视频物体分割

视频物体分割
本案例分为以下几个章节:
- 视频物体分割简介
- OSVOS算法训练和预测
- 视频物体分割的应用
1. 视频物体分割简介
视频物体分割就是从视频所有图像中将感兴趣物体的区域完整地分割出来。
注意“感兴趣物体”这个词,“感兴趣物体”是指在一段视频中最容易捕获人眼注意力的一个或多个物体,比如下图中左上角子图中三个正在跳舞的人,这三个人物是“感兴趣物体”,而周围的人群不属于我们常识上的感兴趣物体,下图中的其他子图也是如此,因此视频物体分割算法一般不需要将视频图像中的所有物体都进行分割,而是只需要分割“感兴趣物体”即可。

学术界在视频物体分割领域主要有三个研究方向:
(1)半监督视频物体分割
(2)交互式视频物体分割
(3)无监督视频物体分割
下面我们来一一讲解三个研究方向的内容。
1.1 半监督视频物体分割
半监督是指由用户给定感兴趣物体在视频第一帧图片上的人工标注真实分割区域,然后算法根据这一帧图片和标注进行学习,完成学习后,由算法来对后续所有帧图片进行分割区域的预测。

如上图所示,第一行分别是一个视频的RGB图片,第二行是感兴趣物体区域,第一列是视频的第一帧图片和人工标注的分割区域,之后的三列分别是第20、40、60帧图片和算法预测的分割区域。
半监督视频物体分割算法还可以再分为两类:有在线学习和无在线学习。有在线学习的算法就是上面提到的根据第一帧物体的 ground-truth,利用 one-shot learning 的策略来 fine-tune 分割模型,每次对一个视频进行预测前,都要先对该视频的第一帧进行学习,fine-tune一下模型,再进行预测,代表性算法是One-Shot Video Object Segmentation。无在线学习的算法是指它的模型是事先训练好的,不需要针对样本进行 fine-tune,具有更好的时效性,代表性算法是FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation。
1.2 交互式视频物体分割
交互式视频物体分割是指算法在运行过程中需要人不断与其交互,然后根据人的交互信息来决定感兴趣物体并进行分割。
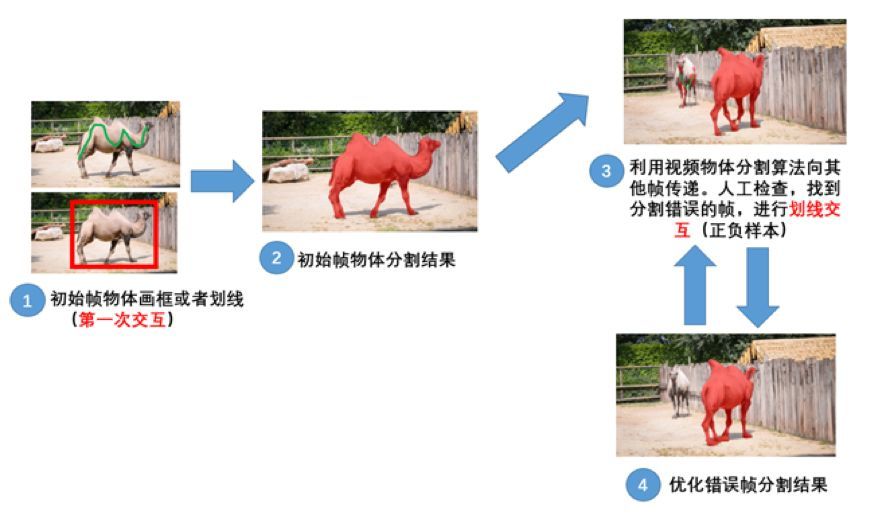
如上图所示,是交互式视频物体分割算法的基本流程,第一帧根据人划的一条线或一个框来确定感兴趣物体,然后得到初始帧的物体分割结果,然后算法继续逐帧预测,直到上面的第3张图,算法分割区域发生了错误,选中了后面一只骆驼的部分区域作为分割区域,这时可以再结合一次人的交互,由人工进行划线区分正负样本,随后算法就进行修正,得到了第4张图的结果。这种交互式视频物体分割算法的特点就是通过人的多次交互达到较好的分割效果。代表性算法是Fast User-Guided Video Object Segmentation by Interaction-and-propagation Networks。
1.3 无监督视频物体分割
无监督视频物体分割是全自动的分割,除了 RGB 视频,没有其他任何输入,其目的是分割出视频中显著性的物体区域,是目前最新的一个研究方向。半监督和交互式视频物体分割中,感兴趣物体是事先指定的,不存在任何歧义,而在无监督视频物体分割中,物体显著性是主观概念,不同人之间存在一定的歧义,因此无监督视频物体分割算法可能需要输出视频中人眼会注意到的多个物体的分割结果。代表性算法是UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking for the 2019 Unsupervised DAVIS Challenge.
