经典文献阅读之--Deformable DETR

0. 简介
已经好久不写深度学习相关的博客了。但是我觉得DETR值得我重新拾起来进行详细介绍。Deformable DETR作为这两年来最有名的DETR变种之一,当然代码量也是比较多的。这里我们从论文到代码来详细分析Deformable DETR的精华之处。最近两年时间从Attention到NAS再到Transformer,视觉检测行业被Transformer拉到了一个新的高度。而DETR作为Transformer中近两年备受关注的方法,也吸引了很多人争相的去改动。其中比较有名的就是Deformable DETR。DETR 提出在目标检测方法中去除人为组件,也可保持优异性能。但由于 Transformer 注意力模块只能有限地处理图像特征图,它的收敛速度就比较慢,特征空间分辨率有限。为了缓解这些问题,作者提出了 Deformable DETR,其注意力模块只会关注目标框周围少量的关键采样点。Deformable DETR 能够取得比 DETR 更优异的性能(尤其在小物体上)。在 COCO 基准上大量的实验证明了该方法的有效性。
1. 文章贡献
目前的目标检测都使用了很多人为组件,比如 anchor 生成、基于规则的训练目标分配机制、NMS 后处理等。而 Carion 等人提出了 DETR 来去除人为组件,第一次构建了一个完全端到端的目标检测器。利用一个简单的结构,将 CNN 和 Transformer 编码器-解码器结合起来使用。但是DETR也有几个问题:(1) 需要更长的训练时间来收敛。例如,在 COCO 基准上,DETR 需要500个 epochs 才能收敛,要比 Faster R-CNN 慢了10-20倍。