xml 解析技术介绍和解析xml文件

xml 解析技术介绍
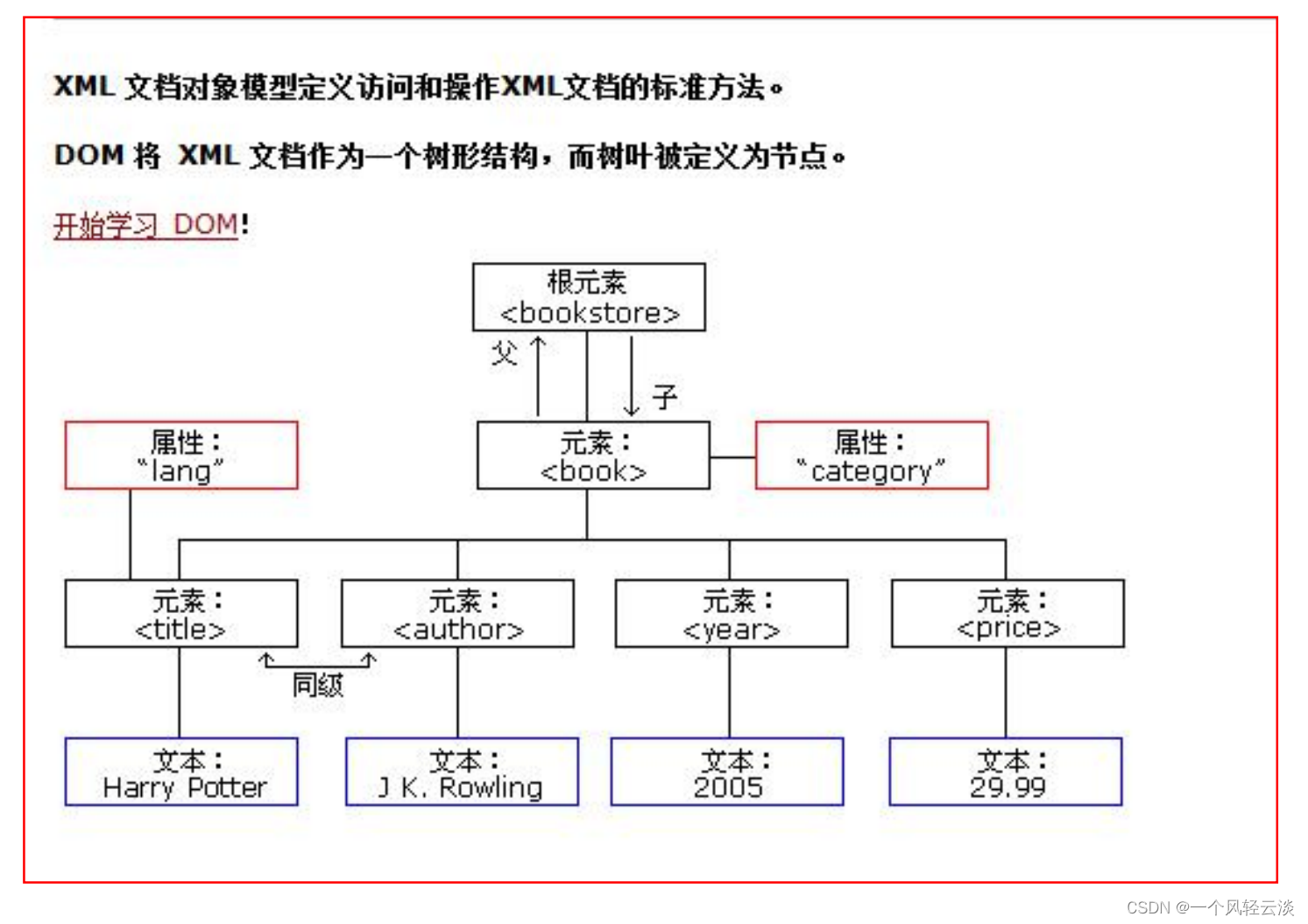
xml 可扩展的标记语言。不管是 html 文件还是 xml 文件它们都是标记型文档,都可以使用 w3c 组织制定的 dom 技术来解析。
![]()
document 对象表示的是整个文档(可以是 html 文档,也可以是 xml 文档)
早期 JDK 为我们提供了两种 xml 解析技术 DOM 和 Sax 简介(已经过时,但我们需要知道这两种技术)dom 解析技术是 W3C 组织制定的,而所有的编程语言都对这个解析技术使用了自己语言的特点进行实现。Java 对 dom 技术解析标记也做了实现。
sun 公司在 JDK5 版本对 dom 解析技术进行升级:SAX( Simple API for XML )SAX 解析,它跟 W3C 制定的解析不太一样。它是以类似事件机制通过回调告诉用户当前正在解析的内容。 它是一行一行的读取 xml 文件进行解析的。不会创建大量的 dom 对象。 所以它在解析 xml 的时候,在内存的使用上。和性能上。都优于 Dom 解析。
第三方的解析:jdom 在 dom 基础上进行了封装 、dom4j 又对 jdom 进行了封装。
pull 主要用在 Android 手机开发,是在跟 sax 非常类似都是事件机制解析 xml 文件。
这个 Dom4j 它是第三方的解析技术。我们需要使用第三方给我们提供好的类库才可以解析 xml 文件。
dom4j 解析技术(重点*****)
由于 dom4j 它不是 sun 公司的技术,而属于第三方公司的技术,我们需要使用 dom4j 就需要到 dom4j 官网下载 dom4j的 jar 包
Dom4j 类库的使用

