Elastic:使用自定义属性来定义冷热节点时,为什么用include来声明路由时索引无法流转,而用require可以?

0.引言
针对这个问题,很早之前我就有疑惑,也查询了官方资料和其他资料,发现并没有相关的解释。毕竟官方推荐的做热冷集群的方式最好是通过data_hot,data_warm,data_cold的形式。但既然用自定义属性可以使用冷热集群,并且有出现了这个问题,内心的强迫症让我忍不住想要弄明白这是怎么导致的。下面我们详细谈谈这个问题
1.问题复原
1、首先我们使用自定义属性来定义冷热集群
节点1添加自定义属性:node.attr.hot_warm_cold: data_hot
节点2添加自定义属性:node.attr.hot_warm_cold: data_warm
节点3添加自定义属性:node.attr.hot_warm_cold: data_cold
2、开启分片分配感知,并且设置生命周期检测时间为1s,方便我们观察结果
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "hot_warm_cold",
"indices.lifecycle.poll_interval": "1s"
}
}
3、创建ILM策略
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "5s",
"max_primary_shard_size": "50gb"
},
"set_priority": {
"priority": 100
}
},
"min_age": "0ms"
},
"warm": {
"min_age": "0s",
"actions": {
"set_priority": {
"priority": 50
},
"allocate": {
"require": {
"hot_warm_cold": "data_warm"
}
}
}
},
"cold": {
"min_age": "3s",
"actions": {
"set_priority": {
"priority": 0
},
