使用CenterFace实现人脸贴图

使用CenterFace实现人脸贴图
注意事项
-
本案例使用AI引擎:MindSpore-1.3.0;
-
本案例使用 GPU 环境运行,需要切换至对应的硬件环境。请查看《ModelArts JupyterLab 硬件规格使用指南》了解切换硬件规格的方法;
-
如果您是第一次使用 JupyterLab,请查看《ModelArts JupyterLab使用指导》了解使用方法;
-
如果您在使用 JupyterLab 过程中碰到报错,请参考《ModelArts JupyterLab常见问题解决办法》尝试解决问题。
案例内容
1 介绍人脸贴图的原理检测是什么
2 介绍数据集,数据集的图,数据集是什么形态没讲
3 数据的预处理(为什么,怎么做)
4 网络模型的定义和原理
5 metric的原理(为什么用这个metrics,metric的介绍)
6 tensor后处理(后处理步骤,原理)
7 推理(推理部署,最后呈现的结果)
1. 概述
人脸贴图算法一般由在输入图片识别与检测人脸位置的神经网络实现。 人脸检测网络根据手机摄像头的输入图片判断是否有人脸存在以及人脸位置与大小,然后输出人脸目标检测框。本案例使用的CenterFace是一个基于CenterNet网络、可以高精度实时检测人脸的模型,网络结构相对简单,非常适合部署在有内存与算力限制的移动端设备。
以人脸贴图为例,本案例会介绍CenterFace在云端(GPU)与移动端(CPU)的推理应用。
2. 数据集准备
下载WIDERFACE数据集与标注集
http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/
http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/support/eval_script/eval_tools.zip
WIDERFACE 数据集包含32,203张图片、393,703张各种拍摄尺寸、姿势与遮挡程度的人脸。40%数据集为训练集,10%为验证集,50%为测试集。所有数据集图片按照检测难度被分为三类:简单、中等与困难。

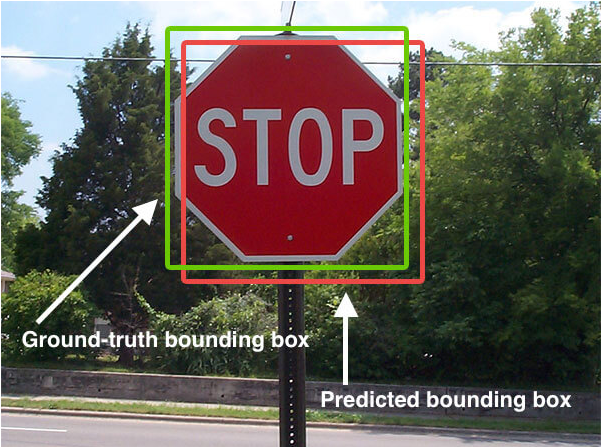
绿色框为标注目标框,红色为模型输出目标框。
WIDERFACE采用IOU(Intersection Over Union)评估目标检测效果。
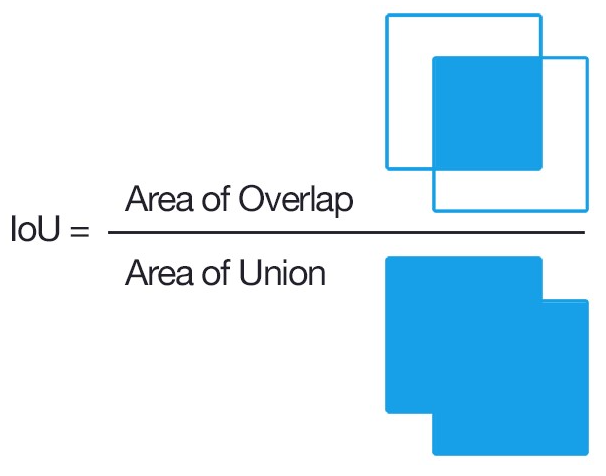
IOU=标注检测框与输出检测框交集面积/标注检测框与输出检测框并集面积。
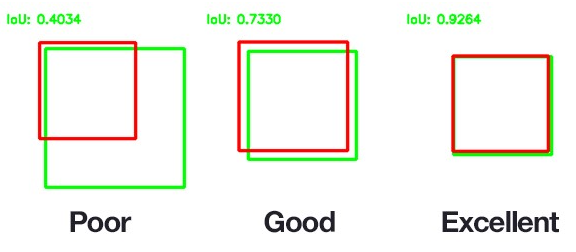
IOU在[0,1]范围之间,比例值越高代表目标检测效果越好。
3. 拷贝项目
import os
import moxing as mox
if not os.path.exists("src"):
mox.file.copy_parallel("obs://modelarts-labs-bj4/case_zoo/centerface_project/centerface/", "./")
INFO:root:Using MoXing-v1.17.3-43fbf97f
INFO:root:Using OBS-Python-SDK-3.20.7
4. 安装mindspore1.3,和必要库
!pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/1.3.0/MindSpore/gpu/x86_64/cuda-10.1/mindspore_gpu-1.3.0-cp37-cp37m-linux_x86_64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install pycocotools