以上三个研究方向其实就是DAVIS挑战赛的三个任务,如果您对此感兴趣,可以前往其网站进行了解。
在以上三个研究方向中,由于半监督视频物体分割算法的发展较为成熟,因此本案例采用该类算法的代表性算法OSVOS来实现一个视频物体分割的demo,接下来我们来开始执行OSVOS的代码。
2. OSVOS算法训练和预测
注意事项:
-
本案例使用框架**:** Pytorch-1.0.0
-
本案例使用硬件规格**:** 8 vCPU + 64 GiB + 1 x Tesla V100-PCIE-32GB
-
切换硬件规格方法**:** 如需切换硬件规格,您可以在本页面右边的工作区进行切换
-
运行代码方法**:** 点击本页面顶部菜单栏的三角形运行按钮或按Ctrl+Enter键 运行每个方块中的代码
-
JupyterLab的详细用法**:** 请参考《ModelAtrs JupyterLab使用指导》
-
碰到问题的解决办法**:** 请参考《ModelAtrs JupyterLab常见问题解决办法》
2.1 准备代码和数据
相关代码、数据和模型都已准备好存放在OBS中,执行下面一段代码即可将其拷贝到Notebook中
import os
import subprocess
import moxing as mox
print('Downloading datasets and code ...')
if not os.path.exists('./video_object_segmention/OSVOS-PyTorch'):
mox.file.copy('s3://modelarts-labs-bj4/notebook/DL_video_object_segmentation/OSVOS-PyTorch.zip',
'./video_object_segmention/OSVOS-PyTorch.zip')
p1 = subprocess.run(['cd ./video_object_segmention/;unzip OSVOS-PyTorch.zip;rm OSVOS-PyTorch.zip'],
stdout=subprocess.PIPE, shell=True, check=True)
if os.path.exists('./video_object_segmention/OSVOS-PyTorch'):
print('Download success')
else:
raise Exception('Download failed')
else:
print('Download success')
INFO:root:Using MoXing-v1.17.3-
INFO:root:Using OBS-Python-SDK-3.20.7
Downloading datasets and code ...
Download success
2.2 安装需要的python模块
本案例需要torch 0.4.0才能跑通,如果直接使用pip install torch==0.4.0,安装的是CUDA8.0编译的torch,但是ModelArts的默认CUDA版本为9.0,因此我们指定安装使用CUDA9.0编译的torch 0.4.0,该安装包已经存储在OBS,使用下面一行代码直接copy即可。
if not os.path.exists('./video_object_segmention/torch-0.4.0-cp36-cp36m-linux_x86_64.whl'):
mox.file.copy('obs://modelarts-labs-bj4/notebook/DL_video_object_segmentation/torch-0.4.0-cp36-cp36m-linux_x86_64.whl',
'./video_object_segmention/torch-0.4.0-cp36-cp36m-linux_x86_64.whl')
!pip install ./video_object_segmention/torch-0.4.0-cp36-cp36m-linux_x86_64.whl # 必须安装用CUDA9.0编译的torch 0.4.0
Requirement already satisfied: torch==0.4.0 from file:///home/ma-user/work/ma_share/object_segmentation/video_object_segmention/torch-0.4.0-cp36-cp36m-linux_x86_64.whl in /home/ma-user/anaconda3/envs/Pytorch-1.0.0/lib/python3.6/site-packages
[33mYou are using pip version 9.0.1, however version 21.0.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.[0m
!pip install -r ./video_object_segmention/OSVOS-PyTorch/requirements.txt
此处输出较长,省略
注意!安装完以上模块后,会有一些c++库的更新,因此需要点击本页面顶部菜单栏的 Kernel,再点 Restart
导入需要的python模块
!pip install scipy==1.1.0
from __future__ import division
import os
import cv2
import sys
sys.path.insert(0, './video_object_segmention/OSVOS-PyTorch')
import socket
import time
import timeit
import numpy as np
from datetime import datetime
# from tensorboardX import SummaryWriter
# PyTorch includes
import torch
import torch.optim as optim
from torchvision import transforms
from torch.utils.data import DataLoader
# Custom includes
from dataloaders import davis_2016 as db
from dataloaders import custom_transforms as tr
from util import visualize as viz
