可变形卷积(Deformable Conv)实战

可变形卷积(Deformable Conv)实战(Paddle版本)
本次教程将对MSRA出品的可变形卷积进行讲解,对DCNv1和DCNv2论文中提出的主要思想进行讲解,并对其代码实现进行讲解。最后,使用一个简单的图像分类任务对DCN进行验证。
一、可变形卷积主要思想讲解
这里我们首先看一下我们正常使用的规整卷积和可变形卷积之间的对比图。如下图所示:
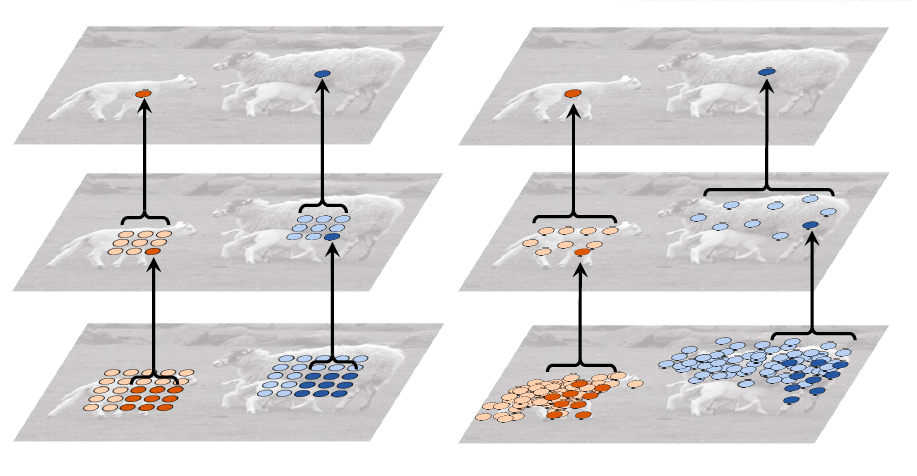
我们可以看到在理想情况下,可变形卷积能够比规整卷积学习到更加有效的图像特征。
现在我们反推一下为什么这种卷积结构会比经典的卷积结构更有效?在论文中,作者给出的回答是:经典卷积神经网络的卷积结构固定,对目标建模不充分。图像不同位置的结构应当是不同的,但是却用相同结构的卷积进行计算;不管当前位置的图像是什么结构,都使用固定比例的池化层降低特征图分辨率。这种做法是不可取的,尤其是对非刚性目标。
接下来,我们思考一下该如何实现这种卷积的形变,我们明确一点,在这里我们不可能真的让卷积核进行形变,那我们该如何实现呢?答案如下所示,通过给卷积的位置加一个偏移值(offset)来实现卷积的“变形”,加上该偏移量的学习之后,可变形卷积核的大小和位置能够根据图像内容进行动态调整,其直观效果就是不同位置的卷积核采样点位置会根据图像内容发生自适应变化,从而适应不同目标物体的几何形变。
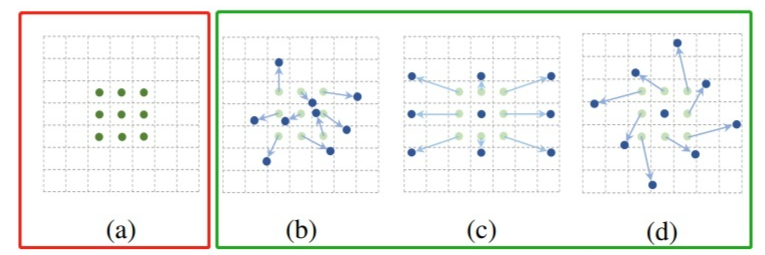
以上是DCNv1的主要思想,在之后DCNv2主要做了两点改进,一是在网络结构中增加了可变形卷积层的使用(Stacking More Deformable Conv Layers),二是在偏移值上又增加了一个权值(Modulated Deformable Modules)。对于DCNv1,作者发现在实际的应用中,其感受野对应位置超出了目标范围,导致特征不受图像内容影响。在DCNv2中,其主要改进点为引入了幅度调制机制,让网络学习到每一个采样点偏移量的同时也学习到这一采样点的幅度(即该特征点对应的权重。)使得网络在具备学习空间形变能力的同时具备区分采样点重要性的能力。(此改进是否为注意力机制?)
