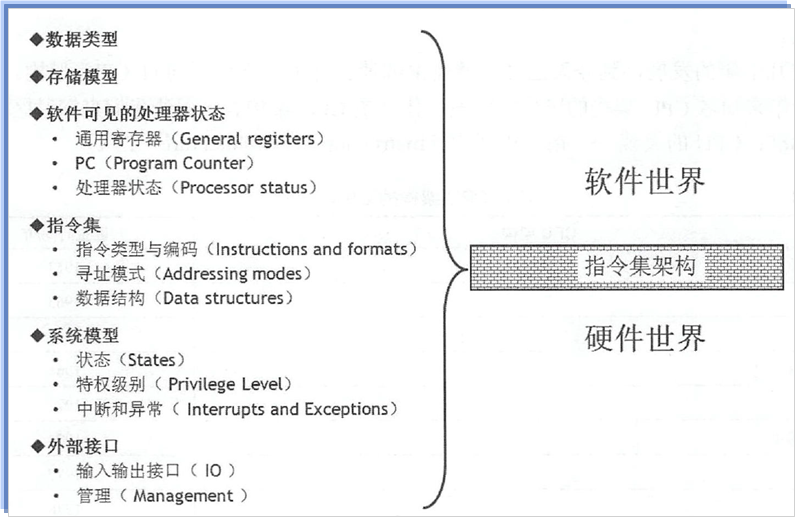
嵌入式:ARM体系结构详解

指令集与指令集架构
- 指令:就是指挥计算机工作的命令,程序就是一系列按一定顺序排列的指令,计算机就是通过执行程序中的指令来完成工作的。
- 指令集:就是CPU中用来计算和控制计算机系统的一套指令的集合, 每一种CPU在设计时就要规定好它能够执行的一系列的指令系统。在计算机硬件中,每条指令都有与之对应的硬件电路相对应,指令执行的过程,就是这些硬件有序工作的过程。
- 指令集架构,有时简称为“架构”或者称为“处理器架构”,是处理器设计时制定的指令集以及与指令集相关的数据类型定义、数据存取方式等内容的一系列规划方案。
一套指令集架构,可以使用不同的处理器硬件实现方案来设计不同性能的处理器(比如多少nm的工艺)。某种处理器的具体硬件实现方案称为微架构( Microarchitecture )。
不同的微架构实现可能造成性能与成本的差异,但是,软件无须做任何修改便可以完全运行在任何一款遵循同一指令集架构实现的处理器上。
因此,指令集架构可以理解为一个抽象层,如下图所示: 
主要计算机指令集架构
PC及服务器领域
-
Intel: x86—CISC
-
SUN: Sparc —-RISC
-
IBM等:Power — RISC
嵌入式领域
- ARM——RISC
- MIPS——RISC
新生代
- RISC-v
ARM体系结构的演变
ARM发展的历程
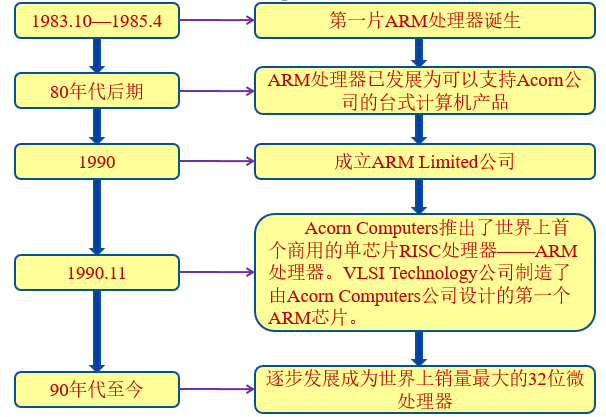
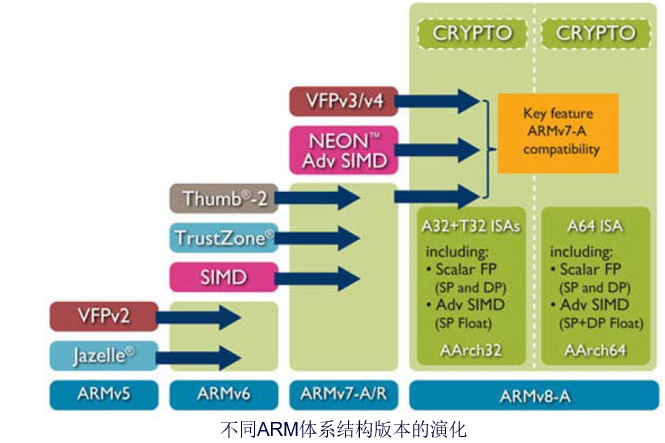
ARM体系结构从最初开发到现在有了很大的改进,并仍在完善和发展。
为了清楚地表达每个ARM应用实例所使用的指令集,ARM公司定义了8种主要的ARM指令集体系结构版本,以版本号V1~V8表示。
-
版本1,本版本包括下列指令:
该版架构只在原型机ARM1出现过,只有26位的寻址空间64MB,没有用于商业产品。
基于字节,字和多字的存储器访问操作指令**(Load/Store);
子程序调用指令BL在内的跳转指令;
完成系统调用的软件中断指令SWI**。 -
版本2 ,该版架构对V1版进行了扩展,例如ARM2和ARM3(V2a)架构。包含了对32位乘法指令和协处理器指令的支持。
版本2a是版本2的变种,ARM3芯片采用了版本2a,是第一片采用片上Cache的ARM处理器。
同样为26位寻址空间,寻址空间仍为:64MB。现在已经废弃不再使用。
V2版架构与版本V1相比,增加了以下功能:
乘法和乘加指令;
支持协处理器操作指令;
快速中断模式;
SWP/SWPB的最基本存储器与寄存器交换指令; -
版本3较以前的版本发生了大的变化
地址空间扩展到了32位(4GB),但除了版本3G外的其他版本是向前兼容的,也支持26位的地址空间;
分开的当前程序状态寄存器CPSR(Current Program Status Register)和备份的程序状态寄存器SPSR(Saved Program Status Register),SPSR用于在程序异常中断时保存被中断的程序状态;