import scipy.misc as sm
import networks.vgg_osvos as vo
from layers.osvos_layers import class_balanced_cross_entropy_loss
from dataloaders.helpers import *
from mypath import Path
from IPython.display import clear_output, Image, display
Requirement already satisfied: scipy==1.1.0 in /home/ma-user/anaconda3/envs/Pytorch-1.0.0/lib/python3.6/site-packages
Requirement already satisfied: numpy>=1.8.2 in /home/ma-user/anaconda3/envs/Pytorch-1.0.0/lib/python3.6/site-packages (from scipy==1.1.0)
[33mYou are using pip version 9.0.1, however version 21.0.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.[0m
定义模型和训练超参
# Setting of parameters
if 'SEQ_NAME' not in os.environ.keys():
seq_name = 'flamingo'
else:
seq_name = str(os.environ['SEQ_NAME'])
db_root_dir = Path.db_root_dir() # 训练数据所在路径,定义在./video_object_segmention/OSVOS-PyTorch/mypath.py中
save_dir = Path.save_root_dir() # 训练结果保存路径,定义在./video_object_segmention/OSVOS-PyTorch/mypath.py中
if not os.path.exists(save_dir):
os.makedirs(os.path.join(save_dir))
vis_net = 0 # Visualize the network?
vis_res = 0 # Visualize the results?
nAveGrad = 5 # Average the gradient every nAveGrad iterations
nEpochs = 200 * nAveGrad # Number of epochs for training # 总的训练轮数
snapshot = nEpochs # Store a model every snapshot epochs
parentEpoch = 240
# Parameters in p are used for the name of the model
p = {
'trainBatch': 1, # Number of Images in each mini-batch
}
seed = 0
parentModelName = 'parent'
# Select which GPU, -1 if CPU
gpu_id = 0
device = torch.device("cuda:"+str(gpu_id) if torch.cuda.is_available() else "cpu")
# Network definition
net = vo.OSVOS(pretrained=0)
net.load_state_dict(torch.load(os.path.join(save_dir, parentModelName+'_epoch-'+str(parentEpoch-1)+'.pth'),
map_location=lambda storage, loc: storage))
print('Initializing weights success')
# Logging into Tensorboard
log_dir = os.path.join(save_dir, 'runs', datetime.now().strftime('%b%d_%H-%M-%S') + '_' + socket.gethostname()+'-'+seq_name)
# writer = SummaryWriter(log_dir=log_dir)
net.to(device) # PyTorch 0.4.0 style
# Use the following optimizer
lr = 1e-8
wd = 0.0002
optimizer = optim.SGD([
{'params': [pr[1] for pr in net.stages.named_parameters() if 'weight' in pr[0]], 'weight_decay': wd},
{'params': [pr[1] for pr in net.stages.named_parameters() if 'bias' in pr[0]], 'lr': lr * 2},
{'params': [pr[1] for pr in net.side_prep.named_parameters() if 'weight' in pr[0]], 'weight_decay': wd},
{'params': [pr[1] for pr in net.side_prep.named_parameters() if 'bias' in pr[0]], 'lr': lr*2},
{'params': [pr[1] for pr in net.upscale.named_parameters() if 'weight' in pr[0]], 'lr': 0},
{'params': [pr[1] for pr in net.upscale_.named_parameters() if 'weight' in pr[0]], 'lr': 0},
{'params': net.fuse.weight, 'lr': lr/100, 'weight_decay': wd},
{'params': net.fuse.bias, 'lr': 2*lr/100},
], lr=lr, momentum=0.9)
Constructing OSVOS architecture..
