知识蒸馏NST算法实战:使用CoatNet蒸馏ResNet18(二)

蒸馏学生网络
学生网络继续选用ResNet18,使用Teacher网络蒸馏学生网络,训练100个epoch,最终,验证集的ACC为90%。
NST知识蒸馏的脚本详见:
https://wanghao.blog.csdn.net/article/details/127802486?spm=1001.2014.3001.5502。
代码如下:
nst.py
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
'''
NST with Polynomial Kernel, where d=2 and c=0
'''
class NST(nn.Module):
'''
Like What You Like: Knowledge Distill via Neuron Selectivity Transfer
https://arxiv.org/pdf/1707.01219.pdf
'''
def __init__(self):
super(NST, self).__init__()
def forward(self, fm_s, fm_t):
s_H, t_H = fm_s.shape[2], fm_t.shape[2]
if s_H > t_H:
fm_s = F.adaptive_avg_pool2d(fm_s, (t_H, t_H))
elif s_H < t_H:
fm_t = F.adaptive_avg_pool2d(fm_t, (s_H, s_H))
else:
pass
fm_s = fm_s.view(fm_s.size(0), fm_s.size(1), -1)
fm_s = F.normalize(fm_s, dim=2)
fm_t = fm_t.view(fm_t.size(0), fm_t.size(1), -1)
fm_t = F.normalize(fm_t, dim=2)
loss = self.poly_kernel(fm_t, fm_t).mean() \
+ self.poly_kernel(fm_s, fm_s).mean() \
- 2 * self.poly_kernel(fm_s, fm_t).mean()
return loss
def poly_kernel(self, fm1, fm2):
fm1 = fm1.unsqueeze(1)
fm2 = fm2.unsqueeze(2)
out = (fm1 * fm2).sum(-1).pow(2)
return out
步骤
新建kd_train.py,插入代码:
导入需要的库
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from torchvision import datasets
from model.resnet import ResNet18
import json
import os
from nst import NST
导入需要的库,这里要注意,导入的ResNet18是我自定义的模型,不要导入官方自带的ResNet18。
定义训练和验证函数
# 定义训练过程
def train(s_net,t_net, device, criterionCls,criterionKD,train_loader, optimizer, epoch):
s_net.train()
sum_loss = 0
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
l1_out_s,l2_out_s,l3_out_s,l4_out_s,fea_s, out_s = s_net(data)
cls_loss = criterionCls(out_s, target)
l1_out_t,l2_out_t,l3_out_t,l4_out_t,fea_t, out_t = t_net(data) # 训练出教师的 teacher_output
kd_loss = criterionKD(l4_out_s, l4_out_t.detach()) * lambda_kd
loss = cls_loss + kd_loss
loss.backward()
optimizer.step()
print_loss = loss.data.item()
sum_loss += print_loss
if (batch_idx + 1) % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
ave_loss = sum_loss / len(train_loader)
print('epoch:{},loss:{}'.format(epoch, ave_loss))
Best_ACC=0
# 验证过程
@torch.no_grad()
def val(model, device,criterionCls, test_loader):
global Best_ACC
model.eval()
test_loss = 0
correct = 0
total_num = len(test_loader.dataset)
print(total_num, len(test_loader))
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
l1_out_s, l2_out_s, l3_out_s, l4_out_s, fea_s, out_s = model(data)
loss = criterionCls(out_s, target)
_, pred = torch.max(out_s.data, 1)
correct += torch.sum(pred == target)
print_loss = loss.data.item()
test_loss += print_loss
correct = correct.data.item()