查看当前mindspore版本
import mindspore
print(mindspore.__version__)
5. CenterFace介绍
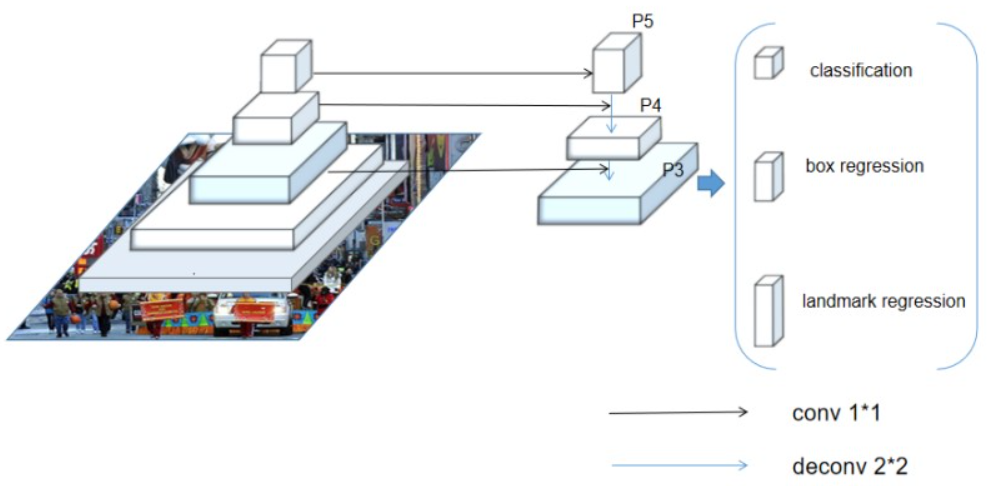
CenterFace的backbone为MobileNetv2网络的downsampling与bottleneck层。bottleneck P2 P3 P5 P7层形成FPN结构作为head输入。
CenterFace在预处理部分首先将输入图片resize为832*832尺寸的图片,然后做标准化处理保证输入数据均值为0且标准差为1。
head通过conv2d+batch normalization分别输出4个部分:location、scale、offset、points, 分别对应4个输出向量:
bbox锚定点位置(x,y)坐标,输出人脸框左上角坐标。
bbox大小(w,h),输出人脸框宽与高。
bbox偏移值 (offset) 输出下采样后框坐标相对输入图片的偏移校正值。
人脸关键点 (x1,y1~x5,y5)输出五组坐标对应双眼、鼻子与嘴位置。
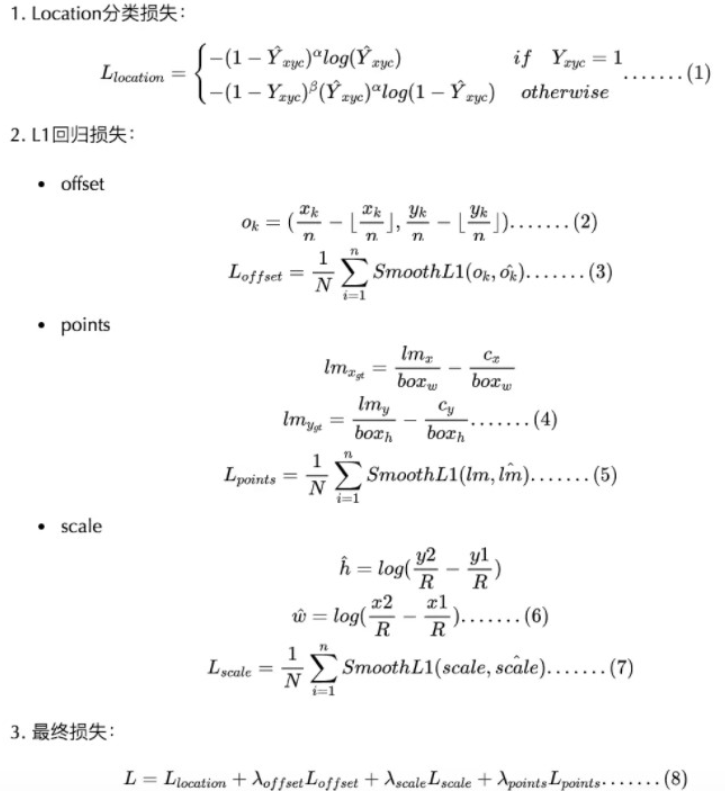
CenterFace采用与CenterNet相同的loss函数,输出四部分的loss对应四个输出向量,分别为:
points、offset、scale使用SmoothL1 loss。
location使用focal BCE loss平衡正负样本数量。
最终loss函数为四部分loss加权和。
CenterFace在后处理部分首先根据输入图片尺寸还原输出框坐标与大小值,然后对锚定点heatmap score做归一化处理### 使其在[0,1]范围内,最后合并多尺度输出向量得到一个尺寸为 16*候选人脸检测框数量的输出detections。
detections[:,:,0:4]为bbox坐标。
detections[:,:,4]为人脸中心点分类得分。
detections[:,:,5:15]为5个人脸关键点坐标(x1,y1)…(x5,y5)。
from src.model_utils.config import config
from src.mobile_v2 import mobilenet_v2
from src.losses import FocalLoss, SmoothL1LossNew, SmoothL1LossNewCMask
import mindspore as ms
import mindspore.nn as nn
from mindspore.common.tensor import Tensor
from mindspore import context
from mindspore.parallel._auto_parallel_context import auto_parallel_context
from mindspore.communication.management import get_group_size
from mindspore.ops import operations as P
from mindspore.ops import functional as F
from mindspore.ops import composite as C
from mindspore.common import dtype as mstype
from mindspore.ops.operations import NPUGetFloatStatus, NPUAllocFloatStatus, NPUClearFloatStatus, ReduceSum, LessEqual
