数据存放到List中。\n" +
"\n" +
"8888.KeyedHandler(name) : 将结果集中的每行数据都封装到Map里,然后将所有的map再单独存放到一个map中,其key为指定的key。\n" +
"\n" +
"9999.MapHandler : 将结果集中的第一行数据封装到一个Map里,key是列名,value就是对应的值。\n" +
"\n" +
"1010.1010.MapListHandler : 将结果集中的每一行数据都封装到Map里,再存入List。\n" +
"\n" +
"1111.1111.ScalarHandler : 将结果集中的一列映射为一个Object对象,适用于返回单行单列的情况。";
//1.指定匹配格式 (PS : \\d表示0~9的一个任意数字)
String regStr = "\\d\\d\\d\\d";
//2.创建一个模式对象 (一个正则表达式对象)
Pattern pattern = Pattern.compile(regStr);
//3.获取对应的匹配器
Matcher matcher = pattern.matcher(text);
//4.进行匹配
//find方法返回boolean类型; group方法获取字符串
while (matcher.find()) {
System.out.println("GET —— " + matcher.group(0));
}
}
}
运行结果 :
2.底层实现 :
1° fund()方法
1>根据指定的规则,定位满足规则的子字符串;
2>找到后,将子字符串的开始索引记录到matcher对象的int[] groups属性中,即groups[0],如下图所示 :

以文本中第一个四位数1111为例,即groups[0] = 20; 接着,将子字符串结束的(索引值 + 1)记录到groups[1]中。如下图所示 :

同时,还会将该子字符串结束的(索引值 + 1)用oldLast变量来保存,如下图所示 :
![]()
oldLast默认值为1.

当下次执行find方法时,就会从oldLast变量保存的索引值( = 上一次匹配结果的末尾索引值 + 1)开始匹配。
2° group(0/1)方法
(1)group(0):
group方法源码如下 :

first和last分别表示上一次匹配到的子字符串的(首索引)和(尾索引 + 1) 。

若传入的group = 0,则groups[0 * 2]~groups[0*2 + 1] = groups[0]~groups[1]。
Δ最终返回的就是find方法捕获到的子字符串, getSubSequence方法底层调用了subString方法(前闭后开)。
当下一次执行find方法后,就会用匹配到的新值覆盖groups[0]和groups[1],如下图所示:

(2)group(1):
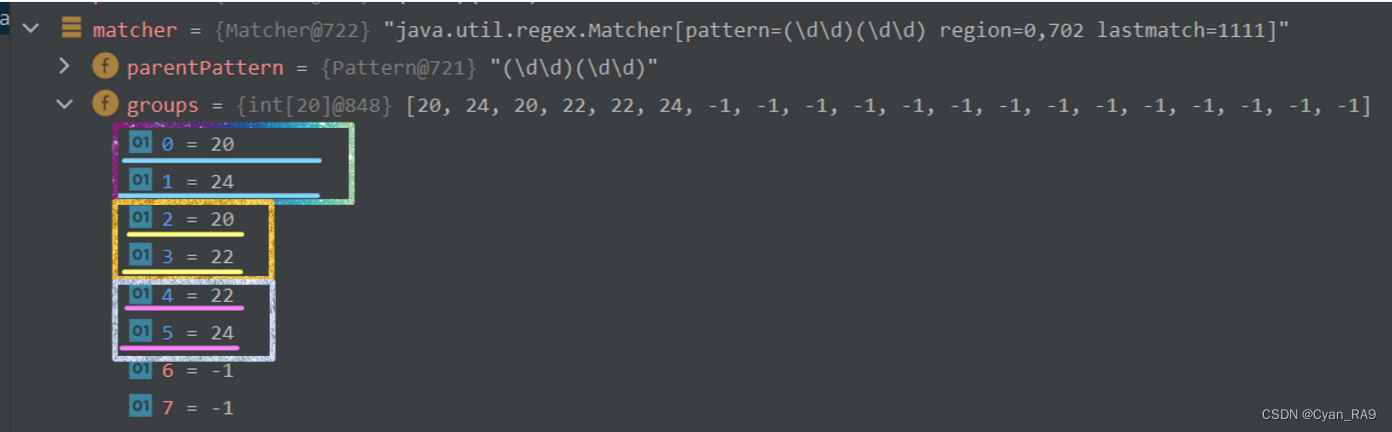
PS : 若将匹配格式由"\\d\\d\\d\\d"改为"(\\d\\d)(\\d\\d)",则表示分组;第一个()表示第一组,第二个()表示第二组,以此类推。
以"(\\d\\d)(\\d\\d)"分组为例,find方法在找到匹配的子字符串后,仍然会将该子字符串的(首索引值)和(尾索引值 + 1)分别保存在groups数组的group[0]和group[1]中。
但是,由于进行了分组,会继续在groups数组中保存分组的信息,groups[2]和groups[3]保存第一组的信息(与groups[0],groups[1]同理);groups[4]和groups[5]保存第二组的信息,以此类推。
因此,当传入1时,group(1)就表示获取第一组的内容;当传入2时,group(2)就表示获取第二组的内容,以此类推。注意 : 传入的group实参不能越界。
如下图所示 :
尝试输入子字符串的不同分组 :
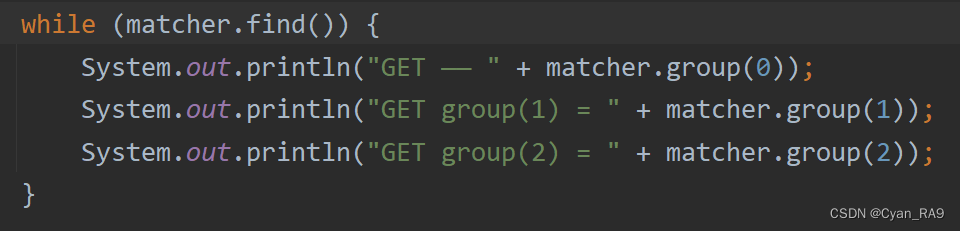
运行结果 :

