GhostNet网络解析

摘要
GhostNet网络是2019年的发布的轻量级网络,速度和MobileNetV3相似,但是识别的准确率比MobileNetV3高,在ImageNet ILSVRC-2012分类数据集的达到了75.7%的top-1精度。
论文链接:https://arxiv.org/abs/1911.11907
作者解读:https://zhuanlan.zhihu.com/p/109325275
开源代码:https://github.com/huawei-noah/ghostnet
论文翻译:https://wanghao.blog.csdn.net/article/details/127981705?spm=1001.2014.3001.5502
该论文提除了Ghost模块,通过廉价操作生成更多的特征图。基于一组原始的特征图,作者应用一系列线性变换,以很小的代价生成许多能从原始特征发掘所需信息的“Ghost”特征图(Ghost feature maps)。Ghost模块是一种即插即用的模块,通过堆叠Ghost模块得出Ghost bottleneck,进而搭建轻量级神经网络——GhostNet。
首先,我们先来分析这篇论文的核心:Ghost 模块
Ghost 模块
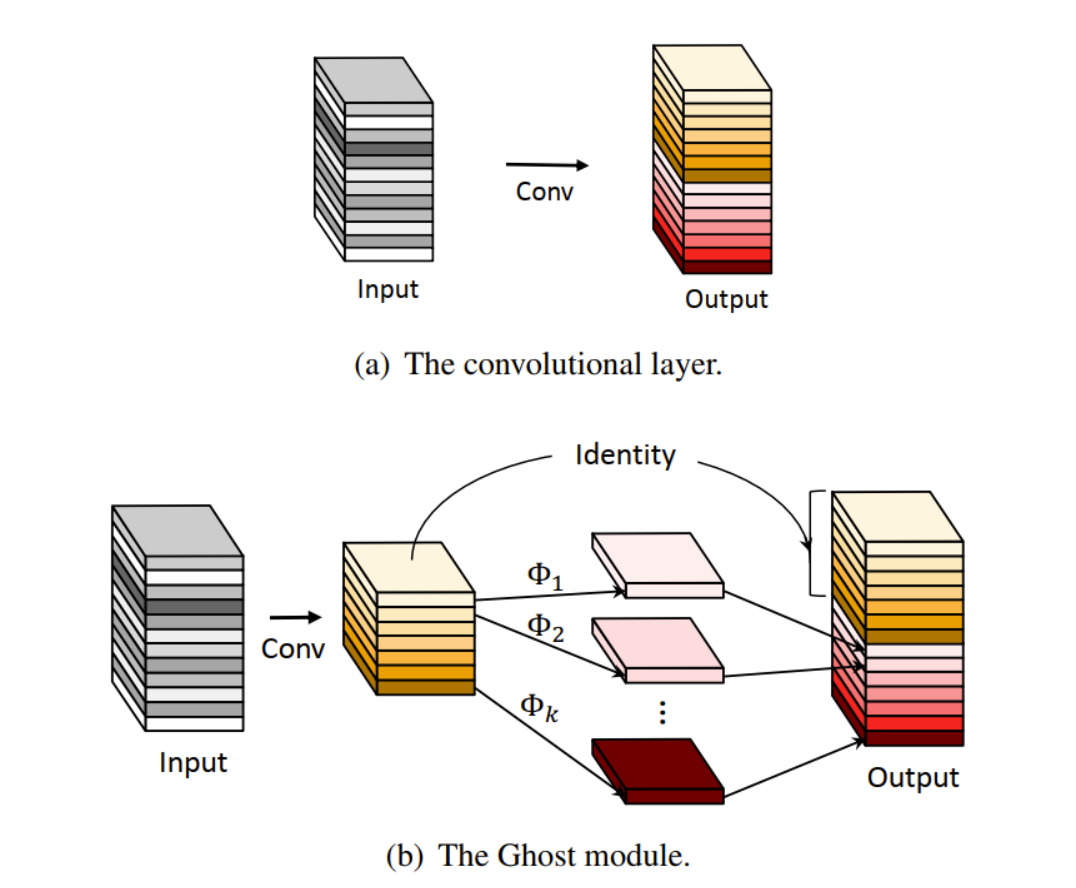
Ghost-Module分成三个步骤:
第一、先通过普通的conv生成一些特征图。
第二、对生成的特征图进行cheap操作生成冗余特征图,这步使用的卷积是DW 卷积。
第三 将conv生成的特征图与cheap操作生成的特征图进行concat操作。
如下图(b)所示,展示了Ghost模块和普通卷积的过程。
代码:
class GhostModule(nn.Module):
def __init__(self, in_channels,out_channels,s=2, kernel_size=1,stride=1, use_relu=True):
super(GhostModule, self).__init__()
intrinsic_channels = out_channels//s
ghost_channels = intrinsic_channels * (s - 1)
self.primary_conv = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=intrinsic_channels, kernel_size=kernel_size, stride=stride,
padding=kernel_size // 2, bias=False),
nn.BatchNorm2d(intrinsic_channels),
nn.ReLU(inplace=True) if use_relu else nn.Sequential()
)
self.cheap_op = DW_Conv3x3BNReLU(in_channels=intrinsic_channels, out_channels=ghost_channels, stride=stride,groups=intrinsic_channels)
def forward(self, x):
y = self.primary_conv(x)
z = self.cheap_op(y)
out = torch.cat([y, z], dim=1)
return out
实现了Ghost 模块,接下来开始搭建 Ghost Bottlenecks
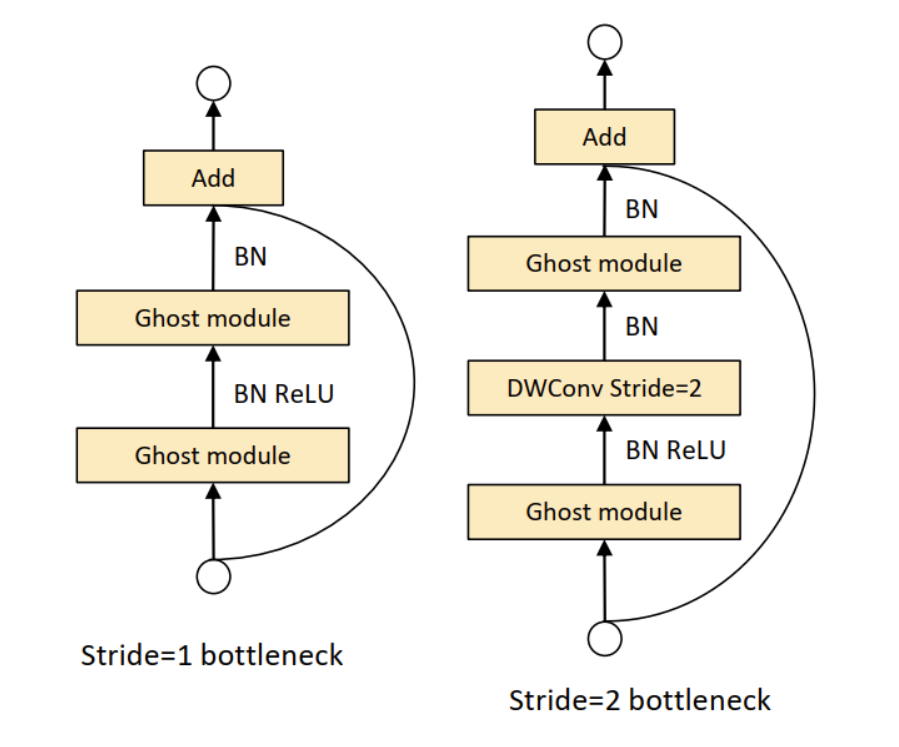
Ghost Bottlenecks
Ghost Bottlenecks 有两种,这点和ResNet的Block是一样的,一种stride=1,使用Ghost Module代替3×3的普通卷积;一种是stride=2,在Ghost module中间加入stride=2的DW卷积。
代码:
class GhostBottleneck(nn.Module):
def __init__(self, in_channels,mid_channels, out_channels , kernel_size, stride, use_se, se_kernel_size=1):
super(GhostBottleneck, self).__init__()
self.stride = stride
self.bottleneck = nn.Sequential(
GhostModule(in_channels=in_channels,out_channels=mid_channels,kernel_size=1,use_relu=True),
