JDBC 事务和批处理 详解(通俗易懂)

目录
一、前言
- 第四节内容,up主要和大家分享一下JDBC——事务,批处理方面的内容。PS : 若大家对事务没有任何认识,先去阅读up之前的的博文。
- 注意事项——①代码中的注释也很重要;②不要眼高手低;③点击文章的侧边栏目录或者文章开头的目录可以进行跳转。
- 良工不示人以朴,所有文章都会适时补充完善。大家如果有问题都可以在评论区进行交流或者私信up。 感谢阅读!
二、事务
1.事务介绍 :
JDBC程序中,当一个Connection(实现类)对象被创建后,默认情况下是自动提交事务;即每次成功执行一个SQL,都会向对应的数据库自动提交,而不能回滚。为了让多个SQL在JDBC中作为一个整体来执行,我们就需要用到“事务”,以保证数据的一致性。
可以使用Connection接口中的setAutoCommit(false)方法(动态绑定后,实际为实现类的方法),传入一个false,可以取消自动提交事务;当所有SQL都成功执行后,可以调用Connection接口的commit方法来提交事务;若中途出现失败或异常,则可以调用Connection接口的rollback方法回滚事务。
2.事务处理 :
Δ准备工作
以“转账”操作为栗。
我们先来建一张账户表accounts,代码如下 :
CREATE TABLE IF NOT EXISTS `accounts`(
`id` INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(64) NOT NULL DEFAULT '',
`balance` DECIMAL(16,2) NOT NULL DEFAULT 0.0
) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin ENGINE INNODB;
INSERT INTO accounts(`name`,balance)
VALUES
('Cyan', 1000),
('Five', 1900),
('Alice', 2100);
SELECT * FROM accounts;账户表效果如下 :

Δ不使用事务的情况
先在不使用事务的情况下进行转账操作,看看会出现什么问题:
令Cyan转给Five 200块,最终Cyan应该是800,Five是2100;但是,假设在Cyan发出转账后,Five收取转账失败了。那会发生什么结果?
up以NoTransaction类为演示类,代码如下 :
package transaction;
import utils.JDBCUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class NoTransaction {
public static void main(String[] args) throws ClassNotFoundException {
//1.注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接
Connection connection = null;
//3.执行SQL
PreparedStatement preparedStatement = null;
String sql1 = "UPDATE accounts " +
"SET balance = balance - 200 " +
"WHERE `name` = ?;";
String sql2 = "UPDATE accounts " +
"SET balance = balance + 200 " +
"WHERE `name` = ?;";
try {
connection = JDBCUtils.getConnection();
preparedStatement = connection.prepareStatement(sql1);
preparedStatement.setString(1,"Cyan");
/** 若在初始化preparedStatement对象时,已经与要执行的SQL绑定,则执行时不能再传入SQL参数! */
preparedStatement.executeUpdate();
//抛出一个算术异常(ArithmeticException),阻止第二条SQL语句的执行
int i = 1 / 0;
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.setString(1,"Five");
/** 若在初始化preparedStatement对象时,已经与要执行的SQL绑定,则执行时不能再传入SQL参数! */
preparedStatement.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
//4.释放资源
JDBCUtils.close(null,preparedStatement,connection);
}
}
}
程序如我们所料,在int i = 1/0; 处出现算术异常,如下图所示 :

此时如果我们查询accounts表,会发现出大问题了!如下图所示 :

Cyan凭空消失了200块钱😱。原因也很简单:发出转账操作的DML顺利执行,而接收转账操作的DML——由于异常的抛出——没有顺利执行;但是由于JDBC默认是自动提交事务的,因此发出转账的操作对数据库产生了永久的影响(事务的持久性)。
Δ使用事务的情况
使用事务后,我们可以轻松解决以上问题。
up以WithTransaction类为演示类,代码如下 :
package transaction;
import utils.JDBCUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class WithTransaction {
public static void main(String[] args) throws ClassNotFoundException {
//1.注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接
Connection connection = null;
//3.执行SQL
PreparedStatement preparedStatement = null;
String sql1 = "UPDATE accounts " +
"SET balance = balance - 200 " +
"WHERE `name` = ?;";
String sql2 = "UPDATE accounts " +
"SET balance = balance + 200 " +
"WHERE `name` = ?;";
try {
connection = JDBCUtils.getConnection();
/** 开启一个事务 */
connection.setAutoCommit(false);
preparedStatement = connection.prepareStatement(sql1);
preparedStatement.setString(1,"Cyan");
preparedStatement.executeUpdate();
//抛出一个算术异常(ArithmeticException),试图阻止第二条SQL语句的执行
int i = 1 / 0;
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.setString(1,"Five");
preparedStatement.executeUpdate();
/** 若没有出现异常,则在SQL执行完毕后,提交事务。*/
connection.commit();
} catch (SQLException e) {
/** 若事务执行过程中发生异常,捕获异常后进行回滚,
默认回滚到事务开启时的状态。 */
try {
connection.rollback();
} catch (SQLException ex) {
throw new RuntimeException(ex);
}
throw new RuntimeException(e);
} finally {
//4.释放资源
JDBCUtils.close(null,preparedStatement,connection);
}
}
}
仍然是抛出一个算术异常,如下图所示 :