三、 基本语法
1.元字符介绍 :
元字符指正则表达式中具有特殊意义的字符。元字符从功能上大致分为六类,分别是限定符;选择匹配符;分组组合和反向引用符;特殊字符;字符匹配符;定位符。
PS : 使用正则表达式去检索某些特殊字符时,需要用到转义符号,否则检索不到结果,甚至报错。在Java的RegExp中,\\代表其他语言的一个\,表示转义符号。常见的需要用到转义符号的元字符有:.,*,+,(,),$,/,\,?,[,],^,{,}。
2.元字符—字符匹配符 :
| 符号 | 含义 | 实例 | 解释 |
|---|---|---|---|
| [] | 可接收的字符列表 | [yurisa] | y,u,r,i,s,a中任意一个字符都可以 |
| [^] | 不接收的字符列表 | [^slack] | 除s,l,a,c,k外的任意一个字符,包括数字和特殊字符 |
| - | 连字符 | A-Z | 任意的单个大写字母 |
| . | 匹配除\n以外的任意字符 | a..b | 以a开头,以b结尾,中间包含两个任意非\n字符的长度为4的字符串 |
| | | 选择匹配符 | [a|b|c] | 满足a,b,c中的任意一个即可 |
| \\d | 匹配单个数字字符,相当于[0-9] | \\d{3}(\\d)? | 包含3个或4个数字的字符串;?表示(\\d)可能为0次或1次(正则限定符?,*,+,{}) |
| \\D | 匹配单个非数字字符,相当于[^0-9] | \\D(\\d)* | 以单个非数字字符开头,后接任意个数字的字符串;*表示0次或多次 |
| \\w | 匹配单个数字或大小写字母字符或下划线,相当于[0-9a-zA-Z] | \\d{3}\\w{4} |
以3个数字字符开头,长度为7的数字字母字符串 |
| \\W | 匹配单个非数字,非大小写字母,非下划线字符,相当于[^0-9a-zA-Z] | \\W+\\d{2} | 以至少一个非数字字母字符开头,两个数字字符结尾的字符串;+表示1~多次 |
| \\s | 匹配任何空白字符(空格,制表符等) | \\s+ | 匹配至少连续一个空白字符 |
| \\S | 匹配任何非空白字符;与\\s相反 | \\S{3} | 匹配连续的三个非空白字符;{n}表示匹配确定数量的字符;{n,}表示匹配≥n的数量的字符;{n,m}表示匹配[n,m]数量的字符 |
PS : (1) java正则表达式默认贪婪匹配——即尽可能匹配更多的字符;若想使用非贪婪匹配,可以在+,*,{n}等元字符后加?,eg : \\d?。
(2) 若[]中出现?,表示匹配一个真正的?,等价于\\?。(*,+,.同样适用)
Δ代码演示
以RegExp_Demo2类为演示类,代码如下 :
package csdn.advanced.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class RegExp_Demo2 {
public static void main(String[] args) {
String context = "I have $233RA9BB apples and one of those apples is #666hhh$.";
//1.指定匹配格式
String regStr = "\\W+\\d{3}\\w{3}[A-B]*(\\W)?";
//2.创建模式对象
Pattern pattern = Pattern.compile(regStr);
//3.获取对应的匹配器(传入要检索的内容)
Matcher matcher = pattern.matcher(context);
//4.进行匹配
while (matcher.find()) {
System.out.println("Get —— " + matcher.group(0));
}
}
}
运行结果 :

