Pytorch2.0发布了,向下兼容,加一句代码,性能翻番

概述
介绍PyTorch 2.0,我们迈向PyTorch下一代2系列发行版的第一步。在过去的几年里,我们进行了创新和迭代,从PyTorch 1.0到最近的1.13,并转移到新成立的PyTorch基金会,它是Linux基金会的一部分。
除了我们令人惊叹的社区之外,PyTorch最大的优势是我们继续作为一流的Python集成、命令式风格、API和选项的简单性。PyTorch 2.0提供了相同的急切模式开发和用户体验,同时从根本上改变和加强了PyTorch在底层编译器级别的操作方式。我们能够为动态形状和分布式提供更快的性能和支持。
下面你会发现你需要更好地理解PyTorch 2.0是什么,它的发展方向,更重要的是今天如何开始(例如,教程,需求,模型,常见的常见问题)的所有信息。还有很多东西需要学习和开发,但我们期待社区的反馈和贡献,使2系列更好,感谢所有使1系列如此成功的人。
PYTORCH 2.X:更快,更python化,和以前一样动态
今天,我们宣布了torch.compile,这一特性将PyTorch的性能推到新的高度,并开始将PyTorch的部分内容从c++移回Python。我们相信这是PyTorch的一个重要的新方向——因此我们称之为2.0。compile是一个完全可添加的(可选的)特性,因此根据定义2.0是100%向后兼容的。
-
支持torch.compile的是一些新技术——TorchDynamo, AOTAutograd, PrimTorch和TorchInductor。
-
TorchDynamo使用Python框架评估钩子安全地捕获PyTorch程序,这是我们在安全图形捕获方面进行了5年研发的一个重大创新
-
AOTAutograd会重载PyTorch的autograd引擎,作为一个跟踪autodiff来生成提前向后的跟踪。
-
PrimTorch将大约2000多个PyTorch操作符规范化,简化为一个大约250个基本操作符的封闭集合,开发人员可以针对这些操作符构建一个完整的PyTorch后端。这大大降低了编写PyTorch特性或后端的障碍。
-
TorchInductor是一个深度学习编译器,可以为多个加速器和后端生成快速代码。对于NVIDIA gpu,它使用OpenAI Triton作为关键构建块。
-
46个HuggingFace Transomer的模型
-
TIMM的61个模型:由Ross Wightman收集最先进的PyTorch图像模型
-
TorchBench的56个模型:一组来自整个github的流行代码库
我们不修改这些开源模型,只是添加了一个torch.compile调用来包装它们。
然后我们测量加速并验证这些模型的准确性。由于加速可以依赖于数据类型,我们在float32和自动混合精度(AMP)上测量加速。我们报告了一个不均匀的加权平均加速0.75 * AMP + 0.25 * float32,因为我们发现AMP在实践中更常见。
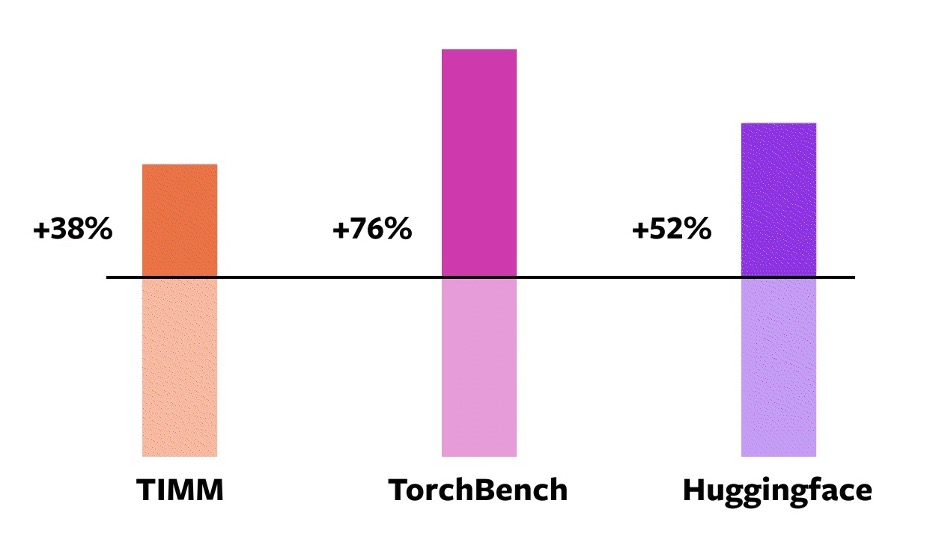
在这163个开源模型中,torch.compile的工作时间达到93%,在NVIDIA A100 GPU上训练时,该模型的运行速度要快43%。在Float32精度上,它的运行速度平均快21%,在AMP精度上,它的运行速度平均快51%。
注意:在桌面级GPU(如NVIDIA 3090)上,我们测量的速度要低于服务器级GPU(如A100)。到今天为止,我们的默认后端TorchInductor支持cpu和NVIDIA Volta和安培gpu。它(还)不支持其他gpu, xpu或更老的NVIDIA gpu。
TorchDynamo、AOTAutograd、PrimTorch和TorchInductor都是用Python编写的,支持动态形状(即可以发送不同大小的张量而不需要重新编译),这使得它们灵活、容易被黑客攻击,并降低了开发人员和供应商的进入门槛。
为了验证这些技术,我们在不同的机器学习领域使用了163个不同的开源模型。我们仔细地构建了这个基准测试,包括图像分类、目标检测、图像生成、各种NLP任务,如语言建模、问答、序列分类、推荐系统和强化学习。我们将基准分为三类:
不妨试试:torch.compile正处于开发的早期阶段。从今天开始,您可以在夜间的二进制文件中尝试使用torch.compile。我们预计在2023年3月初发布第一个稳定的2.0版本。
在PyTorch 2的路线图中。X,我们希望在性能和可伸缩性方面将编译模式推进得越来越远。正如我们今天在会议上谈到的,其中一些工作正在进行中。其中一些工作还没有开始。其中一些工作是我们希望看到的,但我们自己没有足够的带宽去做。如果你有兴趣投稿,请在本月开始的Ask the Engineers: 2.0 Live Q&A系列中与我们聊天(详情见本文末尾)或通过Github / forum。
动机
我们在PyTorch上的理念一直是把灵活性和可破解性放在首位,性能紧随其后。我们争取:
-
高性能快速执行
-
整洁的内部
-
对分布式,自动差异,数据加载,加速器等更好的抽象。
自从我们在2017年推出PyTorch以来,硬件加速器(如gpu)的计算速度提高了约15倍,内存访问速度提高了约2倍。因此,为了保持在高性能状态下的快速执行,我们不得不将PyTorch内部的大量部分迁移到c++中。将内部代码迁移到c++中使其不易被黑客攻击,并增加了代码贡献的进入障碍。
从第一天起,我们就知道急切执行的性能极限。2017年7月,我们开始了第一个为PyTorch开发编译器的研究项目。编译器需要使PyTorch程序快速,但不能以牺牲PyTorch体验为代价。我们的关键标准是保持某种灵活性——支持研究人员在不同探索阶段使用的动态形状和动态程序。
用户体验
我们介绍一个简单的函数torch.compile,它包装模型并返回一个编译后的模型:
compiled_model = torch.compile(model)
compiled_model保存对模型的引用,并将转发函数编译为一个更优化的版本。在编译模型时,我们给了几个旋钮来调整它:
def torch.compile(model: Callable,
*,
mode: Optional[str] = "default",
dynamic: bool = False,
fullgraph:bool = False,
backend: Union[str, Callable] = "inductor",
# advanced backend options go here as kwargs
**kwargs
) -> torch._dynamo.NNOptimizedModule
mode:指定编译器在编译时优化方式。
- 默认模式是一种预设模式,它试图有效地编译,而不会花费太长时间编译或使用额外的内存。
- 其他模式,如reduce-overhead,可以大大减少框架开销,但只消耗少量额外内存。Max-autotune编译了很长时间,试图为您提供它所能生成的最快的代码。
dynamic指定是否启用动态形状的代码路径。某些编译器优化不能应用于动态形状程序。明确您想要一个带有动态形状还是静态形状的编译程序,将有助于编译器提供更好的优化代码。
fullgraph类似于Numba的nopython。它将整个程序编译成一个图形,或者给出一个错误解释为什么它不能这样做。大多数用户不需要使用这种模式。如果您非常注重性能,那么您可以尝试使用它。
Backend指定要使用哪个编译器后端。默认情况下,使用TorchInductor,但还有其他一些可用的工具。