from mindspore.context import ParallelMode
# CenterFace网络NMS输出wrapper类。
class CenterFaceWithNms(nn.Cell):
"""
CenterFace with nms.
"""
def __init__(self, network):
super(CenterFaceWithNms, self).__init__()
self.centerface_network = network
self.config = config
# two type of maxpool
self.maxpool2d = nn.MaxPool2d(kernel_size=3, stride=1, pad_mode='same')
self.topk = P.TopK(sorted=True)
self.reshape = P.Reshape()
self.print = P.Print()
self.test_batch = self.config.test_batch_size
self.k = self.config.K
def construct(self, x):
"""
Construct method.
"""
output_hm, output_wh, output_off, output_kps = self.centerface_network(x)
output_hm_nms, _ = self.maxpool2d(output_hm)
abs_error = P.Abs()(output_hm - output_hm_nms)
abs_out = P.Abs()(output_hm)
error = abs_error / (abs_out + 1e-12)
keep = P.Select()(P.LessEqual()(error, 1e-3), \
P.Fill()(ms.float32, P.Shape()(error), 1.0), \
P.Fill()(ms.float32, P.Shape()(error), 0.0))
output_hm = output_hm * keep
# get topK and index
scores = self.reshape(output_hm, (self.test_batch, -1))
topk_scores, topk_inds = self.topk(scores, self.k)
return topk_scores, output_wh, output_off, output_kps, topk_inds
# CenterFace网络建构类。backbone为MobileNetv2 downsampling与bottleneck层。bottleneck P2 P3 P5 P7层形成FPN结构作为head输入。
# head有4个部分:location、scale、offset、points,分别对应bbox锚定点位置、bbox大小、bbox偏移值与人脸关键点。
class CenterfaceMobilev2(nn.Cell):
"""
Mobilev2 based CenterFace network.
Args:
num_classes: Integer. Class number.
feature_shape: List. Input image shape, [N,C,H,W].
Returns:
Cell, cell instance of Darknet based YOLOV3 neural network.
CenterFace use the same structure.
