CSP网络结构实战

CSP网络结构实战(Paddle版本)
0 理论介绍
Cross Stage Partial Network(CSPNet)就是从网络结构设计的角度来解决以往工作在推理过程中需要很大计算量的问题。作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。CSPNet通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。CSPNet是一种处理的思想,可以和ResNet、ResNeXt和DenseNet结合。
其核心思想就是将输入切分。其目的在于提出一种新的特征融合方式(降低计算量的同时保证精度)。
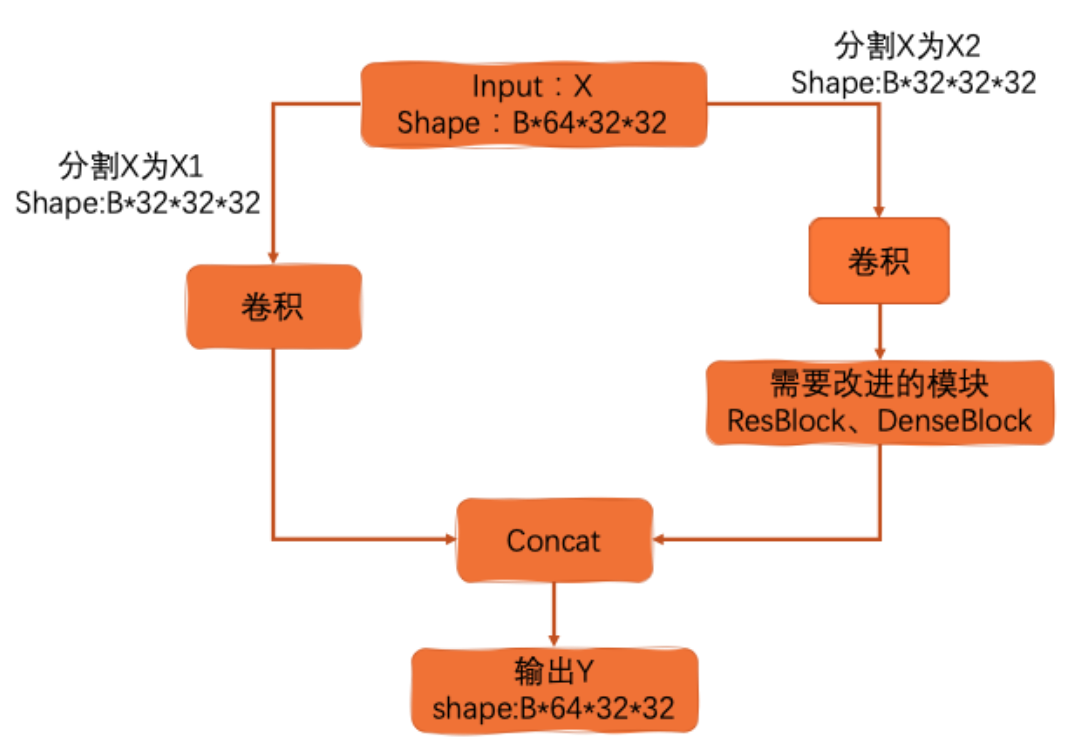
- CSPNet提出主要解决了以下三个问题:
- 增强CNN的学习能力,能够在轻量化的同时保持准确性。
- 降低计算瓶颈。
- 降低内存成本
网络结构对比

1 实验
本次教程通过图像分类任务对CSP的有效性进行验证。使用的数据集为Paddle2.0中的Flowers 数据集。使用darknet53作为baseline。使用CSP结构作为提升点,完成实验。
核心代码讲解
- 知识点
在CSPDarknet中,其主要结构未被更改,只是在每个层级中添加了CSP结构,在该教程中,复现代码主要参考了飞桨官方复现代码,以及咩酱大佬的复现代码。CSP结构如理论介绍中的结构图所示,其需要三层卷积,左侧卷积、右侧卷积以及一层Neck。其核心代码如下所示,在Darknet的每个层级中都需要应用相同三层卷积。
class BasicBlock(nn.Layer):
def __init__(self, input_channels, output_channels, name=None):
super(BasicBlock, self).__init__()
self._conv1 = ConvBNLayer(
input_channels, output_channels, 1, 1, 0, name=name + ".0")
self._conv2 = ConvBNLayer(
output_channels, output_channels * 2, 3, 1, 1, name=name + ".1")
def forward(self, inputs):
x = self._conv1(inputs)
x = self._conv2(x)
return paddle.add(x=inputs, y=x)
# stage 0
self.stage1_conv1 = ConvBNLayer(
32, 64, 3, 2, 1, name="stage.0.csp0")
self.stage1_conv2 = ConvBNLayer(
64, 64, 1, 1, 1, name="stage.0.csp1")
self._basic_block_01 = BasicBlock(64, 32, name="stage.0.0")
self.stage1_conv4 = ConvBNLayer(
64, 64, 1, 1, 0, name="stage.0.csp3")
self._downsample_0 = ConvBNLayer(
128, 64, 1, 1, 1, name="stage.0.downsample")
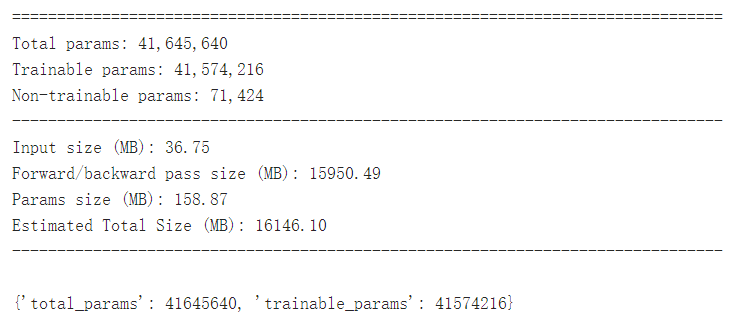
模型可视化
通过模型可视化,大家可以发现,在网络结构中加入了CSP结构之后,网络模型的参数量从41645640下降到了19047240,模型的参数量大大下降。但是由于我们在网络结构中每个stage中都增加了四层卷积,因此,模型的大小也增加了。
import paddle
from work.darknet53 import CSP_DarkNet53
cnn2 = CSP_DarkNet53(class_dim=10)
model2 = paddle.Model(cnn2)
# 模型可视化
# model2.summary((64, 3, 224, 224))

