2022脑机接口算法挑战赛:脑纹识别比赛基线方案分享

2022脑机接口算法挑战赛:脑纹识别比赛基线
1、背景介绍
在当前的数字信息社会中,个人身份验证技术是许多个人和企业安全系统中必不可少的工具。生物特征识别是一种个人身份验证技术,使用生物测量,包括物理、生理或行为特征。有别于传统的指纹,声纹,脸部识别等身份识别方式,脑纹识别技术在不可窃取、不可伪造、不易受损、必须活体检测等方面具有独特的优势,能为身份识别提供更安全的生物识别方法,被称为最安全的下一代密码。
然而,目前脑纹识别技术的发展仍处于探索阶段,存在数据样本量小、测试时段单一、记录范式单一等一系列局限性。同时,脑纹识别系统的准确性、稳定性和通用性受到挑战。同时,没有公开的基于脑电图的生物特征竞争。缺乏统一的测试基准和平台阻碍了这一领域的发展。为此,我们收集了M3CV(一个用于研究EEG共性和个性问题的多被试、多时间段和多任务的数据库)数据集,以启动基于脑电的脑纹识别竞争。
PS:以上背景介绍转载自2022脑机接口算法挑战赛:脑纹识别
2、数据可视化

人脑产生的特定脑电波波形,被称为“脑纹”,不同个体在观看特定图片时,大脑会产生有针对性的脑电波反应,这种反应是独一无二的,每个人都不尽相同。记录这些个人特有的脑电波信号,可以构建“脑纹”比对数据库。当需要进行身份认证时,只要再次浏览特定图片,就可以通过采集的“脑纹”信息与数据库进行比对,快速得出待识别个体的身份信息,准确率高达100%。
3、Baseline搭建
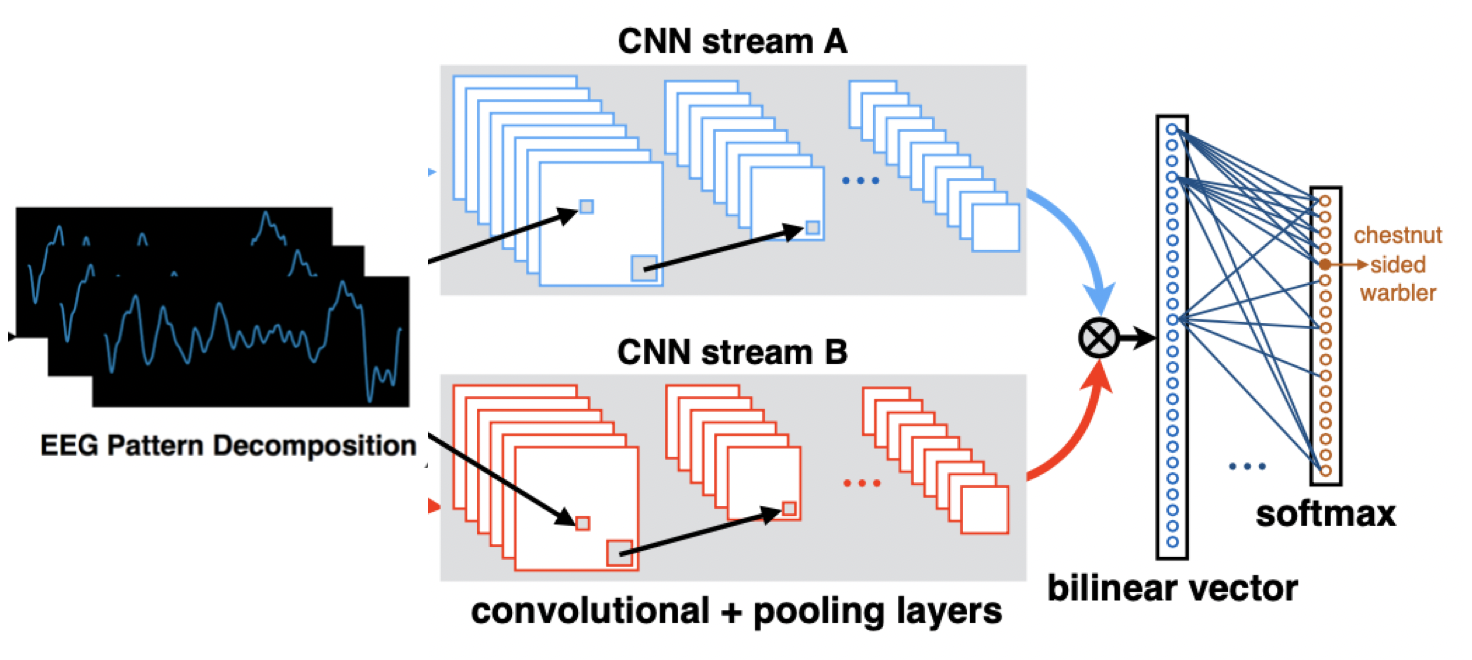
在Baseline中,提出了一种双分支网络,首先將脑纹信号进行离散小波变换,将脑纹信号拆解为两个函数,分别入对应的网络通路,网络整体设计思想参考了双线性卷积神经网络的结构。对于脑纹识别问题采取了分而治之的思想。网络整体结构如上图所示。
3.1 离散小波变换
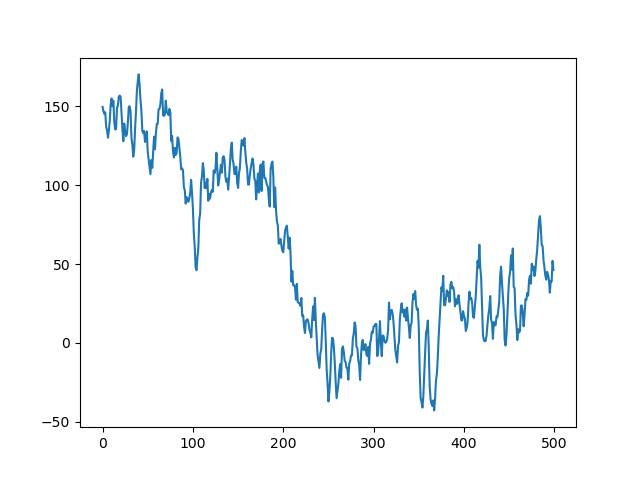
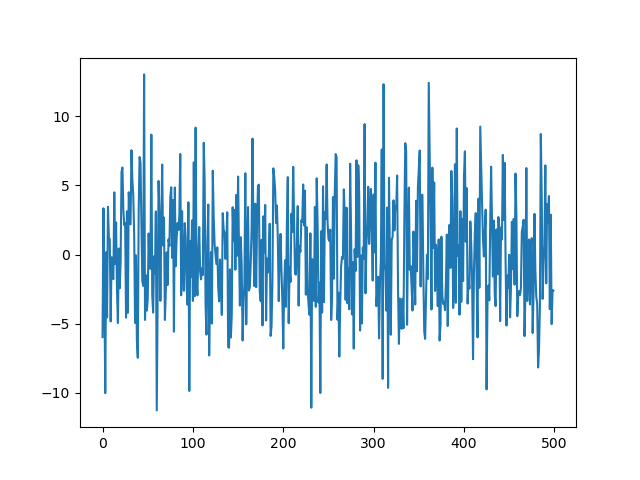
如上图所示,脑纹信号经过离散小波变换之后可以拆分为两组不同的函数。
小波分解的意义就在于能够在不同尺度上对信号进行分解,而且对不同尺度的选择可以根据不同的目标来确定。对于许多信号,低频成分相当重要,它常常蕴含着信号的特征,而高频成分则给出信号的细节或差别。人的话音如果去掉高频成分,听起来与以前可能不同,但仍能知道所说的内容;如果去掉足够的低频成分,则听到的是一些没有意义的声音。在小波分析中经常用到近似与细节。近似表示信号的高尺度,即低频信息;细节表示信号的高尺度,即高频信息。因此,原始信号通过两个相互滤波器产生两个信号。
参考资料:离散小波变换(DWT)
3.2 数据读取
import scipy.io as scio
from sklearn.utils import shuffle
import os
import pandas as pd
import numpy as np
from PIL import Image
import paddle
import paddle.nn as nn
from paddle.io import Dataset
import paddle.vision.transforms as T
import paddle.nn.functional as F
from paddle.metric import Accuracy
from sklearn.preprocessing import LabelEncoder
from paddle.optimizer.lr import LinearWarmup
from paddle.optimizer.lr import CosineAnnealingDecay
import warnings
warnings.filterwarnings("ignore")
# 读取数据
train_images = pd.read_csv('data/data151025/Enrollment_Info.csv')
val_images = pd.read_csv('data/data151025/Calibration_Info.csv')
train_images = shuffle(train_images, random_state=0)
val_images = shuffle(val_images)
# 划分训练集和校验集
train_image_list = train_images
val_image_list = val_images
df = train_image_list
train_image_path_list = train_image_list['EpochID'].values
train_label_list = train_image_list['SubjectID'].values
val_image_path_list = val_image_list['EpochID'].values