Examples:
yolov3_darknet53(80, [1,3,416,416])
"""
def __init__(self):
super(CenterfaceMobilev2, self).__init__()
self.config = config
self.base = mobilenet_v2()
channels = self.base.feat_channel
self.dla_up = MobileNetUp(channels, out_dim=self.config.head_conv)
self.hm_head = nn.SequentialCell([conv1x1(self.config.head_conv, 1, has_bias=True),
nn.Sigmoid().add_flags_recursive(fp32=True)])
self.wh_head = conv1x1(self.config.head_conv, 2, has_bias=True)
self.off_head = conv1x1(self.config.head_conv, 2, has_bias=True)
self.kps_head = conv1x1(self.config.head_conv, 10, has_bias=True)
def construct(self, x):
x1, x2, x3, x4 = self.base(x)
x = self.dla_up(x1, x2, x3, x4)
output_hm = self.hm_head(x)
output_wh = self.wh_head(x)
output_off = self.off_head(x)
output_kps = self.kps_head(x)
return output_hm, output_wh, output_off, output_kps
def conv1x1(in_channels, out_channels, stride=1, padding=0, has_bias=False):
return nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, has_bias=has_bias,
padding=padding, pad_mode="pad")
def conv3x3(in_channels, out_channels, stride=1, padding=1, has_bias=False):
return nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, has_bias=has_bias,
padding=padding, pad_mode="pad")
def convTranspose2x2(in_channels, out_channels, has_bias=False, weight_init='normal', bias_init='zeros', pad_mode='same', dilation=1): # Davinci devices only support 'groups=1'
return nn.Conv2dTranspose(in_channels, out_channels, kernel_size=2, stride=2, has_bias=False,
weight_init='normal', bias_init='zeros', pad_mode='same', dilation=1)
# Iterative Deep Aggregation module.
class IDAUp(nn.Cell):
"""
IDA Module.
"""
def __init__(self, out_dim, channel):
super(IDAUp, self).__init__()
self.out_dim = out_dim
self.up = nn.SequentialCell([
convTranspose2x2(out_dim, out_dim, has_bias=False, weight_init='normal', bias_init='zeros', pad_mode='same', dilation=1),
nn.BatchNorm2d(out_dim, eps=0.001, momentum=0.9).add_flags_recursive(fp32=True),
nn.ReLU()])
self.conv = nn.SequentialCell([
conv1x1(channel, out_dim),
nn.BatchNorm2d(out_dim, eps=0.001, momentum=0.9).add_flags_recursive(fp32=True),
nn.ReLU()])
def construct(self, x0, x1):
x = self.up(x0)
y = self.conv(x1)
out = x + y
return out
# MobilenetV2 backbone module.
class MobileNetUp(nn.Cell):
"""
Mobilenet module.
"""
def __init__(self, channels, out_dim=24):
super(MobileNetUp, self).__init__()
channels = channels[::-1]
self.conv = nn.SequentialCell([
conv1x1(channels[0], out_dim),
nn.BatchNorm2d(out_dim, eps=0.001).add_flags_recursive(fp32=True),
nn.ReLU()])
self.conv_last = nn.SequentialCell([
conv3x3(out_dim, out_dim),
nn.BatchNorm2d(out_dim, eps=1e-5, momentum=0.99).add_flags_recursive(fp32=True),
nn.ReLU()])
self.up1 = IDAUp(out_dim, channels[1])
self.up2 = IDAUp(out_dim, channels[2])
self.up3 = IDAUp(out_dim, channels[3])
def construct(self, x1, x2, x3, x4): # tuple/list can be type of input of a subnet
x = self.conv(x4) # top_layer, change outdim
x = self.up1(x, x3)
x = self.up2(x, x2)
x = self.up3(x, x1)
x = self.conv_last(x)
return x
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import cv2
import pickle
import sys
import mindspore
from mindspore import Tensor,export
from dependency.centernet.src.lib.external.nms import soft_nms
from dependency.centernet.src.lib.utils.image import get_affine_transform, affine_transform
# 仿射函数。
def transform_preds(coords, center, scale, output_size):
"""
Transform target coords
"""
target_coords = np.zeros(coords.shape)
trans = get_affine_transform(center, scale, 0, output_size, inv=1)
for p in range(coords.shape[0]):
target_coords[p, 0:2] = affine_transform(coords[p, 0:2], trans)
return target_coords
# 输出仿射变换后的预测bbox。
def multi_pose_post_process(dets, c, s, h, w):
"""
Multi pose post process
dets_result: 4 + score:1 + kpoints:10 + class:1 = 16
dets: batch x max_dets x 40
return list of 39 in image coord
"""
# detections=(1,200,16)
ret = []
for i in range(dets.shape[0]):
bbox = transform_preds(dets[i, :, :4].reshape(-1, 2), c[i], s[i], (w, h))
pts = transform_preds(dets[i, :, 5:15].reshape(-1, 2), c[i], s[i], (w, h))
top_preds = np.concatenate([bbox.reshape(-1, 4), dets[i, :, 4:5], pts.reshape(-1, 10)],
axis=1).astype(np.float32).tolist()
ret.append({np.ones(1, dtype=np.int32)[0]: top_preds})
return ret
# centerface推理wrapper类,包含前后处理方法。
class CenterFaceDetector():
"""
Centerface detector
"""
def __init__(self, opt, model):
self.flip_idx = opt.flip_idx
print('Creating model...')