如何查 Dom4j 的文档

Dom4j 快速入门
lib 目录
src 目录是第三方类库的源码目录:
dom4j 编程步骤:
第一步: 先加载 xml 文件创建 Document 对象
第二步:通过 Document 对象拿到根元素对象
第三步:通过根元素.elelemts(标签名); 可以返回一个集合,这个集合里放着。所有你指定的标签名的元素对象
第四步:找到你想要修改、删除的子元素,进行相应在的操作 第五步,保存到硬盘上
获取 document 对象
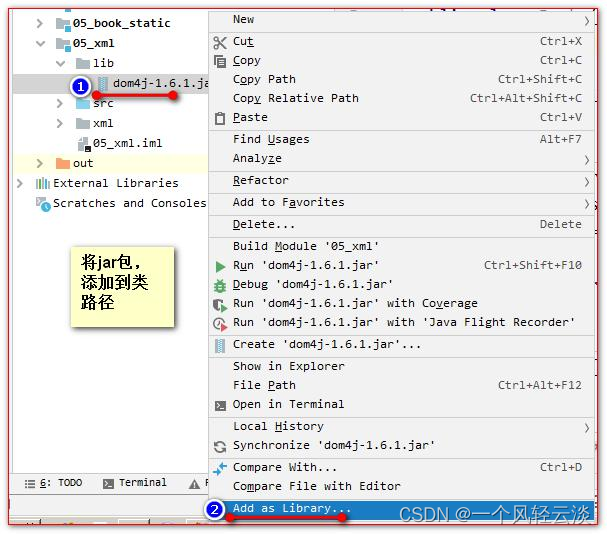
创建一个 lib 目录,并添加 dom4j 的 jar 包。并添加到类路径。
需要解析的 books.xml 文件内容
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book sn="SN12341232">
<name>辟邪剑谱</name>
<price>9.9</price>
<author>班主任</author>
</book>
<book sn="SN12341231">
<name>葵花宝典</name>
<price>99.99</price>
<author>班长</author>
</book>
</books>解析获取 Document 对象的代码
第一步,先创建 SaxReader 对象。这个对象,用于读取 xml 文件,并创建 Document
/*
* dom4j 获取 Documet 对象
*/
@Test
public void getDocument() throws DocumentException {
// 要创建一个 Document 对象,需要我们先创建一个 SAXReader 对象
SAXReader reader = new SAXReader();
// 这个对象用于读取 xml 文件,然后返回一个 Document。
Document document = reader.read("src/books.xml");
// 打印到控制台,看看是否创建成功
System.out.println(document);
}遍历 标签 获取所有标签中的内容(*****重点)
需要分四步操作:
第一步,通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象
第二步,通过 Document 对象。拿到 XML 的根元素对象
第三步,通过根元素对象。获取所有的 book 标签对象
第四步,遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素,再通过 getText() 方法拿到起始标签和结 束标签之间的文本内容
/*
* 读取 xml 文件中的内容
*/
@Test
public void readXML() throws DocumentException {
// 需要分四步操作:
// 第一步,通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象
// 第二步,通过 Document 对象。拿到 XML 的根元素对象
// 第三步,通过根元素对象。获取所有的 book 标签对象
// 第四小,遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素,再通过 getText() 方法拿到起始标签和结束标签之间的文本内容
// 第一步,通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象
SAXReader reader = new SAXReader();
Document document = reader.read("src/books.xml");
// 第二步,通过 Document 对象。拿到 XML 的根元素对象
Element root = document.getRootElement();
// 打印测试
// Element.asXML() 它将当前元素转换成为 String 对象
// System.out.println( root.asXML() );
// 第三步,通过根元素对象。获取所有的 book 标签对象
// Element.elements(标签名)它可以拿到当前元素下的指定的子元素的集合
List<Element> books = root.elements("book");
// 第四小,遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素,
for (Element book : books) {
// 测试
// System.out.println(book.asXML());
// 拿到 book 下面的 name 元素对象
Element nameElement = book.element("name");
// 拿到 book 下面的 price 元素对象
Element priceElement = book.element("price");
// 拿到 book 下面的 author 元素对象
Element authorElement = book.element("author");
// 再通过 getText() 方法拿到起始标签和结束标签之间的文本内容
System.out.println("书名" + nameElement.getText() + " , 价格:"
+ priceElement.getText() + ", 作者:" + authorElement.getText());
}
}

- 点赞
- 收藏
- 关注作者
评论(0)