知识蒸馏算法汇总(一)

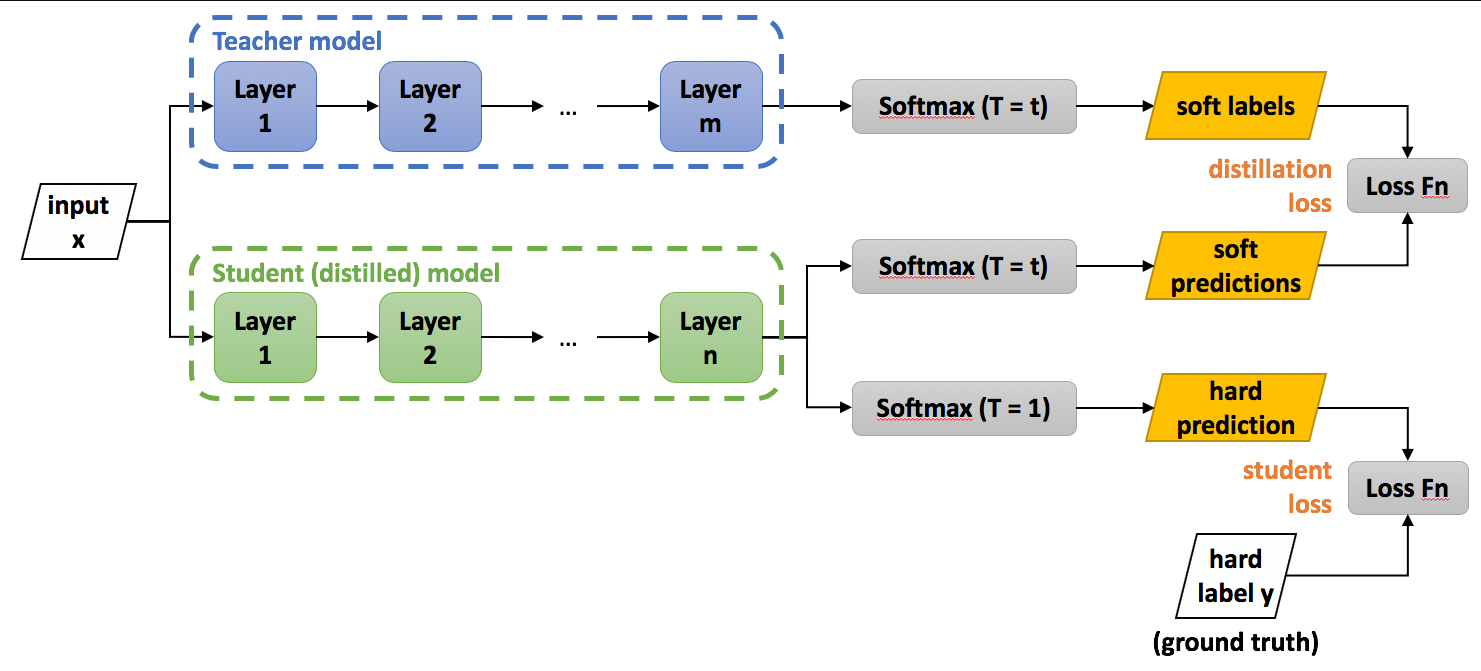
【摘要】 知识蒸馏有两大类:一类是logits蒸馏,另一类是特征蒸馏。logits蒸馏指的是在softmax时使用较高的温度系数,提升负标签的信息,然后使用Student和Teacher在高温softmax下logits的KL散度作为loss。中间特征蒸馏就是强迫Student去学习Teacher某些中间层的特征,直接匹配中间的特征或学习特征之间的转换关系。例如,在特征No.1和No.2中间,知识可以...
