使用DQN算法玩2048游戏

通过本案例的学习和课后作业的练习:
- 了解DQN算法的基本概念
- 了解如何基于DQN训练一个小游戏
- 了解强化学习训练推理游戏的整体流程
你也可以将本案例相关的 ipynb 学习笔记分享到 AI Gallery Notebook 版块获得成长值,分享方法请查看此文档。
案例内容介绍
《2048》是一款单人在线和移动端游戏,由19岁的意大利人Gabriele Cirulli于2014年3月开发。游戏任务是在一个网格上滑动小方块来进行组合,直到形成一个带有有数字2048的方块。该游戏可以上下左右移动方块。如果两个带有相同数字的方块在移动中碰撞,则它们会合并为一个方块,且所带数字变为两者之和。每次移动时,会有一个值为2或者4的新方块出现,所出现的数字都是2的幂。当值为2048的方块出现时,游戏即胜利,该游戏因此得名。(源自维基百科) DQN是强化学习的经典算法之一,最早由DeepMind于2013年发表的论文“Playing Atari with Deep Reinforcement Learning”中提出,属于value based的model free方法,在多种游戏环境中表现稳定且良好。 在本案例中,我们将展示如何基于simple dqn算法,训练一个2048的小游戏。
整体流程:安装基础依赖->创建2048环境->构建DQN算法->训练->推理->可视化效果
DQN算法的基本结构
Deep Q-learning(DQN)是Q-learing和神经网络的结合,利用经验回放来进行强化学习的训练,结构如下:
- 神经网络部分
神经网络用来逼近值函数,一般采用全连接层表达特征输入,采用卷积层表达图像输入。其损失函数表达为

γ经验折扣率,γ取0,表示只考虑当下,γ取1,表示只考虑未来。
- 经验回放
经验回放是指:模型与环境交互得到的(s,a,r,s')会存入一个replay buffer,然后每次从中随机采样出一批样本进行学习。采用该策略的优点如下:减少样本之间的相关性,以近似符合独立同分布的假设;同时增大样本的利用率。
- 探索策略
一般采用贪婪探索策略,即agent以ε的概率进行随机探索,其他时间则采取模型计算得到的动作。
- DQN的整体结构可以简单的表示为:

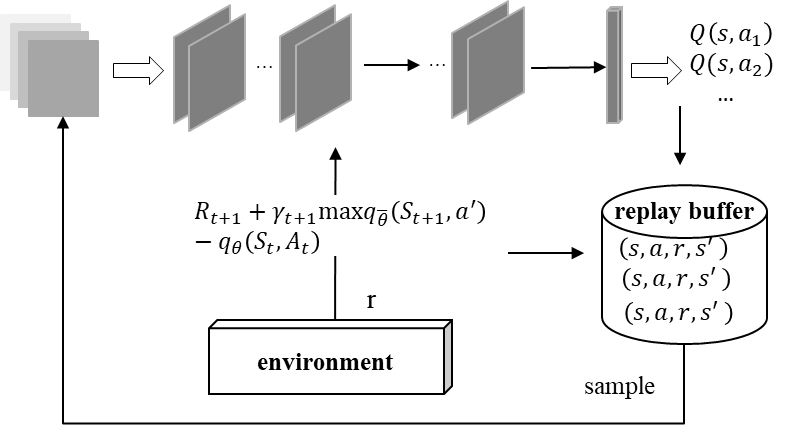
Nature DQN在DQN的基础上,采用两个结构一样的网络,一个当前Q网络用来选择动作,更新模型参数,另一个目标Q网络用于计算目标Q值。这样可以减少目标Q值和当前的Q值相关性。
2048游戏环境简介
2048环境来源于GitHub开源项目,继承于gym基本环境类。玩家可以上下左右移动方块,如果方块数字相同,则合并且所带数字变成两者之和。当值为2048的方块出现时,则获得胜利。
- 结束标志
只要出现非法移动,即移动的方向的数字无法合并,则该局结束。相比较于传统的可试验多次更加严格,难度提高。
- 奖励函数
奖励值为当前方块和累加
- 最大合成数字
最大能合成4096
注意事项
-
本案例运行环境为 Pytorch-1.0.0,支持 GPU和CPU 运行,请查看《ModelAtrs JupyterLab 硬件规格使用指南》了解切换硬件规格的方法;
-
如果您是第一次使用 JupyterLab,请查看《ModelAtrs JupyterLab使用指导》了解使用方法;
-
如果您在使用 JupyterLab 过程中碰到报错,请参考《ModelAtrs JupyterLab常见问题解决办法》尝试解决问题。
!pip install gym第2步:导入相关的库
import sys
import time
import logging
import argparse
import itertools
from six import StringIO
from random import sample, randint
import gym
from gym import spaces
from gym.utils import seeding
import numpy as np
import torch
import torch.nn as nn
from PIL import Image, ImageDraw, ImageFont
from IPython import display
import matplotlib
import matplotlib.pyplot as plt2. 训练参数初始化¶
本案例设置的 epochs = 3000,可以达到较好的训练效果,GPU下训练耗时约10分钟。CPU下训练较慢,建议调小 epochs 的值,如50,以便快速跑通代码。
parser = argparse.ArgumentParser()
parser.add_argument("--learning_rate", type=float, default=0.001) # 学习率
parser.add_argument("--gamma", type=float, default=0.99) # 经验折扣率
parser.add_argument("--epochs", type=int, default=50) # 迭代多少局数
parser.add_argument("--buffer_size", type=int, default=10000) # replaybuffer大小
parser.add_argument("--batch_size", type=int, default=128) # batchsize大小
parser.add_argument("--pre_train_model", type=str, default=None) # 是否加载预训练模型
