深度时空残差网络在城市人流量预测中的应用

@[toc]
摘要
人群流量预测对交通管理和公共安全具有重要意义,同时也受到跨区域交通、事件、天气等复杂因素的影响,具有很大的挑战性。我们提出了一种基于深度学习的方法,称为ST-ResNet,用来集体预测城市每个区域的人群流入和流出。基于时空数据的独特属性,设计了一种端到端的ST-ResNet结构。更具体地说,我们使用残差神经网络框架来建模人群交通的时间距离、周期和趋势属性。针对每个特性,我们设计了残差卷积单元的分支,每个分支都模拟了人群交通的空间特性。ST-ResNet学会基于数据动态聚合三个残差神经网络的输出,给不同的分支和区域分配不同的权重。聚合进一步结合外部因素,如天气和星期几,预测每个地区的人群最终流量。对北京和纽约两种类型的人群流动的实验表明,提出的ST-ResNet优于6种已知的方法。
简介
预测城市的人流量对交通管理和公共安全具有重要意义(Zheng et al. 2014)。例如,在2015年的上海跨年庆典上,大量人群涌入一个狭长地带,导致了灾难性的踩踏事件,造成36人死亡。2016年7月中旬,数百名“精灵宝可梦Go”玩家跑过纽约中央公园,希望抓住一个特别罕见的数字怪物,导致那里发生了危险的踩踏事件。如果可以预测一个地区的人流量,就可以通过使用紧急机制,如实施交通管制、发出警告或提前疏散人员,来减轻或防止这种悲剧。
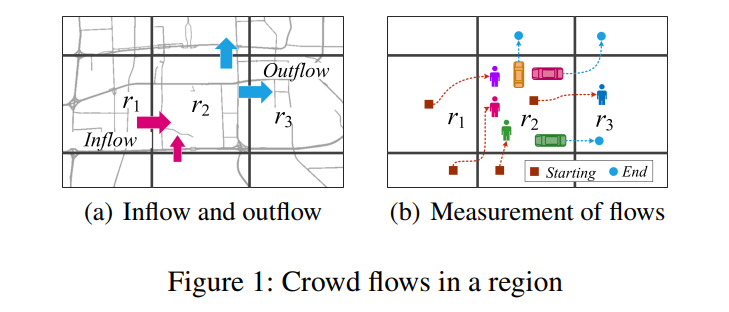
本文预测了两种人群流动类型(Zhang et al. 2016):流入和流出,如图1(a)所示。流入是指在一定时间间隔内从其他地方进入一个地区的人群的总流量。外流指的是在一定时间间隔内离开一个地区前往其他地方的人群的总交通流量。这两种流动都追踪人群在地区之间的转移。了解它们对风险评估和交通管理非常有益。资金流入/流出
可以通过行人数量、附近道路上行驶的汽车数量、乘坐公共交通系统(如地铁、公共汽车)的人数来衡量,如果有数据的话,可以将所有这些综合起来衡量。图1(b)给出了一个例子。我们可以用手机信号来测量行人的数量,可见r2的流入和流出分别为(3;1)分别。同理,利用车辆的GPS轨迹,两种流类型分别为(0;3)。
预备知识
在本节中,我们将简要回顾人流量预测问题(Zhang et al. 2016;Hoang, Zheng, and Singh 2016),并介绍了深度剩余学习(He et al. 2016)。
人流量问题的制定
定义1 (Region (Zhang et al. 2016))根据不同的粒度和语义,位置有很多定义。在本研究中,我们根据经纬度将一个城市划分为I \times J网格地图,其中网格表示一个区域,如图2(a)所示。

定义2(流入/流出(Zhang et al. 2016))设 是 时间间隔上的轨迹集合。对于位于第 行和第 列的网格(i, j),在时间间隔 处人群的流入和流出分别定义为