DW_Conv3x3BNReLU(in_channels=mid_channels, out_channels=mid_channels, stride=stride,groups=mid_channels) if self.stride>1 else nn.Sequential(),
SqueezeAndExcite(mid_channels,mid_channels,se_kernel_size) if use_se else nn.Sequential(),
GhostModule(in_channels=mid_channels, out_channels=out_channels, kernel_size=1, use_relu=False)
)
if self.stride>1:
self.shortcut = DW_Conv3x3BNReLU(in_channels=in_channels, out_channels=out_channels, stride=stride)
else:
self.shortcut = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1)
def forward(self, x):
out = self.bottleneck(x)
residual = self.shortcut(x)
out += residual
return out
接下来实现GhostNet。
GhostNet
GhostNet的参数结构参考论文中的图。如下图:
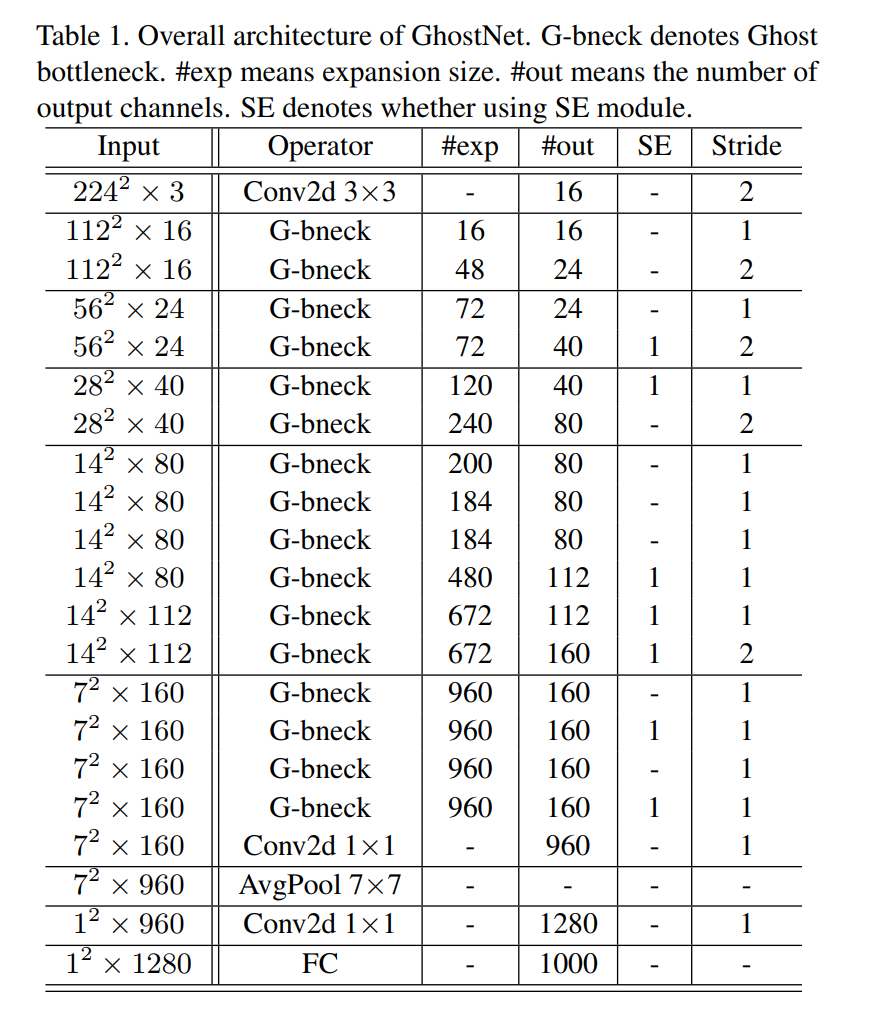
我们将参数传入到Ghost Bottlenecks中即可
如下:
class GhostNet(nn.Module):
def __init__(self, num_classes=1000):
super(GhostNet, self).__init__()
self.first_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(16),
nn.ReLU6(inplace=True),
)
self.features = nn.Sequential(
GhostBottleneck(in_channels=16, mid_channels=16, out_channels=16, kernel_size=3, stride=1, use_se=False),
GhostBottleneck(in_channels=16, mid_channels=64, out_channels=24, kernel_size=3, stride=2, use_se=False),
GhostBottleneck(in_channels=24, mid_channels=72, out_channels=24, kernel_size=3, stride=1, use_se=False),
GhostBottleneck(in_channels=24, mid_channels=72, out_channels=40, kernel_size=5, stride=2, use_se=True, se_kernel_size=28),
GhostBottleneck(in_channels=40, mid_channels=120, out_channels=40, kernel_size=5, stride=1, use_se=True, se_kernel_size=28),
GhostBottleneck(in_channels=40, mid_channels=120, out_channels=40, kernel_size=5, stride=1, use_se=True, se_kernel_size=28),
GhostBottleneck(in_channels=40, mid_channels=240, out_channels=80, kernel_size=3, stride=1, use_se=False),
GhostBottleneck(in_channels=80, mid_channels=200, out_channels=80, kernel_size=3, stride=1, use_se=False),
GhostBottleneck(in_channels=80, mid_channels=184, out_channels=80, kernel_size=3, stride=2, use_se=False),
GhostBottleneck(in_channels=80, mid_channels=184, out_channels=80, kernel_size=3, stride=1, use_se=False),
GhostBottleneck(in_channels=80, mid_channels=480, out_channels=112, kernel_size=3, stride=1, use_se=True, se_kernel_size=14),
