语义分割———多尺度特征融合

前言
随着模型深度的不断加大,与输入图像轮廓特征有关的信息会逐层丢失。传统的语义分割模型在“编码”层和“解码”层之间通过直接相连的方式进行特征图和信息的传递。因此在“编码”阶段,特征图各个位置均以相同的感受野获取输入图像的信息。但是对于尺寸、体积大小不同的物体,感受野需求往往是不一样的。
例如,汽车和房屋需要相对较大的感受野获取足够的语义信息完成物体的识别,而人以及其他小物体所需的感受野相对较小。完全一致的单一感受野难以适应真实场景下各类物体大小不同的分割问题,于是多尺度特征融合得到了广泛研究和采用。
多尺度特征融合
多尺度特征融合,它主要解决的问题是对“编码”阶段获取的低级特征进行相关操作获取不同尺度下的特征,然后进行多尺度特征融合使得“编码”可以获取不同感受野大小的特征。多尺度特征融合一般分为两种类型,图像金字塔和特征金字塔模式。图像金字塔模型在传统数据图像处理中得到了广泛的应用。
图像金字塔:在语义分割领域,多支路结构是典型的图像金字塔模型,如ICNet、BiSeNet等。这类模型在不同模块或处理支路中输入不同分辨率大小的图像,通过对不同分辨率大小图像的处理提取出不同感受野下的特征,最终将特征进行融合以补充输出结果中缺失的空间轮廓细节信息。
图像金字塔充分利用了多尺度图像的各类信息,模仿人眼观察不同大小分辨率图像获取信息的方式,较好地补充了多尺度信息。但是,图像金字塔并行的网络结构使得模型的内存消耗较大。
特征金字塔:它解决了图像金字塔内存消耗较大的问题,主要思路是利用不同分辨率大小的特征图进行融合,获取不同感受野大小的特征。带有跳跃连接的U-Shape型网络是典型的利用不同层特征图信息的结构。在语义分割领域得到广泛应用的特征金字塔模型,包括金字塔池化模型(Pyramid Pooling Module,PPN)和空洞空间金字塔池化模块(Atrous Spatial Pyramid Pooling,ASPP)等。
金字塔池化模型最早由H Zhao等人提出的PSPNet使用,如下图所示,“编码器”获取的特征首先利用自适应池化获取不同分辨率的特征图,然后用一系列1*1卷积对获取的特征图处理获取新特征,再用双线性插值将新特征图恢复为初始分辨率,最终将特征值通过堆叠的方式进行特征融合从而完成了对不同感觉野特征的融合。
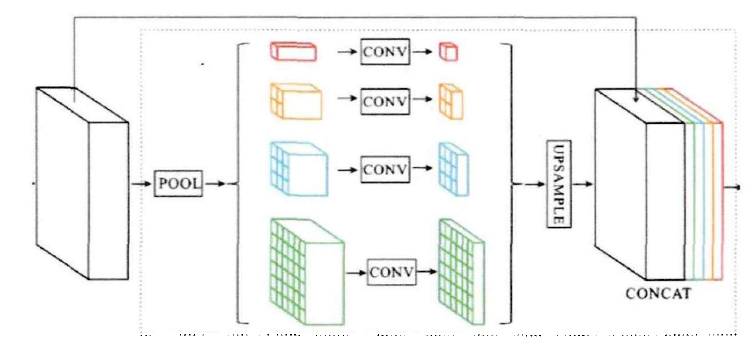
ASPP模型采用相似的方式,利用不同膨胀率的空洞卷积对特征图进行操作获取不同感觉野大小的特征图,然后将各特征图进行通道堆叠。

- 点赞
- 收藏
- 关注作者
评论(0)