知识蒸馏有两大类:一类是logits蒸馏,另一类是特征蒸馏。logits蒸馏指的是在softmax时使用较高的温度系数,提升负标签的信息,然后使用Student和Teacher在高温softmax下logits的KL散度作为loss。中间特征蒸馏就是强迫Student去学习Teacher某些中间层的特征,直接匹配中间的特征或学习特征之间的转换关系。例如,在特征No.1和No.2中间,知识可以表示为如何模做两者中间的转化,可以用一个矩阵让学习者产生这个矩阵,学习者和转化之间的学习关系。
这篇文章汇总了常用的知识蒸馏的论文和代码,方便后续的学习和研究。
1、Logits
论文链接:https://proceedings.neurips.cc/paper/2014/file/ea8fcd92d59581717e06eb187f10666d-Paper.pdf
代码:
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
class Logits(nn.Module):
'''
Do Deep Nets Really Need to be Deep?
http://papers.nips.cc/paper/5484-do-deep-nets-really-need-to-be-deep.pdf
'''
def __init__(self):
super(Logits, self).__init__()
def forward(self, out_s, out_t):
loss = F.mse_loss(out_s, out_t)
return loss
2、ST
论文链接:https://arxiv.org/pdf/1503.02531.pdf
代码:
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
class SoftTarget(nn.Module):
'''
Distilling the Knowledge in a Neural Network
https://arxiv.org/pdf/1503.02531.pdf
'''
def __init__(self, T):
super(SoftTarget, self).__init__()
self.T = T
def forward(self, out_s, out_t):
loss = F.kl_div(F.log_softmax(out_s/self.T, dim=1),
F.softmax(out_t/self.T, dim=1),
reduction='batchmean') * self.T * self.T
return loss
3、AT
论文链接:https://arxiv.org/pdf/1612.03928.pdf
代码:
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
'''
AT with sum of absolute values with power p
'''
class AT(nn.Module):
'''
Paying More Attention to Attention: Improving the Performance of Convolutional
Neural Netkworks wia Attention Transfer
https://arxiv.org/pdf/1612.03928.pdf
'''
def __init__(self, p):
super(AT, self).__init__()
self.p = p
def forward(self, fm_s, fm_t):
loss = F.mse_loss(self.attention_map(fm_s), self.attention_map(fm_t))
return loss
def attention_map(self, fm, eps=1e-6):
am = torch.pow(torch.abs(fm), self.p)
am = torch.sum(am, dim=1, keepdim=True)
norm = torch.norm(am, dim=(2,3), keepdim=True)
am = torch.div(am, norm+eps)
return am
4、Fitnet
论文链接:https://arxiv.org/pdf/1412.6550.pdf
代码:
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
class Hint(nn.Module):
'''
FitNets: Hints for Thin Deep Nets
https://arxiv.org/pdf/1412.6550.pdf
'''
def __init__(self):
super(Hint, self).__init__()
def forward(self, fm_s, fm_t):
loss = F.mse_loss(fm_s, fm_t)
return loss
5、NST
论文链接:https://arxiv.org/pdf/1707.01219.pdf
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
'''
NST with Polynomial Kernel, where d=2 and c=0
'''
class NST(nn.Module):
'''
Like What You Like: Knowledge Distill via Neuron Selectivity Transfer
https://arxiv.org/pdf/1707.01219.pdf
'''
def __init__(self):
super(NST, self).__init__()
def forward(self, fm_s, fm_t):
fm_s = fm_s.view(fm_s.size(0), fm_s.size(1), -1)
fm_s = F.normalize(fm_s, dim=2)
fm_t = fm_t.view(fm_t.size(0), fm_t.size(1), -1)