增加了三种异常模式,使操作系统代码可以方便地使用数据访问中止异常、指令预取中止异常和未定义指令异常;增加了MRS指令和MSR指令用于完成对CPSR和SPSR寄存器的读写。修改了原来的从异常中返回的指令。 -
版本4。与版本3相比,版本4增加了下列指令
有符号、无符号的半字和有符号字节的load和store指令。
增加了T变种,处理器可以工作于Thumb状态,在该状态下的指令集是16位的Thumb指令集。
增加了处理器的特权模式。在该模式下,使用的是用户模式下的寄存器。
完善了软件中断SWI指令的功能;
把一些未使用的指令空间捕获为未定义指令
V4版架构是目前应用最广的ARM体系结构之一,ARM7、ARM8、ARM9和StrongARM都采用该架构。 -
版本5主要由两个变型版本5T、5TE组成
相比与版本4,版本5的指令集有了如下的变化:
提高了T变种中ARM/Thumb混合使用的效率。
增加前导零记数(CLZ)指令,该指令可使整数除法和中断优先级排队操作更为有效;
带有链接和交换的转移BLX指令;
BRK中断指令;
增加了数字信号处理指令(V5TE版); 为协处理器增加更多可选择的指令;
改进了ARM/Thumb状态之间的切换效率;
E—增强型DSP指令集,包括全部算法操作和16位乘法操作;
J----支持新的JAVA,提供字节代码执行的硬件和优化软件加速功能。 -
V6版架构是2001年发布的,首先在2002年春季发布的ARM11处理器中使用。在降低耗电量地同时,还强化了图形处理性能。通过追加有效进行多媒体处理的SIMD(Single Instruction, Multiple Data,单指令多数据 )功能,将语音及图像的处理功能提高到了原型机的4倍。
此架构在V5版基础上增加了以下功能:
THUMBTM:35%代码压缩;
DSP扩充:高性能定点DSP功能;
JazelleTM:Java性能优化,可提高8倍;
Media扩充:音/视频性能优化,可提高4倍 -
ARM V7版本:基于ARMv7版本的ARM Cortex系列产品由A、R、M三个系列组成,具体分类延续了一直以来ARM面向具体应用设计CPU的思路。
ARMv7定义了3种不同的处理器配置(processor profiles):
- Profile A是面向复杂、基于虚拟内存的OS和应用的
- Profile R是针对实时系统的
- Profile M是针对低成本应用的优化的微控制器的。
所有ARMv7 profiles实现Thumb-2技术,Thumb-2技术比纯32位代码少使用31%的内存,降低了系统开销,同时却能够提供比已有的基于Thumb技术的解决方案高出38%的性能表现。
同时还包括了NEON™技术的扩展提高DSP和多媒体处理吞吐量400% ,并提供浮点支持以满足下一代3D图形和游戏以及传统嵌入式控制应用的需要。
NEON 技术是 ARM Cortex™-A 系列处理器的 128 位 SIMD(单指令,多数据)架构扩展,旨在为消费性多媒体应用程序提供灵活、强大的加速功能,从而显著改善用户体验。它具有 32 个寄存器,64 位宽(双倍视图为 16 个寄存器,128 位宽。)
-
ARM v8:ARM体系结构定义了抽象机器的行为,称为处理元素(processing element),通常缩写为PE。
ARMv8架构支持:
- A 64-bit Execution state, AArch64.
