BEVSegFormer---BEV的语义分割

0. 简介
在阅读了近些年的前视的工作后,发现现在以特斯拉为首的BEV纯视觉语义分割方法目前也越来收到关注,并吸引了大量的研究工作,但是灵活的,不依赖内外参的任意位置安装单个或多个摄像头仍然是一个挑战,而Nullmax就提出了《BEVSegFormer: Bird’s Eye View Semantic Segmentation From Arbitrary Camera Rigs》以用来解决这个问题目前代码还未开源,而另一个BEVFormer团队说22年6月开源,正在持续观望中:https://github.com/zhiqi-li/BEVFormer。
1. 主要工作
这个工作主要是有三块组成部分:
1. a shared backbone
提取多个camera图像的特征,ResNet。
2. transformer encoder
在C3,C4和C5的特征上通过1*1的卷积来得到multi-scale的features,然后和deformable detr一样,分别对各个相机的multi-scale feature施加multi-scale deformable attention,这样就会得到每一个相机的增强版的multi-scale feature
3. BEV Transformer Decoder
decoder的输入只有32倍下采样的feature map。当中包含两部分,一部分是计算BEV queries和multi-camera feature maps之间的cross-attention,一部分是通过一个semantic decoder来解析queries得到BEV的分割结果
2. 详细内容
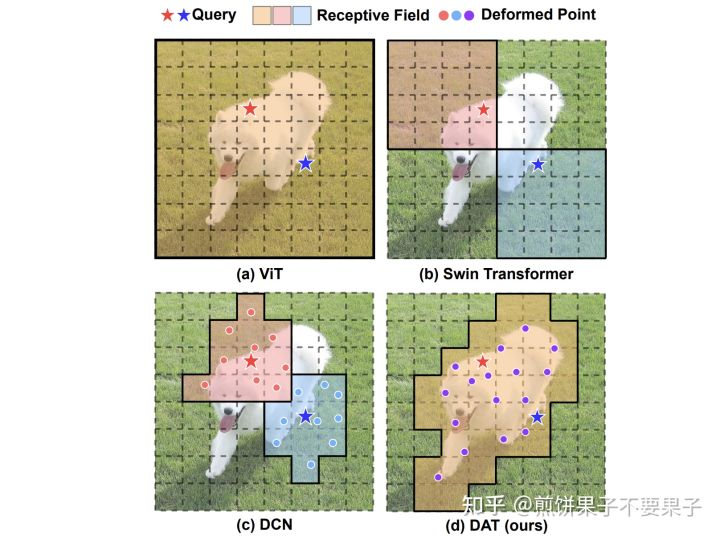
