
一、前言
不就展示一个富文本吗,有啥难的,至于这么大惊小怪吗,哎,各位老铁,莫慌,先看需求,咱们再一探究竟。
1、大致需求
要求,用户内容编辑页面,实现图文混排,1、图片随意位置插入,并且可长按拖动排序;2、图片拖动完成之后,上下无内容,则需要空出输入位置,有内容,则无需空出;3、内容支持随意位置插入;4、以富文本的形式传入后台;5、解析富文本,回显内容。
2、大致效果图

实现这个需求倒不是很难,直接一个RecyclerView就搞定了,无非就是使用ItemTouchHelper,再和RecyclerView绑定之后,在onMove方法里实现Item的位置转换,当然需要处理一些图片和输入框之间的逻辑,这个不是本篇文章的重点,以后再说一块。
效果的话,我又单独的写了一个Demo,和项目中用到的一样,具体效果如下:

获取富文本的方式也是比较的简单,无论文本还是图片,最终都是存到集合中,我们直接遍历集合,给图片和文字设置对应的富文本标签即可,具体的属性,比如宽高,颜色大小,可以自行定义,大致如下:
/**
* AUTHOR:AbnerMing
* INTRODUCE:返回富文本数据
*/
fun getRichContent(): String {
val endContent = StringBuffer()
mRichList.forEach {
if (it.isPic == 0) {
//图片
endContent.append("<img src=\"" + it.image + "\"/>")
} else {
//文本
endContent.append("<p>" + it.text + "</p>")
}
}
return endContent.toString()
}以上的各个环节,不管怎么说,还是比较的顺利,接下来就到了我们今日的话题了,富文本我们是传上去了,但是如何回显呢?
二、富文本回显分析
回显有两种情况,第一种是编辑之后,可以保存至草稿,下次再编辑时,需要回显;第二种情况是,内容已经发布了,可以再次编辑内容。
具体的草稿回显有多种方式,我们不是使用RecyclerView实现的吗,直接保存列表数据就可以了,可以使用本地或者数据库形式的存储方式,不管使用哪种,实现起来绝非难事,回显的时候也是以集合的形式传入RecyclerView即可。
内容已经发布过的,这才是探究的重点,由于接口返回的是富文本信息,一开始无脑想到的是,富文本信息还得要解析里边的内容,着实麻烦,想着每次发布成功之后在本地存储一份数据,在编辑的时候,根据约定好的标识去存储的数据里找,确实可以实现,但是忽略了这是网络数据,是可以更换设备的,换个设备,数据从哪取呢?哈哈,这种投机取巧的方案,实在是不可取。
那没办法了,解析富文本呗,然后逐次取出图片和内容,再封装成集合,回显到RecyclerView中即可。
三、富文本解析
以下是发布成功后,某个字段的富文本信息,我们拿到之后,需要回显到编辑的页面,也就是自定义的RecyclerView中,老铁们,你们的第一解决方案是什么?
