机器学习(五):机器学习算法分类

【摘要】 机器学习算法分类根据数据集组成不同,可以把机器学习算法分为:监督学习无监督学习半监督学习强化学习一、监督学习定义:输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。1、回归问题例如:预测房价,根据样本集拟合出一条连续曲线。2、分类问题例如:根据肿瘤特征判断良性还是恶性,得到的是结果是“良性”或者“恶性”,是离散的。二、无监督...
机器学习算法分类
根据数据集组成不同,可以把机器学习算法分为:
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
一、监督学习
定义:输入数据是由输入特征值和目标值所组成。
函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。
1、回归问题
例如:预测房价,根据样本集拟合出一条连续曲线。
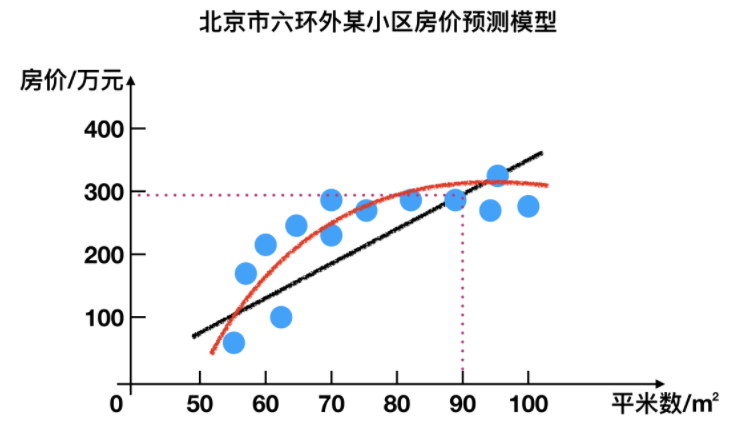
2、分类问题
例如:根据肿瘤特征判断良性还是恶性,得到的是结果是“良性”或者“恶性”,是离散的。

二、无监督学习
定义:输入数据是由输入特征值组成,没有目标值。
- 输入数据没有被标记,也没有确定的结果。样本数据类别未知;
- 需要根据样本间的相似性对样本集进行类别划分。
有监督,无监督算法对比:

三、半监督学习
定义:训练集同时包含有标记样本数据和未标记样本数据。
监督学习训练方式:

半监督学习训练方式:

四、强化学习
定义:实质是make decisions 问题,即自动进行决策,并且可以做连续决策。
举例:
小孩想要走路,但在这之前,他需要先站起来,站起来之后还要保持平衡,接下来还要先迈出一条腿,是左腿还是右腿,迈出一步后还要迈出下一步。
小孩就是 agent,他试图通过采取行动(即行走)来操纵环境(行走的表面),并且从一个状态转变到另一个状态(即他走的每一步),当他完成任务的子任务(即走了几步)时,孩子得到奖励(给巧克力吃),并且当他不能走路时,就不会给巧克力。
主要包含五个元素:agent, action, reward, environment, observation;
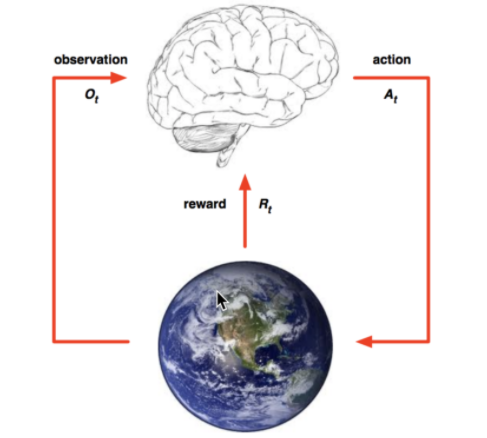
强化学习的目标就是获得最多的累计奖励。
监督学习和强化学习的对比
|
|
监督学习 |
强化学习 |
|---|---|---|
|
反馈映射 |
输出的是之间的关系,可以告诉算法什么样的输入对应着什么样的输出。 |
输出的是给机器的反馈 reward function,即用来判断这个行为是好是坏。 |
|
反馈时间 |
做了比较坏的选择会立刻反馈给算法。 |
结果反馈有延时,有时候可能需要走了很多步以后才知道以前的某一步的选择是好还是坏。 |
|
输入特征 |
输入是独立同分布的。 |
面对的输入总是在变化,每当算法做出一个行为,它影响下一次决策的输入。 |

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)