DFCNN + Transformer模型完成中文语音识别(二)

7.声学模型训练
准备训练参数及数据
为了本示例演示效果,参数batch_size在此仅设置为1,参数data_length在此仅设置为20。
若进行完整训练,则应注释data_args.data_length = 20,并调高batch_size。
def data_hparams():
params = HParams(
data_path = './speech_recognition/data/', #d数据路径
batch_size = 1, #批尺寸
data_length = None, #长度
)
return params
data_args = data_hparams()
data_args.data_length = 20 # 重新训练需要注释该行
train_data = get_data(data_args)
acoustic_model_args = acoustic_model_hparams()
acoustic_model_args.vocab_size = len(train_data.acoustic_vocab)
acoustic = acoustic_model(acoustic_model_args)
print('声学模型参数:')
print(acoustic_model_args)
if os.path.exists('/speech_recognition/acoustic_model/model.h5'):
print('加载声学模型')
acoustic.ctc_model.load_weights('./speech_recognition/acoustic_model/model.h5')
声学模型参数:
[('is_training', True), ('learning_rate', 0.0008), ('vocab_size', 353)]
训练声学模型
epochs = 20
batch_num = len(train_data.wav_lst) // train_data.batch_size
print("训练轮数epochs:",epochs)
print("批数量batch_num:",batch_num)
print("开始训练!")
for k in range(epochs):
print('第', k+1, '个epoch')
batch = train_data.get_acoustic_model_batch()
acoustic.ctc_model.fit_generator(batch, steps_per_epoch=batch_num, epochs=1)
print("\n训练完成,保存模型")
acoustic.ctc_model.save_weights('./speech_recognition/acoustic_model/model.h5')
WARNING:tensorflow:From /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/ops/math_grad.py:102: div (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Deprecated in favor of operator or tf.math.divide.
训练轮数epochs: 20
批数量batch_num: 20
开始训练!
第 1 个epoch
Epoch 1/1
20/20 [==============================] - 11s 532ms/step - loss: 248.9609
第 2 个epoch
Epoch 1/1
20/20 [==============================] - 1s 27ms/step - loss: 196.4688
第 3 个epoch
Epoch 1/1
20/20 [==============================] - 1s 27ms/step - loss: 183.9930
第 4 个epoch
Epoch 1/1
20/20 [==============================] - 1s 28ms/step - loss: 166.3000
第 5 个epoch
Epoch 1/1
20/20 [==============================] - 1s 26ms/step - loss: 138.5052
第 6 个epoch
Epoch 1/1
20/20 [==============================] - 1s 26ms/step - loss: 109.4493
第 7 个epoch
Epoch 1/1
20/20 [==============================] - 1s 25ms/step - loss: 80.0930