self.model = model
self.mean = np.array(opt.mean, dtype=np.float32).reshape((1, 1, 3))
self.std = np.array(opt.std, dtype=np.float32).reshape((1, 1, 3))
self.max_per_image = 100
self.num_classes = opt.num_classes
self.scales = opt.test_scales
self.opt = opt
self.pause = False
# 前处理使用仿射变换resize输入图片并标准化处理。
def pre_process(self, image, scale, meta=None):
"""
Preprocess method
"""
height, width = image.shape[0:2]
new_height = int(height * scale)
new_width = int(width * scale)
inp_height, inp_width = self.opt.input_h, self.opt.input_w
c = np.array([new_width / 2., new_height / 2.], dtype=np.float32)
s = max(height, width) * 1.0
trans_input = get_affine_transform(c, s, 0, [inp_width, inp_height])
resized_image = cv2.resize(image, (new_width, new_height))
inp_image = cv2.warpAffine(
resized_image, trans_input, (inp_width, inp_height),
flags=cv2.INTER_LINEAR)
inp_image = ((inp_image / 255. - self.mean) / self.std).astype(np.float32)
images = inp_image.transpose(2, 0, 1).reshape(1, 3, inp_height, inp_width)
if self.opt.flip_test:
images = np.concatenate((images, images[:, :, :, ::-1]), axis=0)
meta = {'c': c, 's': s, 'out_height': inp_height // self.opt.down_ratio,
'out_width': inp_width // self.opt.down_ratio}
return images, meta
# 对模型输出进行后处理。
def process(self, images):
"""
Process method
"""
images = Tensor(images)
# test with mindspore model
# hm=(1,200) wh=(1,2,208,208) off=(1,2,208,208) kps=(1,10,208,208) topk_inds=(1,200)
output_hm, output_wh, output_off, output_kps, topk_inds = self.model(images)
# Tensor to numpy
output_hm = output_hm.asnumpy().astype(np.float32)
output_wh = output_wh.asnumpy().astype(np.float32)
output_off = output_off.asnumpy().astype(np.float32)
output_kps = output_kps.asnumpy().astype(np.float32)
topk_inds = topk_inds.asnumpy().astype(np.long)
reg = output_off if self.opt.reg_offset else None
# hm=(1,200) wh=(1,2,208,208) kps=(1,10,208,208) reg=(1,2,208,208) K=200 topk_inds=(1,200)
dets = self.centerface_decode(output_hm, output_wh, output_kps, reg=reg, opt_k=self.opt.K, topk_inds=topk_inds)
return dets
# 对模型输出进行解码并输出检测向量。
# detections[:,:,0:4]为bbox坐标.
# detections[:,:,4]为人脸中心点分类得分。
# detections[:,:,5:15]为5个人脸关键点坐标(x1,y1)...(x5,y5).
def centerface_decode(self, heat, wh, kps, reg=None, opt_k=100, topk_inds=None):
"""
Decode detection bbox
# hm=(1,200) wh=(1,2,208,208) kps=(1,10,208,208) reg=(1,2,208,208) K=200 topk_inds=(1,200)
"""
batch, _, _, width = wh.shape
num_joints = kps.shape[1] // 2
scores = heat
inds = topk_inds
ys_int = (topk_inds / width).astype(np.int32).astype(np.float32)
xs_int = (topk_inds % width).astype(np.int32).astype(np.float32)
reg = reg.reshape(1, 2, -1)
reg_tmp = np.zeros((1, 2, opt_k), dtype=np.float32)
reg_tmp[0, 0, :] = reg[0, 0, inds[0]]
reg_tmp[0, 1, :] = reg[0, 1, inds[0]]
# reg shape is now (1,200,2)
reg = reg_tmp.transpose(0, 2, 1)
xs = xs_int.reshape(batch, opt_k, 1) + reg[:, :, 0:1]
ys = ys_int.reshape(batch, opt_k, 1) + reg[:, :, 1:2]
wh = wh.reshape(batch, 2, -1)
wh_tmp = np.zeros((batch, 2, opt_k), dtype=np.float32)
wh_tmp[0, 0, :] = wh[0, 0, inds[0]]
wh_tmp[0, 1, :] = wh[0, 1, inds[0]]
wh = wh_tmp.transpose(0, 2, 1)
wh = np.exp(wh) * 4.
