软件测试|Selenium常见api

【摘要】 Selenium常用 API WebDriver 常用API 打开浏览器用法:driver.get()driver = webdriver.Chrome()# 打开浏览器driver.get("https://www.baidu.com/") 设置浏览器最大化用法:driver.maximize_window()driver = webdriver.Chrome()# 打开浏览器drive...
Selenium常用 API
WebDriver 常用API
- 用法:
driver.get()
driver = webdriver.Chrome()
# 打开浏览器
driver.get("https://www.baidu.com/")
- 用法:
driver.maximize_window()
driver = webdriver.Chrome()
# 打开浏览器
driver.get("https://www.baidu.com/")
# 浏览器最大化
driver.maximize_window()
- driver.minimize_window()
driver = webdriver.Chrome()
# 打开浏览器
driver.get("https://www.baidu.com/")
# 浏览器最小化
driver.minimize_window()
- driver.set_window_size(宽,高)
driver = webdriver.Chrome()
# 打开浏览器
driver.get("https://www.baidu.com/")
# 设置浏览器宽为1200,高为800
driver.set_window_size(1200,800)
- driver.close()
driver = webdriver.Chrome()
# 打开浏览器
driver.get("https://www.baidu.com/")
# 关闭当前窗口
driver.close()
- driver.quit()
driver = webdriver.Chrome()
# 打开浏览器
driver.get("https://www.baidu.com/")
# 关闭所有关联窗口
driver.quit()
- driver.implicitly_wait()
driver = webdriver.Chrome()
# 打开浏览器
driver.get("https://www.baidu.com/")
# 设置等待时间为5秒,5秒之后找不到元素则抛出异常
driver.implicitly_wait(5)
- driver.title
driver = webdriver.Chrome()
# 打开浏览器
driver.get("https://www.baidu.com/")
# 打印百度的title(百度一下,你就知道)
title = driver.title
print(title)
- driver.page_source
driver = webdriver.Chrome()
# 打开浏览器
driver.get("https://www.baidu.com/")
# 打印百度的页面元素
page_source = driver.page_source
print(page_source)
控件元素定位 API
Selenium提供了八种定位方式:https://www.selenium.dev/documentation/webdriver/elements/locators/
| 定位器 Locator | 描述 |
|---|---|
| id | 定位 id 属性与搜索值匹配的元素 |
| name | 定位 name 属性与搜索值匹配的元素 |
| class name | 定位class属性与搜索值匹配的元素(不允许使用复合类名) |
| css selector | 定位 CSS 选择器匹配的元素 |
| xpath | 定位与 XPath 表达式匹配的元素 |
| tag name | 定位标签名称与搜索值匹配的元素 |
| link text | 定位link text可视文本与搜索值完全匹配的锚元素 |
| partial link text | 定位link text可视文本部分与搜索值部分匹配的锚点元素。如果匹配多个元素,则只选择第一个元素。 |