数据读取与预处理
import paddle
import paddle.nn.functional as F
from paddle.vision.datasets import Cifar10
import paddle.vision.transforms as T
# 该数据集标签值从1开始,但是正常从0开始,故对标签值进行进一步处理
class FlowerDataset(Cifar10):
def __init__(self, mode, transform):
super(FlowerDataset, self).__init__(mode=mode, transform=transform)
def __getitem__(self, index):
image, label = super(FlowerDataset, self).__getitem__(index)
return image, label
transform = T.Compose([
T.Resize([224,224]),
T.Transpose(),
T.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
flowers_train =FlowerDataset(mode='train', transform=transform)
flowers_valid = FlowerDataset(mode='test', transform=transform)
# 图像预处理
# transform = T.Compose([
# T.Resize([224, 224]),
# T.ToTensor(),
# ])
# 构建训练集数据加载器
train_loader = paddle.io.DataLoader(flowers_train, batch_size=64, shuffle=True)
# 构建测试集数据加载器
valid_loader = paddle.io.DataLoader(flowers_valid, batch_size=64, shuffle=True)
Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz
Begin to download
Download finished
模型配置
import paddle.nn as nn
model2.prepare(optimizer=paddle.optimizer.Adam(parameters=model2.parameters()),
loss=nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
模型训练与验证
model2.fit(train_loader,
valid_loader,
epochs=5,
verbose=1,
)
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/5
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
step 782/782 [==============================] - loss: 1.0268 - acc: 0.4020 - 355ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 1.5527 - acc: 0.4445 - 187ms/step
Eval samples: 10000
Epoch 2/5
step 782/782 [==============================] - loss: 1.2340 - acc: 0.6099 - 354ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 40/157 [======>.......................] - loss: 0.6905 - acc: 0.6207 - ETA: 22s - 190ms/st
对比实验
import paddle
from work.cspdarknet53 import DarkNet53
cnn3 = DarkNet53(class_dim=10)
model3 = paddle.Model(cnn3)
# 模型可视化
# model3.summary((64, 3, 224, 224))
import paddle.nn as nn
model3.prepare(optimizer=paddle.optimizer.Adam(parameters=model3.parameters()),
loss=nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
model3.fit(train_loader,
valid_loader,
epochs=5,
verbose=1,
ain_loader,
valid_loader,
epochs=5,
verbose=1,
)
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/5
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
step 782/782 [==============================] - loss: 1.4409 - acc: 0.3489 - 233ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 1.5534 - acc: 0.4902 - 169ms/step
Eval samples: 10000
Epoch 2/5
step 782/782 [==============================] - loss: 0.9414 - acc: 0.5933 - 227ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 1.1782 - acc: 0.6465 - 165ms/step
Eval samples: 10000
Epoch 3/5
step 782/782 [==============================] - loss: 1.2450 - acc: 0.7077 - 228ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.9096 - acc: 0.6902 - 181ms/step
Eval samples: 10000
Epoch 4/5
step 782/782 [==============================] - loss: 0.5926 - acc: 0.7720 - 228ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.6070 - acc: 0.7727 - 165ms/step
Eval samples: 10000
Epoch 5/5
step 782/782 [==============================] - loss: 0.1841 - acc: 0.8134 - 226ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.3209 - acc: 0.8045 - 167ms/step
Eval samples: 10000
总结
本次教程针对CSP结构进行了介绍,并通过cifar10数据集进行了对比实验。和之前的一样,由于本人比较懒,故只对模型做了5次迭代,大家感兴趣的可以针对不同的数据集进行实验,也可将此思想应用于其他网络结构中,如ResNet等。BTW,通过CSPNet的论文以及YOLOv4的论文我们可以知道CSP结构是能够Work的。

- 点赞
- 收藏
- 关注作者
评论(0)