# (1,200,1)
scores = scores.reshape(batch, opt_k, 1)
bboxes = np.concatenate([xs - wh[..., 0:1] / 2, ys - wh[..., 1:2] / 2, xs + wh[..., 0:1] / 2,
ys + wh[..., 1:2] / 2], axis=2)
clses = np.zeros((batch, opt_k, 1), dtype=np.float32)
kps = np.zeros((batch, opt_k, num_joints * 2), dtype=np.float32)
detections = np.concatenate([bboxes, scores, kps, clses], axis=2) # box:4 + score:1 + kpoints:10 + class:1 = 16
# detections=(1,200,16)
return detections
# 后处理将输出按输入图片尺寸进行转换。
def post_process(self, dets, meta, scale=1):
"""
Post process
"""
dets = dets.reshape(1, -1, dets.shape[2])
dets = multi_pose_post_process(
dets.copy(), [meta['c']], [meta['s']],
meta['out_height'], meta['out_width'])
for j in range(1, self.num_classes + 1):
dets[0][j] = np.array(dets[0][j], dtype=np.float32).reshape(-1, 15)
dets[0][j][:, :4] /= scale
dets[0][j][:, 5:] /= scale
return dets[0]
# 合并多尺度输出结果。
def merge_outputs(self, detections):
"""
Merge detection outputs
"""
results = {}
results[1] = np.concatenate([detection[1] for detection in detections], axis=0).astype(np.float32)
if self.opt.nms or len(self.opt.test_scales) > 1:
soft_nms(results[1], Nt=0.5, method=2)
results[1] = results[1].tolist()
return results
# centerface main entry method. input a single picture and outputs detection results (bbox coordinates).
def run(self, image_or_path_or_tensor, meta=None):
"""
Run method
"""
image = cv2.imread(image_or_path_or_tensor)
detections = []
images, meta = self.pre_process(image, 1, meta) # --1: pre_process
dets = self.process(images) # --2: process
dets = self.post_process(dets, meta, 1) # box:4 + score:1 + kpoints:10 + class:1 = 16 ## --3: post_process
detections.append(dets)
results = self.merge_outputs(detections) # --4: merge_outputs
return {'results': results}
6. 模型微调
在WIDERFACE train数据集选取100张人脸作为微调数据集/dataset/widerface100
更改训练模式,并在微调数据集上运行训练脚本进行微调
python train.py \
--lr=5e-4 \
--per_batch_size=1 \
--is_distributed=0 \
--t_max=140 \
--max_epoch=300 \
--warmup_epochs=0 \
--lr_scheduler=multistep \
--lr_epochs=90,120 \
--weight_decay=0.0000 \
--loss_scale=1024 \
--resume=centerface/centerface_pretrained.ckpt \
--data_dir=widerface100_train/ \
--annot_path=wider_face/annotations/train_wider_face.json \
--device_target="GPU"
"""
Train centerface and get network model files(.ckpt)
"""
import os
import sys
import time
import datetime
import numpy as np
from mindspore import context
from mindspore.context import ParallelMode
from mindspore.nn.optim.adam import Adam
from mindspore.nn.optim.momentum import Momentum
from mindspore.nn.optim.sgd import SGD
from mindspore import Tensor
from mindspore.communication.management import init, get_rank, get_group_size
from mindspore.train.callback import ModelCheckpoint, RunContext
from mindspore.train.callback import CheckpointConfig
from mindspore.train.serialization import load_checkpoint, load_param_into_net
from mindspore.profiler.profiling import Profiler
from mindspore.common import set_seed
from src.utils import AverageMeter
from src.lr_scheduler import warmup_step_lr
from src.lr_scheduler import warmup_cosine_annealing_lr, \
warmup_cosine_annealing_lr_v2, warmup_cosine_annealing_lr_sample
from src.lr_scheduler import MultiStepLR
from src.var_init import default_recurisive_init
from src.centerface import CenterfaceMobilev2
from src.utils import load_backbone, get_param_groups
from src.centerface import CenterFaceWithLossCell, TrainingWrapper
from src.dataset import GetDataLoader
from src.model_utils.config import config
from src.model_utils.moxing_adapter import moxing_wrapper
from src.model_utils.device_adapter import get_device_id
set_seed(1)
dev_id = get_device_id()
context.set_context(mode=context.GRAPH_MODE, device_target=config.device_target,
save_graphs=False, device_id=dev_id, reserve_class_name_in_scope=False)
config.lr = 5e-4
config.per_batch_size = 1
config.is_distributed = 0
config.t_max = 140
config.max_epoch = 3
config.warmup_epochs = 0
config.lr_epochs = 90,120
config.weight_decay = 0.0000
config.loss_scale = 1024
config.resume = "./centerface_pretrained.ckpt"
config.data_dir = "./data/widerface100_train/"
config.annot_path = "./data/annotations/train_wider_face.json"
config.device_target = "GPU"
def convert_training_shape(args_):
"""
Convert training shape
"""
training_shape = [int(args_.training_shape), int(args_.training_shape)]
return training_shape
class InternalCallbackParam(dict):
"""Internal callback object's parameters."""