GhostBottleneck(in_channels=112, mid_channels=672, out_channels=112, kernel_size=3, stride=1, use_se=True, se_kernel_size=14),
GhostBottleneck(in_channels=112, mid_channels=672, out_channels=160, kernel_size=5, stride=2, use_se=True,se_kernel_size=7),
GhostBottleneck(in_channels=160, mid_channels=960, out_channels=160, kernel_size=5, stride=1, use_se=True,se_kernel_size=7),
GhostBottleneck(in_channels=160, mid_channels=960, out_channels=160, kernel_size=5, stride=1, use_se=True,se_kernel_size=7),
)
self.last_stage = nn.Sequential(
nn.Conv2d(in_channels=160, out_channels=960, kernel_size=1, stride=1),
nn.BatchNorm2d(960),
nn.ReLU6(inplace=True),
nn.AvgPool2d(kernel_size=7, stride=1),
nn.Conv2d(in_channels=960, out_channels=1280, kernel_size=1, stride=1),
nn.ReLU6(inplace=True),
)
self.classifier = nn.Linear(in_features=1280,out_features=num_classes)
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear) or isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.first_conv(x)
x = self.features(x)
x= self.last_stage(x)
x = x.view(x.size(0), -1)
out = self.classifier(x)
return out
完整代码:
import torch
import torch.nn as nn
import torchvision
def DW_Conv3x3BNReLU(in_channels,out_channels,stride,groups=1):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=1,groups=groups, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
class SqueezeAndExcite(nn.Module):
def __init__(self, in_channels, out_channels, divide=4):
super(SqueezeAndExcite, self).__init__()
mid_channels = in_channels // divide
self.pool = nn.AdaptiveAvgPool2d(1)
self.SEblock = nn.Sequential(
nn.Linear(in_features=in_channels, out_features=mid_channels),
nn.ReLU6(inplace=True),
nn.Linear(in_features=mid_channels, out_features=out_channels),
nn.ReLU6(inplace=True),
)
def forward(self, x):
b, c, h, w = x.size()
out = self.pool(x)
out = out.view(b, -1)
out = self.SEblock(out)
out = out.view(b, c, 1, 1)
return out * x
class GhostModule(nn.Module):
def __init__(self, in_channels,out_channels,s=2, kernel_size=1,stride=1, use_relu=True):
super(GhostModule, self).__init__()