其中 : 是 中的轨迹, 是地理空间坐标; 表示点 位于网格(i, j)内,反之亦然; 表示集合的基数。
在 时间区间,所有I \times J区域的流入和流出可以表示为一个张量 。流入矩阵如图2(b)所示。
形式上,对于一个由 网格图表示的空间区域上的动力系统,随着时间的推移,每个网格中有两种类型的流动。因此,任何时刻的观测可以用一个张量 表示。
问题1给定历史观察 ,预测
深度残差学习
深度残差学习(He et al. 2015)允许卷积神经网络具有100层甚至超过1000层的超深结构。该方法已经在多个具有挑战性的识别任务中显示了先进的结果,包括图像分类、目标检测、分割和定位(He et al. 2015)。
形式上,具有标识映射的残差单元(He et al. 2016)定义为:
其中 分别为 残差单元的输入和输出;\mathcal{F}是残差函数,例如,两个 卷积层的堆栈(He et al. 2015)。残差学习的核心思想是学习关于 的加性残差函数 (He et al. 2016)。
深度时空残差网络
图3展示了ST-ResNet的体系结构,它由四个主要组件组成,分别建模时间紧密度、周期、趋势和外部影响。如图3的右上部分所示,我们首先使用定义1和定义2中介绍的方法,将流经城市的每个时间间隔的流入和流出分别转化为两个通道的类图像矩阵。然后我们将时间轴分成三个片段,分别表示最近的时间、近历史和遥远的历史。然后将每个时间片段中区间的2通道流矩阵分别输入前三个组件,分别对上述三个时间属性进行建模:接近度、周期和趋势。前三个组成部分与卷积神经网络共享相同的网络结构,然后是残差单元序列。这种结构体现了远近区域之间的空间依赖性。在外部组件中,我们从外部数据集中手动提取一些特征,如天气条件和事件,将它们输入到一个两层完全连接的神经网络中。将前三个分量的输出融合为基于参数矩阵的
,对不同区域不同分量的结果赋予不同的权重。
与外部组件
的输出进一步集成。最后,聚合映射到[−1;1],它在反向传播学习过程中产生比标准逻辑函数更快的收敛(LeCun et al. 2012)。
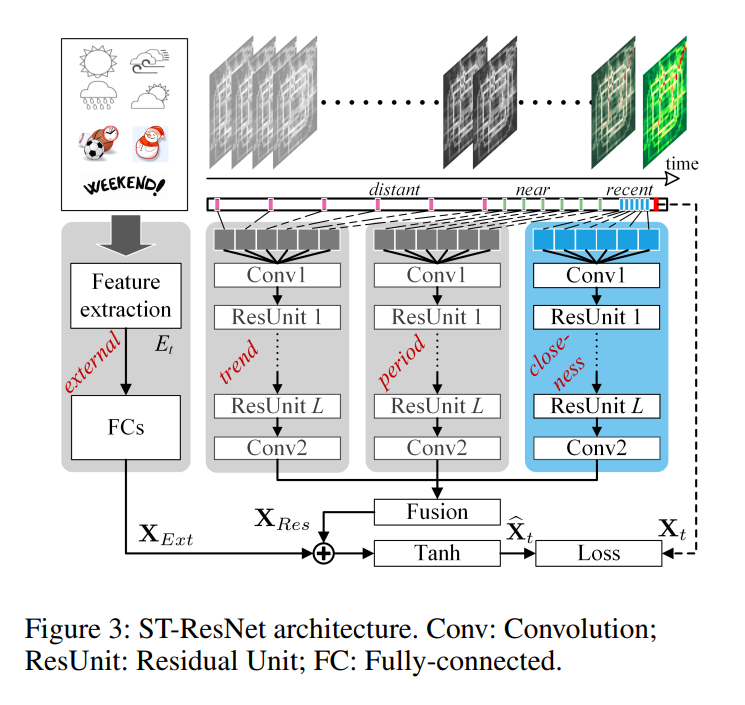
前三个成分的结构
前三个分量(即接近度、周期、趋势)具有相同的网络结构,由卷积和残差单元两个子分量组成,如图4所示。
卷积。 一个城市通常有很大的规模,包含许多不同距离的区域。直观地看,附近区域的人群流动可能会相互影响,卷积神经网络(CNN)可以有效地处理这一问题,它显示出了强大的分层捕获空间结构信息的能力(LeCun et.al.1998)。此外,地铁系统和高速公路连接两个地点的距离很远,导致遥远的地区之间的依赖。为了捕获任何区域的空间依赖性,我们需要设计一个具有许多层的CNN,因为一个卷积只考虑空间上的近依赖性,受其内核大小的限制。在输入和输出具有相同分辨率的视频序列生成任务中也发现了同样的问题(Mathieu, Couprie,和LeCun 2015)。