def __getattr__(self, para_name):
return self[para_name]
def __setattr__(self, para_name, para_value):
self[para_name] = para_value
def modelarts_pre_process():
config.ckpt_path = os.path.join(config.output_path, config.ckpt_path)
if __name__ == "__main__":
print('\ntrain.py config:\n', config)
# init distributed
if config.is_distributed:
init()
config.rank = get_rank()
config.group_size = get_group_size()
# select for master rank save ckpt or all rank save, compatible for model parallel
config.rank_save_ckpt_flag = 0
if config.is_save_on_master:
if config.rank == 0:
config.rank_save_ckpt_flag = 1
else:
config.rank_save_ckpt_flag = 1
# logger
config.outputs_dir = os.path.join(
config.ckpt_path, datetime.datetime.now().strftime('%Y-%m-%d_time_%H_%M_%S'))
if config.need_profiler:
profiler = Profiler(output_path=config.outputs_dir)
loss_meter = AverageMeter('loss')
context.reset_auto_parallel_context()
if config.is_distributed:
parallel_mode = ParallelMode.DATA_PARALLEL
degree = get_group_size()
else:
parallel_mode = ParallelMode.STAND_ALONE
degree = 1
context.set_auto_parallel_context(
parallel_mode=parallel_mode, gradients_mean=True, device_num=degree)
network = CenterfaceMobilev2()
# init, to avoid overflow, some std of weight should be small enough
default_recurisive_init(network)
if config.pretrained_backbone:
network = load_backbone(network, config.pretrained_backbone, config)
print(
'load pre-trained backbone {} into network'.format(config.pretrained_backbone))
else:
print('Not load pre-trained backbone, please be careful')
if os.path.isfile(config.resume):
param_dict = load_checkpoint(config.resume)
param_dict_new = {}
for key, values in param_dict.items():
if key.startswith('moments.') or key.startswith('moment1.') or key.startswith('moment2.'):
continue
elif key.startswith('centerface_network.'):
param_dict_new[key[19:]] = values
else:
param_dict_new[key] = values
load_param_into_net(network, param_dict_new)
print('load_model {} success'.format(config.resume))
else:
print('{} not set/exists or not a pre-trained file'.format(config.resume))
network = CenterFaceWithLossCell(network)
print('finish get network')
# -------------reset config-----------------
if config.training_shape:
config.multi_scale = [convert_training_shape(config)]
# data loader
data_loader, config.steps_per_epoch = GetDataLoader(per_batch_size=config.per_batch_size,
max_epoch=config.max_epoch, rank=config.rank,
group_size=config.group_size,
config=config, split='train')
config.steps_per_epoch = config.steps_per_epoch // config.max_epoch
print('Finish loading dataset')
if not config.ckpt_interval:
config.ckpt_interval = config.steps_per_epoch
# multistep lr scheduler
lr_fun = MultiStepLR(config.lr, config.lr_epochs, config.lr_gamma, config.steps_per_epoch, config.max_epoch,
config.warmup_epochs)
lr = lr_fun.get_lr()
# Adam optimizer
opt = Adam(params=get_param_groups(network),
learning_rate=Tensor(lr),
weight_decay=config.weight_decay,
loss_scale=config.loss_scale)
print("use adam optimizer")
network = TrainingWrapper(network, opt, sens=config.loss_scale)
network.set_train()
if config.rank_save_ckpt_flag:
# checkpoint save
ckpt_max_num = config.max_epoch * config.steps_per_epoch // config.ckpt_interval
ckpt_config = CheckpointConfig(save_checkpoint_steps=config.ckpt_interval,
keep_checkpoint_max=ckpt_max_num)
ckpt_cb = ModelCheckpoint(config=ckpt_config,
directory=config.outputs_dir,
prefix='{}'.format(config.rank))
cb_params = InternalCallbackParam()
cb_params.train_network = network
cb_params.epoch_num = ckpt_max_num
cb_params.cur_epoch_num = 1
run_context = RunContext(cb_params)