这时候如果我们查询accounts表,会发生数据没有发生变化,如下图所示 :

显然,由于事务机制的加入,我们可以轻松避免错误情况的发生。那么,正确的情况又如何呢?接下来,我们将制造异常的int i = 1/0; 语句给注释掉,如下图所示 :

再次尝试执行代码 :

可以看到,无异常抛出。再次查询accounts表,如下 :

🐂🍺,这下Cyan的💴好歹是“死得其所”了(bushi)。
三、批处理
1.介绍 :
当需要成批地执行DML时,可以采用Java提供的批量更新机制。这一机制允许多条SQL一次性地提交给数据库进行批量处理,通常比单独提交SQL效率更高。
Java批处理机制往往与PreparedStatement一起搭配使用,既可以减少编译次数(预处理),又可以减少运行次数,极大地提高了SQL执行效率。
2.常用方法 :
1° addBatch() : 向集合中添加需要批量处理的SQL或者参数;
2° executeBatch() : 执行批量处理语句;
3° clearBatch() : 清空当前批处理包内的语句;
PS :
ΔJDBC连接MySQL时,如果要使用批处理功能,需要在url 中加入参数?rewriteBatchedStatements=true
3.应用 :
为了明确的看到批处理机制对执行效率的提升,up打算统计大量DML语句的执行时间,对比在未使用批处理机制和使用批处理机制后,DML语句执行时间的差异。PS : 可以使用System类的静态方法currentTimeMillis()。
还是先来建一张表,up以狗表(dogs)为例,代码如下 :
CREATE TABLE IF NOT EXISTS `dogs`(
`id` MEDIUMINT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(64) NOT NULL DEFAULT ''
) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin ENGINE INNODB;
SELECT * FROM dogs;狗表效果如下 :

现要求向狗表中加入10000只🐕,看看需要多长时间执行完;
up以NoBatch类为演示类,代码如下 :
package batch;
import utils.JDBCUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
public class NoBatch {
public static void main(String[] args) throws ClassNotFoundException {
//JDBC核心四部曲
//1.注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接
Connection connection = null;
//3.执行SQL
PreparedStatement preparedStatement = null;
String sql = "INSERT INTO dogs " +
"VALUES " +
"(null,?);";
try {
connection = JDBCUtils.getConnection();
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1, "狗");
System.out.println("开始执行万🐕SQL!");
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
preparedStatement.executeUpdate();
}
long end = System.currentTimeMillis();
System.out.println("万🐕SQL执行完毕,一共用时:" + (end - start) + "ms");
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
//4.释放资源
JDBCUtils.close(null, preparedStatement, connection);
}
}
}
运行效果 :

可以看到,用了足足2s多。
我们再来看看用了批处理机制后性能会有多大提升:记住,别忘了在url中加入?rewriteBatchedStatements=true参数,如下图所示 :

然后,我们清空dogs表中的全部数据 :
TRUNCATE TABLE dogs;
接下来测试使用批处理机制后,万🐕SQL的执行时间。
up以WithBatch类为演示类,代码如下 :
package batch;
import utils.JDBCUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class WithBatch {
public static void main(String[] args) throws ClassNotFoundException {
//JDBC核心四部曲
//1.注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接
Connection connection = null;
//3.执行SQL
PreparedStatement preparedStatement = null;
String sql = "INSERT INTO dogs " +
"VALUES " +
"(null,?);";
try {
connection = JDBCUtils.getConnection();
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1, "狗");
System.out.println("开始执行万🐕SQL!");
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
preparedStatement.addBatch();
//批处理包中每满1000条SQL,就一次性发送给MySQL进行处理。
if ((i + 1) % 1000 == 0) {
preparedStatement.executeBatch();
preparedStatement.clearBatch(); //执行后及时清理当前集合内的SQL
}
}
long end = System.currentTimeMillis();
System.out.println("万🐕SQL执行完毕,一共用时:" + (end - start) + "ms");
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
//4.释放资源
JDBCUtils.close(null, preparedStatement, connection);
}
}
}
运行结果 :