val_label_list = val_image_list['SubjectID'].values
# 定义数据读取类
class MyDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, train_img_list, val_img_list,train_label_list,val_label_list, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
self.img = []
self.label = []
# 借助pandas读csv的库
self.train_images = train_img_list
self.test_images = val_img_list
self.train_label = train_label_list
self.test_label = val_label_list
if mode == 'train':
# 读train_images的数据
for img,la in zip(self.train_images, self.train_label):
self.img.append('data/data151025/train/'+img+'.mat')
self.label.append(paddle.to_tensor(int(la[4:]) - 1, dtype='int64'))
else:
# 读test_images的数据
for img,la in zip(self.test_images, self.test_label):
self.img.append('data/data151025/val/'+img+'.mat')
self.label.append(paddle.to_tensor(int(la[4:]) - 1, dtype='int64'))
def load_eeg(self, eeg_path):
data = scio.loadmat(eeg_path)
return data['epoch_data']
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
eeg_data = self.load_eeg(self.img[index])
eeg_label = self.label[index]
# label = paddle.to_tensor(label)
return eeg_data,eeg_label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.img)
#train_loader
train_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='train')
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=256, shuffle=True, num_workers=0)
#val_loader
val_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='test')
val_loader = paddle.io.DataLoader(val_dataset, places=paddle.CPUPlace(), batch_size=256, shuffle=True, num_workers=0)
import math
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import pywt
from paddle.nn import Linear, Dropout, ReLU
from paddle.nn import Conv1D, MaxPool1D
from paddle.nn.initializer import Uniform
from paddle.fluid.param_attr import ParamAttr
from paddle.utils.download import get_weights_path_from_url
class MyNet_dwt(nn.Layer):
def __init__(self, num_classes=1000):
super(MyNet_dwt, self).__init__()
self.num_classes = num_classes
self._conv1 = Conv1D(
65,
128,
3,
stride=2,
padding=1,
)
self._conv2_1 = Conv1D(
128,
256,
3,
stride=2,
padding=1,
)
self._conv3_1 = Conv1D(
256,
512,
3,
stride=2,
padding=1,
)
self._conv4_1 = Conv1D(
512,
256,
3,
stride=2,