intrinsic_channels = out_channels//s
ghost_channels = intrinsic_channels * (s - 1)
self.primary_conv = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=intrinsic_channels, kernel_size=kernel_size, stride=stride,
padding=kernel_size // 2, bias=False),
nn.BatchNorm2d(intrinsic_channels),
nn.ReLU(inplace=True) if use_relu else nn.Sequential()
)
self.cheap_op = DW_Conv3x3BNReLU(in_channels=intrinsic_channels, out_channels=ghost_channels, stride=stride,groups=intrinsic_channels)
def forward(self, x):
y = self.primary_conv(x)
z = self.cheap_op(y)
out = torch.cat([y, z], dim=1)
return out
class GhostBottleneck(nn.Module):
def __init__(self, in_channels,mid_channels, out_channels , kernel_size, stride, use_se, se_kernel_size=1):
super(GhostBottleneck, self).__init__()
self.stride = stride
self.bottleneck = nn.Sequential(
GhostModule(in_channels=in_channels,out_channels=mid_channels,kernel_size=1,use_relu=True),
DW_Conv3x3BNReLU(in_channels=mid_channels, out_channels=mid_channels, stride=stride,groups=mid_channels) if self.stride>1 else nn.Sequential(),
SqueezeAndExcite(mid_channels,mid_channels,se_kernel_size) if use_se else nn.Sequential(),
GhostModule(in_channels=mid_channels, out_channels=out_channels, kernel_size=1, use_relu=False)
)
if self.stride>1:
self.shortcut = DW_Conv3x3BNReLU(in_channels=in_channels, out_channels=out_channels, stride=stride)
else:
self.shortcut = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1)
def forward(self, x):
out = self.bottleneck(x)
residual = self.shortcut(x)
out += residual
return out
class GhostNet(nn.Module):
def __init__(self, num_classes=1000):
super(GhostNet, self).__init__()
self.first_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(16),
nn.ReLU6(inplace=True),
)
self.features = nn.Sequential(
GhostBottleneck(in_channels=16, mid_channels=16, out_channels=16, kernel_size=3, stride=1, use_se=False),
GhostBottleneck(in_channels=16, mid_channels=64, out_channels=24, kernel_size=3, stride=2, use_se=False),
GhostBottleneck(in_channels=24, mid_channels=72, out_channels=24, kernel_size=3, stride=1, use_se=False),