3.关于字母大小写问题 :
Java正则表达式默认会区分字母的大小写,实现"不区分字母大小写"的方式如下——
1° (?i)abcd : 表示abcd均不区分大小写;
2° a(?i)bcd : 表示bcd均不区分大小写;
3° a((?i)b)cd : 表示仅有b不区分字母大小写;
4° 在获取Pattern对象的compile方法中,追加Pattern.CASE_INSENSITIVE参数,
eg :Pattern pattern = Pattern.compile(regStr, Pattern.CASE_INSENSITIVE);
Δ代码演示
以RegExp_Demo3类为演示类,代码如下 :
package csdn.advanced.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp_Demo3 {
public static void main(String[] args) {
String context = "My hobby is ABCDEabcde, abcdeABCDE, fGG and FGG";
//1.指定匹配格式
String regStr = "(?i)[a-e]{5}";
String regStr_EX = "(?i)fGG";
String regStr_pro = "abcde";
//2.创建模式对象
Pattern pattern = Pattern.compile(regStr);
Pattern pattern_EX = Pattern.compile(regStr_EX);
Pattern pattern_pro = Pattern.compile(regStr_pro, Pattern.CASE_INSENSITIVE);
//3.获取对应的匹配器
Matcher matcher = pattern.matcher(context);
Matcher matcher_EX = pattern_EX.matcher(context);
Matcher matcher_pro = pattern_pro.matcher(context);
//4.开始匹配
while (matcher.find()) {
System.out.println(matcher.group(0));
}
System.out.println("======================================");
while (matcher_EX.find()) {
System.out.println(matcher_EX.group(0));
}
System.out.println("======================================");
while (matcher_pro.find()) {
System.out.println(matcher_pro.group(0));
}
}
}
运行结果 :

4.元字符—定位符 :
1° 定义
定位符,用于规定要匹配的字符串出现的位置;比如在字符串的开始还是结束的位置。
2° 常用定位符
| 符号 | 含义 | 实例 | 解释 |
|---|---|---|---|
| ^ | 指定要检索内容的起始字符 | ^[0-9]+[a-z]* | 匹配以至少一个数字开头,后接任意个小写字母的字符串 |
| $ | 指定要检索内容的结束字符 | ^[0-9]//-[A-Z]+$ | 匹配以一个数字开头,后接一个连字符-,以任意个大写字母结束的字符串 |
| \\b | 匹配符合指定格式,又处于边界位置的字符串 | \\W\\b | 所谓边界位置,即该子字符串之后是空格或结束位置 |
| \\B | 匹配符合指定格式,但处于非边界位置的字符串 | \\W\\B | 非边界位置,即与\\b相反 |
3° 代码演示
以RegExp_Demo4类为演示类,代码如下 :
package csdn.advanced.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class RegExp_Demo4 {
public static void main(String args[]) {
String context = "A-140-#";
String context_EX = "Cyan_RA9_CSDN Cyan_Ra9 Cyan_RA9";
//1.指定匹配格式
String regStr = "^[ABC]\\-\\d{3}\\-\\W$";
String regStr_EX = "(Cyan_R((?i)A)9)\\b"; //\\b匹配2个; \\B匹配1个(第一个)
//2.创建模式对象
Pattern pattern = Pattern.compile(regStr);
Pattern pattern_EX = Pattern.compile(regStr_EX);
//3.获取对应的匹配器对象
Matcher matcher = pattern.matcher(context);
Matcher matcher_EX = pattern_EX.matcher(context_EX);
//4.进行匹配
while (matcher.find()) {
System.out.println("Matched : " + matcher.group(0));
}
System.out.println("-------------------------");
while (matcher_EX.find()) {
System.out.println("Matched : " + matcher_EX.group(0));
}
}
}
运行结果 :