可以看到,从2204ms到113ms,性能的提升是肉眼可见的。
4.源码分析(JDK17.0版本) :
如下图所示,在addBatch()方法处下断点 :

![]()
接着,跳入addBatch方法,如下图所示 :

注意,checkAllParametersSet()方法就是对你通过setXxx传入的参数进行校验(对?的赋值),同时也进行一些预编译的工作。
其实,我们跳入的addBatch方法是位于ClientPreparedStatement类中的,那么,ClientPreparedStatement类又是何方神圣呢?
我们来看一下它的类图就明白了,如下所示 :

挑重点说,ClientPreparedStatement类直接继承自StatementImpl类,并且间接实现了PreparedStatement接口。
继续,我们可以发现这个addBatch方法并没有涉及到什么集合,但是它最后又调用了一个带参的addBatch方法,如下 :

我们接着追进去看看,如下 :

追进去后的addBatch方法位于AbstractQuery类中(该类实现了Query接口),我们还是把重点放在代码本身上,可以看到,这个addBatch方法底层,其实是new了一个ArrayList类的对象,并且将当前的SQL语句加入到了ArrayList集合中。
不难猜出,batchedArgs是一个List类型或者ArrayList类型,看下它的源码 :

果然如此。
再往下调用的就是ArrayList类的add方法了,这里不再赘述。up之前已经出过一篇专门的文章,非常详细,有兴趣的小伙伴儿可以去看看。
继续,当我们将第一句SQL添加到ArrayList集合中后,便可以发现elementData数组中已经有了一个元素,如下图所示 :
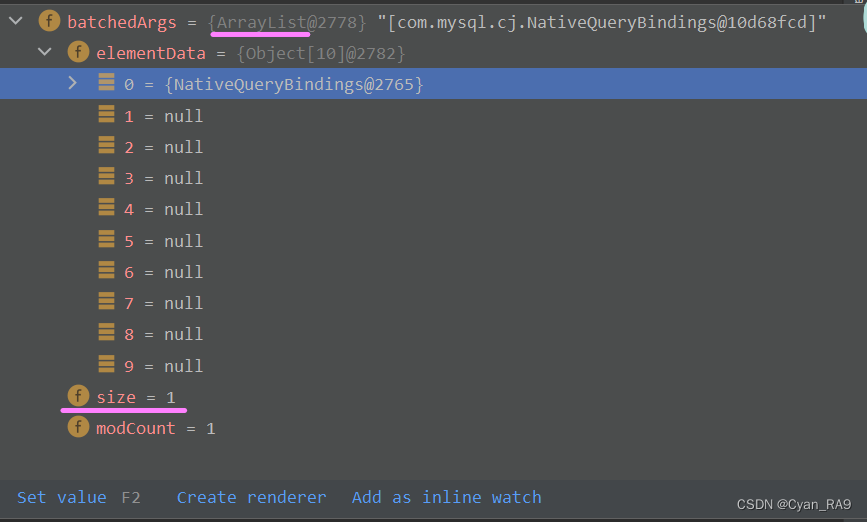
当然,关于elementData数组的本质及它的扩容问题,还是建议大家去看up的ArrayList类源码分析。 这里我们只需要明白——批处理机制的本质,就是将多条SQL打包到了ArrayList集合中,然后统一发送给MySQL,因此减少了执行次数。比如我们这里有10000条SQL,每批执行1000条,只需要执行10次即可;若没有批处理机制,那就是执行10000条,挨个执行,自然网络开销就上来了。
四、总结
- 🆗,以上就是JDBC系列博文第四节的全部内容了。
- 总结一下,为了保证进行DML操作时数据的一致性,Java提供了事务机制,只有一组SQL都成功执行才提交事务,否则回滚。而为了提高多条DML的执行效率,Java又提供了批处理机制,通过Debug我们也发现,批处理机制的本质就是将多条SQL打包到集合中,成批成批地发送给MySQL,减少了网络传输的次数,批处理机制与PreparedStatement配合使用,可以极大地提高SQL执行效率。
- 下一节内容——JDBC 连接池,我们不见不散。感谢阅读!
System.out.println("END-----------------------------------------------------------------------------");

- 点赞
- 收藏
- 关注作者
评论(0)