- 用法:
driver.find_element(By.ID, "ID属性对应的值")
# 通过 id 定位
driver.find_element(By.ID,"kw")
- 用法:
driver.find_element(By.NAME, "Name属性对应的值")
# 通过 name 定
driver.find_element(By.NAME,"wd")
- 用法:
driver.find_element(By.CLASS_NAME, "ClassName属性对应的值")
# 通过 classname 定位
driver.find_element(By.CLASS_NAME,"s_ipt"))
- 用法:
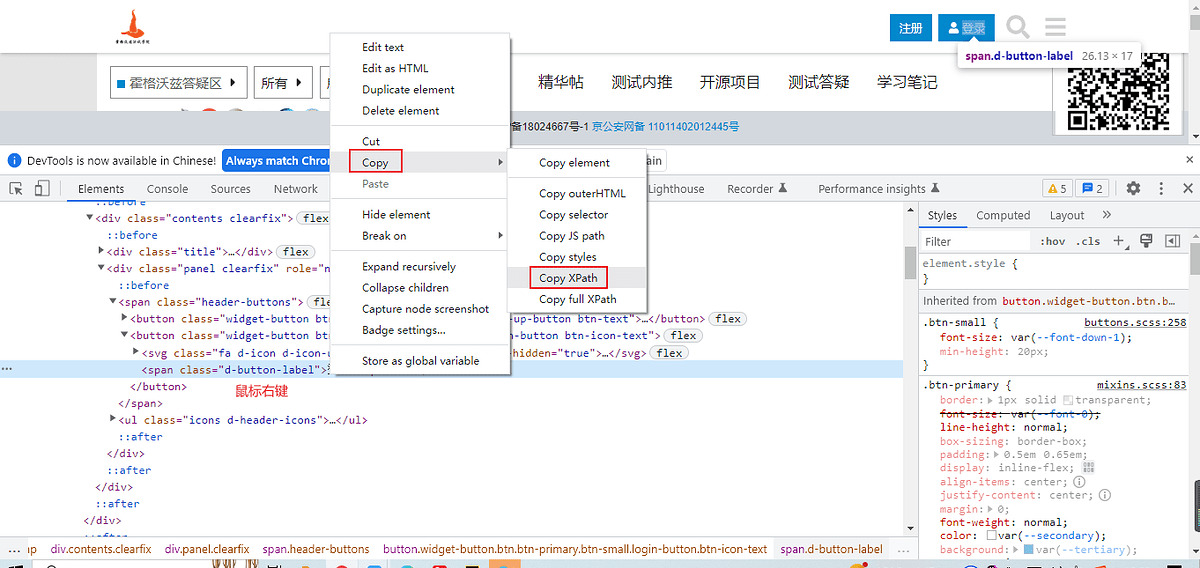
driver.find_element(By.CSS_SELECTOR, "css表达式") - 复制css定位

# css selector定位
driver.find_element(By.CSS_SELECTOR,"#ember7 > header > div > div > div.panel.clearfix > span > button.widget-button.btn.btn-primary.btn-small.login-button.btn-icon-text > span")
css基础语法
| 类型 | 表达式 |
|---|---|
| 标签 | 标签名 |
| 类 | .class属性值 |
| ID | #id属性值 |
| 属性 | [属性名=‘属性值’] |
//在console中的写法,以百度首页为例
//标签名
$('input')
//.类属性值
$('.s_ipt')
//#id属性值
$('#kw')
//[属性名='属性值']
$('[name="wd"]')
css关系定位
| 选择器 | 例子 | 例子描述 |
|---|---|---|
| .class | .intro | 选择 class = “intro” 的所有元素 |
| #id | #firstname | 选择 id= "firstname " 的所有元素 |
| * | * | 选择所有元素 |
| element | p | 选择所有p元素 |
| element,element | div,p | 选择所有div元素和选择所有p元素 |
| element element | div p | 选择所有div元素内部的所有p元素 |
| element>element | div>p | 选择父元素为div元素的所有p元素 |
| element+element | div+p | 选择紧接在div元素之后的所有p元素 |
# 在console中的写法
# 元素,元素(选择所有bg、s_ipt_wr、new-pmd、quickdelete-wrap的元素)
$('.bg,.s_ipt_wr,.new-pmd,.quickdelete-wrap')
# 元素>元素(选择父元素id为s_kw_wrap元素下的所有input元素)
$('#s_kw_wrap>input')
# 元素 元素(选择所有form元素内部的所有input元素)
$('#form input')
# 元素+元素,了解即可(class为soutu-btn和input元素是相邻的兄弟的元素)
$('.soutu-btn+input')
# 元素1~元素2,了解即可(class为soutu-btn和i元素不是相邻的兄弟的元素)
$('.soutu-btn~i')
- 用法:
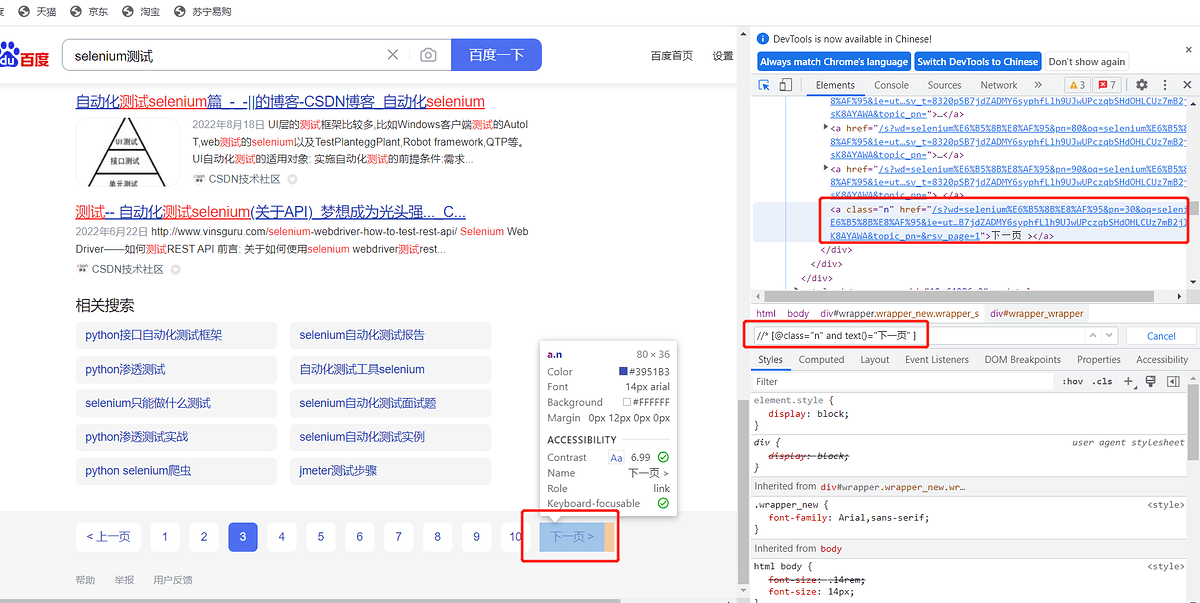
driver.find_element(By.XPATH, "xpath表达式") - 复制xpath定位
# css selector定位
# xpath定位
driver.find_element(By.XPATH,"//*[@id='ember7']/header/div/div/div[2]/span/button[2]/span")
xpath 基础语法
| 表达式 | 结果 |
|---|---|
| / | 从该节点的子元素选取 |
| // | 从该节点的子孙元素选取 |
| * | 通配符 |
