驾驭千级节点——揭秘PUMA大规模集群能力(二)——瓶颈分析

PUMA:Portable(Programmable) and Unified Message Architecture,统一开放消息总线,解决大规模分布式应用的通讯问题,属于分布式与并行软件实验室推出的HARES的子部件,保障消息通信高可靠、搞吞吐、高扩展。
1 理论分析
前面介绍了针对大规模集群的产品诉求和业界分析,下面来说说集群大规模化的理论分析;PUMA集群分为broker(server节点)、client(消费者和生产者)、zookeeper这三大块,我这里分别分析这三个模块是否会成为PUMA集群大规模化的瓶颈。
1.1 Broker
前面说过,PUMA集群内的节点间是松耦合的,就是集群内节点间的关系比较松散,一般是通过controller或者zk来进行交互,其他节点间除了副本同步外基本没有交互;理论上说这种松散的集群中的节点数是没有上限的,可以无限增加(其实受zk上znode数量的限制)。
PUMA的server配置文件中需要配置一个server.id,其值要求为一个非负整数,就是每一个节点单独配置一个,不能重复;需要确认这个值最大可以配置多少,我这边查阅了相关资料和源代码,没发现有信息说server.id的值会受限的,也就是说这个值在INT型整数范围内都是合法的。
1.2 Client
PUMA消息总线的producer和consumer都可以看做是PUMA集群的client,一般情况下,client和PUMA的server集群是解耦的,client的数量受限于所有server节点的最大连接数之和,在现有的技术下,一台配置中等的服务器,其最大连接数一般都是百万级别的,和宿主系统的内存及部分内核参数有关;因此,client的数量原则上不会影响集群节点的数量,而且集群节点数越大,能支撑的client数量肯定也越大。
