软件测试|教你使用Python快速绘制酷炫词云图

【摘要】 前言词云图现在似乎成了各个互联网产品年终盘点的标准形式,比如我们的热搜,我们QQ音乐网易云音乐最喜欢的歌手最喜欢的歌曲等等,词云图实在是太契合互联网时代了。那么我们能不能自己也去画一个词云图出来?就用我们的Python来完成这个目标。 环境准备Python绘制词云图有几个常用的库,wordcloud,jieba,matplotlib三个库,环境准备也非常简单,安装这三个库即可.。pip ...
前言
词云图现在似乎成了各个互联网产品年终盘点的标准形式,比如我们的热搜,我们QQ音乐网易云音乐最喜欢的歌手最喜欢的歌曲等等,词云图实在是太契合互联网时代了。那么我们能不能自己也去画一个词云图出来?就用我们的Python来完成这个目标。
环境准备
Python绘制词云图有几个常用的库,wordcloud,jieba,matplotlib三个库,环境准备也非常简单,安装这三个库即可.。
pip install wordcloud jieba matplotlib
wordcloud是python的一个三方库,称为词云也叫做文字云,是根据文本中的词频,对内容进行可视化的汇总。
jieba是优秀的中文分词第三方库,由于中文文本之间每个汉字都是连续书写的,我们需要通过特定的手段来获得其中的每个词组,这种手段叫做分词,jieba库就能很好地帮我们完成这项工作。
好的,环境准备好了,直接开干。
简单词云图
绘制词云图之前,我们需要先准备好我们的文本文件,用于统计频次,可以自己创建文本文档。代码如下:
import matplotlib.pyplot as plt # 在任何绘图之前,我们需要一个figure对象,可以理解成我们需要一张画板才能开始绘图
import jieba # jieba库是中文分词的第三方库(中文文本需要通过分词获得单个的词语)
from wordcloud import WordCloud # 导入wordcloud库
text = open(r'names.txt', "r", encoding="utf-8").read() # 读入txt文本数据,在字符串前面加上字符r或R之后表示原始字符串,字符串中的任意字符都不再进行转义,后一个r表示“只读”
cut_text = jieba.cut(text) # jieba中文分词,生成字符串,默认精确模式,如果不通过分词,无法直接生成正确的中文词云
result = " ".join(cut_text) # 必须给个符号分隔开分词结果来形成字符串,否则不能绘制词云
# join函数的用法:'sep'.join(seq)参数说明:sep:分隔符。可以为空;seq:要连接的元素序列、字符串、元组、字典;即:以sep作为分隔符,将seq所有的元素合并成一个新的字符串
# 生成词云图,这里需要注意的是WordCloud默认不支持中文,所以这里需已下载好的中文字库
# 无自定义背景图:需要指定生成词云图的像素大小,默认背景颜色为黑色,统一文字颜色:mode='RGBA'和colormap='pink'
wc = WordCloud(
# 设置字体,不指定就会出现乱码
background_color='white', # 设置背景色,默认为黑色
width=500, # 设置背景宽
height=350, # 设置背景高
max_font_size=50, # 最大字体
min_font_size=10, # 最小字体
mode='RGBA' # 当参数为“RGBA”并且background_color不为空时,背景为透明
)
wc.generate(result) # 根据分词后的文本产生词云
wc.to_file(r"wordcloud.png") # 保存绘制好的词云图
plt.imshow(wc) # 以图片的形式显示词云
plt.axis("off") # 关闭图像坐标系,即不显示坐标系
plt.show() # plt.imshow()函数负责对图像进行处理,并显示其格式,但是不能显示。其后必须有plt.show()才能显示
代码显示效果如下:
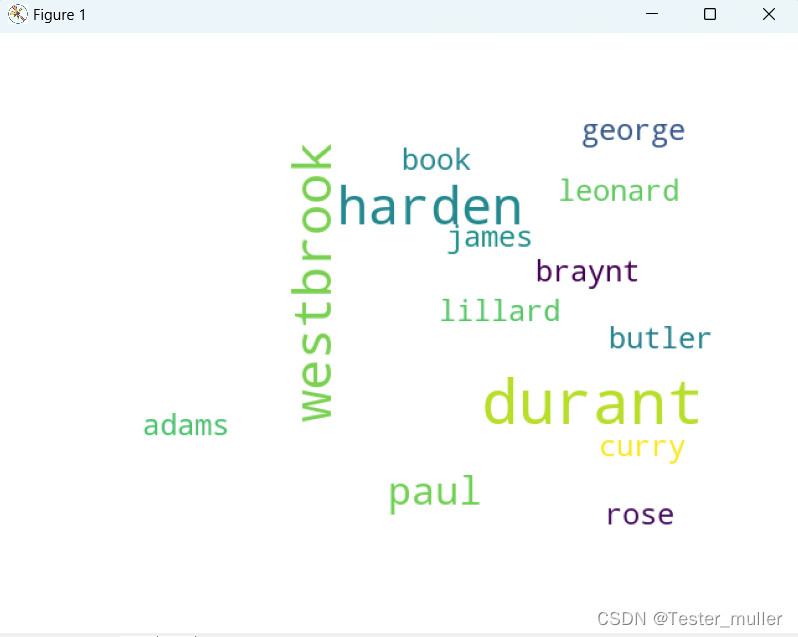
因为我们文件中涉及的词汇不多,所以导致生成的词云图不够密集,但是当词汇较多且部分词汇出现次数较多时,便会生成较为密集的词云图。
定制指定形状的词云图
很多时候,我们想要生成的词云图并不是上面的方方正正的,那样太过传统,词云图要的是酷炫新奇,所以我们也可以先指定一下形状,这样生成的词云图会更加吸引眼球。以下面的需求为例,我们需要绘制《滕王阁序》的词云图,以我最喜欢的动漫人物——柯南为词云图的形状。

import wordcloud
import numpy as np
from PIL import Image # Image模块是在Python PIL图像处理常用的模块
import jieba
pic = Image.open("conan.png") # 打开图片路径,形成轮廓
shape = np.array(pic) # 图像轮廓转换为数组
wc = wordcloud.WordCloud(mask=shape, font_path="simkai.ttf", background_color="white",
max_font_size=100) # mask为图片背景,font_path为字体,若不设置可能乱码
text = open(r'article.txt', "r", encoding='UTF-8').read() # 对中文应该设置编码方式为utf—8,article.txt为滕王阁序的全文
cut_text = jieba.cut(text)
result = " ".join(cut_text)
wc.generate(result)
wc.to_file("cloud.jpg")
生成的词云图如下:

是不是比第一次生成的词云图好看了很多,终于有了些互联网产品年终盘点词云图的形状。
总结
本文主要介绍了词云图的绘制,词云图是一个新鲜的互联网工具,能够帮我们直观的了解互联网的热点事件等等,本文就介绍到这里,后续我们将继续讲解一些有趣的图表绘制。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)