padding=1,
)
self._conv2_2 = Conv1D(
128,
256,
3,
stride=2,
padding=1,
)
self._conv3_2 = Conv1D(
256,
512,
3,
stride=2,
padding=1,
)
self._conv4_2 = Conv1D(
512,
256,
3,
stride=2,
padding=1,
)
self._fc8 = Linear(
in_features=16384,
out_features=num_classes,
)
def forward(self, inputs):
x = self._conv1(inputs)
x = paddle.to_tensor(pywt.dwt(x.numpy(), 'haar'), dtype='float32')
x1,x2 = x.split(2)
x1 = x1.squeeze(axis=0)
x2 = x2.squeeze(axis=0)
x1 = self._conv2_1(x1)
x1 = self._conv3_1(x1)
x1 = F.relu(x1)
x1 = self._conv4_1(x1)
x1 = F.relu(x1)
x2 = self._conv2_2(x2)
x2 = self._conv3_2(x2)
x2 = F.relu(x2)
x2 = self._conv4_2(x2)
x2 = F.relu(x2)
x = paddle.concat(x = [x1,x2], axis=2)
x = paddle.flatten(x, start_axis=1, stop_axis=-1)
x = self._fc8(x)
return x
model_res = MyNet_dwt(num_classes=95)
paddle.summary(model_res,(512,65,1000))
# 模型封装
model = paddle.Model(model_res)
# 定义优化器
class Cosine(CosineAnnealingDecay):
"""
Cosine learning rate decay
lr = 0.05 * (math.cos(epoch * (math.pi / epochs)) + 1)
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
epochs(int): total training epochs
"""
def __init__(self, lr, step_each_epoch, epochs, **kwargs):
super(Cosine, self).__init__(
learning_rate=lr,
T_max=step_each_epoch * epochs, )
self.update_specified = False
class CosineWarmup(LinearWarmup):
"""
Cosine learning rate decay with warmup
[0, warmup_epoch): linear warmup
[warmup_epoch, epochs): cosine decay
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
epochs(int): total training epochs
warmup_epoch(int): epoch num of warmup
"""
def __init__(self, lr, step_each_epoch, epochs, warmup_epoch=5, **kwargs):
assert epochs > warmup_epoch, "total epoch({}) should be larger than warmup_epoch({}) in CosineWarmup.".format(
epochs, warmup_epoch)
warmup_step = warmup_epoch * step_each_epoch
start_lr = 0.0
end_lr = lr
lr_sch = Cosine(lr, step_each_epoch, epochs - warmup_epoch)
super(CosineWarmup, self).__init__(
learning_rate=lr_sch,
warmup_steps=warmup_step,
start_lr=start_lr,
end_lr=end_lr)
self.update_specified = False
scheduler = CosineWarmup(
lr=0.00125, step_each_epoch=226, epochs=24, warmup_steps=20, start_lr=0, end_lr=0.00125, verbose=True)