(2) DETR 对小目标检测表现相对较差。当前的目标检测器通常使用多尺度特征,从高分辨率特征图上可以检测小目标。而对 DETR 来说,高分辨率特征图意味着高复杂度。这些问题主要可以归结为 Transformer 缺乏处理图像特征图的组件。Transformer 编码器的注意力权重的计算,相对于像素个数来说是平方计算的。因此,要处理高分辨率特征图,其计算量是非常高的,内存复杂度也是非常高的。 而Deformable DETR,通过下述的方法加快了 DETR 的收敛速度,并降低高复杂度问题。
- 它将 deformable 卷积的最佳稀疏空间采样方法和 Transformer 的关系建模能力结合起来。作者使用了(多尺度)deformable 注意力模块替换 Transformer 注意力模块,来处理特征图。
- Deformable DETR 开启了探索端到端目标检测器的机会,因为它收敛很快,内存消耗和计算量都较低。


2. Transformer
在讲Deformable DETR之前,我们需要先了解一下Transformer和DETR。这一节我们主要通过self-attention来介绍Transformer中最主要的Q、K、V三个参数,分别对应查询向量(Query)、键向量(Key)、值向量(Value)。
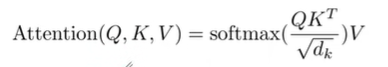
与
权重矩阵相乘得到
, 就是与这个单词相关的查询向量。最终使得输入序列的每个单词的创建一个查询向量
、一个键向量
和一个值向量
。
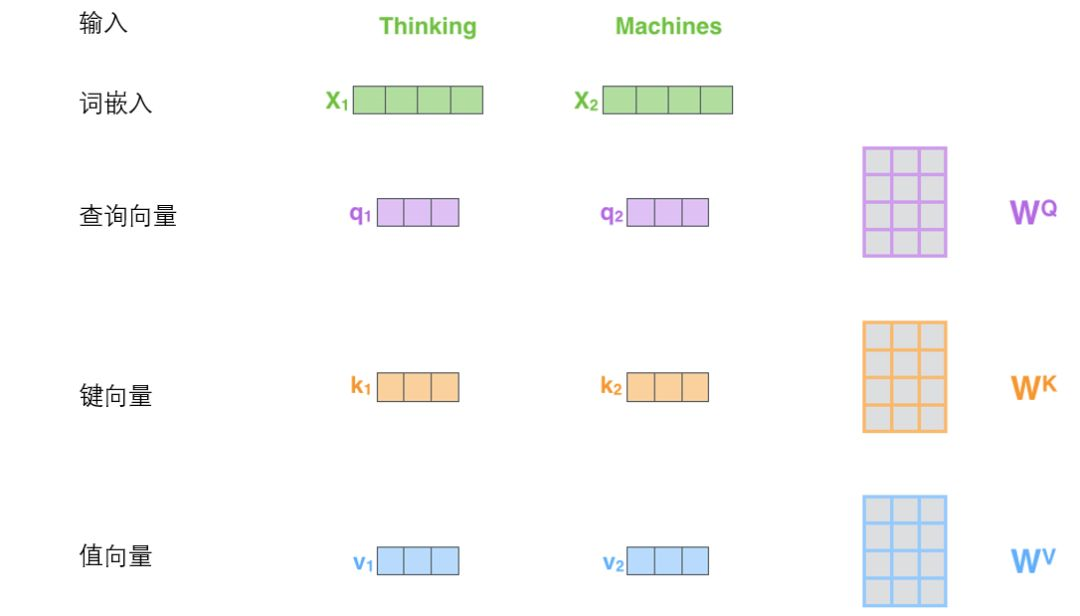
具体步骤为:
-