acc = correct / total_num
avgloss = test_loss / len(test_loader)
if acc > Best_ACC:
torch.save(model, file_dir + '/' + 'best.pth')
Best_ACC = acc
print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
avgloss, correct, len(test_loader.dataset), 100 * acc))
return acc
编写train方法和val函数,由于修改输出的结果,所以返回结果有多个,我们需要对l4_out_s这个结果做蒸馏。
将Student的l4_out_s和Teacher的l4_out_t输入到criterionKD这个loss函数中计算loss。
l4_out_t.detach()的意思是阻断Teacher模型的反向传播。
在val函数中验证ACC,保存ACC最高的模型。
定义全局参数
if __name__ == '__main__':
# 创建保存模型的文件夹
file_dir = 'resnet_kd'
if os.path.exists(file_dir):
print('true')
os.makedirs(file_dir, exist_ok=True)
else:
os.makedirs(file_dir)
# 设置全局参数
modellr = 1e-4
BATCH_SIZE = 16
EPOCHS = 100
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
lambda_kd=1.0
modellr :学习率
BATCH_SIZE:BatchSize的大小。
EPOCHS :epoch的大小
DEVICE:选择cpu还是gpu训练,默认是gpu,如果找不到GPU则改为CPU训练。
lambda_kd:蒸馏loss的比重,默认是1.0
图像预处理与增强
# 数据预处理7
transform = transforms.Compose([
transforms.RandomRotation(10),
transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)),
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933])
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933])
])
对于训练集,增强有10°的随机旋转、高斯模糊、饱和度明亮等。
对于验证集,则不做数据集增强。
注意:数据增强和Teacher模型里的增强保持一致。
读取数据
使用pytorch默认读取数据的方式。
# 读取数据
dataset_train = datasets.ImageFolder('data/train', transform=transform)
dataset_test = datasets.ImageFolder("data/val", transform=transform_test)
with open('class.txt', 'w') as file:
file.write(str(dataset_train.class_to_idx))
with open('class.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(dataset_train.class_to_idx))
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
设置模型和Loss
model_ft = ResNet18()
print(model_ft)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, 12)
model_ft.to(DEVICE)
# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.Adam(model_ft.parameters(), lr=modellr)
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-9)
teacher_model=torch.load('./CoatNet/best.pth')
teacher_model.eval()
# 实例化模型并且移动到GPU
criterionKD = NST()
criterionCls = nn.CrossEntropyLoss()
# 训练
val_acc_list= {}
for epoch in range(1, EPOCHS + 1):
train(model_ft,teacher_model, DEVICE,criterionCls,criterionKD, train_loader, optimizer, epoch)
cosine_schedule.step()
acc=val(model_ft,DEVICE,criterionCls , test_loader)
val_acc_list[epoch]=acc
with open('result_kd.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(val_acc_list))
torch.save(model_ft, 'resnet_kd/model_final.pth')
设置模型为ResNet18。
修改最后的输出层,将其改为数据集的类别。
设置优化器为Adam。
设置学习率的调节方式为余弦退火算法。
加载Teacher模型,并设置为eval模式。
设置蒸馏loss为criterionKD
设置分类loss为交叉熵。
完成上面的代码就可以开始蒸馏模式!!!