一个完整的实例:
import torch
import torchvision.models as models
model = models.resnet18().cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
compiled_model = torch.compile(model)
x = torch.randn(16, 3, 224, 224).cuda()
optimizer.zero_grad()
out = compiled_model(x)
out.sum().backward()
optimizer.step()
第一次运行compiled_model(x)时,它将编译模型。因此,它需要更长的运行时间。后续的运行速度很快。
Modes
编译器有一些预设,可以用不同的方式调优编译后的模型。由于框架开销,您可能正在运行一个速度较慢的小型模型。或者,您可能正在运行一个几乎无法装入内存的大型模型。根据您的需要,您可能需要使用不同的模式。
# API NOT FINAL
# default: optimizes for large models, low compile-time
# and no extra memory usage
torch.compile(model)
# reduce-overhead: optimizes to reduce the framework overhead
# and uses some extra memory. Helps speed up small models
torch.compile(model, mode="reduce-overhead")
# max-autotune: optimizes to produce the fastest model,
# but takes a very long time to compile
torch.compile(model, mode="max-autotune")
reduce-overhead适用于小模型,max-autotune类似TensorRT那样生成一个更加快速的模型。
如何安装Pytorch2.0
CUDA 11.7
pip install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117
CUDA 11.6
pip install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu116
CPU
pip install numpy --pre torch torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cpu
总结
核心是compile,增加一句话,实现模型近一倍的提速,我表示怀疑,等正式版吧!欢迎勇士去做尝试,如果有问题请留言讨论。
参考:

- 点赞
- 收藏
- 关注作者
评论(0)