第 8 个epoch
Epoch 1/1
20/20 [==============================] - 1s 26ms/step - loss: 61.2114
第 9 个epoch
Epoch 1/1
20/20 [==============================] - 1s 26ms/step - loss: 39.3055
第 10 个epoch
Epoch 1/1
20/20 [==============================] - 1s 26ms/step - loss: 20.6111
第 11 个epoch
Epoch 1/1
20/20 [==============================] - 1s 27ms/step - loss: 8.5875
第 12 个epoch
Epoch 1/1
20/20 [==============================] - 1s 29ms/step - loss: 3.1909
第 13 个epoch
Epoch 1/1
20/20 [==============================] - 1s 27ms/step - loss: 2.1323
第 14 个epoch
Epoch 1/1
20/20 [==============================] - 1s 28ms/step - loss: 1.3118
第 15 个epoch
Epoch 1/1
20/20 [==============================] - 1s 27ms/step - loss: 1.1473
第 16 个epoch
Epoch 1/1
20/20 [==============================] - 1s 29ms/step - loss: 0.8594
第 17 个epoch
Epoch 1/1
20/20 [==============================] - 1s 26ms/step - loss: 0.8544
第 18 个epoch
Epoch 1/1
20/20 [==============================] - 1s 28ms/step - loss: 0.7285
第 19 个epoch
Epoch 1/1
20/20 [==============================] - 1s 29ms/step - loss: 0.6799
第 20 个epoch
Epoch 1/1
20/20 [==============================] - 1s 27ms/step - loss: 0.5522
训练完成,保存模型
8.语言模型
在本实践中,选择使用 Transformer 结构进行语言模型的建模。
Transformer 是完全基于注意力机制(attention mechanism)的网络框架,attention 来自于论文《attention is all you need》。 一个序列每个字符对其上下文字符的影响作用都不同,每个字对序列的语义信息贡献也不同,可以通过一种机制将原输入序列中字符向量通过加权融合序列中所有字符的语义向量信息来产生新的向量,即增强了原语义信息。其结构如下图所示。
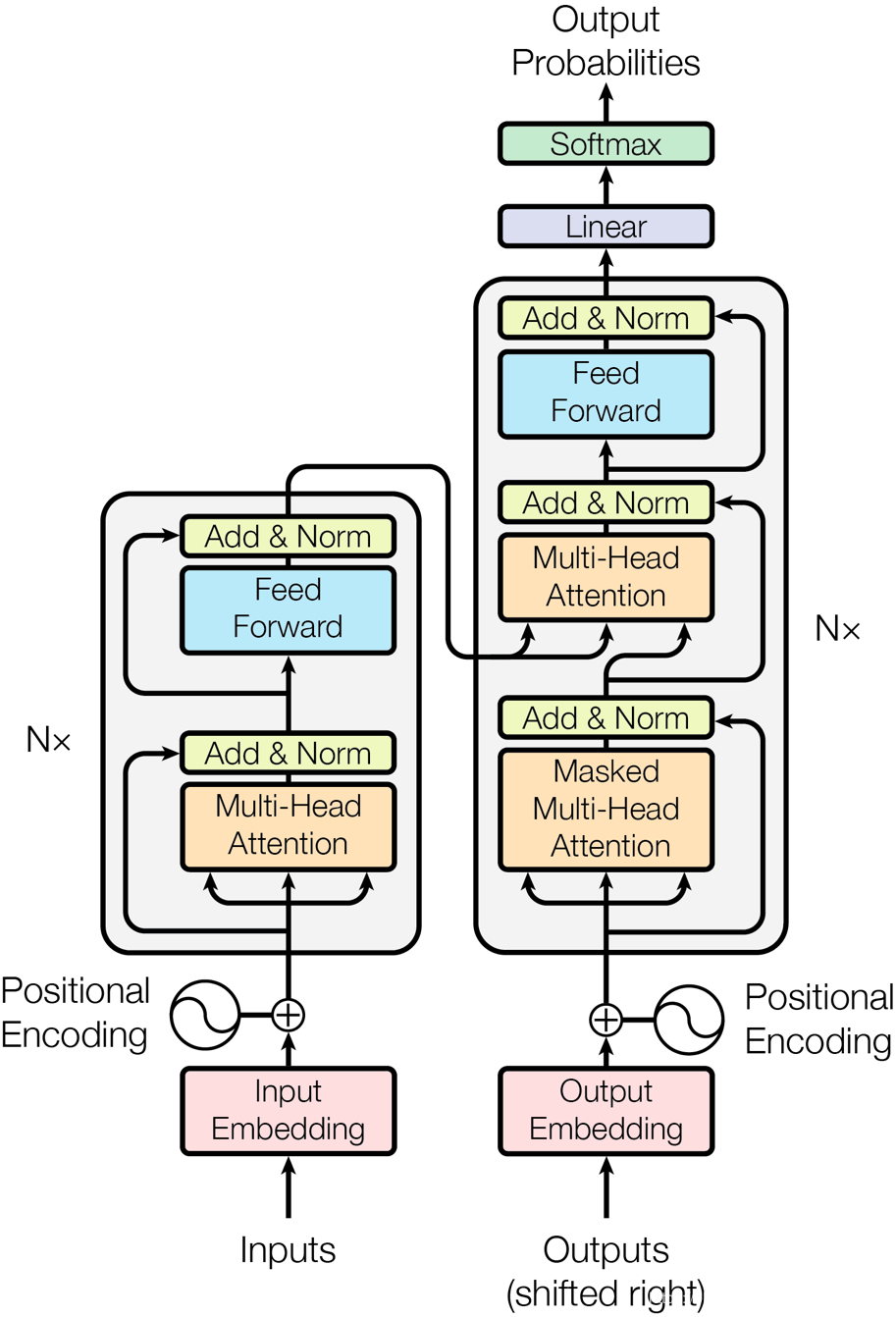
其中左半部分是编码器 encoder 右半部分是解码器 decoder。在本实践中,仅需要搭建左侧 encoder 结构即可。
encoder的详细结构为: 由N=6个相同的 layers 组成, 每一层包含两个 sub-layers. 第一个 sub-layer 就是多头注意力层(multi-head attention layer)然后是一个简单的全连接层。 其中每个 sub-layer 都加了residual connection(残差连接)和 normalisation(归一化)。
下面来具体构建一个基于 Transformer 的语言模型。
定义归一化 normalize层
def normalize(inputs,
epsilon = 1e-8,
scope="ln",
reuse=None):
with tf.variable_scope(scope, reuse=reuse):
inputs_shape = inputs.get_shape()
params_shape = inputs_shape[-1:]
mean, variance = tf.nn.moments(inputs, [-1], keep_dims=True)
beta= tf.Variable(tf.zeros(params_shape))
gamma = tf.Variable(tf.ones(params_shape))
normalized = (inputs - mean) / ( (variance + epsilon) ** (.5) )