结果比对
加载保存的结果,然后绘制acc曲线。
import numpy as np
from matplotlib import pyplot as plt
import json
teacher_file='result.json'
student_file='result_student.json'
student_kd_file='result_kd.json'
def read_json(file):
with open(file, 'r', encoding='utf8') as fp:
json_data = json.load(fp)
print(json_data)
return json_data
teacher_data=read_json(teacher_file)
student_data=read_json(student_file)
student_kd_data=read_json(student_kd_file)
x =[int(x) for x in list(dict(teacher_data).keys())]
print(x)
plt.plot(x, list(teacher_data.values()), label='teacher')
plt.plot(x,list(student_data.values()), label='student without NST')
plt.plot(x, list(student_kd_data.values()), label='student with NST')
plt.title('Test accuracy')
plt.legend()
plt.show()
最终得到的结果如下图:
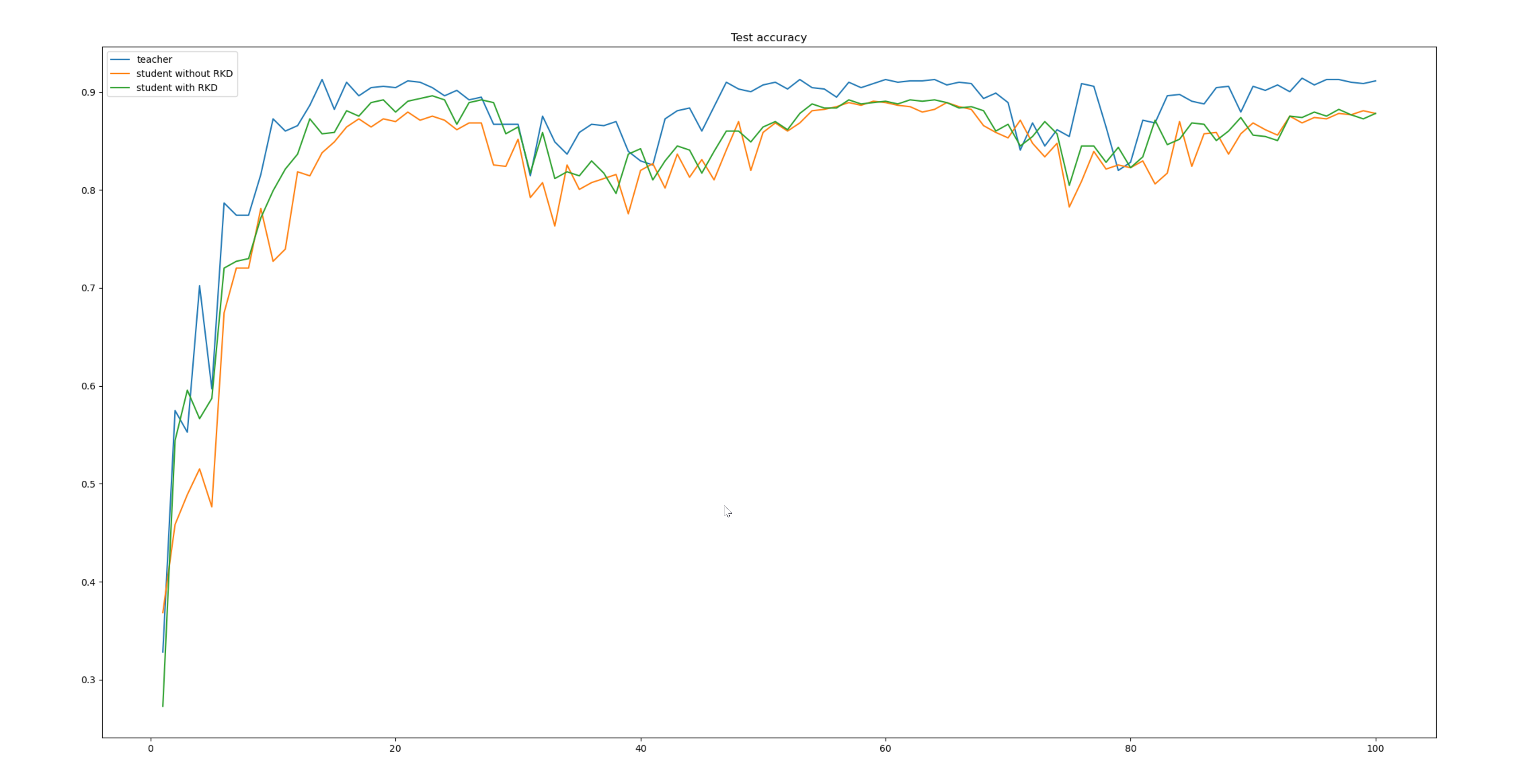
总结
本文重点讲解了如何使用NST知识蒸馏算法对Student模型进行蒸馏。经过蒸馏算法NST训练后,Student模型提高了1%。希望能帮助到大家,如果觉得有用欢迎收藏、点赞和转发;如果有问题也可以留言讨论。
本次实战用到的代码和数据集详见:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/87121089?spm=1001.2014.3001.5503

- 点赞
- 收藏
- 关注作者
评论(0)