生成三个向量QKV:对于每个输入 ,通过词嵌入与三个权重矩阵相乘创建三个向量:一个查询向量、一个键向量和一个值向量。
-
计算得分:为每个输入 计算自注意力向量,利用其它输入 对当前 打分,这些分数决定了在编码 的过程中有多重视输入的其它部分。
-
稳定梯度:将分数除以8(默认值),8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定,也可以使用其它值。
-
归一化:通过softmax传递结果,其作用是使所有 的分数归一化,得到的分数都是正值且和为1。这个softmax分数决定了每个单词对编码当下位置(“Thinking”)的贡献。显然,已经在这个位置上的单词将获得最高的softmax分数,但有时关注另一个与当前单词相关的单词也会有帮助。
-
每个值向量乘以softmax分数:为之后将它们求和做准备,达到关注语义上的相关,并弱化其不相关(乘以非常小的小数)。
-
对加权值向量求和:含义:在编码某个 时,将所有其它 的表示(值向量)进行加权求和 ,其权重是通过 的表示(键向量)与被编码 表示(查询向量)的点积并通过softmax得到。即得到自注意力层在该位置的输出。然后即得到自注意力层在该位置的输出(在我们的例子中是对于第一个单词)。
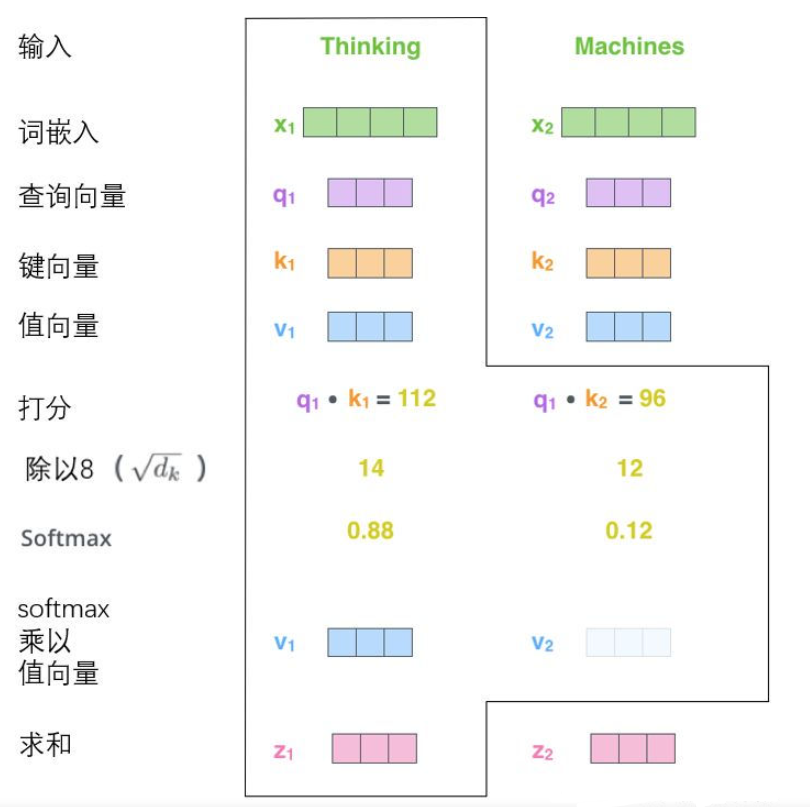
2.1 将张量引入图景
我们已经了解了模型的主要部分,接下来我们看一下各种向量或张量(译注:张量概念是矢量概念的推广,可以简单理解矢量是一阶张量、矩阵是二阶张量。)是怎样在模型的不同部分中,将输入转化为输出的。
像大部分NLP应用一样,我们首先将每个输入单词通过词嵌入算法转换为词向量。每个单词都被嵌入为512维的向量,我们用这些简单的方框来表示这些向量。