Initializing weights..
Initializing weights success
定义数据生成器
# Preparation of the data loaders
# Define augmentation transformations as a composition
composed_transforms = transforms.Compose([tr.RandomHorizontalFlip(),
tr.ScaleNRotate(rots=(-30, 30), scales=(.75, 1.25)),
tr.ToTensor()])
# Training dataset and its iterator
db_train = db.DAVIS2016(train=True, db_root_dir=db_root_dir, transform=composed_transforms, seq_name=seq_name)
trainloader = DataLoader(db_train, batch_size=p['trainBatch'], shuffle=True, num_workers=1)
# Testing dataset and its iterator
db_test = db.DAVIS2016(train=False, db_root_dir=db_root_dir, transform=tr.ToTensor(), seq_name=seq_name)
testloader = DataLoader(db_test, batch_size=1, shuffle=False, num_workers=1)
num_img_tr = len(trainloader)
num_img_ts = len(testloader)
loss_tr = []
aveGrad = 0
Done initializing train_seqs Dataset
Done initializing val_seqs Dataset
2.3 开始在线学习
默认训练1000epoch,总耗时约5分钟
print("Start of Online Training, sequence: " + seq_name)
start_time = timeit.default_timer()
# Main Training and Testing Loop
for epoch in range(0, nEpochs):
# One training epoch
running_loss_tr = 0
np.random.seed(seed + epoch)
for ii, sample_batched in enumerate(trainloader):
inputs, gts = sample_batched['image'], sample_batched['gt']
# Forward-Backward of the mini-batch
inputs.requires_grad_()
inputs, gts = inputs.to(device), gts.to(device)
outputs = net.forward(inputs)
# Compute the fuse loss
loss = class_balanced_cross_entropy_loss(outputs[-1], gts, size_average=False)
running_loss_tr += loss.item() # PyTorch 0.4.0 style
# Print stuff
if epoch % (nEpochs//20) == (nEpochs//20 - 1):
running_loss_tr /= num_img_tr
loss_tr.append(running_loss_tr)
print('[Epoch: %d, numImages: %5d]' % (epoch+1, ii + 1))
print('Loss: %f' % running_loss_tr)
# writer.add_scalar('data/total_loss_epoch', running_loss_tr, epoch)
# Backward the averaged gradient
loss /= nAveGrad
loss.backward()
aveGrad += 1
# Update the weights once in nAveGrad forward passes
if aveGrad % nAveGrad == 0:
# writer.add_scalar('data/total_loss_iter', loss.item(), ii + num_img_tr * epoch)
optimizer.step()
optimizer.zero_grad()
aveGrad = 0
# Save the model
if (epoch % snapshot) == snapshot - 1 and epoch != 0:
torch.save(net.state_dict(), os.path.join(save_dir, seq_name + '_epoch-'+str(epoch) + '.pth'))
stop_time = timeit.default_timer()
print('Online training success, model saved at', os.path.join(save_dir, seq_name + '_epoch-'+str(epoch) + '.pth'))
print('Online training time: ' + str(stop_time - start_time))
此处输出较长,省略
2.4 测试模型
# Testing Phase
if vis_res:
import matplotlib.pyplot as plt
plt.close("all")
plt.ion()
f, ax_arr = plt.subplots(1, 3)
save_dir_res = os.path.join(save_dir, 'Results', seq_name) # 图片测试结果保存路径
if not os.path.exists(save_dir_res):
os.makedirs(save_dir_res)
print('Testing Network')
with torch.no_grad(): # PyTorch 0.4.0 style
# Main Testing Loop
for ii, sample_batched in enumerate(testloader):
img, gt, fname = sample_batched['image'], sample_batched['gt'], sample_batched['fname']