BEVSegFormer,具体来说,该方法的主要框架是先使用一个共享的主干网络来对任意相机的图像特征进行统一编码,实验中选用了ResNet作为实编码。然后就会传入基于变形Transformer的编码器进行增强(即图中Transformer Encoder部分)。在该部分主要使用了Deformable Attention可变性Attention作为框架。Query代表了待查找项,而Defromed Point代表了使用Deformable CNN得到的可变性卷积方法。
在共享主干的c3、c4、c5级特征上应用1×1 卷积运算符。在每个摄像头生成的特征地图上分别应用Deformable Attention模块。它不需要计算致密注意图,只关注参考点附近的一组采样点。transformer编码器为每个摄像头输出增强的多尺度特征。
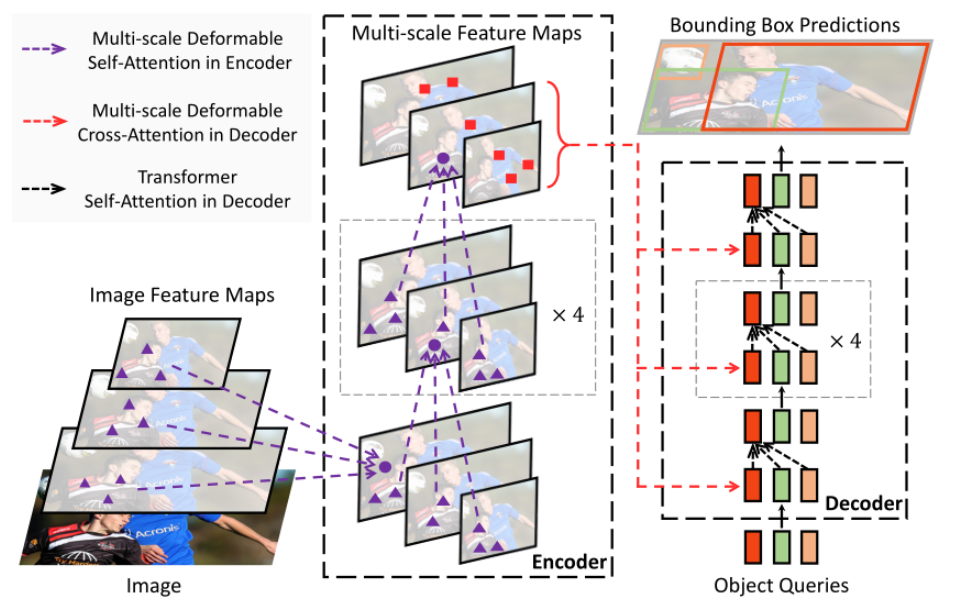
然后我们来看一下解码器,用来处理BEV查询(Query)和多摄像头特征图之间的cross attention,以及一个语义解码器,并将多尺度特征图的最小分辨率(原始输入分辨率的1/32)作为transformer解码器的输入,以用于将查询解析为BEV分割结果。
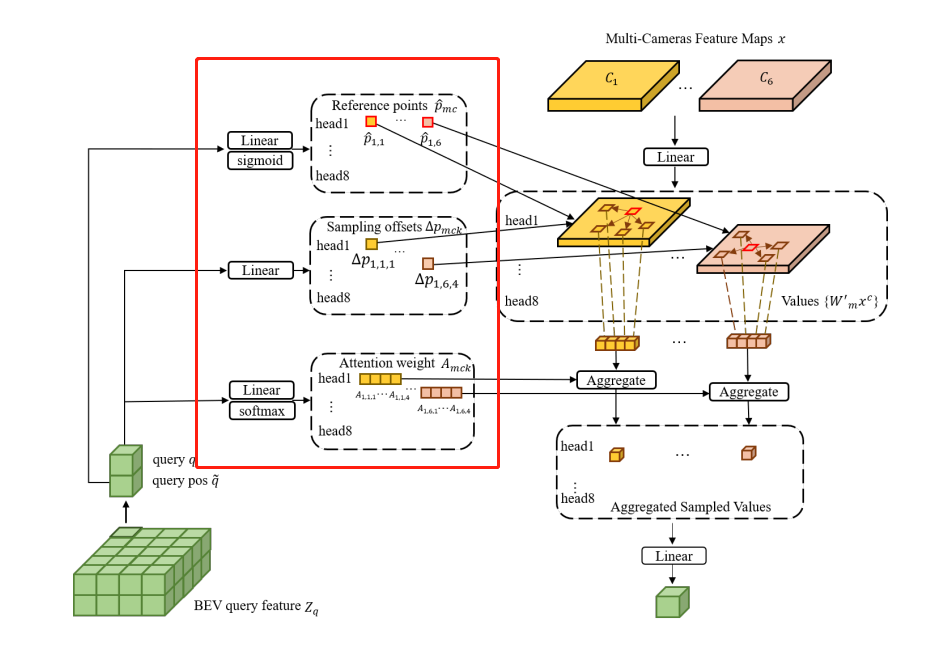
这里的多摄像头Deformable Cross-Attention 模块借鉴了Deformable DETR中的Deformable Cross-Attention 模块,也就是将六幅图通过四层的Deformable Attention进行encoder。并将这些特征的参考点、采样点和Attention权重。
…详情请参照古月居

- 点赞
- 收藏
- 关注作者
评论(0)