1.3 Zookeeper
前面说过,PUMA选型于kafka的,总所周知,kafka需要连接一套zookeeper才能正常工作,甚至如果你使用的是低版的kafka,其consumer也需要连接zk,而且,kafka会在zk上注册大量的znode,同时,kafka的controller和consumer会watch一部分znode,在有新的节点加入集群或者有新的topic创建都会触发相应的watch事件;那么在千节点的大规模集群中,zk能支撑这么多的znode和watch吗?我们来看看kafka在zk上的存储结构,如下图:
从上图可以看到,znode数比较多就是brokers的ids、topic的partition以及consumer的offsets等等,另外,zk还有自身的一些瓶颈,如下:
1、 zk中name node数量理论上仅受限于内存,但一个节点下的子节点数量受限于该节点的数据不能超过1M的限制,同时如果有很多包含成千上万子节点的znode,zk的性能会变的很差。
2、 zk的单台机器的连接数限制,默认为60,就是单个broker连接zk的连接数不能超过这个值,可以修改配置文件提高该值
3、 kafka的broker和consumer会对zk的一部分znode进行watch,如果一个znode 的watch过多,比如达到50w,在fire后进行事件通知的时候会报错,另外,zk有1MB的数据传输限制,因此,znode上的的数据必须要小于这个值
4、 zk节点数超过5之后,随着节点数的增加,读性能增长不明显,相反,写性能会下降,所以,一般zk的部署都是5节点或者7节点