<p>我是测试内容</p><p>我是测试内容12333</p><img src="https://www.vipandroid.cn/ming/image/gan.png"/><p>我是测试内容88888</p><p>我是测试内容99999999</p><img src="https://www.vipandroid.cn/ming/image/zao.png"/>我们最终需要拿到的数据,如下,只有这样,我们才能逐一封装到集合,回显到列表中。
我是测试内容
我是测试内容12333
https://www.vipandroid.cn/ming/image/gan.png
我是测试内容88888
我是测试内容99999999
https://www.vipandroid.cn/ming/image/zao.png字符串截取呗,我相信这是大家的第一直觉,以什么方式截取,才能拿到标签里的内容呢?可以负责任的告诉大家,截取是可以实现的,需要实现的逻辑有点多,我简单的举一个截取的例子:
content = content.replace("<p>", "")
val split = content.split("</p>")
val contentList = arrayListOf<String>()
for (i in split.indices) {
val pContent = split[i]
if (TextUtils.isEmpty(pContent)) {
continue
}
if (pContent.contains("img")) {
//包含了图片
val imgContent = pContent.split("/>")
for (j in imgContent.indices) {
val img = imgContent[j]
if (img.contains("img")) {
//图片,需要再次截取
val index = img.indexOf("\"")
val last = img.lastIndexOf("\"")
val endImg = img.substring(index + 1, last)//最终的图片内容
contentList.add(endImg)
} else {
//文本内容
contentList.add(img)
}
}
} else {
contentList.add(pContent)
}
}截取的方式有很多种,但是无论哪一种,你的判断是少不了的,为了取得对应的内容,不得不多级嵌套,不得不一而再再而三的进行截取,虽然实现了,但是其冗余了代码,丢失了效率,目前还是仅有两种标签,如果说以后的富文本有多种标签呢?想想都可怕。
有没有一种比较简洁的方式呢?必须有,那就是正则表达式,需要解决两个问题,第一、正则怎么用?第二,正则表达式如何写?搞明白这两条之后,获取富文本中想要的内容就很简单了。
四、Kotlin中的正则使用
说到正则,咱就不得不聊聊Java中的正则,这是我们做Android再熟悉不过的,一般也是最常用的,基本代码如下:
String str = "";//匹配内容
String pattern = "";//正则表达式
Pattern r = Pattern.compile(pattern);
Matcher m = r.matcher(str);
System.out.println(m.matches());获取匹配内容的话,取对应的group即可,这个例子太多了,就不单独举了,除了Java中提供的Api之外,在Kotlin当中,也提供了相关的Api,使用起来也是无比的简单。
在Kotlin中,我们可以使用Regex这个对象,主要用于搜索字符串或替换正则表达式对象,我们举几个简单的例子。
1、判定是否包含某个字符串,containsMatchIn
val regex = Regex("Ming")//定义匹配规则
val matched = regex.containsMatchIn("AbnerMing")//传入内容
print(matched)输出结果
true2、匹配目标字符串matches
val regex = """[A-Za-z]+""".toRegex()//只匹配英文字母
val matches1 = regex.matches("abcdABCD")
val matches2 = regex.matches("12345678")
println(matches1)
println(matches2)输出结果
true
false3、返回首次出现指定字符串find
val time = Regex("""\d{4}-\d{1,2}-\d{1,2}""")
val timeValue= time.find("今天是2023-6-28,北京,有雨,请记得带雨伞!")?.value
println(timeValue)输出结果
2023-6-284、返回所有情况出现目标字符串findAll
val time = Regex("""\d{4}-\d{1,2}-\d{1,2}""")
val timeValue = time.findAll(
"今天是2023-6-28,北京,有雨,请记得带雨伞!" +
"明天是2023-6-29,可能就没有雨了,具体得等到后天2023-6-30日才能知晓!"
)
timeValue.forEach {
println(it.value)
}输出结果
2023-6-28
2023-6-29
2023-6-30ok,当然了,里面还有许多方法,比如替换,分割等,这里就不介绍了,后续有时间补一篇,基本上常用的就是以上的几个方法。
五、富文本使用正则获取内容
一个富文本里的标签有很多个,显然我们都需要进行获取里面的内容,这里肯定是要使用findAll这个方法了,但是,我们该如何设置标签的正则表达式呢?
我们知道,富文本中的标签,都是有左右尖括号组成的,比如<p></p>,<a></a>,当然也有单标签,比如<img/>,<br/>等,那这就有规律了,无非就是开头<开始,然后是不确定字母,再加上结尾的>就可以了。
1、标签精确匹配
比如有这样一个富文本,我们要获取所有的<p></p>标签。
<div>早上好啊</div><p>我是一个段落</p><a>我是一个链接</a><p>我是另一个一个段落</p>我们的正则表达式就如下:
<p.*?>(.*?)</p>什么意思呢,就是以<p开头,</p>结尾,这个点. 是 除换行符以外的所有字符,* 为匹配 0 次或多次,? 为0 次或 1 次匹配,之所以开头这样写<p.*?>而不是<p>,一个重要的原因就是需要匹配到属性或者空格,要不然富文本中带了属性或空格,就无法匹配了,这个需要注意!