"allocate": {
"require": {
"hot_warm_cold": "data_cold"
}
}
}
},
"delete": {
"min_age": "6s",
"actions": {
"delete": {}
}
}
}
}
}
4、创建索引模版,可以看到这里我使用的是include的方式来声明热节点
“index.routing.allocation.include.hot_warm_cold”: “data_hot”
PUT _component_template/settings_1
{
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "my_policy",
"index.routing.allocation.include.hot_warm_cold": "data_hot"
}
}
}
PUT _index_template/my_template_1
{
"index_patterns": ["my-*"],
"composed_of": ["settings_1"],
"data_stream": {}
}
5、创建数据流并且插入数据
POST my-index/_doc
{
"@timestamp": "11",
"name": "1"
}
6、观察分片
GET _cat/shards?v
结果:会发现数据流下的索引一直存在与node1中,并没有按照ILM策略的设置流转到warm节点中。
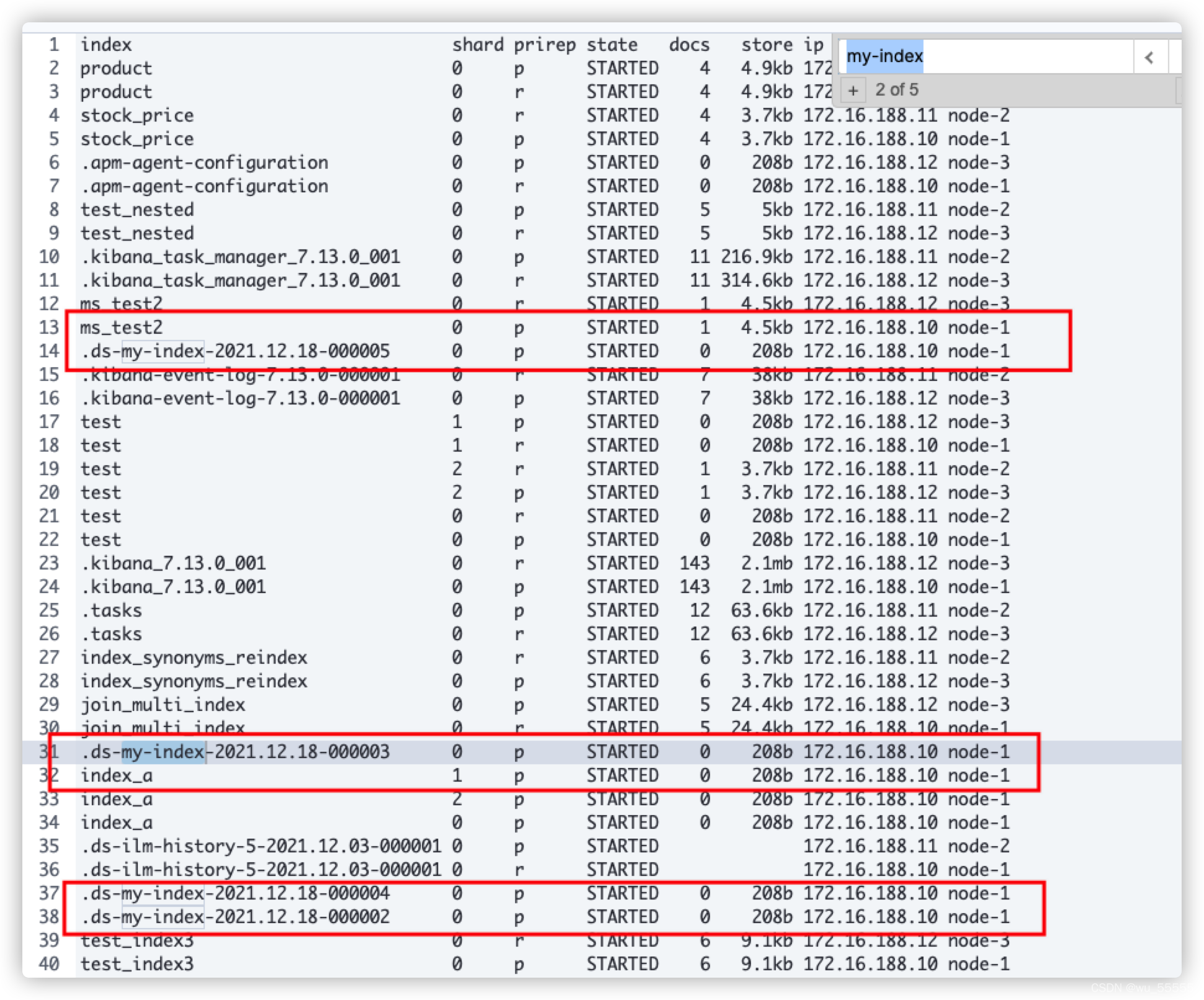
7、下面我们将申明方式改为require,再来实验一次
PUT _component_template/settings_1
{
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "my_policy",
"index.routing.allocation.require.hot_warm_cold": "data_hot"
}
}
}
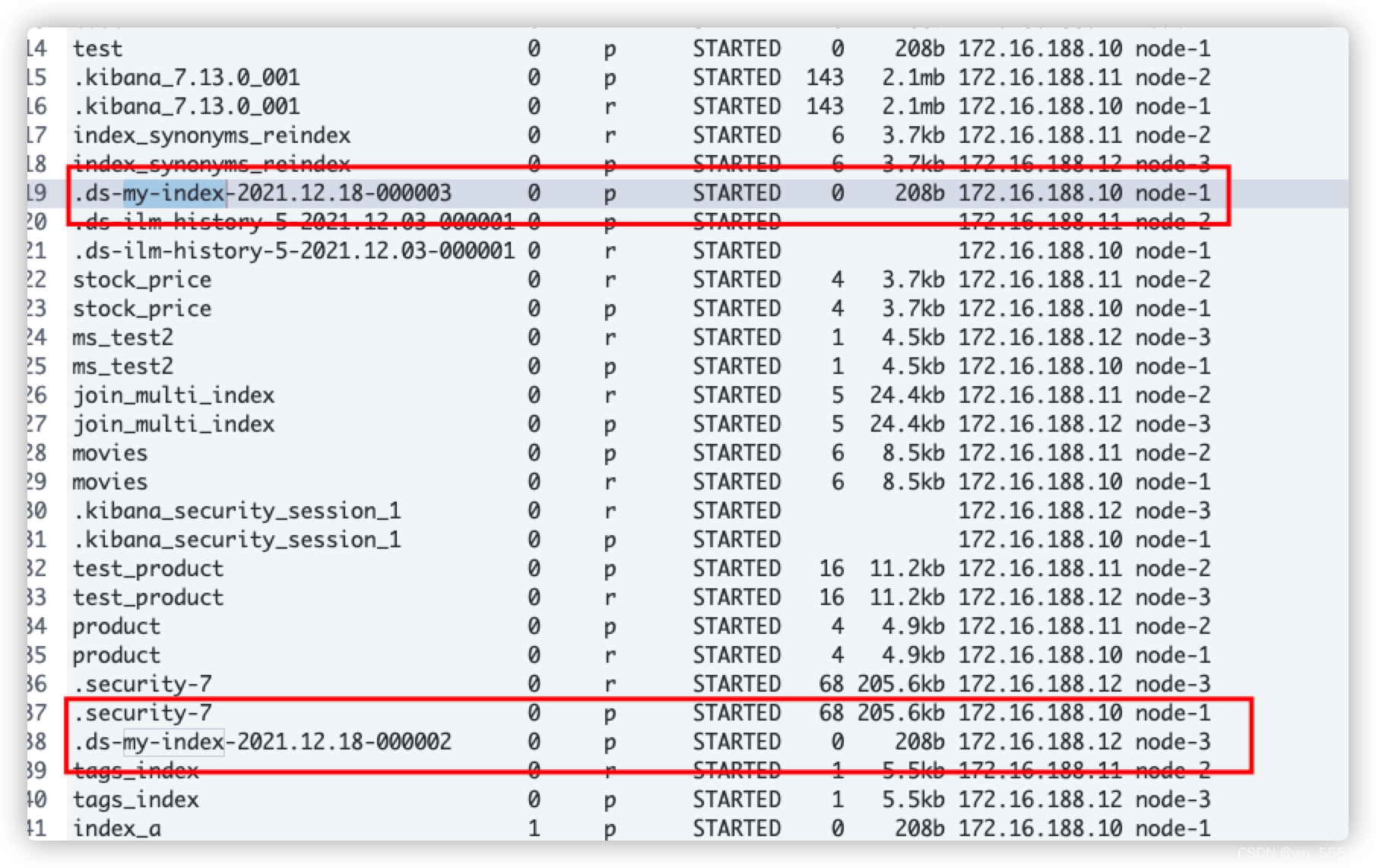