如上述已经提到的,一个编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注意力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一个编码器中。
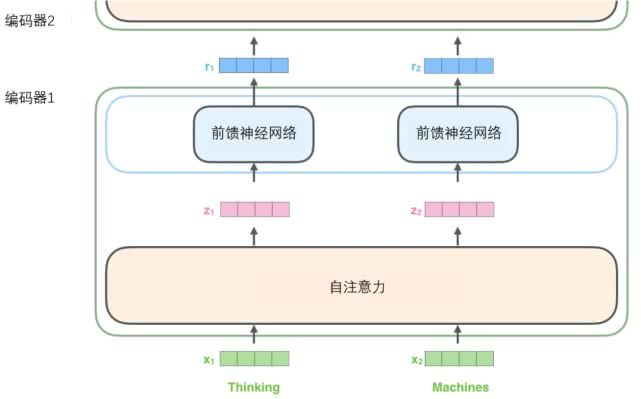
输入序列的每个单词都经过自编码过程。然后,他们各自通过前向传播神经网络——完全相同的网络,而每个向量都分别通过它。
2.2 什么是查询向量、键向量和值向量向量?
它们都是有助于计算和理解注意力机制的抽象概念。请继续阅读下文的内容,你就会知道每个向量在计算注意力机制中到底扮演什么样的角色。
计算自注意力的第二步是计算得分。假设我们在为这个例子中的第一个词“Thinking”计算自注意力向量,我们需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。
这些分数是通过打分单词(所有输入句子的单词)的键向量与“Thinking”的查询向量相点积来计算的。所以如果我们是处理位置最靠前的词的自注意力的话,第一个分数是q1和k1的点积,第二个分数是q1和k2的点积。
最后,由于我们处理的是矩阵,我们可以将步骤2到步骤6合并为一个公式来计算自注意力层的输出。
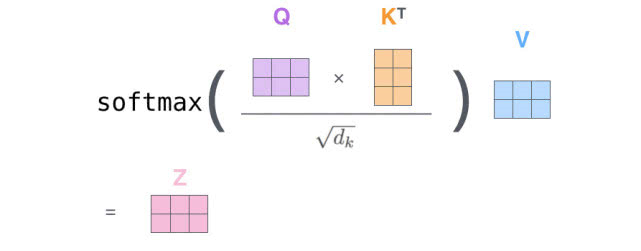
3. Multi-head Transformer
这一节主要围绕Transformer 的 Multi-head 注意力。通过增加一种叫做“多头”注意力(“multi-headed” attention)的机制,论文进一步完善了自注意力层,并在两方面提高了注意力层的性能:
[video(video-HmEqkf1d-1656487223413)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=248709521)(image-https://img-blog.csdnimg.cn/img_convert/c97cba7ff24371e42b360e448f383f68.png)(title-Transformer中Self-Attention以及Multi-Head Attention详解)]

1.它扩展了模型专注于不同位置的能力。在上面的例子中,虽然每个编码都在 中有或多或少的体现,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
2.它给出了注意力层的多个“表示子空间”(representation subspaces)。接下来我们将看到,对于“多头”注意机制,我们有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
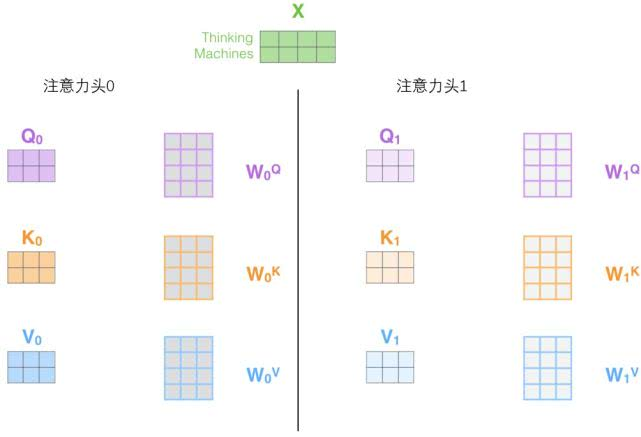
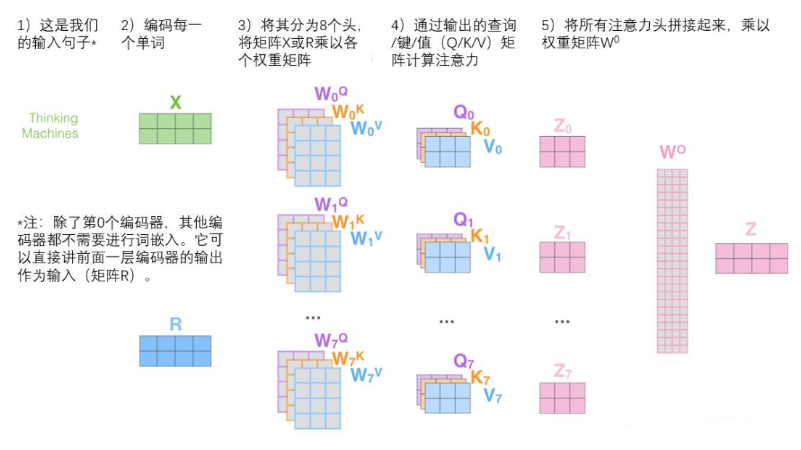
在“多头”注意机制下,我们为每个头保持独立的查询/键/值权重矩阵,从而产生不同的查询/键/值矩阵。和之前一样,我们拿X乘以
矩阵来产生查询/键/值矩阵。如果我们做与上述相同的自注意力计算,只需八次不同的权重矩阵运算,我们就会得到八个不同的Z矩阵。
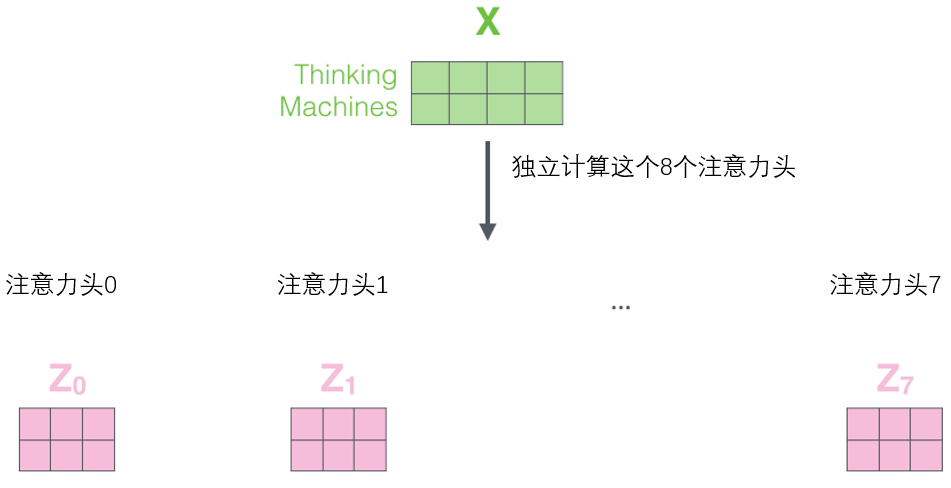