optim = paddle.optimizer.Adam(learning_rate=scheduler, parameters=model.parameters())
# 配置模型
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
callback = paddle.callbacks.VisualDL(log_dir='visualdl_log_dir_alexdwt')
# 模型训练与评估
model.fit(train_loader,
val_loader,
log_freq=1,
epochs=24,
callbacks=callback,
verbose=1,
)
model.save('Hapi_MyCNN_dwt', True) # save
# 模型预测并生成提交文件
import os, time
import matplotlib.pyplot as plt
import paddle
from PIL import Image
import numpy as np
import pandas as pd
import scipy.io as scio
use_gpu = True
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
param_state_dict = paddle.load( "Hapi_MyCNN_dwt.pdparams")
model_res.set_dict(param_state_dict)
model_res.eval() #训练模式
test_image = pd.read_csv('data/data151025/Testing_Info.csv')
test_image_path_list = test_image['EpochID'].values
eeg_list = list()
labeled_img_list = []
for img in test_image_path_list:
eeg_list.append('data/data151025/test/'+img+'.mat')
labeled_img_list.append(img)
def load_eeg(eeg_path):
# 读取数据
data = scio.loadmat(eeg_path)
return data['epoch_data']
pre_list = []
for i in range(len(eeg_list)):
data = load_eeg(eeg_path=eeg_list[i])
dy_x_data = np.array(data).astype('float32')
dy_x_data = dy_x_data[np.newaxis,:, :]
eeg = paddle.to_tensor(dy_x_data)
out = model_res(eeg)
res = paddle.nn.functional.softmax(out)[0] # 若模型中已经包含softmax则不用此行代码。
lab = np.argmax(out.numpy()) #argmax():返回最大数的索引
pre_list.append(int(lab)+1)
img_test = pd.DataFrame(labeled_img_list)
img_pre = pd.DataFrame(labeled_img_list)
img_test = img_test.rename(columns = {0:"EpochID"})
img_pre['SubjectID'] = pre_list
pre_info = img_pre['SubjectID'].values
test_info = test_image['SubjectID'].values
result_cnn = list()
for i,j in zip(test_info, pre_info):
if i == 'None':
result_cnn.append(j)
elif int(i[4:])==j :
print(i[4:])
result_cnn.append(int(1))
else:
result_cnn.append(int(0))
img_test['Prediction'] = result_cnn
img_test.to_csv('result_dwt.csv', index=False)
总结
在本项目中通过提出的网络结构,完成了模型训练、结果提交全流程,包括数据准备、模型训练及保存和预测步骤,并完成了预测结果提交。对于模型的调优,大家可以从以下几个方面考虑:
1、对数据集进行预处理,使用Label Smooth对标签进行处理
2、模型的选择,增加网络深度,添加残差结构等
3、模型的超参数,如学习率、batch_size等参数
4、模型训练方式,包括优化器的选择、WarmUp方式选择
如果项目中有任何问题,欢迎在评论区留言交流,共同进步!

- 点赞
- 收藏
- 关注作者
评论(0)