已经引入了几种方法来避免子采样带来的分辨率损失,同时保留远程依赖(Long, Shelhamer,和Darrell 2015)。与经典CNN不同的是,我们不使用子采样,而只使用卷积(Jain et al. 2007)。如图4(a)所示,有三个多层的特征映射,它们通过一些卷积连接起来。我们发现,高层特征图中的一个节点依赖于中层特征图中的九个节点,而中层特征图中的九个节点又依赖于低层特征图中的所有节点(即输入)。这意味着一个卷积自然地捕获空间上的近依赖关系,而一堆卷积可以进一步捕获遥远的甚至城市范围内的依赖关系。
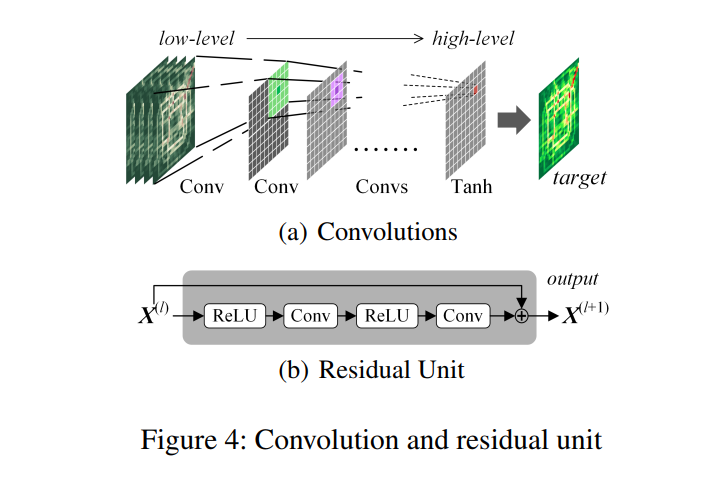
图3的紧密度分量采用了最近时间区间的几个2通道流矩阵来建模时间紧密度依赖。设最近的片段为 ,也称为紧密依赖序列。我们首先将它们与第一个轴(即时间间隔)连接起来,作为一个张量 ,然后进行卷积(即图3所示的Conv1):
其中 表示卷积; 是激活函数,例如整流器 (Krizhevsky, Sutskever, and Hinton 2012); 是第一层的可学习参数。
残差单元。 众所周知,尽管使用了众所周知的激活函数(如ReLU)和正则化技术,但深度卷积网络会损害训练效果(Ioffe和Szegedy 2015;Krizhevsky, Sutskever和Hinton 2012;Nair和Hinton 2010)。另一方面,我们仍然需要一个非常深入的网络来捕获非常大的全市范围的依赖关系。对于一个典型的人群流数据,假设输入大小为32 × 32,并建模全市依赖性(即,高层层中的每个节点依赖于输入的所有节点),它需要超过15个连续的卷积层。为了解决这一问题,我们在模型中使用了残差学习(He et al. 2015),该方法已被证明对于训练超过1000层的超深度神经网络非常有效。
在我们的ST-ResNet中(见图3),我们在Conv1上堆叠L个残差单元如下:
其中 是残差函数(即“ReLU + Convolution”的两个组合,见图4(b)), 包括 残差单元中所有可学习的参数。我们还尝试了在ReLU之前添加的批处理归一化(BN) (Ioffe和Szegedy 2015)。在 残差单元之上,我们添加一个卷积层(即如图3所示的Conv2)。有2个卷积和L个残差单元,图3的紧密度分量的输出是 。
同样,使用上述操作,我们可以构造图3的周期和趋势组件。假设周期片段有l_{p}个时间间隔,周期为p。因此,周期相关序列为 。通过卷积运算和等式2和3中的L个残差单位,周期分量的输出是 。同时,趋势分量的输出为 ,输入为 ,其中 为趋势相关序列的长度,q为趋势span。注意p和q实际上是两种不同类型的周期。在详细的实现中,p等于一天,描述了每日的周期性,q等于一周,揭示了每周的趋势。
外部组件的结构
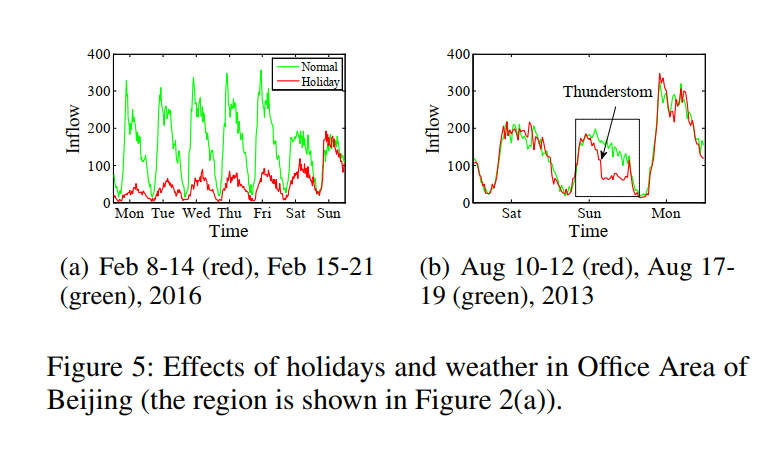