结合以上的分析第二条和第四条应该不会成为瓶颈,而且我们后面的实测过程中一直是三节点的zk在跑,整个测试过程中,zk侧没有发现任何问题。
第一条和第三条需要进行测试才能知道是否会成为瓶颈,下面我来对zk做一下针对性测试,主要针对kafka和zk的之间的交互来做以下两点测试:znode数量和watch数量的压力测试
1.3.1 测试创建大量znode和子znode
从前面的图片可以看到,随着kafka集群节点数量的增加,kafka在zk上注册的znode数量也会增加,我这里测试时使用了自己写的测试程序,模拟在zk上创建大量节点,如下
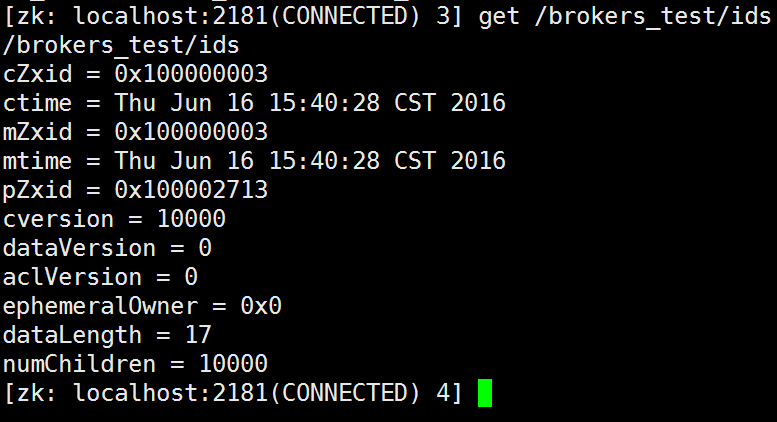
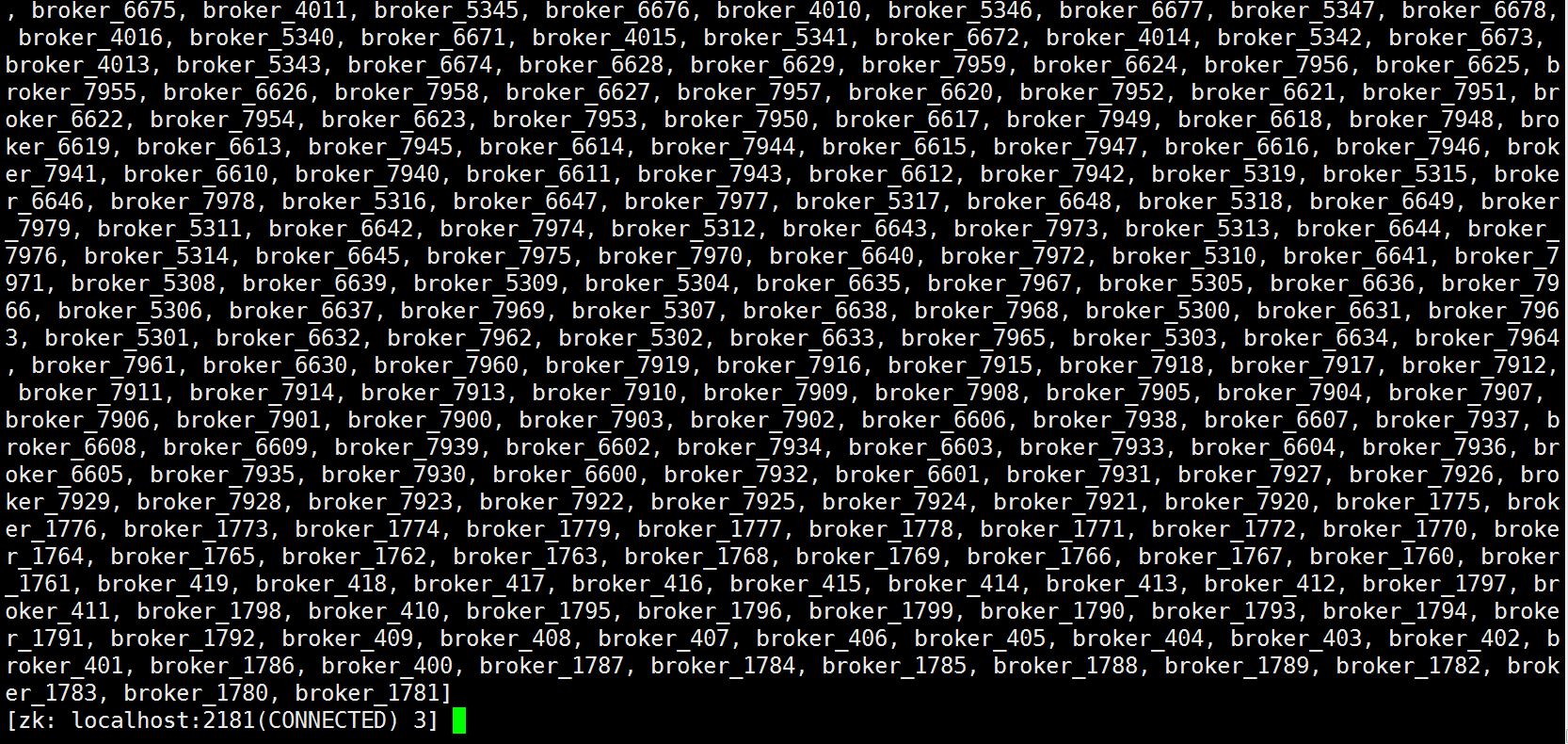
模拟创建10000个broker节点,下面的numChildren的值就是broker子节点的数量
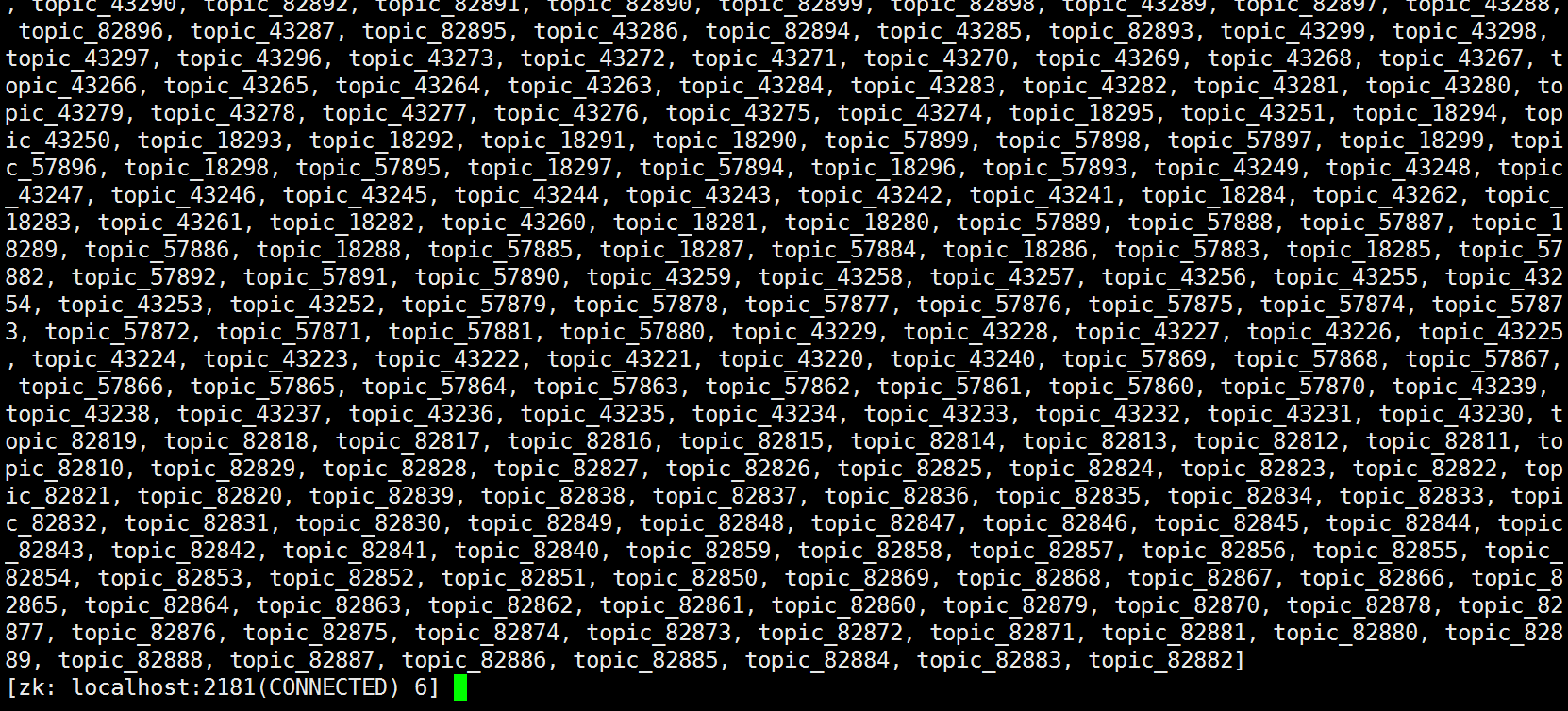
模拟创建100000个topic节点,如下,下面的numChildren的值就是topic子节点的数量
结论,zk能支撑kafka达到1000节点数、100000个topic数的集群规模,znode的数量不会成为PUMA集群大规模化的瓶颈。
1.3.2 测试watch数
kafka的broker和consumer会watch部分znode,而且随着broker和consumer的增多,watch的数量也会增加。下面来测试下zk的watch连接数,如下命令可以查看zk上的watch数
当前连接数19.3w
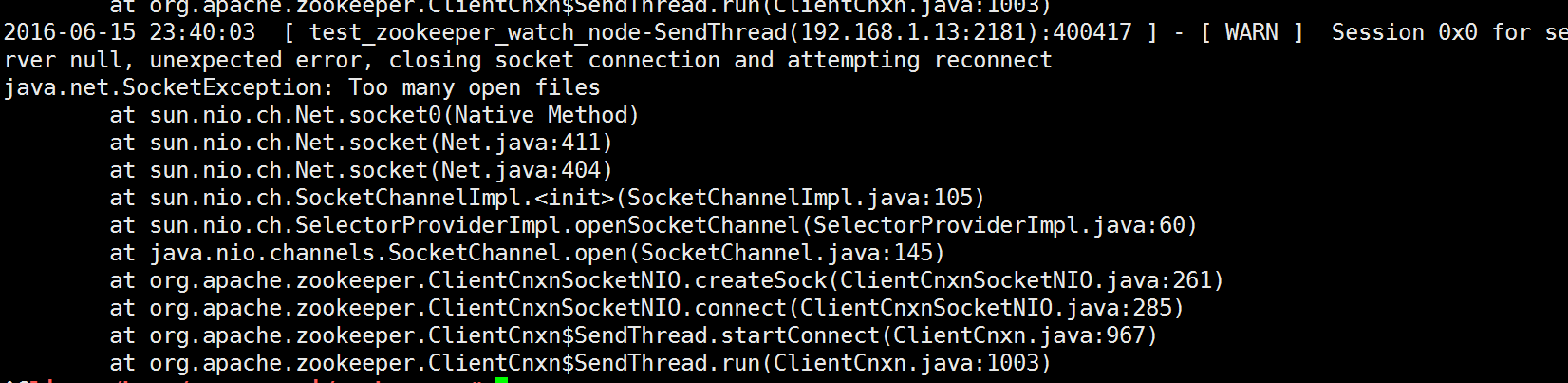