| nodename | 选取此节点的所有子节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
# 整个页面
$x("/")
# 页面中的所有的子元素
$x("/*")
# 整个页面中的所有元素
$x("//*")
# 查找页面上面所有的div标签节点
$x("//div")
# 查找id属性为site-logo的节点
$x('//*[@id="site-logo"]')
# 查找节点的父节点
$x('//*[@id="site-logo"]/..')
xpath 高级用法
| 语法 | 描述 |
|---|---|
| [last()] | 选取最后一个 |
| [@属性名=‘属性值’ and @属性名=‘属性值’] | 与关系 |
| [@属性名=‘属性值’ or @属性名=‘属性值’] | 或关系 |
| [text()=‘文本信息’] | 根据文本信息定位 |
| [contains(text(),‘文本信息’)] | 根据文本信息包含定位 |
# 选取最后一个input标签
//input[last()]
# 选取属性name的值为passward并且属性pwd的值为123456的input标签
//input[@name='passward' and @pwd='123456']
# 选取属性name的值为passward或属性pwd的值为123456的input标签
//input[@name='passward' or @pwd='123456']
# 选取所有文本信息为'霍格沃兹测试开发'的元素
//*[text()='霍格沃兹测试开发']
# 选取所有文本信息包'霍格沃兹'的元素
//*[contains(text(),'霍格沃兹')]
xpath 进阶语法
| 表达式 | 举例 | 结果 |
|---|---|---|
| //标签名/标签名 | //ul/* | 选取ul的所有子元素 |
| //标签名[int] | //input[2] | 选取第二个input元素 |
| //标签名[last()] | //input[last()] | 选取最后一个input标签 |
| //标签名[postion()<3] | input[postion()<3] | 选取前2个input元素 |
| //标签名[@属性名=‘属性值’] | //*[@value=‘text’] | 选取所有value属性为text的元素 |
| //标签名[@属性名=‘属性值’ and @属性名=‘属性值’] | //input[@name=‘passward’ and @pwd=‘123456’] | 选取属性name的值为passward并且属性pwd的值为123456的input标签 |
| //标签名[text()=‘文本信息’] | //*[text()=‘霍格沃兹测试开发’] | 选取所有文本信息为’霍格沃兹测试开发’的元素 |
| //标签名[contains(text(),‘文本信息’)] | //*[contains(text(),‘霍格沃兹’)] | 选取所有文本信息包’霍格沃兹’的元素 |
- 用法:
driver.find_element(By.TAG_NAME, "tag标签名称")
# tag标签定位
tag = driver.find_element(By.TAG_NAME,"head")
- 用法:
driver.find_element(By.LINK_TEXT,"文本信息")
# link_text 定位
driver.find_element(By.LINK_TEXT,"霍格沃兹测试开发学社介绍")

- 用法:
driver.find_element(By.PARTIAL_LINK_TEXT,"部分文本信息")
# partial_link_text 定位
driver.find_element(By.PARTIAL_LINK_TEXT,"测试开发学社介绍")
link_text和partial_link_text的区别:
link_text是完全匹配元素中会出现文字,partial_link_text可以是匹配全部元素也可以部分匹配元素的方式,可以写成:“霍格沃兹”、“测试开发学社”、“霍格沃兹测试开发学社介绍”

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)