# Forward of the mini-batch
inputs, gts = img.to(device), gt.to(device)
outputs = net.forward(inputs)
for jj in range(int(inputs.size()[0])):
pred = np.transpose(outputs[-1].cpu().data.numpy()[jj, :, :, :], (1, 2, 0))
pred = 1 / (1 + np.exp(-pred))
pred = np.squeeze(pred)
# Save the result, attention to the index jj
sm.imsave(os.path.join(save_dir_res, os.path.basename(fname[jj]) + '.png'), pred)
if vis_res:
img_ = np.transpose(img.numpy()[jj, :, :, :], (1, 2, 0))
gt_ = np.transpose(gt.numpy()[jj, :, :, :], (1, 2, 0))
gt_ = np.squeeze(gt)
# Plot the particular example
ax_arr[0].cla()
ax_arr[1].cla()
ax_arr[2].cla()
ax_arr[0].set_title('Input Image')
ax_arr[1].set_title('Ground Truth')
ax_arr[2].set_title('Detection')
ax_arr[0].imshow(im_normalize(img_))
ax_arr[1].imshow(gt_)
ax_arr[2].imshow(im_normalize(pred))
plt.pause(0.001)
# writer.close()
print('Test end')
print('Results saved at', save_dir_res)
Testing Network
/home/ma-user/anaconda3/envs/Pytorch-1.0.0/lib/python3.6/site-packages/ipykernel_launcher.py:29: DeprecationWarning: `imsave` is deprecated!
`imsave` is deprecated in SciPy 1.0.0, and will be removed in 1.2.0.
Use ``imageio.imwrite`` instead.
Test end
Results saved at ./video_object_segmention/OSVOS-PyTorch/./models/Results/flamingo
2.5 查看视频分割结果
src_dir = './video_object_segmention/OSVOS-PyTorch/DAVIS_2016/JPEGImages/480p/flamingo'
result_dir = './video_object_segmention/OSVOS-PyTorch/./models/Results/flamingo'
files = os.listdir(result_dir)
files.sort()
for file_name in files:
clear_output(wait=True)
src_img = cv2.imread(os.path.join(src_dir, file_name.split('.')[0] + '.jpg'))
result_img = cv2.imread(os.path.join(result_dir, file_name))
src_img = cv2.resize(src_img, (416, 256), interpolation=cv2.INTER_AREA)
result_img = cv2.resize(result_img, (416, 256), interpolation=cv2.INTER_AREA)
cv2.putText(src_img, 'id: ' + str(file_name.split('.')[0]), (15, 15), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2) # 画frame_id
cv2.putText(result_img, 'id: ' + str(file_name.split('.')[0]), (15, 15), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2) # 画frame_id
img_show = np.hstack((src_img, np.zeros((256, 20, 3), dtype=src_img.dtype), result_img))
display(Image(data=cv2.imencode('.jpg', img_show)[1]))
time.sleep(0.04)
print('end')

end
可以从上面的分割结果看出,目标大概是能被分割的,但是细节部分还存在一些差异,特别是目标之外的区域也被分割了
3. 视频物体分割的应用
如果你已经得到了一个视频的物体分割结果,那么可以用来做什么呢?
视频物体分割是一项广泛使用的技术,电影电视特效、短视频直播等可以用该技术将场景中的前景从背景中分离出来,通过修改或替换背景,可以将任务设置在现实不存在或不易实现的场景、强化信息的冲击力。传统方式可通过视频图像的手工逐帧抠图方式(比如,摄影在带绿幕的专业摄影棚环境摄制,后期特效完成背景移除切换,如下图所示),比如《复仇者联盟》《美国队长》《钢铁侠》等通过专业影视处理软件加入各种逼真的特效,让影片更加有趣,更加震撼。

再比如华为Mate 20系列手机新增的人像留色功能,能够在录像过程中,实时识别出人物的轮廓,然后通过AI优化只保留人物衣服、皮肤、头发的颜色,将周边景物全部黑白化,如此一来使人物主体更加突出,打造大片既视感。这种人像留色功能就是使用了视频物体分割的技术,将人物从视频中分割出来,再保留其色彩。


接下来,我们将实现视频抠图的另一种应用:将某个目标从视频中去掉,仿佛该目标从来没在视频中出现过一样。本案例采用的视频抠图算法是Deep Flow-Guided Video Inpainting
3.1 准备代码和数据
相关代码、数据和模型都已准备好存放在OBS中,执行下面一段代码即可将其拷贝到Notebook中。
import os
import subprocess
import moxing as mox
print('Downloading datasets and code ...')