在测试过程中要注意下,需要修改内核参数的,我这里忘记修改内核参数了,文件句柄上限满了,如下
修改句柄后,重新运行脚本程序,发现连接数慢慢突破了,一直上涨
可以发现,很快就超过30w的watch了,还能继续增加
测试过程中,受限于测试机器的内存和测试程序的原因,最大watch数达到了140w,zk能正常工作,读写znode,watch事件均能正常通知。
内存不足了,不能再new 客户端了
修改zk数据,观察watch事件能否通知
可以看到,watch事件均能正常通知。
后面又协调了几台物理机,又重新做了下压测,发现watch数能达到1000w左右,如下图:
1.4 小结
通过前面的分析,可以初步得出一个结论,PUMA集群的broker、client、zookeeper都不是集群大规模化的瓶颈(关于这一点,在后续的测试中也得到了证实),那么是不是说明搭建大规模的PUMA集群是可行的,搭建好的大规模集群是可用的呢?现在还不能这么说,毕竟业界没有大规模kafka集群使用的案例,而且即使千节点的PUMA集群搭建成功了,是否可用也需要进行验证,如果集群搭建成功后,其tps很低,或者消息收发时延很高,这显然也是不行的
【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请发送邮件至hwclouds.bbs@huawei.com;如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
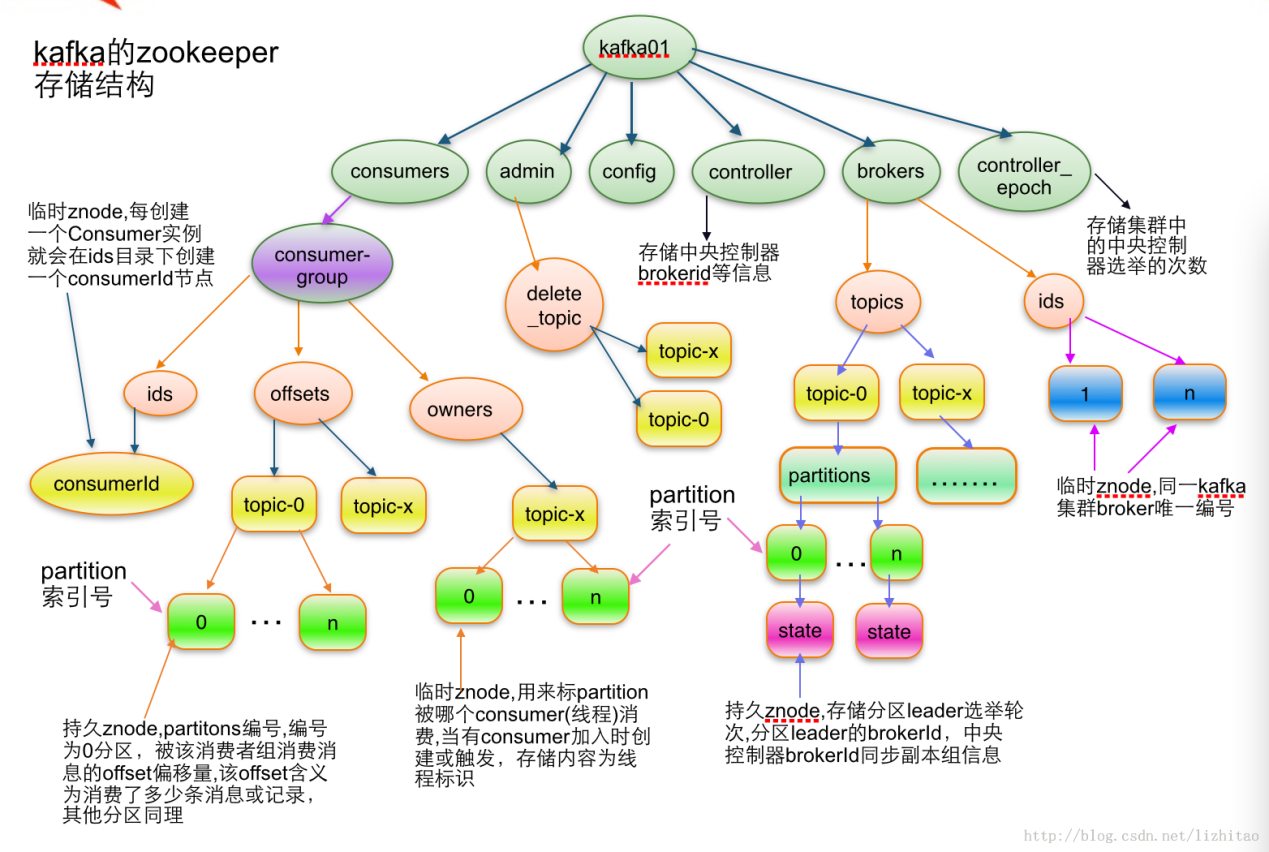
从上图可以看到,znode数比较多就是brokers的ids、topic的partition以及consumer的offsets等等,另外,zk还有自身的一些瓶颈,如下:
