基于R的Bilibili视频数据建模及分析——预处理篇

【摘要】 基于R的Bilibili视频数据建模及分析——预处理篇
基于R的Bilibili视频数据建模及分析——预处理篇
0、写在前面
实验环境
- Python版本:
Python3.9 - Pycharm版本:
Pycharm2021.1.3 - R版本:
R-4.2.0 - RStudio版本:
RStudio-2021.09.2-382
该实验一共使用4个数据集,但文章讲述只涉及到一个数据集,并且对于每个数据集的分析,数据大小在110条左右
1、项目介绍
1.1 项目背景
Bilibili是国内比较热门的视频网站,本次实验是通过对Bilibili四个不同专区视频数据进行R使用的统计分析、聚类分析以及建模分析。
1.2 数据来源
- 数据来源于和鲸社区
https://www.heywhale.com/mw/dataset/62a45d284619d87b3b2b9147/file
数据字段描述说明
- title:视频的标题
- duration:视频时长
- publisher:视频作者
- descriptions:视频描述信息
- pub_time:视频发布时间
- view:视频播放量
- comments:视频评论数
- praise:视频点赞量
- coins:视频投币数
- favors:视频收藏数
- forwarding:视频转发量
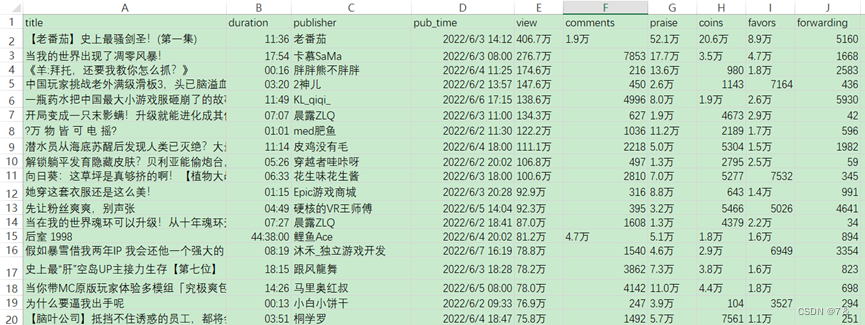
1.3 数据集展示
表单机游戏——游戏区:
2、数据预处理
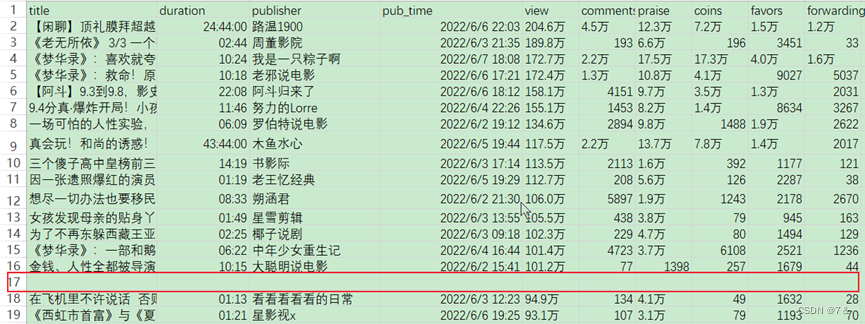
2.1 删除空数据
整行数据为空,直接删除
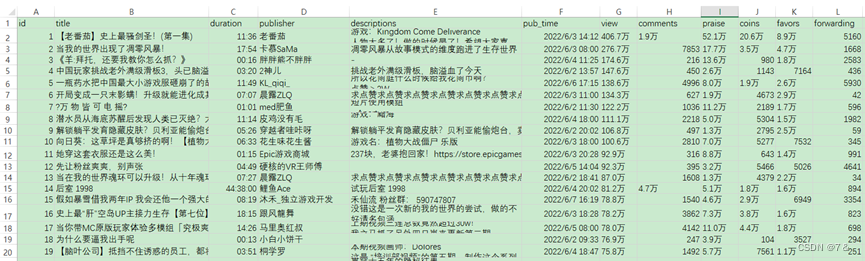
2.2 增加id字段
在Excel每张表的首列添加id字段,
预处理后数据展示:
2.3 处理数值字段
对于
view,comments,praise,coins,favors,forwarding这些数值型字段,原始数据中,1万以上的数值是以xxx.xx万的形式展示的,为方便后续统计,此处将这些类型的字段值转换为常规数字格式。
此处的预处理操作使用Python来处理,代码如下
import pandas as pd
data1 = pd.read_csv('data/videos1.csv', encoding='utf8')
print(data1.shape)
print('---------------------------------------')
# TODO 处理数值字段(view,comments,praise,coins,favors,forwarding)
import pandas as pd
import operator
data1 = pd.read_csv('data/videos1.csv', encoding='utf8')
print(data1.head(3))
print('-------------------------------------------------------')
# # TODO id,title,duration,publisher,pub_time,view,comments,praise,coins,favors,forwarding
def operateVideos1() :
for i in range(0, len(data1)):
# if i == 0 :
# print(data1.iloc[i])
# print(data1.iloc[i][5])
id = data1.iloc[i][0]
view = data1.iloc[i][5]
comments = data1.iloc[i][6]
praise = data1.iloc[i][7]
coins = data1.iloc[i][8]
favors = data1.iloc[i][9]
forwarding = data1.iloc[i][10]
if operator.contains(view, '万'):
num = int(float(view[0: len(view) - 1]) * 10000)
data1._set_value(i, "view", num)
if operator.contains(comments, '万'):
num = int(float(comments[0: len(comments) - 1]) * 10000)
data1._set_value(i, "comments", num)
if operator.contains(praise, '万'):
num = int(float(praise[0: len(praise) - 1]) * 10000)
data1._set_value(i, "praise", num)
if operator.contains(coins, '万'):
num = int(float(coins[0: len(coins) - 1]) * 10000)
data1._set_value(i, "coins", num)
if operator.contains(favors, '万'):
num = int(float(favors[0: len(favors) - 1]) * 10000)
data1._set_value(i, "favors", num)
if operator.contains(forwarding, '万'):
num = int(float(forwarding[0: len(forwarding) - 1]) * 10000)
data1._set_value(i, "forwarding", num)
data1.to_csv('out/v1.csv', index=False)
operateVideos1()
预处理之后的部分数据展示:
数据集1:

3、参考资料
- 多元统计分析及R使用(第五版)
结束!

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)