ChatGPT 背后包含了哪些技术?

ChatGPT 是由OpenAI开发的一款基于GPT-3(Generative Pre-trained Transformer 3)的人工智能语言模型。这个模型是使用多种编程语言和技术组合编写的。
首先,ChatGPT 使用了 Python 作为主要的编程语言。Python 是一种流行的高级编程语言,特别适合用于数据科学、机器学习和自然语言处理等领域。OpenAI 的研究团队使用 Python 来编写 ChatGPT 的核心算法和模型架构。Python 在数据科学和机器学习方面的优势主要体现在其丰富的库和工具集上,这些工具可以加快开发速度,提高代码质量和效率。
其次,ChatGPT 使用了 TensorFlow 作为深度学习框架。TensorFlow 是由 Google 公司开发的一款流行的深度学习框架,它可以帮助研究人员快速开发和训练深度神经网络。OpenAI 使用 TensorFlow 来搭建 ChatGPT 的神经网络模型,并使用 TensorFlow 的分布式训练功能来加速模型的训练过程。TensorFlow 的优势在于它的灵活性和可扩展性,可以适应不同规模和复杂度的模型。
除此之外,ChatGPT 还使用了其他一些编程语言和技术,包括:
- CUDA:用于在 NVIDIA GPU 上进行并行计算,以加速深度学习模型的训练和推理。
- C++:用于优化模型的计算性能和内存管理,特别是在模型部署和推理时。
- Rust:用于编写高性能的系统级代码,以提高模型的稳定性和安全性。
- JavaScript:用于开发 ChatGPT 的 Web API,使其可以通过网络接口与其他应用程序集成。
综上所述,ChatGPT 是使用多种编程语言和技术组合编写的。Python 是主要的编程语言,用于编写核心算法和模型架构。TensorFlow 是深度学习框架,用于搭建神经网络模型。其他编程语言和技术则用于优化计算性能、提高系统稳定性和安全性,以及扩展 ChatGPT 的应用范围。通过这些技术的组合,ChatGPT 成为了一款高效、可靠、灵活的自然语言处理模型。
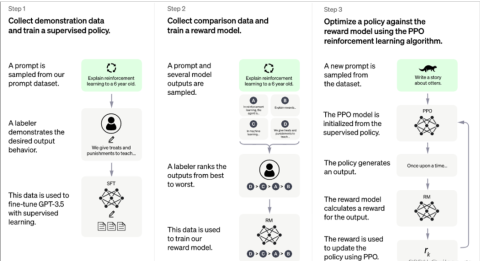
从组成模块上划分:
- Transformer 架构
GPT-3 基于 Transformer 架构,这是一种在自然语言处理(NLP)领域非常流行的神经网络架构。Transformer 由 Vaswani 等人在 2017 年的论文 “Attention is All You Need” 中首次提出。与传统的 RNN 和 LSTM 不同,Transformer 使用自注意力(self-attention)机制,可以并行处理序列中的所有元素,从而在许多 NLP 任务中取得了突破性的性能。
- 自注意力(Self-Attention)
自注意力是 Transformer 的核心组件,用于计算输入序列中元素之间的相关性。给定一组输入向量,自注意力机制会为每个输入向量分配一个权重,以便在生成新的表示时更关注与其相关的其他输入向量。这些权重是通过输入向量之间的点积计算得到的,并通过 softmax 函数将其归一化。
- 编码器与解码器
尽管 GPT-3 仅使用了解码器部分,但许多基于 Transformer 的模型都包含编码器和解码器。编码器负责将输入序列转换为连续的向量表示,而解码器则使用这些表示生成输出序列。在这种情况下,输入和输出序列可以是文本、图像或其他类型的数据。编码器和解码器都包含多层(通常称为“层数”)的自注意力、前馈神经网络和规范化层,以实现高度复杂的模型。
- 预训练与微调
GPT-3 是一个预训练的语言模型,意味着它在大量的文本数据上进行了预先训练,以学习语言的基本结构和模式。一旦预训练完成,GPT-3 可以通过微调针对特定任务进行优化。这种预训练和微调的方法使得 GPT-3 可以在各种 NLP 任务上取得卓越的性能,如文本生成、翻译、摘要等。
- 开发语言
尽管没有具体的信息来证明 ChatGPT 或 GPT-3 是用哪种编程语言编写的,但根据 OpenAI 的其他项目和社区的广泛实践,我们可以推测它可能是用 Python 编写的。Python 是数据科学和机器学习领域最受欢迎的编程语言之一,拥有许多用于构建和训练机器模型的工具库。

- 点赞
- 收藏
- 关注作者
评论(0)