但是,前馈层不需要8个矩阵,它只需要一个矩阵(由每一个单词的表示向量组成)。所以需要把这八个矩阵压缩成一个矩阵,可以直接把这些矩阵拼接在一起,然后用一个附加的权重矩阵
与它们相乘。
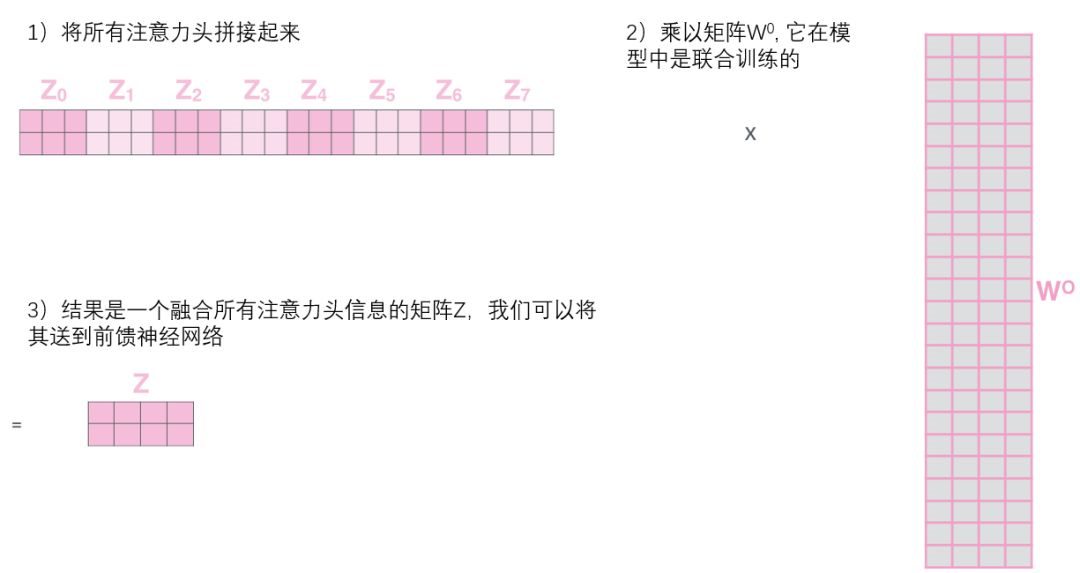
这几乎就是多头自注意力的全部。这确实有好多矩阵,我们试着把它们集中在一个图片中,这样可以一眼看清。这也可以说明我们在多头输入后可以得到相关联的部位对该位置的影响。
3.1 使用位置编码表示序列的顺序
到目前为止,我们对模型的描述缺少了一种理解输入单词顺序的方法。
为了解决这个问题,Transformer为每个输入的词嵌入添加了一个向量。这些向量遵循模型学习到的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。这里的直觉是,将位置向量添加到词嵌入中使得它们在接下来的运算中,能够更好地表达的词与词之间的距离。(这一点在Vision Transfomer中也很重要)
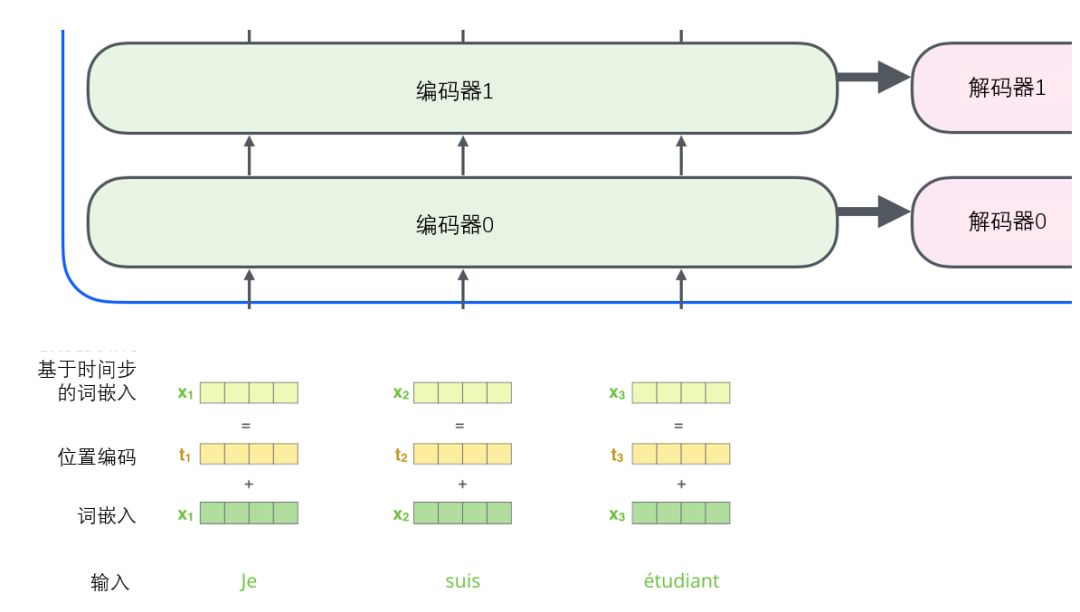
为了让模型理解单词的顺序,我们添加了位置编码向量,这些向量的值遵循特定的模式。如果我们假设词嵌入的维数为4,则实际的位置编码如下:
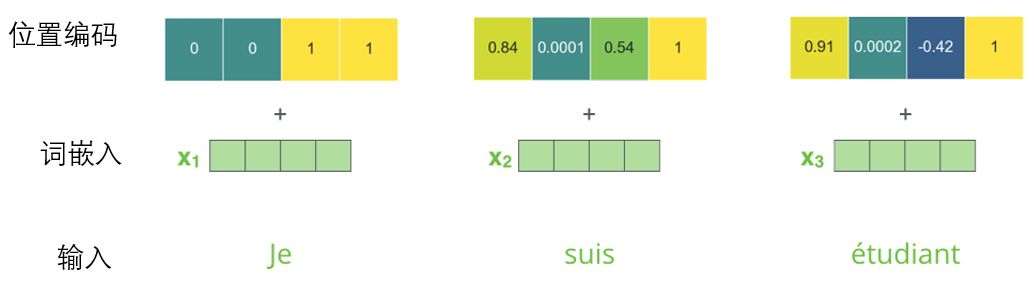
在下图中,每一行对应一个词向量的位置编码,所以第一行对应着输入序列的第一个词。每行包含512个值,每个值介于1和-1之间。我们已经对它们进行了颜色编码,所以图案是可见的。
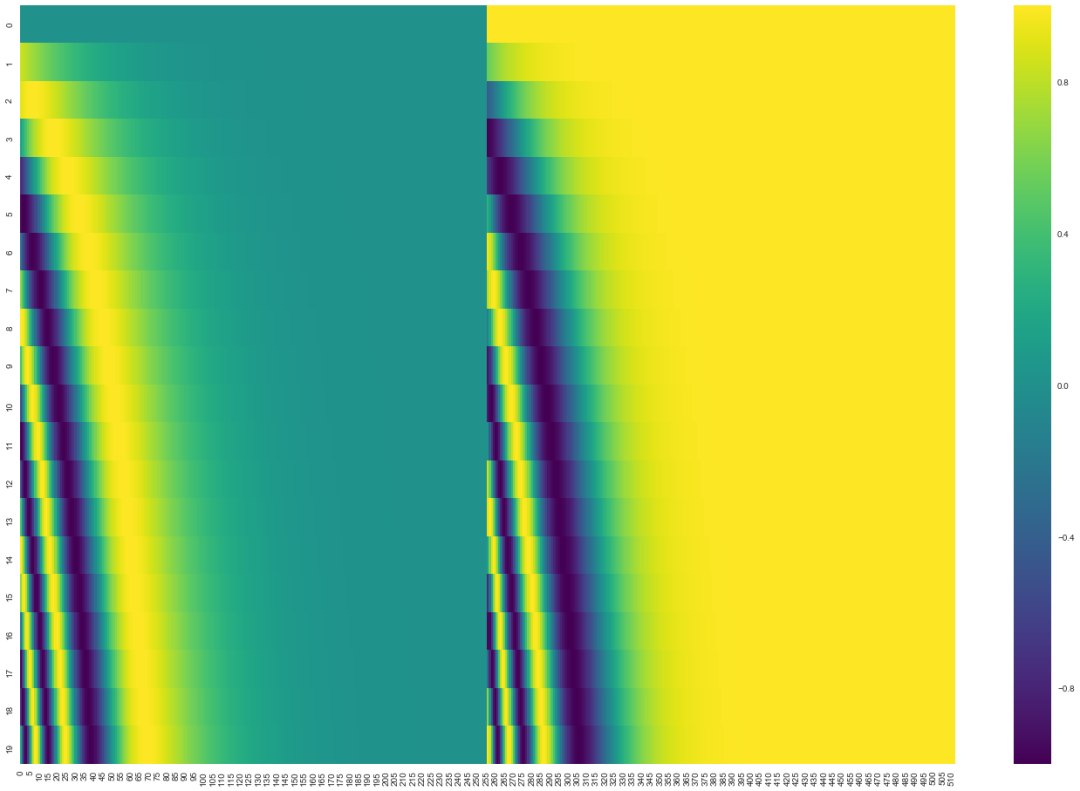