if not os.path.exists('./video_object_segmention/Deep-Flow-Guided-Video-Inpainting'):
mox.file.copy('s3://modelarts-labs-bj4/notebook/DL_video_object_segmentation/Deep-Flow-Guided-Video-Inpainting.zip',
'./video_object_segmention/Deep-Flow-Guided-Video-Inpainting.zip')
p1 = subprocess.run(['cd ./video_object_segmention/;unzip Deep-Flow-Guided-Video-Inpainting.zip;rm Deep-Flow-Guided-Video-Inpainting.zip'],
stdout=subprocess.PIPE, shell=True, check=True)
if os.path.exists('./video_object_segmention/Deep-Flow-Guided-Video-Inpainting'):
print('Download success')
else:
raise Exception('Download failed')
else:
print('Download success')
INFO:root:Using MoXing-v1.17.3-
INFO:root:Using OBS-Python-SDK-3.20.7
Downloading datasets and code ...
Download success
3.2 运行算法demo
按照下图打开一个terminal:

然后复制以下四条命令到terminal中粘贴执行,执行过程耗时约2分半:
source activate /home/ma-user/anaconda3/envs/Pytorch-1.0.0
cd `find ~/work/ -name "Deep-Flow-Guided-Video-Inpainting"`
bash install_scripts.sh
#(执行多次,直到将所有numpy删除完全)
pip uninstall numpy -y
pip uninstall numpy -y
pip uninstall numpy -y
pip install numpy
python tools/video_inpaint.py --frame_dir ../OSVOS-PyTorch/DAVIS_2016/JPEGImages/480p/flamingo --MASK_ROOT ../OSVOS-PyTorch/DAVIS_2016/Annotations/480p/flamingo --img_size 128 128 --FlowNet2 --DFC --ResNet101 --Propagation --enlarge_mask
3.3 查看视频抠图结果
执行下面这段代码将看到视频抠图的结果,左侧视频是原视频,右侧视频是去除了一只火烈鸟目标之后的视频,可以看到目标抠除的效果是非常好的,完全不影响背景,仿佛这个目标在视频中就从来没有出现过一样。
注意:由于视频物体分割算法的发展时间较短,离实用场景还有一段距离,所以本案例的视频抠图demo使用的目标分割区域是人工标注的(存储位置在./video_object_segmention/Deep-Flow-Guided-Video-Inpainting/demo/masks),而不是上面的OSVOS算法输出的分割区域。
src_dir = './video_object_segmention/OSVOS-PyTorch/DAVIS_2016/JPEGImages/480p/flamingo'
result_dir = './video_object_segmention/OSVOS-PyTorch/DAVIS_2016/JPEGImages/480p/Inpaint_Res/inpaint_res'
files = os.listdir(result_dir)
files.sort()
for file_name in files:
clear_output(wait=True)
src_img = cv2.imread(os.path.join(src_dir, file_name.split('.')[0] + '.jpg'))
result_img = cv2.imread(os.path.join(result_dir, file_name))
src_img = cv2.resize(src_img, (416, 256), interpolation=cv2.INTER_AREA)
result_img = cv2.resize(result_img, (416, 256), interpolation=cv2.INTER_AREA)
cv2.putText(src_img, 'id: ' + str(file_name.split('.')[0]), (15, 15), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2) # 画frame_id
cv2.putText(result_img, 'id: ' + str(file_name.split('.')[0]), (15, 15), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2) # 画frame_id
img_show = np.hstack((src_img, np.zeros((256, 20, 3), dtype=src_img.dtype), result_img))
display(Image(data=cv2.imencode('.jpg', img_show)[1]))
time.sleep(0.02)
print('end')

end
参考资料
https://davischallenge.org/index.html
https://github.com/kmaninis/OSVOS-PyTorch
https://github.com/nbei/Deep-Flow-Guided-Video-Inpainting
A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation

- 点赞
- 收藏
- 关注作者
评论(0)