1、 zk中name node数量理论上仅受限于内存,但一个节点下的子节点数量受限于该节点的数据不能超过1M的限制,同时如果有很多包含成千上万子节点的znode,zk的性能会变的很差。
2、 zk的单台机器的连接数限制,默认为60,就是单个broker连接zk的连接数不能超过这个值,可以修改配置文件提高该值
3、 kafka的broker和consumer会对zk的一部分znode进行watch,如果一个znode 的watch过多,比如达到50w,在fire后进行事件通知的时候会报错,另外,zk有1MB的数据传输限制,因此,znode上的的数据必须要小于这个值
4、 zk节点数超过5之后,随着节点数的增加,读性能增长不明显,相反,写性能会下降,所以,一般zk的部署都是5节点或者7节点
结合以上的分析第二条和第四条应该不会成为瓶颈,而且我们后面的实测过程中一直是三节点的zk在跑,整个测试过程中,zk侧没有发现任何问题。
第一条和第三条需要进行测试才能知道是否会成为瓶颈,下面我来对zk做一下针对性测试,主要针对kafka和zk的之间的交互来做以下两点测试:znode数量和watch数量的压力测试
从前面的图片可以看到,随着kafka集群节点数量的增加,kafka在zk上注册的znode数量也会增加,我这里测试时使用了自己写的测试程序,模拟在zk上创建大量节点,如下
模拟创建10000个broker节点,下面的numChildren的值就是broker子节点的数量
模拟创建100000个topic节点,如下,下面的numChildren的值就是topic子节点的数量

结论,zk能支撑kafka达到1000节点数、100000个topic数的集群规模,znode的数量不会成为PUMA集群大规模化的瓶颈。