交通流量会受到许多复杂的外部因素的影响,如天气和事件。从图5(a)可以看出,节假日(中国春节)期间的人流量可能与正常工作日的人流量有显著差异。图5(b)显示大雨使办公区域的人流较后一周同日大幅减少。设
为在预测时间区间t上表示这些外部因素的特征向量。在我们的实现中,我们主要考虑天气、节日事件和元数据(例如DayOfWeek、工作日/周末)。详细信息见表1。预测t时间间隔的流量,可以直接得到节日事件和元数据。然而,未来时间间隔t的天气是未知的。相反,可以使用时间间隔t的预报天气或时间间隔
的近似天气。形式上,我们将两个完全连接的层叠加在
上,第一层可以被视为每个子因子的嵌入层,然后是激活层。第二层用于将具有与
相同形状的低维映射到高维。图3的外部组件的输出表示为
,参数为
。
融合
在本节中,我们将讨论如何融合图3中的四个组件。我们首先用基于参数矩阵的融合方法融合前三个分量,然后进一步与外部分量结合。
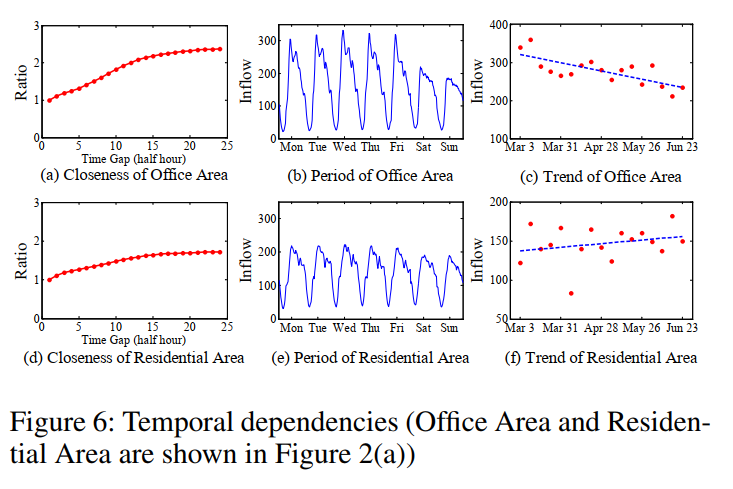
图6(a)和(d)显示了使用表1中北京轨迹数据的比率曲线,其中x轴是两个时间间隔之间的时间差距,y轴是具有相同时间差距的任意两个流入之间的平均比率值。两个不同区域的曲线在时间序列上都表现出经验的时间相关性,即近期时间间隔的流入比遥远时间间隔的流入相关性更强,具有时间上的密切性。这两条曲线的形状不同,说明不同的区域可能有不同的接近特征。图6(b)和(e)描述了7天的所有时间间隔的流入情况。我们可以看到两个地区有明显的日周期性。在办公区域内,工作日的峰值要远远高于周末的峰值。住宅面积在工作日和周末有相似的峰值。图6©和(f)描述了2015年3月至2015年6月周二某个时间段(晚上9:00 -9:30)的流入情况。随着时间的推移,办公区域的流入量逐渐减少,居住区域的流入量逐渐增加。它显示了不同地区的不同趋势。综上所述,两个地区的流入都受到密切程度、时期和趋势的影响,但影响程度可能有很大差异。我们在其他地区也发现了同样的属性,以及它们的流出。
最重要的是,不同区域都受到密切程度、时期和趋势的影响,但影响程度可能不同。在这些观察的启发下,我们提出了一种基于参数矩阵的融合方法。
Parametric-matrix-based融合。我们将图3的前三个组成部分(即接近度、周期、趋势)融合如下
其中 是Hadamard乘积(即元素智慧乘法), 和 分别是可学习的参数,它们分别调节受密切度、周期和趋势影响的程度。
融合外部组件。这里我们直接将前三个组件的输出与外部组件的输出合并,如图3所示。最后,在 时间区间上的预测值,用 表示,定义为
其中 是双曲正切,保证输出值在-1到1之间。
我们的ST-ResNet可以通过最小化预测流量矩阵与真实流量矩阵之间的均方误差,从三个流量矩阵序列和外部因素特征中预测 :
其中 都是ST-ResNet中可学习的参数。
算法和优化