创建数据流并查看结果:索引001已经被删除,索引002流转到cold节点上,索引流转成功
2.原因分析
综上,使用include时并没有实现索引在冷热节点中的流转,而偏偏require可以。我们查阅下官方文档,看看两者的区别
2.1 require和include的区别

译文:
cluster.routing.allocation.include.{attribute}。
(动态)将分片分配给{属性}至少有一个逗号分隔的值的节点。
cluster.routing.allocation.require.{attribute}。
(动态)只向{属性}具有所有逗号分隔的值的节点分配碎片。
cluster.routing.allocation.exclude.{attribute}(动态)
(动态)不向{属性}具有任何逗号分隔的值的节点分配碎片。
按照译文来看require是需要包含所有的属性值,而include是包含一个就可以了,而我们设置的属性值本身就只有一个,而且也都包含了,但为什么就是流转不了呢?
针对这一点我一开始也疑惑了很久,直到有一天无意之中看到了ILM策略的DSL (平时都是使用kibana可视化配置的),如文章一开始所示,我把warm节点的配置单独拿出来
"warm": {
"min_age": "0s",
"actions": {
"set_priority": {
"priority": 50
},
"allocate": {
"require": {
"hot_warm_cold": "data_warm"
}
}
}
}
看到这里,是不是有点思路了
ILM中warm节点里的路由配置使用的是require,而我们在索引模版中定义的索引分配路由是用的include,这就产生了冲突,从而导致路由分配失败。那么要使用include,我们只需要把ILM中的路由策略给修改为include即可,下面我们来测试一下:
修改ILM策略路由配置
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "5s",
"max_primary_shard_size": "50gb"