kafka的broker和consumer会watch部分znode,而且随着broker和consumer的增多,watch的数量也会增加。下面来测试下zk的watch连接数,如下命令可以查看zk上的watch数
当前连接数19.3w
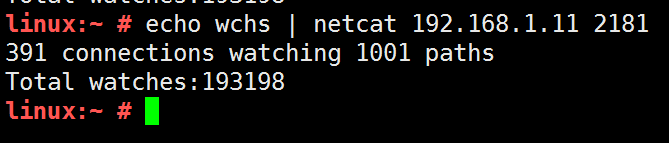
在测试过程中要注意下,需要修改内核参数的,我这里忘记修改内核参数了,文件句柄上限满了,如下
修改句柄后,重新运行脚本程序,发现连接数慢慢突破了,一直上涨
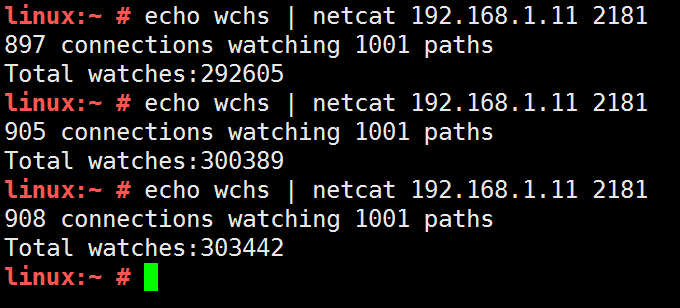
可以发现,很快就超过30w的watch了,还能继续增加



测试过程中,受限于测试机器的内存和测试程序的原因,最大watch数达到了140w,zk能正常工作,读写znode,watch事件均能正常通知。

内存不足了,不能再new 客户端了

修改zk数据,观察watch事件能否通知




可以看到,watch事件均能正常通知。
后面又协调了几台物理机,又重新做了下压测,发现watch数能达到1000w左右,如下图:


通过前面的分析,可以初步得出一个结论,PUMA集群的broker、client、zookeeper都不是集群大规模化的瓶颈(关于这一点,在后续的测试中也得到了证实),那么是不是说明搭建大规模的PUMA集群是可行的,搭建好的大规模集群是可用的呢?现在还不能这么说,毕竟业界没有大规模kafka集群使用的案例,而且即使千节点的PUMA集群搭建成功了,是否可用也需要进行验证,如果集群搭建成功后,其tps很低,或者消息收发时延很高,这显然也是不行的
- 点赞
- 收藏
- 关注作者
评论(0)