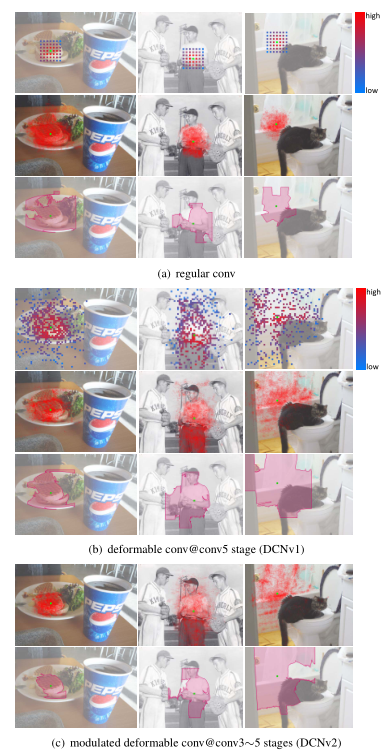
二、对比实验
本小节将通过一个简单的网络进行图像分类任务,分别进行三个实验,其一为规则卷积、其二为DCNv1、其三为DCNv2。
# 导入相关库
import paddle
import paddle.nn.functional as F
from paddle.vision.transforms import ToTensor
from paddle.vision.ops import DeformConv2D
print(paddle.__version__)
2.0.0-rc1
transform = ToTensor()
cifar10_train = paddle.vision.datasets.Cifar10(mode='train',
transform=transform)
cifar10_test = paddle.vision.datasets.Cifar10(mode='test',
transform=transform)
# 构建训练集数据加载器
train_loader = paddle.io.DataLoader(cifar10_train, batch_size=64, shuffle=True)
# 构建测试集数据加载器
test_loader = paddle.io.DataLoader(cifar10_test, batch_size=64, shuffle=True)
2.1 规则卷积
#定义模型
class MyNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(MyNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=32, kernel_size=(3, 3), stride=1, padding = 1)
# self.pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
# self.pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
self.conv4 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 1)
self.flatten = paddle.nn.Flatten()
self.linear1 = paddle.nn.Linear(in_features=1024, out_features=64)
self.linear2 = paddle.nn.Linear(in_features=64, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
# x = self.pool1(x)
# print(x.shape)
x = self.conv2(x)
x = F.relu(x)
# x = self.pool2(x)
# print(x.shape)
x = self.conv3(x)
x = F.relu(x)
# print(x.shape)
x = self.conv4(x)
x = F.relu(x)
# print(x.shape)
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
# 可视化模型
cnn1 = MyNet()
model1 = paddle.Model(cnn1)
model1.summary((64, 3, 32, 32))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[64, 3, 32, 32]] [64, 32, 32, 32] 896
Conv2D-2 [[64, 32, 32, 32]] [64, 64, 15, 15] 18,496
Conv2D-3 [[64, 64, 15, 15]] [64, 64, 7, 7] 36,928
Conv2D-4 [[64, 64, 7, 7]] [64, 64, 4, 4] 36,928
Flatten-1 [[64, 64, 4, 4]] [64, 1024] 0
Linear-1 [[64, 1024]] [64, 64] 65,600
Linear-2 [[64, 64]] [64, 1] 65
===========================================================================
Total params: 158,913
Trainable params: 158,913
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 25.59
Params size (MB): 0.61
Estimated Total Size (MB): 26.95
---------------------------------------------------------------------------
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/distributed/parallel.py:119: UserWarning: Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything.
"Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything."
{'total_params': 158913, 'trainable_params': 158913}
from paddle.metric import Accuracy
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model1.parameters())
# 配置模型
model1.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
# 训练模型
model1.fit(train_data=train_loader,
eval_data=test_loader,
epochs=2,
verbose=1
)
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/2
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
step 782/782 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 39ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 31ms/step
Eval samples: 10000
Epoch 2/2
step 782/782 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 34ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 32ms/step
Eval samples: 10000
2.2 DCNv1
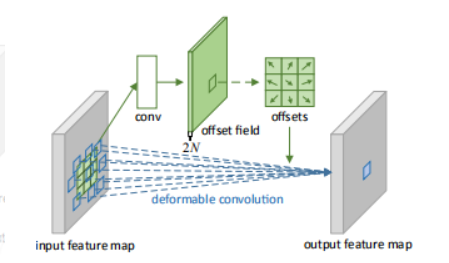
相对于规则卷积,DCNv1在卷积网络中添加了一个偏移值,其过程示意如下图所示:
class Dcn1(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(Dcn1, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=32, kernel_size=(3, 3), stride=1, padding = 1)
# self.pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
# self.pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
self.offsets = paddle.nn.Conv2D(64, 18, kernel_size=3, stride=2, padding=1)
self.conv4 = DeformConv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 1)
# self.conv4 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 1)
self.flatten = paddle.nn.Flatten()
self.linear1 = paddle.nn.Linear(in_features=1024, out_features=64)
self.linear2 = paddle.nn.Linear(in_features=64, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
# x = self.pool1(x)
# print(x.shape)
x = self.conv2(x)
x = F.relu(x)
# x = self.pool2(x)
# print(x.shape)
x = self.conv3(x)
x = F.relu(x)
# print(x.shape)
offsets = self.offsets(x)
# print(offsets.shape)
x = self.conv4(x, offsets)
x = F.relu(x)
# print(x.shape)
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
# 可视化模型
cnn2 = Dcn1()
model2 = paddle.Model(cnn2)
model2.summary((64, 3, 32, 32))
---------------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
=======================================================================================
Conv2D-9 [[64, 3, 32, 32]] [64, 32, 32, 32] 896
Conv2D-10 [[64, 32, 32, 32]] [64, 64, 15, 15] 18,496
Conv2D-11 [[64, 64, 15, 15]] [64, 64, 7, 7] 36,928
Conv2D-12 [[64, 64, 7, 7]] [64, 18, 4, 4] 10,386
DeformConv2D-2 [[64, 64, 7, 7], [64, 18, 4, 4]] [64, 64, 4, 4] 36,928
Flatten-1975 [[64, 64, 4, 4]] [64, 1024] 0
Linear-5 [[64, 1024]] [64, 64] 65,600
Linear-6 [[64, 64]] [64, 1] 65
=======================================================================================
Total params: 169,299
Trainable params: 169,299
Non-trainable params: 0
---------------------------------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 25.73
Params size (MB): 0.65
Estimated Total Size (MB): 27.13
---------------------------------------------------------------------------------------
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/distributed/parallel.py:119: UserWarning: Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything.
"Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything."
{'total_params': 169299, 'trainable_params': 169299}
from paddle.metric import Accuracy
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model2.parameters())
# 配置模型
model2.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
# 训练模型
model2.fit(train_data=train_loader,
eval_data=test_loader,
epochs=2,
verbose=1
)
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/2
step 782/782 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 51ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 33ms/step
Eval samples: 10000
Epoch 2/2
step 782/782 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 39ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 44ms/step
Eval samples: 10000
2.3 DCNv2
大家可以看到,对比DCNv1,DCNv2增加了一个mask参数,此参数用来调整对于特征的权重,即对特征的关注程度。
class dcn2(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(dcn2, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=32, kernel_size=(3, 3), stride=1, padding = 1)
# self.pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
# self.pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
self.offsets = paddle.nn.Conv2D(64, 18, kernel_size=3, stride=2, padding=1)
self.mask = paddle.nn.Conv2D(64, 9, kernel_size=3, stride=2, padding=1)
self.conv4 = DeformConv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 1)
# self.conv4 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 1)
self.flatten = paddle.nn.Flatten()
self.linear1 = paddle.nn.Linear(in_features=1024, out_features=64)
self.linear2 = paddle.nn.Linear(in_features=64, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
# x = self.pool1(x)
# print(x.shape)
x = self.conv2(x)
x = F.relu(x)
# x = self.pool2(x)
# print(x.shape)
x = self.conv3(x)
x = F.relu(x)
# print(x.shape)
offsets = self.offsets(x)
masks = self.mask(x)
# print(offsets.shape)
# print(masks.shape)
x = self.conv4(x, offsets, masks)
x = F.relu(x)
# print(x.shape)
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
cnn3 = dcn2()
model3 = paddle.Model(cnn3)
model3.summary((64, 3, 32, 32))
------------------------------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
======================================================================================================
Conv2D-13 [[64, 3, 32, 32]] [64, 32, 32, 32] 896
Conv2D-14 [[64, 32, 32, 32]] [64, 64, 15, 15] 18,496
Conv2D-15 [[64, 64, 15, 15]] [64, 64, 7, 7] 36,928
Conv2D-16 [[64, 64, 7, 7]] [64, 18, 4, 4] 10,386
Conv2D-17 [[64, 64, 7, 7]] [64, 9, 4, 4] 5,193
DeformConv2D-3 [[64, 64, 7, 7], [64, 18, 4, 4], [64, 9, 4, 4]] [64, 64, 4, 4] 36,928
Flatten-3855 [[64, 64, 4, 4]] [64, 1024] 0
Linear-7 [[64, 1024]] [64, 64] 65,600
Linear-8 [[64, 64]] [64, 1] 65
======================================================================================================
Total params: 174,492
Trainable params: 174,492
Non-trainable params: 0
------------------------------------------------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 25.81
Params size (MB): 0.67
Estimated Total Size (MB): 27.22
------------------------------------------------------------------------------------------------------
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/distributed/parallel.py:119: UserWarning: Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything.
"Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything."
{'total_params': 174492, 'trainable_params': 174492}
from paddle.metric import Accuracy
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model3.parameters())
# 配置模型
model3.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
# 训练模型
model3.fit(train_data=train_loader,
eval_data=test_loader,
epochs=2,
verbose=1
meters())
# 配置模型
model3.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
# 训练模型
model3.fit(train_data=train_loader,
eval_data=test_loader,
epochs=2,
verbose=1
)
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/2
step 782/782 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 41ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 33ms/step
Eval samples: 10000
Epoch 2/2
step 782/782 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 43ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.0000e+00 - acc: 0.1000 - 33ms/step
Eval samples: 10000
三、总结
本次项目主要对可变形卷积的两个版本进行了介绍,并对规则卷积、DCNv1、DCNv2进行了对比实验实验只迭代了两次,故并没有体现出DCN的效果来,大家可以增加迭代次数进行测试。在DCN的论文中,做实验的backbone网络是resnet50,这里只用了一个很简单的浅层网络,并且也没有使用BN等操作,可能会在未来出一个resnet的测试版本,但不保证一定更新哈。。万一没更新大家也别催我。。另外大家可以看一下DCN的论文,加油!

- 点赞
- 收藏
- 关注作者
评论(0)