parser.add_argument("--use_nature_dqn", type=bool, default=True) # 是否采用nature dqn
parser.add_argument("--target_update_freq", type=int, default=250) # 如果采用nature dqn,target模型更新频率
parser.add_argument("--epsilon", type=float, default=0.9) # 探索epsilon取值
args, _ = parser.parse_known_args()3. 创建环境
2048游戏环境继承于gym.Env,主要几个部分:
- init函数 定义动作空间、状态空间和游戏基本设置
- step函数 与环境交互,获取动作并执行,返回状态、奖励、是否结束和补充信息
- reset函数 一局结束后,重置环境
- render函数 绘图,可视化环境
def pairwise(iterable):
"s -> (s0,s1), (s1,s2), (s2, s3), ..."
a, b = itertools.tee(iterable)
next(b, None)
return zip(a, b)
class IllegalMove(Exception):
pass
def stack(flat, layers=16):
"""Convert an [4, 4] representation into [4, 4, layers] with one layers for each value."""
# representation is what each layer represents
representation = 2 ** (np.arange(layers, dtype=int) + 1)
# layered is the flat board repeated layers times
layered = np.repeat(flat[:, :, np.newaxis], layers, axis=-1)
# Now set the values in the board to 1 or zero depending whether they match representation.
# Representation is broadcast across a number of axes
layered = np.where(layered == representation, 1, 0)
return layered
class Game2048Env(gym.Env):
metadata = {'render.modes': ['ansi', 'human', 'rgb_array']}
def __init__(self):
# Definitions for game. Board must be square.
self.size = 4
self.w = self.size
self.h = self.size
self.squares = self.size * self.size
# Maintain own idea of game score, separate from rewards
self.score = 0
# Members for gym implementation
self.action_space = spaces.Discrete(4)
# Suppose that the maximum tile is as if you have powers of 2 across the board.
layers = self.squares
self.observation_space = spaces.Box(0, 1, (self.w, self.h, layers), dtype=np.int)
self.set_illegal_move_reward(-100)
self.set_max_tile(None)
# Size of square for rendering
self.grid_size = 70
# Initialise seed
self.seed()
# Reset ready for a game
self.reset()
def seed(self, seed=None):
self.np_random, seed = seeding.np_random(seed)
return [seed]
def set_illegal_move_reward(self, reward):
"""Define the reward/penalty for performing an illegal move. Also need
to update the reward range for this."""
# Guess that the maximum reward is also 2**squares though you'll probably never get that.
# (assume that illegal move reward is the lowest value that can be returned
self.illegal_move_reward = reward
self.reward_range = (self.illegal_move_reward, float(2 ** self.squares))
def set_max_tile(self, max_tile):
"""Define the maximum tile that will end the game (e.g. 2048). None means no limit.