outputs = gamma * normalized + beta
return outputs
定义嵌入层 embedding
即位置向量,将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,以便Attention分辨出不同位置的词。
def embedding(inputs,
vocab_size,
num_units,
zero_pad=True,
scale=True,
scope="embedding",
reuse=None):
with tf.variable_scope(scope, reuse=reuse):
lookup_table = tf.get_variable('lookup_table',
dtype=tf.float32,
shape=[vocab_size, num_units],
initializer=tf.contrib.layers.xavier_initializer())
if zero_pad:
lookup_table = tf.concat((tf.zeros(shape=[1, num_units]),
lookup_table[1:, :]), 0)
outputs = tf.nn.embedding_lookup(lookup_table, inputs)
if scale:
outputs = outputs * (num_units ** 0.5)
return outputs
9.多头注意力层(multi-head attention layer)
要了解多头注意力层,首先要知道点乘注意力(Scaled Dot-Product Attention)。Attention 有三个输入(querys,keys,values),有一个输出。选择三个输入是考虑到模型的通用性,输出是所有 value 的加权求和。value 的权重来自于 query 和 keys 的乘积,经过一个 softmax 之后得到。
Scaled Dot-Product Attention 的公式及结构如下图所示。

Multi-Head Attention 就是对输入 K,V,Q 分别进行 H 次线性变换,然后把Scaled Dot-Product Attention的过程做 H 次,把输出的结果做 concat 结合,即为输出。
Multi-Head Attention 的公式及结构如下图所示。
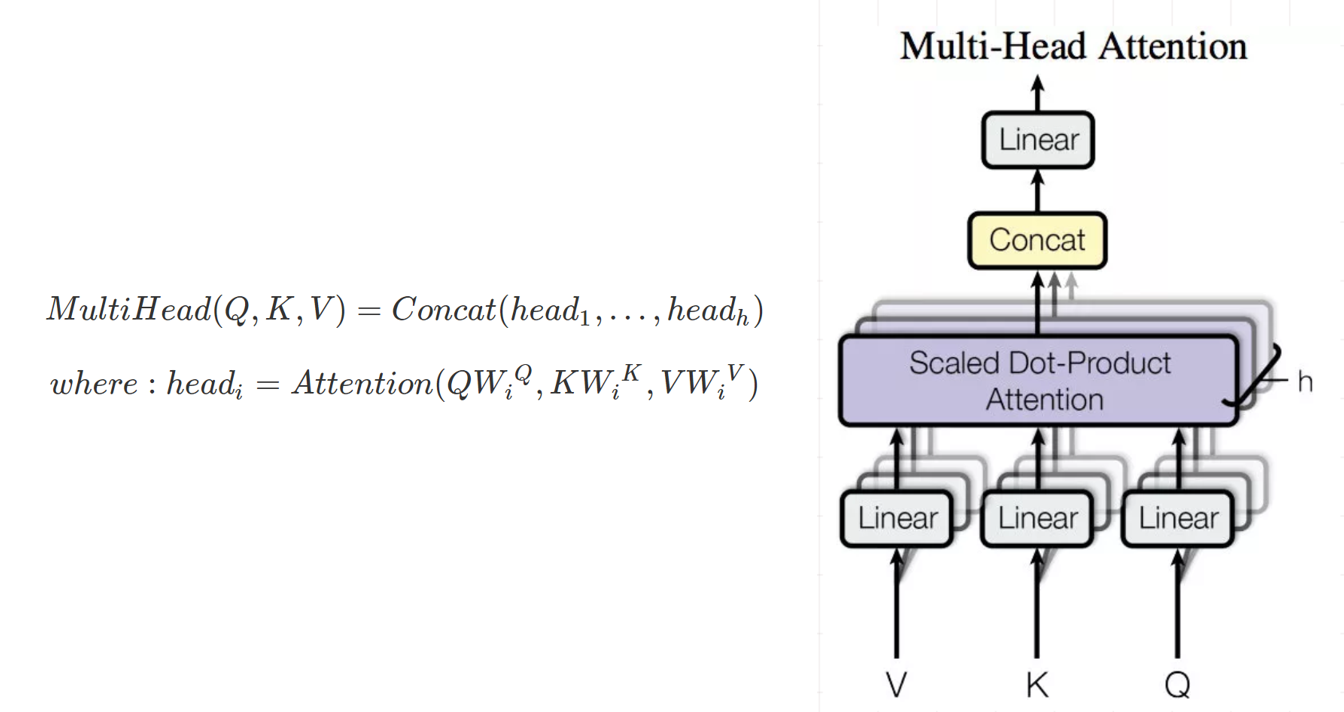
定义 multi-head attention层
def multihead_attention(emb,
queries,
keys,
num_units=None,
num_heads=8,
dropout_rate=0,
is_training=True,
causality=False,
scope="multihead_attention",
reuse=None):
with tf.variable_scope(scope, reuse=reuse):
if num_units is None:
num_units = queries.get_shape().as_list[-1]
Q = tf.layers.dense(queries, num_units, activation=tf.nn.relu) # (N, T_q, C)
K = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C)
V = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C)
Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0) # (h*N, T_q, C/h)
K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0) # (h*N, T_k, C/h)
V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0) # (h*N, T_k, C/h)
outputs = tf.matmul(Q_, tf.transpose(K_, [0, 2, 1])) # (h*N, T_q, T_k)
outputs = outputs / (K_.get_shape().as_list()[-1] ** 0.5)
key_masks = tf.sign(tf.abs(tf.reduce_sum(emb, axis=-1))) # (N, T_k)
key_masks = tf.tile(key_masks, [num_heads, 1]) # (h*N, T_k)
key_masks = tf.tile(tf.expand_dims(key_masks, 1), [1, tf.shape(queries)[1], 1]) # (h*N, T_q, T_k)