基本代码
val content = "<div>早上好啊</div><p>我是一个段落</p><a>我是一个链接</a><p>我是另一个一个段落</p>"
val matchResult = Regex("""<p.*?>(.*?)</p>""").findAll(content)
matchResult.forEach {
println(it.value)
}运行结果
<p>我是一个段落</p>
<p>我是另一个一个段落</p>看到上面的的结果,有的老铁就问了,我要的是内容啊,怎么把标签也返回了,这好像有点不对吧,如果说我们只要匹配到的字符串,目前是对的,但是想要标签里的内容,那么我们的正则需要再优化一下,怎么优化呢,就是增加一个开始和结束的位置,内容的开始位置是”<“结束位置是”>“,如下图
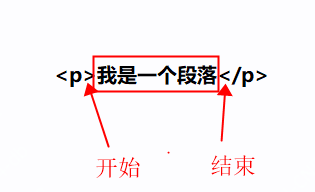
我们只需要更改下起始位置即可:
匹配内容
val content = "<div>早上好啊</div><p>我是一个段落</p><a>我是一个链接</a><p>我是另一个一个段落</p>"
val matchResult = Regex("""(?<=<p>).*?(?=</p>)""").findAll(content)
matchResult.forEach {
println(it.value)
}运行结果
我是一个段落
我是另一个一个段落2、所有标签进行匹配
有了标签精确匹配之后,针对富文本里的所有的标签内容匹配,就变得很是简单了,无非就是要把上边案例中的p换成一个不确定字母即可。
匹配内容
val content = "<div>早上好啊</div><p>我是一个段落</p><a>我是一个链接</a><p>我是另一个一个段落</p>"
val matchResult = Regex("""(?<=<[A-Za-z]*>).+?(?=</[A-Za-z]*>)""").findAll(content)
matchResult.forEach {
println(it.value)
}运行结果
早上好啊
我是一个段落
我是一个链接
我是另一个一个段落3、单标签匹配
似乎已经满足我们的需求了,因为富文本中的内容已经拿到了,封装到集合之中,传递到列表中即可,但是,以上的正则似乎只针对双标签的,带有单标签就无法满足了,比如,我们再看下初始我们要匹配的富文本,以上的正则是匹配不到img标签里的src内容的,怎么搞?
<p>我是测试内容</p><p>我是测试内容12333</p><img src="https://www.vipandroid.cn/ming/image/gan.png"/><p>我是测试内容88888</p><p>我是测试内容99999999</p><img src="https://www.vipandroid.cn/ming/image/zao.png"/>很简单,单标签单独处理呗,还能咋弄,多个正则表达式,用或拼接即可,属性值也是这样的获取原则,定位开始和结束位置,比如以上的img标签,如果要获取到src中的内容,只需要定位开始位置”src="“,和结束位置”"“即可。
匹配内容
val content =
"<p>我是测试内容</p><p>我是测试内容12333</p><img src=\"https://www.vipandroid.cn/ming/image/gan.png\"/><p>我是测试内容88888</p><p>我是测试内容99999999</p><img src=\"https://www.vipandroid.cn/ming/image/zao.png\"/>"
val matchResult =
Regex("""((?<=<[A-Za-z]*>).+?(?=</[A-Za-z]*>))|((?<=src=").+?(?="))""").findAll(content)
matchResult.forEach {
println(it.value)
}运行结果
我是测试内容
我是测试内容12333
https://www.vipandroid.cn/ming/image/gan.png
我是测试内容88888
我是测试内容99999999
https://www.vipandroid.cn/ming/image/zao.png这不就完事了,简简单单,心心念念的数据就拿到了,拿到富文本标签内容之后,再封装成集合,回显到RcyclerView中就可以了,这不很easy吗,哈哈~
点击草稿,效果如下:

六、总结
在正向的截取思维下,正则表达式无疑是最简单的,富文本,无论是标签匹配还是内容以及属性,都可以使用正则进行简单的匹配,轻轻松松就能搞定,需要注意的是,不同属性的匹配规则是不一样的,需要根据特有的情况去分析。

评论(0)