fm_t = F.normalize(fm_t, dim=2)
loss = self.poly_kernel(fm_t, fm_t).mean() \
+ self.poly_kernel(fm_s, fm_s).mean() \
- 2 * self.poly_kernel(fm_s, fm_t).mean()
return loss
def poly_kernel(self, fm1, fm2):
fm1 = fm1.unsqueeze(1)
fm2 = fm2.unsqueeze(2)
out = (fm1 * fm2).sum(-1).pow(2)
return out
6、PKT
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
'''
Adopted from https://github.com/passalis/probabilistic_kt/blob/master/nn/pkt.py
'''
class PKTCosSim(nn.Module):
'''
Learning Deep Representations with Probabilistic Knowledge Transfer
http://openaccess.thecvf.com/content_ECCV_2018/papers/Nikolaos_Passalis_Learning_Deep_Representations_ECCV_2018_paper.pdf
'''
def __init__(self):
super(PKTCosSim, self).__init__()
def forward(self, feat_s, feat_t, eps=1e-6):
# Normalize each vector by its norm
feat_s_norm = torch.sqrt(torch.sum(feat_s ** 2, dim=1, keepdim=True))
feat_s = feat_s / (feat_s_norm + eps)
feat_s[feat_s != feat_s] = 0
feat_t_norm = torch.sqrt(torch.sum(feat_t ** 2, dim=1, keepdim=True))
feat_t = feat_t / (feat_t_norm + eps)
feat_t[feat_t != feat_t] = 0
# Calculate the cosine similarity
feat_s_cos_sim = torch.mm(feat_s, feat_s.transpose(0, 1))
feat_t_cos_sim = torch.mm(feat_t, feat_t.transpose(0, 1))
# Scale cosine similarity to [0,1]
feat_s_cos_sim = (feat_s_cos_sim + 1.0) / 2.0
feat_t_cos_sim = (feat_t_cos_sim + 1.0) / 2.0
# Transform them into probabilities
feat_s_cond_prob = feat_s_cos_sim / torch.sum(feat_s_cos_sim, dim=1, keepdim=True)
feat_t_cond_prob = feat_t_cos_sim / torch.sum(feat_t_cos_sim, dim=1, keepdim=True)
# Calculate the KL-divergence
loss = torch.mean(feat_t_cond_prob * torch.log((feat_t_cond_prob + eps) / (feat_s_cond_prob + eps)))
return loss
7、FSP
论文链接:http://openaccess.thecvf.com/content_cvpr_2017/papers/Yim_A_Gift_From_CVPR_2017_paper.pdf
代码:
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
class FSP(nn.Module):
'''
A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning
http://openaccess.thecvf.com/content_cvpr_2017/papers/Yim_A_Gift_From_CVPR_2017_paper.pdf
'''
def __init__(self):
super(FSP, self).__init__()
def forward(self, fm_s1, fm_s2, fm_t1, fm_t2):
loss = F.mse_loss(self.fsp_matrix(fm_s1,fm_s2), self.fsp_matrix(fm_t1,fm_t2))
return loss
def fsp_matrix(self, fm1, fm2):
if fm1.size(2) > fm2.size(2):
fm1 = F.adaptive_avg_pool2d(fm1, (fm2.size(2), fm2.size(3)))
fm1 = fm1.view(fm1.size(0), fm1.size(1), -1)
fm2 = fm2.view(fm2.size(0), fm2.size(1), -1).transpose(1,2)
fsp = torch.bmm(fm1, fm2) / fm1.size(2)
return fsp
8、FT
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
class FT(nn.Module):
'''
araphrasing Complex Network: Network Compression via Factor Transfer
http://papers.nips.cc/paper/7541-paraphrasing-complex-network-network-compression-via-factor-transfer.pdf