paddings = tf.ones_like(outputs)*(-2**32+1)
outputs = tf.where(tf.equal(key_masks, 0), paddings, outputs) # (h*N, T_q, T_k)
if causality:
diag_vals = tf.ones_like(outputs[0, :, :]) # (T_q, T_k)
tril = tf.contrib.linalg.LinearOperatorTriL(diag_vals).to_dense() # (T_q, T_k)
masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(outputs)[0], 1, 1]) # (h*N, T_q, T_k)
paddings = tf.ones_like(masks)*(-2**32+1)
outputs = tf.where(tf.equal(masks, 0), paddings, outputs) # (h*N, T_q, T_k)
outputs = tf.nn.softmax(outputs) # (h*N, T_q, T_k)
query_masks = tf.sign(tf.abs(tf.reduce_sum(emb, axis=-1))) # (N, T_q)
query_masks = tf.tile(query_masks, [num_heads, 1]) # (h*N, T_q)
query_masks = tf.tile(tf.expand_dims(query_masks, -1), [1, 1, tf.shape(keys)[1]]) # (h*N, T_q, T_k)
outputs *= query_masks # broadcasting. (N, T_q, C)
outputs = tf.layers.dropout(outputs, rate=dropout_rate, training=tf.convert_to_tensor(is_training))
outputs = tf.matmul(outputs, V_) # ( h*N, T_q, C/h)
outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2 ) # (N, T_q, C)
outputs += queries
outputs = normalize(outputs) # (N, T_q, C)
return outputs
定义 feedforward层
两层全连接层,用卷积模拟加速运算,并添加残差结构。
def feedforward(inputs,
num_units=[2048, 512],
scope="multihead_attention",
reuse=None):
with tf.variable_scope(scope, reuse=reuse):
params = {"inputs": inputs, "filters": num_units[0], "kernel_size": 1,
"activation": tf.nn.relu, "use_bias": True}
outputs = tf.layers.conv1d(**params)
params = {"inputs": outputs, "filters": num_units[1], "kernel_size": 1,
"activation": None, "use_bias": True}
outputs = tf.layers.conv1d(**params)
outputs += inputs
outputs = normalize(outputs)
return outputs
定义 label_smoothing层
def label_smoothing(inputs, epsilon=0.1):
K = inputs.get_shape().as_list()[-1] # number of channels
return ((1-epsilon) * inputs) + (epsilon / K)
下面可以将上述层组合,建立完整的语言模型
#组合语言模型
class language_model():
def __init__(self, arg):
self.graph = tf.Graph()
with self.graph.as_default():
self.is_training = arg.is_training
self.hidden_units = arg.hidden_units
self.input_vocab_size = arg.input_vocab_size
self.label_vocab_size = arg.label_vocab_size
