分布式自增ID算法Snowflake

欢迎关注公众号:TestingStudio,学习更多测试开发必备技能
过去的项目开发中,我们常常选用的数据库是mysql,mysql以其体积小、速度快等优势,备受中小型项目的青睐。随着项目数据量的迅速增长,mysql已无法满足我们的项目需求,数据迁移迫在眉睫。经多方对比综合考虑,我们选择了tidb分布式数据库。但是数据迁移后我们遇到一个问题,之前mysql数据库中,我们采用的是自增id主键,可选用的tidb又对自增主键不是很友好,所以我们选用了另一种主键生成方式:Snowflake算法。
算法原理
SnowFlake算法是Twitter设计的一个可以在分布式系统中生成唯一的ID的算法,它可以满足每秒上万条消息ID分配的请求,这些消息ID是唯一的且有大致的递增顺序。
SnowFlake算法产生的ID是一个64位的整型,结构如下:

第一位是标识位,一般不使用,接下来的41位为毫秒级时间差(以1970年为起始时间,41位的长度可以使用69年,从1970-01-01 08:00:00,年 = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69),然后是5位datacenterId(最大支持2^5=32个,二进制表示从00000-11111,也即是十进制0-31),和5位workerId(最大支持2^5=32个,原理同datacenterId),所以datacenterId*workerId最多支持部署1024个节点,最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生2^12=4096个ID序号)。
所有位数加起来共64位,恰好是一个Long型。
当然,实际使用过程中,时间戳、工作机id、序列号的位数是可以根据需要调整的。
优缺点
优点:
01
趋势递增:毫秒数在高位,序列号在低位
02
性能高无单点:本地计算不依赖数据库等第三方
03
使用灵活:三个组成部分的位数可按需求调整
缺点:
01
序列不连续
02
无法控制生成规则(比如序列起始等)
03
强依赖机器时钟,如果时钟回拨,会导致序列重复或者系统不可用
实现代码
#coding: utf-8
import datetime
# 起始时间, 不能改变, 2020-04-10
twepoch = 1586448000000
datacenter_id_bits = 5
worker_id_bits = 15
sequence_id_bits = 2
max_datacenter_id = 1 << datacenter_id_bits
max_worker_id = 1 << worker_id_bits
max_sequence_id = 1 << sequence_id_bits
max_timestamp = 1 << (64 - datacenter_id_bits - worker_id_bits - sequence_id_bits)
def make_snowflake(timestamp_ms, datacenter_id, worker_id, sequence_id, twepoch=twepoch):
"""generate a twitter-snowflake id, based on
:param timestamp_ms: time since UNIX epoch in milliseconds
:param datacenter_id: exec ip
:param worker_id: process id,max is 32767, min is 0
:param sequence_id: thread id, max is 3, min is 0
:param twepoch: start time stamp
:return:
"""
sid = ((int(timestamp_ms) - twepoch) % max_timestamp) << datacenter_id_bits << worker_id_bits << sequence_id_bits
sid += (datacenter_id % max_datacenter_id) << worker_id_bits << sequence_id_bits
sid += (worker_id % max_worker_id) << sequence_id_bits
sid += sequence_id % max_sequence_id
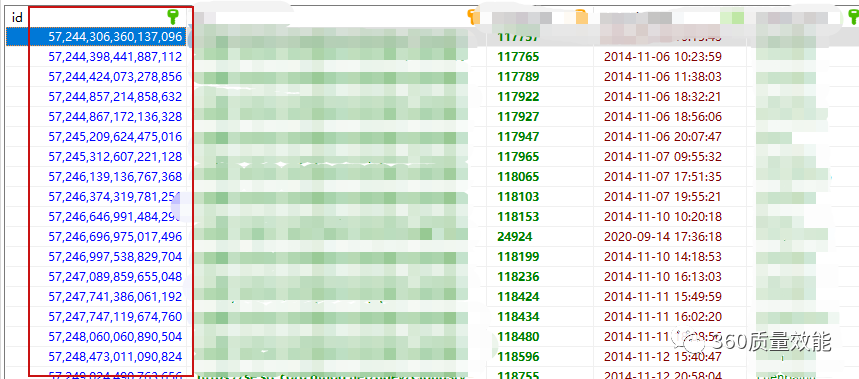
效果
采用Snowflake算法后,数据id可以保持时间递增并且全局唯一。
总结
Snowflake是分布式系统中,用来生成全局唯一ID的一种常用算法。和UUID相比,Snowflake具有简单、占用空间小、有序等优点。但Snowflake算法也有它的弊端,时钟回拨、时钟错乱问题,将是我们程序中需要考虑的问题。

- 点赞
- 收藏
- 关注作者
评论(0)