算法1概述了ST-ResNet训练过程。我们首先从原始序列数据(第1-6行)构建训练实例。然后,ST-ResNet通过反向传播和Adam (Kingma and Ba 2014)进行训练(第7-11行)。

实验
设置
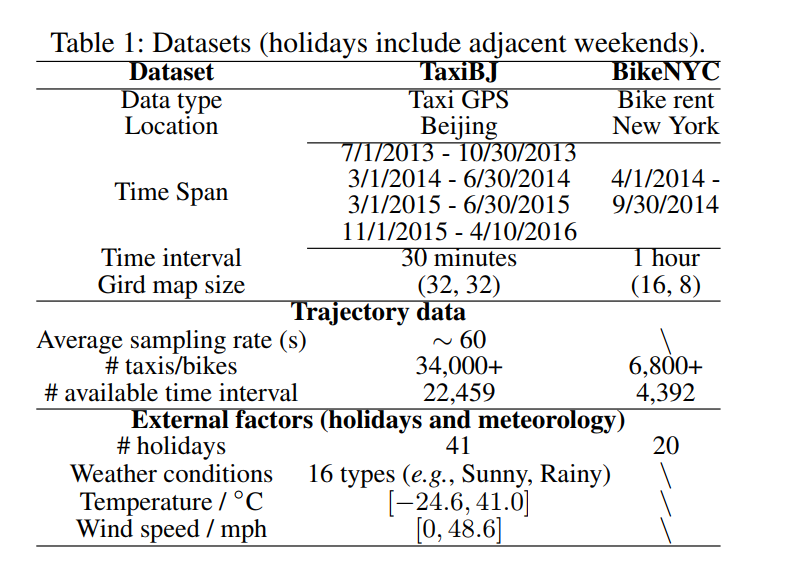
数据集。 我们使用两组不同的数据,如表1所示。每个数据集包含两个子数据集:轨迹和天气,具体如下。
- TaxiBJ:轨迹数据是北京出租车GPS数据和气象数据四个时间段:2013年7月1日- 2013年3月1日- 2014年6月30日,2014年3月1日- 2014年6月30日,2015年3月1日- 2015年6月30日,2015年11月1日- 2016年4月10日。利用定义2,我们得到了两种类型的人群流。我们选择最近四周的数据作为测试数据,之前的所有数据作为训练数据。
- BikeNYC:轨迹数据来自2014年4月1日至9月30日的纽约市自行车系统。行程数据包括:行程持续时间、起讫站编号、起讫时间。数据中选取最近10天作为测试数据,其余10天作为训练数据。
基线。 我们将ST-ResNet与以下6个基线进行比较:
-
HA:我们通过相应时段的历史流入和流出的平均值来预测人群的流入和流出,例如周二上午9:00 -9:30,其对应时段都是所有历史周二上午9:00 -9:30的历史时间间隔。
-
ARIMA:自回归综合移动平均(ARIMA)是一个著名的模型,用于理解和预测时间序列中的未来值。
-
SARIMA:季节性ARIMA。
-
VAR:向量自回归(VAR)是一种更先进的时空模型,它可以捕捉所有流之间的成对关系,但由于参数数量多,计算成本高。
-
ST-ANN:它首先提取空间(附近8个区域的值)和时间(之前的8个时间间隔)特征,然后输入人工神经网络。
-
DeepST (Zhang et al. 2016):基于深度神经网络(DNN)的时空数据预测模型,展示了最先进的人流预测结果。它有4个变体,包括DeepST-C、DeepSTCP、DeepST-CPT和DeepST-CPTM,分别关注不同的时间依赖性和外部因素。
预处理。 在ST-ResNet的输出中,我们使用tanh作为我们的最终激活(见等式5),其范围在-1到1之间。这里,我们使用Min-Max归一化方法将数据扩展到[−1;1]。在评估中,我们将预测值重新调整到正常值,并与groundtruth进行比较。对于外部因素,我们使用onehot编码将元数据(即DayOfWeek, Weekend/Weekday)、节假日和天气条件转换为二进制向量,并使用Min-Max归一化将温度和风速缩放到[0;1]。