},
"set_priority": {
"priority": 100
}
},
"min_age": "0ms"
},
"warm": {
"min_age": "0s",
"actions": {
"set_priority": {
"priority": 50
},
"allocate": {
"include": {
"hot_warm_cold": "data_warm"
}
}
}
},
"cold": {
"min_age": "3s",
"actions": {
"set_priority": {
"priority": 0
},
"allocate": {
"include": {
"hot_warm_cold": "data_cold"
}
}
}
},
"delete": {
"min_age": "6s",
"actions": {
"delete": {}
}
}
}
}
}
修改索引模版中的路由配置
PUT _component_template/settings_1
{
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "my_policy",
"index.routing.allocation.include.hot_warm_cold": "data_hot"
}
}
}
重新创建数据流
POST my-index/_doc
{
"@timestamp": "11",
"name": "1"
}
观察结果
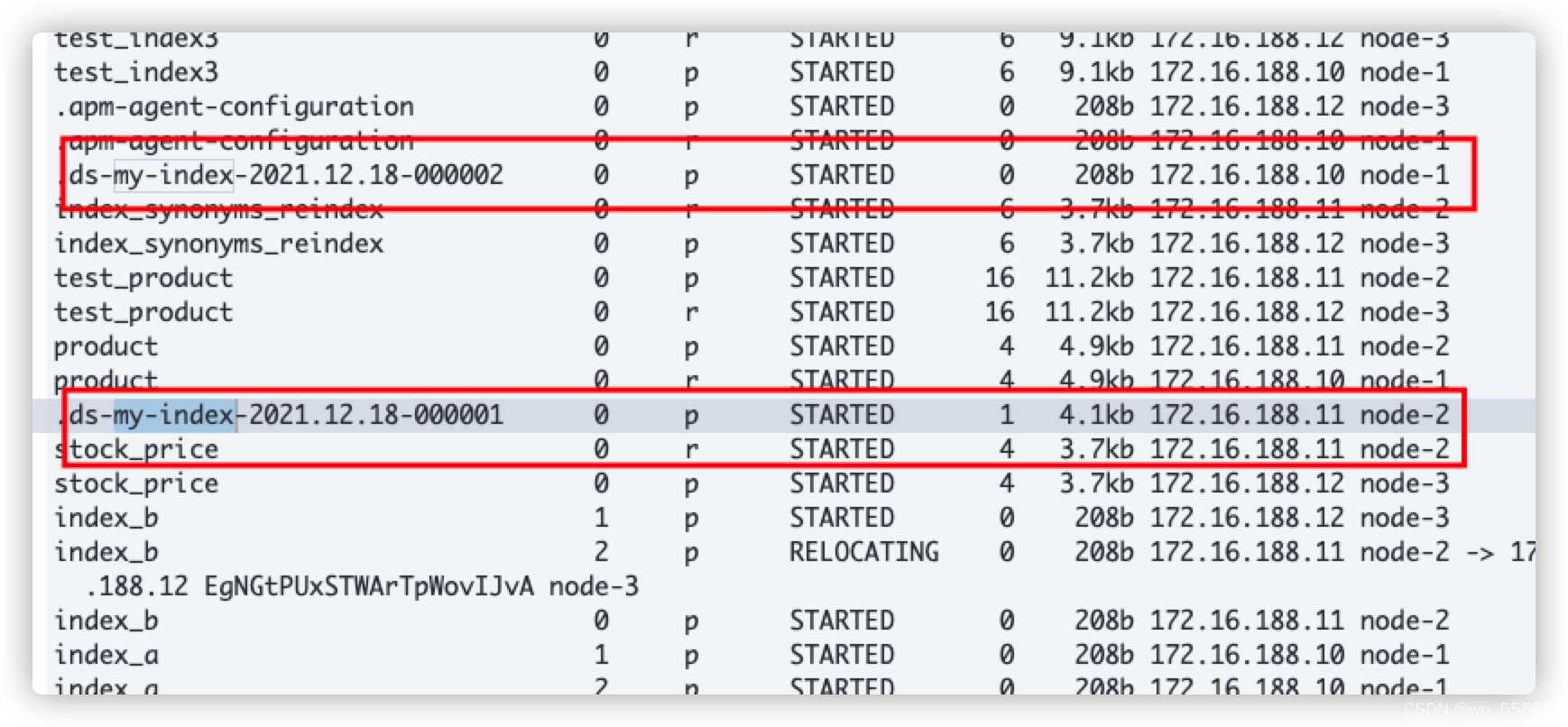
GET _cat/shards?v
结果:可以看到索引001成功流转到了节点2,实验成功!
3. 总结
ILM中各节点的路由配置要和索引模版中的索引的路由配置方式保持一致:如果ILM中使用的是require,那么索引模版中也要使用require;如果ILM中使用的是include,那么索引模版中也要使用include。
通过kibana可视化创建的ILM策略中的路由配置方式默认都是require

- 点赞
- 收藏
- 关注作者
评论(0)