'''
def __init__(self):
super(FT, self).__init__()
def forward(self, factor_s, factor_t):
loss = F.l1_loss(self.normalize(factor_s), self.normalize(factor_t))
return loss
def normalize(self, factor):
norm_factor = F.normalize(factor.view(factor.size(0),-1))
return norm_factor
9、RKD
论文链接:https://arxiv.org/pdf/1904.05068.pdf
代码:
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
'''
From https://github.com/lenscloth/RKD/blob/master/metric/loss.py
'''
class RKD(nn.Module):
'''
Relational Knowledge Distillation
https://arxiv.org/pdf/1904.05068.pdf
'''
def __init__(self, w_dist, w_angle):
super(RKD, self).__init__()
self.w_dist = w_dist
self.w_angle = w_angle
def forward(self, feat_s, feat_t):
loss = self.w_dist * self.rkd_dist(feat_s, feat_t) + \
self.w_angle * self.rkd_angle(feat_s, feat_t)
return loss
def rkd_dist(self, feat_s, feat_t):
feat_t_dist = self.pdist(feat_t, squared=False)
mean_feat_t_dist = feat_t_dist[feat_t_dist>0].mean()
feat_t_dist = feat_t_dist / mean_feat_t_dist
feat_s_dist = self.pdist(feat_s, squared=False)
mean_feat_s_dist = feat_s_dist[feat_s_dist>0].mean()
feat_s_dist = feat_s_dist / mean_feat_s_dist
loss = F.smooth_l1_loss(feat_s_dist, feat_t_dist)
return loss
def rkd_angle(self, feat_s, feat_t):
# N x C --> N x N x C
feat_t_vd = (feat_t.unsqueeze(0) - feat_t.unsqueeze(1))
norm_feat_t_vd = F.normalize(feat_t_vd, p=2, dim=2)
feat_t_angle = torch.bmm(norm_feat_t_vd, norm_feat_t_vd.transpose(1, 2)).view(-1)
feat_s_vd = (feat_s.unsqueeze(0) - feat_s.unsqueeze(1))
norm_feat_s_vd = F.normalize(feat_s_vd, p=2, dim=2)
feat_s_angle = torch.bmm(norm_feat_s_vd, norm_feat_s_vd.transpose(1, 2)).view(-1)
loss = F.smooth_l1_loss(feat_s_angle, feat_t_angle)
return loss
def pdist(self, feat, squared=False, eps=1e-12):
feat_square = feat.pow(2).sum(dim=1)
feat_prod = torch.mm(feat, feat.t())
feat_dist = (feat_square.unsqueeze(0) + feat_square.unsqueeze(1) - 2 * feat_prod).clamp(min=eps)
if not squared:
feat_dist = feat_dist.sqrt()
feat_dist = feat_dist.clone()
feat_dist[range(len(feat)), range(len(feat))] = 0
return feat_dist
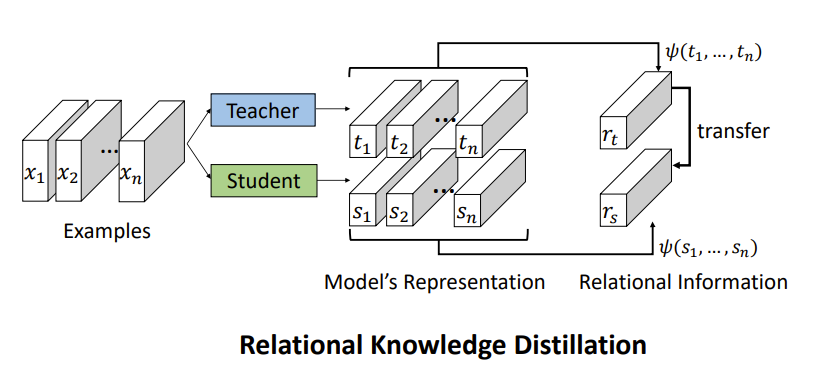
10、AB
论文链接:https://arxiv.org/pdf/1811.03233.pdf
代码:
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
class AB(nn.Module):
'''
Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons
https://arxiv.org/pdf/1811.03233.pdf
'''
def __init__(self, margin):
super(AB, self).__init__()
self.margin = margin
def forward(self, fm_s, fm_t):
# fm befor activation
loss = ((fm_s + self.margin).pow(2) * ((fm_s > -self.margin) & (fm_t <= 0)).float() +
(fm_s - self.margin).pow(2) * ((fm_s <= self.margin) & (fm_t > 0)).float())
loss = loss.mean()
return loss

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)