那如何将位置编码和词嵌入整合到一起,这里设置了20字(行)的位置编码实例,词嵌入大小为512(列)。你可以看到它从中间分裂成两半。这是因为左半部分的值由一个函数(使用正弦)生成,而右半部分由另一个函数(使用余弦)生成。然后将它们拼在一起而得到每一个位置编码向量。
原始论文里描述了位置编码的公式(第3.5节)。你可以在 get_timing_signal_1d()函数中看到生成位置编码的代码。这不是唯一可能的位置编码方法。然而,它的优点是能够扩展到未知的序列长度(例如,当我们训练出的模型需要翻译远比训练集里的句子更长的句子时,或者检测到更多的目标时)。
4. DETR
DETR 构建于 Transformer 编码器-解码器之上,结合使用了匈牙利损失,该损失通过二分匹配为每个 ground-truth 边框分配唯一的预测框。李沐的B站账号中也对DETR进行了详细的学习和讲述。
[video(video-2touxO8t-1656482604547)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=596977764)(image-https://img-blog.csdnimg.cn/img_convert/2775335851422995d004c432a56fe5fe.png)(title-DETR 论文精读【论文精读】)]
DEtection TRansformer,其大大简化了目标检测的框架,更直观。其将目标检测任务视为一个图像到集合(image-to-set)的问题,即给定一张图像,模型的预测结果是一个包含了所有目标的无序集合。
…详情请参照古月居

- 点赞
- 收藏
- 关注作者
评论(0)