GhostBottleneck(in_channels=24, mid_channels=72, out_channels=40, kernel_size=5, stride=2, use_se=True, se_kernel_size=28),
GhostBottleneck(in_channels=40, mid_channels=120, out_channels=40, kernel_size=5, stride=1, use_se=True, se_kernel_size=28),
GhostBottleneck(in_channels=40, mid_channels=120, out_channels=40, kernel_size=5, stride=1, use_se=True, se_kernel_size=28),
GhostBottleneck(in_channels=40, mid_channels=240, out_channels=80, kernel_size=3, stride=1, use_se=False),
GhostBottleneck(in_channels=80, mid_channels=200, out_channels=80, kernel_size=3, stride=1, use_se=False),
GhostBottleneck(in_channels=80, mid_channels=184, out_channels=80, kernel_size=3, stride=2, use_se=False),
GhostBottleneck(in_channels=80, mid_channels=184, out_channels=80, kernel_size=3, stride=1, use_se=False),
GhostBottleneck(in_channels=80, mid_channels=480, out_channels=112, kernel_size=3, stride=1, use_se=True, se_kernel_size=14),
GhostBottleneck(in_channels=112, mid_channels=672, out_channels=112, kernel_size=3, stride=1, use_se=True, se_kernel_size=14),
GhostBottleneck(in_channels=112, mid_channels=672, out_channels=160, kernel_size=5, stride=2, use_se=True,se_kernel_size=7),
GhostBottleneck(in_channels=160, mid_channels=960, out_channels=160, kernel_size=5, stride=1, use_se=True,se_kernel_size=7),
GhostBottleneck(in_channels=160, mid_channels=960, out_channels=160, kernel_size=5, stride=1, use_se=True,se_kernel_size=7),
)
self.last_stage = nn.Sequential(
nn.Conv2d(in_channels=160, out_channels=960, kernel_size=1, stride=1),
nn.BatchNorm2d(960),
nn.ReLU6(inplace=True),
nn.AvgPool2d(kernel_size=7, stride=1),
nn.Conv2d(in_channels=960, out_channels=1280, kernel_size=1, stride=1),
nn.ReLU6(inplace=True),
)
self.classifier = nn.Linear(in_features=1280,out_features=num_classes)
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear) or isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.first_conv(x)
x = self.features(x)
x= self.last_stage(x)
x = x.view(x.size(0), -1)
out = self.classifier(x)
return out
if __name__ == '__main__':
model = GhostNet()
print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)

- 点赞
- 收藏
- 关注作者
评论(0)