四、分组
1.捕获分组 :
1° 非命名捕获
(pattern),非命名捕获,捕获匹配的字符串。编号为0的第一个捕获是由整个正则表达式模式匹配的文本,即group(0);其他捕获结果则根据左括号的顺序从1开始自动编号,即group(1), group(2)...等。
2° 命名捕获
(?<name>pattern),命名捕获。将匹配到的子字符串捕获到一个组名称或编号名称中。获取捕获到的内容时,既可以通过数字编号,也可以通过定义的名称。
3° 代码演示
以RegExp_Demo5类为演示类,代码如下 :
package csdn.advanced.regexp;
import java.sql.SQLOutput;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class RegExp_Demo5 {
public static void main(String[] args) {
String context = "I have 1314 apples, I have 4204 pens.";
//1.指定匹配格式
String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";
//2.创建模式对象
Pattern pattern = Pattern.compile(regStr);
//3.获取对应的匹配器对象
Matcher matcher = pattern.matcher(context);
//4.开始匹配
while (matcher.find()) {
System.out.println("整体的捕获结果 = " + matcher.group(0));
System.out.println("first group by number = " + matcher.group(1));
System.out.println("first group by name = " + matcher.group("g1"));
System.out.println();
System.out.println("second group by number = " + matcher.group(2));
System.out.println("second group by name = " + matcher.group("g2"));
System.out.println("===========================\n");
}
}
}
运行结果 :

2.非捕获分组 :
1° 分类
| 形式 | 说明 |
|---|---|
| (?:pattern) | 匹配符合pattern的子字符串,但不进行捕获;适用于"or"字符(|)组合模式部件的情况。(强调整体) eg : "Cyan_RA9|Cyan_EX|Cyan_Pro" ---> "Cyan_(?:RA9|EX|Pro)"。 |
| (?=pattern) | 非捕获匹配;与(?:pattern)不同的是,(?=pattern)只匹配满足特定条件的主体本身,而不包含条件中的内容。 |
| (?!pattern) | 非捕获匹配;匹配不符合pattern的起始点的搜索字符串。与(?=pattern)相反。 |
2° 演示
以RegExp_Demo6为演示类,代码如下 :
package csdn.advanced.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class RegExp_Demo6 {
public static void main(String[] args) {
String context_0 = "Cyan_RA9 Cyan_EX Cyan_Pro";
String context_1 = "Cyan_RA9 CSDN, Cyan_RA9 AliCloud, Cyan_RA9 HuaweiCloud";
String context_2 = "Cyan_RA9 Cyan_EX Cyan_Pro";
String regStr_0 = "Cyan_(?:RA9|EX|Pro)";
String regStr_1 = "Cyan_RA9(?= CSDN| AliCloud)";
String regStr_2 = "Cyan_RA9(?! CSDN| AliCloud)";
Pattern pattern_0 = Pattern.compile(regStr_0);
Pattern pattern_1 = Pattern.compile(regStr_1);
Pattern pattern_2 = Pattern.compile(regStr_2);
Matcher matcher_0 = pattern_0.matcher(context_0);
Matcher matcher_1 = pattern_1.matcher(context_1);
Matcher matcher_2 = pattern_2.matcher(context_2);
while (matcher_0.find()) {
System.out.println(matcher_0.group()); //不传入参数,默认调用group(0)
}
System.out.println("-----------------------------------");
while (matcher_1.find()) {
System.out.println(matcher_1.group());
}
System.out.println("-----------------------------------");
while (matcher_2.find()) {
System.out.println(matcher_2.group());
}
}
}
运行结果:

五、常用类
1.Pattern :
1° 简介
Pattern类对象是一个正则表达式对象。Pattern类没有公共构造方法,要创建一个Pattern对象,需要调用其公共静态方法compile(regStr),该方法接收一个正则表达式作为第一个参数,并最终返回一个Pattern对象,
2° 常用方法
matches(regStr, context)方法,返回一个布尔类型的变量,用于整体匹配,要求regStr匹配的是context整体,否则返回false。(底层实际仍然创建了Pattern和Matcher对象,并且,Pattern类的matches方法实际使用了Matcher类中的matches方法);因此,使用matches方法时,不要求正则表达式中要用^$定位符。代码如下 :
package csdn;
import java.util.regex.Pattern;
class Fruit {
public static void main(String[] args) {
String context = "Cyandjswojdao____dadwah21421212512@@@";
String regStr = "Cyan.*";
boolean matRes = Pattern.matches(regStr, context);
System.out.println(matRes ? true : false);
}
}
运行结果 :