This does not affect the state returned."""
assert max_tile is None or isinstance(max_tile, int)
self.max_tile = max_tile
# Implement gym interface
def step(self, action):
"""Perform one step of the game. This involves moving and adding a new tile."""
logging.debug("Action {}".format(action))
score = 0
done = None
info = {
'illegal_move': False,
}
try:
score = float(self.move(action))
self.score += score
assert score <= 2 ** (self.w * self.h)
self.add_tile()
done = self.isend()
reward = float(score)
except IllegalMove:
logging.debug("Illegal move")
info['illegal_move'] = True
done = True
reward = self.illegal_move_reward
# print("Am I done? {}".format(done))
info['highest'] = self.highest()
# Return observation (board state), reward, done and info dict
return stack(self.Matrix), reward, done, info
def reset(self):
self.Matrix = np.zeros((self.h, self.w), np.int)
self.score = 0
logging.debug("Adding tiles")
self.add_tile()
self.add_tile()
return stack(self.Matrix)
def render(self, mode='human'):
if mode == 'rgb_array':
black = (0, 0, 0)
grey = (200, 200, 200)
white = (255, 255, 255)
tile_colour_map = {
2: (255, 255, 255),
4: (255, 248, 220),
8: (255, 222, 173),
16: (244, 164, 96),
32: (205, 92, 92),
64: (240, 255, 255),
128: (240, 255, 240),
256: (193, 255, 193),
512: (154, 255, 154),
1024: (84, 139, 84),
2048: (139, 69, 19),
4096: (178, 34, 34),
}
grid_size = self.grid_size
# Render with Pillow
pil_board = Image.new("RGB", (grid_size * 4, grid_size * 4))
draw = ImageDraw.Draw(pil_board)
draw.rectangle([0, 0, 4 * grid_size, 4 * grid_size], grey)
fnt = ImageFont.truetype('/usr/share/fonts/truetype/dejavu/DejaVuSans-Bold.ttf', 30)
for y in range(4):
for x in range(4):
o = self.get(y, x)
if o:
draw.rectangle([x * grid_size, y * grid_size, (x + 1) * grid_size, (y + 1) * grid_size],
tile_colour_map[o])
(text_x_size, text_y_size) = draw.textsize(str(o), font=fnt)
draw.text((x * grid_size + (grid_size - text_x_size) // 2,
y * grid_size + (grid_size - text_y_size) // 2), str(o), font=fnt, fill=black)
assert text_x_size < grid_size
assert text_y_size < grid_size
return np.asarray(pil_board)
outfile = StringIO() if mode == 'ansi' else sys.stdout
s = 'Score: {}\n'.format(self.score)
s += 'Highest: {}\n'.format(self.highest())
npa = np.array(self.Matrix)
grid = npa.reshape((self.size, self.size))
s += "{}\n".format(grid)
outfile.write(s)
return outfile
# Implement 2048 game
def add_tile(self):
"""Add a tile, probably a 2 but maybe a 4"""
possible_tiles = np.array([2, 4])
tile_probabilities = np.array([0.9, 0.1])
val = self.np_random.choice(possible_tiles, 1, p=tile_probabilities)[0]
empties = self.empties()
assert empties.shape[0]
empty_idx = self.np_random.choice(empties.shape[0])
empty = empties[empty_idx]
logging.debug("Adding %s at %s", val, (empty[0], empty[1]))
self.set(empty[0], empty[1], val)
def get(self, x, y):
"""Return the value of one square."""
return self.Matrix[x, y]
def set(self, x, y, val):
"""Set the value of one square."""
self.Matrix[x, y] = val
def empties(self):
"""Return a 2d numpy array with the location of empty squares."""
return np.argwhere(self.Matrix == 0)
def highest(self):
"""Report the highest tile on the board."""
return np.max(self.Matrix)
def move(self, direction, trial=False):
"""Perform one move of the game. Shift things to one side then,
combine. directions 0, 1, 2, 3 are up, right, down, left.
Returns the score that [would have] got."""