Hyperparameters。 我们使用了包括Theano (Theano Development Team 2016)和Keras (Chollet 2015)在内的python库来构建模型。Conv1和所有剩余单元的卷积使用64个大小为3 \乘以3的滤波器,而Conv2使用一个具有2个大小为3 \乘以3的滤波器的卷积。批大小为32。我们选择90 %的训练数据来训练每个模型,剩下的10 %被选为验证集,用于根据最佳验证分数提前停止我们的每个模型的训练算法。之后,我们继续在固定时间的完整训练数据上训练模型(例如,10,100个时间)。在我们的ST-ResNet中有5个额外的超参数,其中p和q分别被经验固定为一天和一周。对于三个相关序列的长度,我们设它们为: 。评估指标:我们通过均方根误差(RMSE)来衡量我们的方法
其中 和 分别为预测值和根据值; 是所有预测值的个数。
结果TaxiBJ
我们首先在TaxiBJ上与其他6个模型进行比较,如表2所示。我们给出了7种具有不同层次和不同因素的ST-ResNet变体。以L12-E为例,它考虑了所有可用的外部因素,有12个残差单元,每个残差单元由两个卷积层组成。我们观察到这7个模型都优于6个基线。与之前的先进模型相比,L12-E-BN将误差降低到16.69,显著提高了精度。

不同成分的影响。 设L12-E为比较模型。
-
残差单元数:L2-E、L4-E和L12E的结果表明,RMSE随着残差单元数的增加而减小。使用残差学习,网络越深,结果越准确。
-
剩余单元的内部结构:我们尝试了三种不同类型的剩余单元。L12-E采用标准残差单元(见图4(b))。与L12-E相比,L12-single-E的Residual Unit只包含1 \mathrm{ReLU}和1个卷积,L12-E- bn的Residual Unit增加了两个批归一层,每个归一层插入到ReLU之前。我们观察到L12-single-E比L12-E差,L12-E- bn最好,证明了批归一化的有效性。
-
外部因素:L12-E考虑外部因素,包括气象数据、节日活动和元数据。如果不是,则模型降级为L12。结果表明,\mathrm{L} 12-\mathrm{E}优于\mathrm{L} 12,说明外界因素总是有利的。
-
基于参数矩阵的融合:与L12-E不同,L12-E- nofusion不使用基于参数矩阵的融合(见Eq. 4)。相反,L12-E- nofusion使用一个简单的方法进行融合,即 。结果表明,误差大大增加,证明了我们提出的基于参数矩阵的融合的有效性。
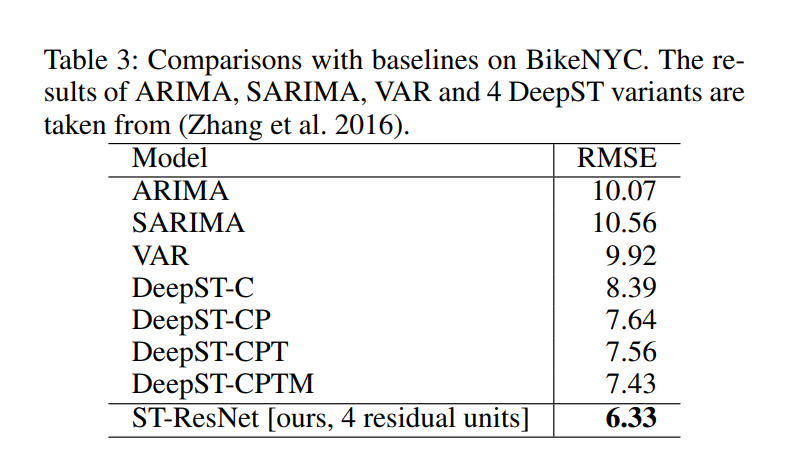
结果BikeNYC
表3显示了我们的模型和BikeNYC上的其他基线的结果。与TaxiBJ不同,BikeNYC由两种不同类型的人群流组成,包括新流和端流(Hoang, Zheng, and Singh 2016)。在这里,我们总共采用4残差单元ST-ResNet,并将元数据视为像DeepST那样的外部特征(Zhang et al. 2016)。ST-ResNet的RMSE相对于这些基线低14.8 %至37.1 %,表明我们提出的模型在其他流量预测任务中具有良好的泛化性能。