ckpt_cb.begin(run_context)
print('config.steps_per_epoch = {} config.ckpt_interval ={}'.format(config.steps_per_epoch,
config.ckpt_interval))
t_end = time.time()
for i_all, batch_load in enumerate(data_loader):
i = i_all % config.steps_per_epoch
epoch = i_all // config.steps_per_epoch + 1
images, hm, reg_mask, ind, wh, wight_mask, hm_offset, hps_mask, landmarks = batch_load
images = Tensor(images)
hm = Tensor(hm)
reg_mask = Tensor(reg_mask)
ind = Tensor(ind)
wh = Tensor(wh)
wight_mask = Tensor(wight_mask)
hm_offset = Tensor(hm_offset)
hps_mask = Tensor(hps_mask)
landmarks = Tensor(landmarks)
loss, overflow, scaling = network(
images, hm, reg_mask, ind, wh, wight_mask, hm_offset, hps_mask, landmarks)
# Tensor to numpy
overflow = np.all(overflow.asnumpy())
loss = loss.asnumpy()
loss_meter.update(loss)
print('epoch:{}, iter:{}, avg_loss:{}, loss:{}, overflow:{}, loss_scale:{}'.format(
epoch, i, loss_meter, loss, overflow, scaling.asnumpy()))
if config.rank_save_ckpt_flag:
# ckpt progress
cb_params.cur_epoch_num = epoch
cb_params.cur_step_num = i + 1 + (epoch-1)*config.steps_per_epoch
cb_params.batch_num = i + 2 + (epoch-1)*config.steps_per_epoch
ckpt_cb.step_end(run_context)
if (i_all+1) % config.steps_per_epoch == 0:
time_used = time.time() - t_end
fps = config.per_batch_size * config.steps_per_epoch * config.group_size / time_used
if config.rank == 0:
print(
'epoch[{}], {}, {:.2f} imgs/sec, lr:{}'
.format(epoch, loss_meter, fps, lr[i + (epoch-1)*config.steps_per_epoch])
)
t_end = time.time()
loss_meter.reset()
if config.need_profiler:
profiler.analyse()
print('==========end training===============')
7. 使用微调得到的模型推理
python test.py \
--is_distributed=0 \
--data_dir=mobile_test_dataset/ \
--test_model=centerface/centerface_finetuned.ckpt \
--ground_truth_mat=wider_face/ground_truth/wider_face_val.mat \
--save_dir='./test_output_widerface100' \
--rank=1 \
--device_id=5 \
--device_target=GPU
# 推理执行脚本。
import os
from os import walk
import sys
import cv2
import time
import datetime
import scipy.io as sio
from mindspore import context
from mindspore.train.serialization import load_checkpoint, load_param_into_net
from mindspore import export,Tensor
from src.var_init import default_recurisive_init
from src.model_utils.config import config
network = CenterfaceMobilev2()
default_recurisive_init(network)
test_model ="./output/centerface_finetuned_0823.ckpt"
param_dict = load_checkpoint(test_model)
param_dict_new = {}
for key, values in param_dict.items():
if key.startswith('moments.') or key.startswith('moment1.') or key.startswith('moment2.'):
continue
elif key.startswith('centerface_network.'):
param_dict_new[key[19:]] = values
else:
param_dict_new[key] = values
load_param_into_net(network, param_dict_new)
print('load_model {} success'.format(test_model))
network = CenterFaceWithNms(network)
network.set_train(False)
print('finish get network')
input_img = "./data/widerface100_train/9_Press_Conference_Press_Conference_9_194.jpg"
ground_truth_mat = sio.loadmat("./data/ground_truth/wider_face_val.mat")
event_list = ground_truth_mat['event_list']
file_list = ground_truth_mat['file_list']
save_path = config.save_dir+ '/'
detector = CenterFaceDetector(config, network)
dets = detector.run(input_img)['results'][1][0]
x1, y1, x2, y2, s = dets[0], dets[1], dets[2], dets[3], dets[4]
print("CenterFace output")
print(x1, y1, (x2 - x1 + 1), (y2 - y1 + 1), s)
image_cv2 = cv2.imread(input_img)
# cv2.imshow('output',image_cv2)
cv2.rectangle(image_cv2, (int(x1), int(y1)), (int(x2-y1+1), int(y2-y1+1)), (255, 0, 0), 5)
cv2.imwrite("output_cv2.jpg", image_cv2)

- 点赞
- 收藏
- 关注作者
评论(0)