self.num_heads = arg.num_heads
self.num_blocks = arg.num_blocks
self.max_length = arg.max_length
self.learning_rate = arg.learning_rate
self.dropout_rate = arg.dropout_rate
self.x = tf.placeholder(tf.int32, shape=(None, None))
self.y = tf.placeholder(tf.int32, shape=(None, None))
self.emb = embedding(self.x, vocab_size=self.input_vocab_size, num_units=self.hidden_units, scale=True, scope="enc_embed")
self.enc = self.emb + embedding(tf.tile(tf.expand_dims(tf.range(tf.shape(self.x)[1]), 0), [tf.shape(self.x)[0], 1]),
vocab_size=self.max_length,num_units=self.hidden_units, zero_pad=False, scale=False,scope="enc_pe")
self.enc = tf.layers.dropout(self.enc,
rate=self.dropout_rate,
training=tf.convert_to_tensor(self.is_training))
for i in range(self.num_blocks):
with tf.variable_scope("num_blocks_{}".format(i)):
self.enc = multihead_attention(emb = self.emb,
queries=self.enc,
keys=self.enc,
num_units=self.hidden_units,
num_heads=self.num_heads,
dropout_rate=self.dropout_rate,
is_training=self.is_training,
causality=False)
self.outputs = feedforward(self.enc, num_units=[4*self.hidden_units, self.hidden_units])
self.logits = tf.layers.dense(self.outputs, self.label_vocab_size)
self.preds = tf.to_int32(tf.argmax(self.logits, axis=-1))
self.istarget = tf.to_float(tf.not_equal(self.y, 0))
self.acc = tf.reduce_sum(tf.to_float(tf.equal(self.preds, self.y))*self.istarget)/ (tf.reduce_sum(self.istarget))
tf.summary.scalar('acc', self.acc)
if self.is_training:
self.y_smoothed = label_smoothing(tf.one_hot(self.y, depth=self.label_vocab_size))
self.loss = tf.nn.softmax_cross_entropy_with_logits_v2(logits=self.logits, labels=self.y_smoothed)
self.mean_loss = tf.reduce_sum(self.loss*self.istarget) / (tf.reduce_sum(self.istarget))
self.global_step = tf.Variable(0, name='global_step', trainable=False)
self.optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate, beta1=0.9, beta2=0.98, epsilon=1e-8)
self.train_op = self.optimizer.minimize(self.mean_loss, global_step=self.global_step)
tf.summary.scalar('mean_loss', self.mean_loss)
self.merged = tf.summary.merge_all()
print('语音模型建立完成!')
语音模型建立完成!
未完待续

- 点赞
- 收藏
- 关注作者
评论(0)