if not trial:
if direction == 0:
logging.debug("Up")
elif direction == 1:
logging.debug("Right")
elif direction == 2:
logging.debug("Down")
elif direction == 3:
logging.debug("Left")
changed = False
move_score = 0
dir_div_two = int(direction / 2)
dir_mod_two = int(direction % 2)
shift_direction = dir_mod_two ^ dir_div_two # 0 for towards up left, 1 for towards bottom right
# Construct a range for extracting row/column into a list
rx = list(range(self.w))
ry = list(range(self.h))
if dir_mod_two == 0:
# Up or down, split into columns
for y in range(self.h):
old = [self.get(x, y) for x in rx]
(new, ms) = self.shift(old, shift_direction)
move_score += ms
if old != new:
changed = True
if not trial:
for x in rx:
self.set(x, y, new[x])
else:
# Left or right, split into rows
for x in range(self.w):
old = [self.get(x, y) for y in ry]
(new, ms) = self.shift(old, shift_direction)
move_score += ms
if old != new:
changed = True
if not trial:
for y in ry:
self.set(x, y, new[y])
if changed != True:
raise IllegalMove
return move_score
def combine(self, shifted_row):
"""Combine same tiles when moving to one side. This function always
shifts towards the left. Also count the score of combined tiles."""
move_score = 0
combined_row = [0] * self.size
skip = False
output_index = 0
for p in pairwise(shifted_row):
if skip:
skip = False
continue
combined_row[output_index] = p[0]
if p[0] == p[1]:
combined_row[output_index] += p[1]
move_score += p[0] + p[1]
# Skip the next thing in the list.
skip = True
output_index += 1
if shifted_row and not skip:
combined_row[output_index] = shifted_row[-1]
return (combined_row, move_score)
def shift(self, row, direction):
"""Shift one row left (direction == 0) or right (direction == 1), combining if required."""
length = len(row)
assert length == self.size
assert direction == 0 or direction == 1
# Shift all non-zero digits up
shifted_row = [i for i in row if i != 0]
# Reverse list to handle shifting to the right
if direction:
shifted_row.reverse()
(combined_row, move_score) = self.combine(shifted_row)
# Reverse list to handle shifting to the right
if direction:
combined_row.reverse()
assert len(combined_row) == self.size
return (combined_row, move_score)
def isend(self):
"""Has the game ended. Game ends if there is a tile equal to the limit
or there are no legal moves. If there are empty spaces then there
must be legal moves."""
if self.max_tile is not None and self.highest() == self.max_tile:
return True
for direction in range(4):
try:
self.move(direction, trial=True)
# Not the end if we can do any move
return False
except IllegalMove:
pass
return True
def get_board(self):
"""Retrieve the whole board, useful for testing."""
return self.Matrix
def set_board(self, new_board):
"""Retrieve the whole board, useful for testing."""
self.Matrix = new_board神经网络结构包含三层卷积网络和一层全连接网络,输出维度为动作空间维度。 神经网络部分可自由设计,以训练出更好的效果。
class Net(nn.Module):
#obs是状态空间输入,available_actions_count为动作输出维度
def __init__(self, obs, available_actions_count):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(obs, 128, kernel_size=2, stride=1)
self.conv2 = nn.Conv2d(128, 64, kernel_size=2, stride=1)
self.conv3 = nn.Conv2d(64, 16, kernel_size=2, stride=1)
self.fc1 = nn.Linear(16, available_actions_count)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = x.permute(0, 3, 1, 2)
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.relu(self.conv3(x))
x = self.fc1(x.view(x.shape[0], -1))
return xDQN核心逻辑部分
class DQN:
def __init__(self, args, obs_dim, action_dim):
# 是否加载预训练模型
if args.pre_train_model:
print("Loading model from: ", args.pre_train_model)
self.behaviour_model = torch.load(args.pre_train_model).to(device)
# 如果采用Nature DQN,则需要额外定义target_network
self.target_model = torch.load(args.pre_train_model).to(device)
else:
self.behaviour_model = Net(obs_dim, action_dim).to(device)
self.target_model = Net(obs_dim, action_dim).to(device)
self.optimizer = torch.optim.Adam(self.behaviour_model.parameters(), args.learning_rate)
self.criterion = nn.MSELoss()
# 动作维度
self.action_dim = action_dim
# 统计学习步数
self.learn_step_counter = 0
self.args = args
def learn(self, buffer):
# 当replaybuffer中存储的数据大于batchsize时,从中随机采样一个batch的数据学习
if buffer.size >= self.args.batch_size:
# 更新target_model的参数
if self.learn_step_counter % args.target_update_freq == 0:
self.target_model.load_state_dict(self.behaviour_model.state_dict())
self.learn_step_counter += 1
# 从replaybuffer中随机采样一个五元组(当前观测值,动作,下一个观测值,是否一局结束,奖励值)
s1, a, s2, done, r = buffer.get_sample(self.args.batch_size)
s1 = torch.FloatTensor(s1).to(device)
s2 = torch.FloatTensor(s2).to(device)
r = torch.FloatTensor(r).to(device)
a = torch.LongTensor(a).to(device)
if args.use_nature_dqn:
q = self.target_model(s2).detach()
else:
q = self.behaviour_model(s2)
# 每个动作的q值=r+gamma*(1-0或1)*q_max
target_q = r + torch.FloatTensor(args.gamma * (1 - done)).to(device) * q.max(1)[0]
target_q = target_q.view(args.batch_size, 1)
eval_q = self.behaviour_model(s1).gather(1, torch.reshape(a, shape=(a.size()[0], -1)))
# 计算损失函数
loss = self.criterion(eval_q, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def get_action(self, state, explore=True):
# 判断是否探索,如果探索,则采用贪婪探索策略决定行为
if explore:
if np.random.uniform() >= args.epsilon:
action = randint(0, self.action_dim - 1)
else:
# Choose the best action according to the network.
q = self.behaviour_model(torch.FloatTensor(state).to(device))
m, index = torch.max(q, 1)
action = index.data.cpu().numpy()[0]
else:
q = self.behaviour_model(torch.FloatTensor(state).to(device))
m, index = torch.max(q, 1)
action = index.data.cpu().numpy()[0]
return actionreplay buffer数据存储部分
class ReplayBuffer:
def __init__(self, buffer_size, obs_space):
self.s1 = np.zeros(obs_space, dtype=np.float32)
self.s2 = np.zeros(obs_space, dtype=np.float32)
self.a = np.zeros(buffer_size, dtype=np.int32)
self.r = np.zeros(buffer_size, dtype=np.float32)
self.done = np.zeros(buffer_size, dtype=np.float32)
# replaybuffer大小
self.buffer_size = buffer_size
self.size = 0
self.pos = 0
# 不断将数据存储入buffer
def add_transition(self, s1, action, s2, done, reward):
self.s1[self.pos] = s1
self.a[self.pos] = action
if not done:
self.s2[self.pos] = s2
self.done[self.pos] = done
self.r[self.pos] = reward
self.pos = (self.pos + 1) % self.buffer_size
self.size = min(self.size + 1, self.buffer_size)
# 随机采样一个batchsize
def get_sample(self, sample_size):
i = sample(range(0, self.size), sample_size)
return self.s1[i], self.a[i], self.s2[i], self.done[i], self.r[i]5. 训练模型
初始化环境和算法
# 初始化环境
env = Game2048Env()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化dqn
dqn = DQN(args, obs_dim=env.observation_space.shape[2], action_dim=env.action_space.n)
# 初始化replay buffer
memory = ReplayBuffer(buffer_size=args.buffer_size, obs_space=
(args.buffer_size, env.observation_space.shape[0], env.observation_space.shape[1], env.observation_space.shape[2]))开始训练
print('\ntraining...')
begin_t = time.time()
max_reward = 0
for i_episode in range(args.epochs):
# 每局开始,重置环境
s = env.reset()
# 累计奖励值
ep_r = 0
while True:
# 计算动作
a = dqn.get_action(np.expand_dims(s, axis=0))
# 执行动作
s_, r, done, info = env.step(a)
# 存储信息
memory.add_transition(s, a, s_, done, r)
ep_r += r
# 学习优化过程
dqn.learn(memory)
if done:
print('Ep: ', i_episode,
'| Ep_r: ', round(ep_r, 2))
if ep_r > max_reward:
max_reward = ep_r
print("current_max_reward {}".format(max_reward))
# 保存模型
torch.save(dqn.behaviour_model, "2048.pt")
break
s = s_
print("finish! time cost is {}s".format(time.time() - begin_t))6. 使用模型推理游戏¶
#加载模型
model = torch.load("2048.pt").to(device)
model.eval()
s = env.reset()
img = plt.imshow(env.render(mode='rgb_array'))
while True:
plt.axis("off")
img.set_data(env.render(mode='rgb_array'))
display.display(plt.gcf())
display.clear_output(wait=True)
s = torch.FloatTensor(np.expand_dims(s, axis=0)).to(device)
a = torch.argmax(model(s), dim=1).cpu().numpy()[0]
# take action
s_, r, done, info = env.step(a)
time.sleep(0.1)
if done:
break
s = s_
env.close()
plt.close()
7. 作业

- 点赞
- 收藏
- 关注作者
评论(0)