当仅需要对context进行整体判断,而不需要保存匹配结果时,就可以使用matches方法,代码更加简洁明了。
2.Matcher :
1° 简介
Matcher对象是对输入字符串进行解释和匹配的引擎。与Pattern类一样,Matcher类也没有公共构造方法,需要调用Pattern对象的matcher(context)方法来获得一个Matcher对象。
2° 常用方法
| 方法 | 描述 |
|---|---|
| public int start() | 返回上次匹配的起始索引 |
| public int start(int group) | 返回上次匹配指定组的起始索引 |
| public int end() | 返回上次匹配的结束索引 |
| public int end(int group) | 返回上次匹配指定组的结束索引 |
| public boolean lookingAt() | 尝试从输入序列开头进行匹配 |
| public boolean find() | 尝试查找匹配当前模式的下一个子序列 |
| public boolean find(int start) | 重置当前匹配器,并从输入序列指定索引处开始匹配 |
| public boolean matches() | 尝试将整个区域(输入序列)进行匹配 |
| public String replaceAll(String replacement) | 用指定字符串替换原输入序列中满足模式的子字符串,并最终返回替换后的结果 |
| public String replaceFirst(String replacement) | 只替换满足模式的第一个子字符串,并返回替换后的结果 |
3.PatternSyntaxException :
1° 简介
PatternSyntaxException是一个非强制异常类,表示一个正则表达式中的语法错误。
六、反向引用
1.定义 :
分组后,圆括号中的内容被捕获,可以在这个括号后被使用,从而写出一个比较实用的匹配模式,称为“反向引用”。反向引用既可以存在于正则表达式的内部,使用\\ + 组号或者\\ + 组号{n};也可以存在于外部,使用$ + 组号。
2.反向引用实例 :
以RegExp_Demo7类为演示类,代码如下 :
package csdn.advanced.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class RegExp_Demo7 {
public static void main(String[] args) {
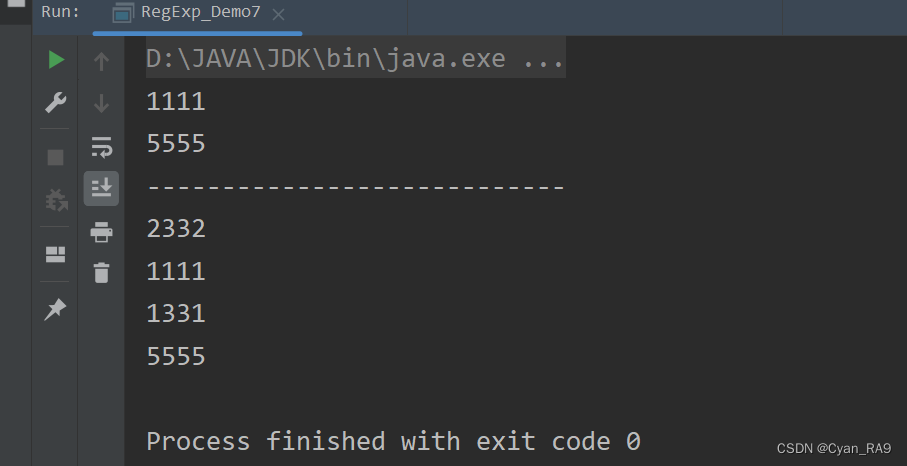
String context = "2332, I have 1111 love ,1331 patience and 5555 peace";
//match a number consist of four sequent identical numbers
String regStr = "(\\d)\\1{3}";
String regStr_EX = "(\\d)(\\d)\\2\\1"; //The number 1111 also correspond to that pattern
Pattern pattern = Pattern.compile(regStr);
Pattern pattern_EX = Pattern.compile(regStr_EX);
Matcher matcher = pattern.matcher(context);
Matcher matcher_EX = pattern_EX.matcher(context);
while (matcher.find()) {
System.out.println(matcher.group(0));
}
System.out.println("----------------------------");
while (matcher_EX.find()) {
System.out.println(matcher_EX.group(0));
}
}
}
运行结果 :
3.结巴去重实例 :
以RegExp_Demo8为演示类,代码如下 :
package csdn.advanced.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp_Demo8 {
public static void main(String[] args) {
String context = "I ....reliiiiish .......eeeeeeating gggggrape....!";
System.out.println("state.0 = " + context);
String regStr = "\\.";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(context);
//1.去除"."
context = matcher.replaceAll("");
System.out.println("stage.1 = " + context);
//2.去重结巴
matcher = Pattern.compile("(.)\\1+").matcher(context);
//正则表达式外部的反向应用 ——— “$ + 组号”
context = matcher.replaceAll("$1");
System.out.println("state.2 = " + context);
}
}

七、总结
首先,对于一般的正则表达式的使用步骤(Pattern-Matcher)要熟悉;其次,对于regStr中一些常用的元字符要熟悉;此外,捕获分组和非捕获分组要有印象,反向引用及其利处也要了解。
PS : String类中的一些方法,例如replaceAll, matches, split等,也支持正则表达式。



System.out.println("END----------------------------------------------------------------------------");

- 点赞
- 收藏
- 关注作者
评论(0)