- A 32-bit Execution state, AArch32, 这与以前版本的ARM架构兼容
AArch64是64位执行状态,这意味着地址保存在64位寄存器中,基本指令集中的指令可以使用64位寄存器进行处理。AArch64状态支持A64指令集。
AArch32是32位执行状态,这意味着地址保存在32位寄存器中,基本指令集中的指令使用32位寄存器进行处理。AArch32状态支持T32和A32指令集。
AArch64,64位执行状态:
- 提供31个64位通用寄存器,其中X30用作过程链接寄存器。
提供64位程序计数器(PC)、堆栈指针(SPs)和异常链接寄存器(ELRs)。
为SIMD向量和标量浮点支持提供32个128位寄存器。
提供单个指令集A64
定义了ARMv8异常模型,有四个异常级别,EL0 - EL3,提供了一个执行特权层次结构,
提供对64位虚拟寻址的支持。
定义许多包含PE状态的进程状态(PSTATE)元素。A64指令集包括直接操作各种PSTATE元素的指令
使用表示可以访问寄存器的最低异常级别的后缀来命名每个系统寄存器。
-
AArch32,32位执行状态:
- 提供13个32位通用寄存器,以及一个32位PC、SP和link寄存器(LR)。LR同时用作ELR和过程链接寄存器。其中一些寄存器具有多个存储实例,用于不同的PE模式。
为从Hyp模式返回的异常提供一个ELR。
为高级SIMD向量和标量浮点支持提供32个64位寄存器。
提供两个指令集,A32和T32。
支持基于PE模式的ARMv7-A异常模型,并将其映射到基于异常级别的ARMv8异常模型。
提供对32位虚拟寻址的支持。
定义许多包含PE状态的进程状态(PSTATE)元素。A32和T32指令集包括直接操作各种PSTATE元素的指令,以及使用应用程序状态寄存器(APSR)或当前程序状态寄存器(CPSR)访问PSTATE的指令。
- 提供13个32位通用寄存器,以及一个32位PC、SP和link寄存器(LR)。LR同时用作ELR和过程链接寄存器。其中一些寄存器具有多个存储实例,用于不同的PE模式。
-
这些执行状态支持三个主要指令集:
- A32(或 ARM):32 位固定长度指令集,通过不同架构变体增强部分 32 位架构执行环境现在称为 AArch32。
- T32 (Thumb) 是以 16 位固定长度指令集的形式引入的,随后在引入 Thumb-2 技术时增强为 16 位和 32 位混合长度指令集。部分 32 位架构执行环境现在称为 AArch32。
- A64:提供与 ARM 和 Thumb 指令集类似功能的 32 位固定长度指令集。随 ARMv8-A 一起引入,它是一种 AArch64 指令集。
-
ARMv8架构支持以下整数数据类型:
Byte 8 bits.
Halfword 16 bits.
Word 32 bits.
Doubleword 64 bits.
Quadword 128 bits. -
还支持以下浮点数据类型:
Half-precision
Single-precision
Double-precision

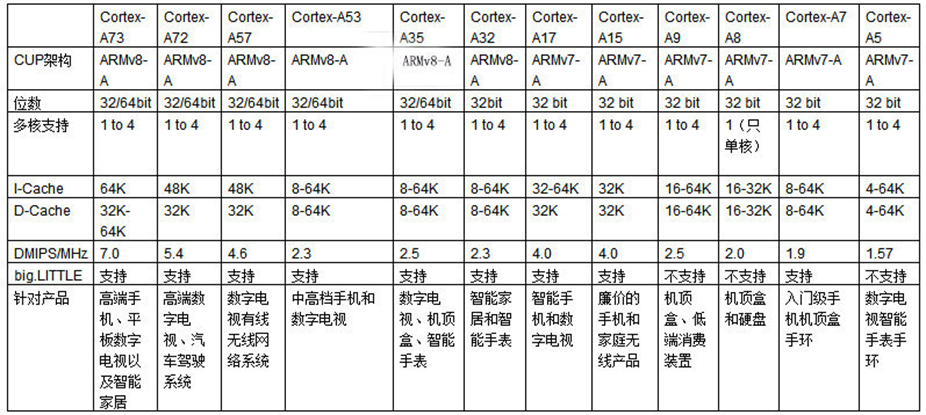
ARM V7与V8的比较
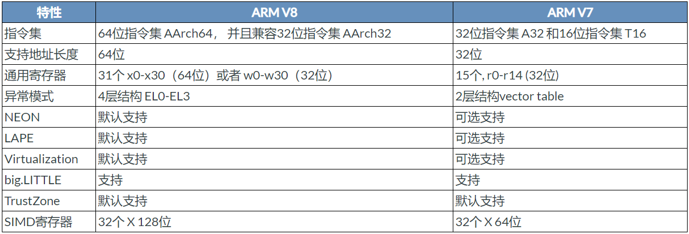
ARM V7与V8的CPU核

- 点赞
- 收藏
- 关注作者
评论(0)