相关工作
人群流量预测。此前有一些发表的作品是基于个人的位置历史来预测个人的运动(Fan et al. 2015;Song et al. 2014)。他们主要预测数百万甚至数十亿个人的流动轨迹,而不是一个地区的人群流动总量。这样的任务可能需要巨大的计算资源,对于公共安全的应用场景并不总是必要的。其他一些研究人员的目标是预测道路上的旅行速度和交通量(Abadi, Rajabioun,和Ioannou 2015;Silva, Kang,和Airoldi 2015;Xu等人2014)。其中大多数预测的是单个或多个路段,而不是全市范围内的路段。最近,研究人员开始关注城市尺度的交通流预测(Hoang, Zheng,和Singh 2016;Li et al. 2015)。这两项工作与我们的不同之处是,我们提出的方法自然专注于单个区域而不是城市,他们没有使用基于网格的方法来划分城市,因为基于网格的方法需要更复杂的方法来首先找到不规则的区域。
深度学习。cnn已经成功地应用于各种问题,特别是在计算机视觉领域(Krizhevsky, Sutskever,和Hinton 2012)。剩余学习(He et al. 2015)允许这样的网络有一个非常深的结构。循环神经网络(rnn)已成功用于序列学习任务(Sutskever, Vinyals,和Le 2014)。长期短期记忆(LSTM)的引入使rnn能够学习长期的时间依赖性。然而,这两种神经网络只能捕获空间或时间依赖性。最近,研究者结合上述网络,提出了一种卷积LSTM网络(Xingjian et al.2015),可以同时学习空间和时间依赖性。这样的网络不能模拟非常长期的时间依赖性(例如,周期和趋势),随着深度的增加,训练变得更加困难。
在我们之前的工作(Zhang et al. 2016)中,我们针对时空数据提出了一个基于dnn的通用预测模型。在本文中,为了有效地对特定的时空预测(即城市人群流量)建模,我们主要提出使用残差学习和基于参数矩阵的融合机制。关于数据融合方法的调查见(Zheng 2015)。
总结及未来工作
基于历史轨迹数据、天气和事件,我们提出了一个基于深度学习的新模型,用于预测城市每个区域的人群流量。我们对北京和纽约两种类型的人流量进行了评估,取得了显著优于6个基线方法的性能,证实了我们的模型更好,更适用于人流量预测。代码和数据集已经在https://www.microsoft.com/en-us/research/publication/deep-spatio-temporal-residual-networks-for-citywide-crowd-flows-prediction/上发布。
未来,我们将考虑其他类型的流(如出租车/卡车/公交车轨迹数据、电话信号数据、地铁刷卡数据),并使用所有这些流生成更多类型的流预测,并使用适当的融合机制对所有这些流进行综合预测。

- 点赞
- 收藏
- 关注作者
评论(0)