Elastic:集群相关知识点总结(一)数据流 Data Stream、索引生命周期 ILM、可搜索快照 searchable

0.引言
集群管理是ES的核心重点,因此相关的知识点至关重要,本期主要针对数据流、索引生命周期、可搜索快照、跨集群搜索、跨集群复制进行讲解
1.数据流 Data Stream
官方文档:Data streams
针对数据流的讲解,之前已经做过详细的梳理,可以参考以下博文:
1.1 数据流六连问
要掌握数据流使用,就要理解以下几点:
1、数据流常用的使用场景?
2、如何通过索引模版创建数据流?
3、索引模版是如何与数据流绑定的?
4、索引与数据流的关系?
5、数据流与ILM的关系?
6、如何通过ILM管理数据流?
可以通过阅读上述博文,来寻找这6道题目的答案,不妨先尝试阅读后再往后查看答案
1.2 六连问解答
1.2.1 数据流常用的使用场景?
适用于日志、事件、指标和其他连续产生的数据
1.2.2 如何通过索引模版创建数据流?
1、创建组件模版
2、创建索引模版。索引模版中引用组件模版,并且通过"data_stream": { }配置开启数据流
3、插入索引数据。这事插入的索引名实际上是数据流名,因为在索引模版中开启了数据流,所以会自动转换,名称要符合索引模版的匹配格式。同时doc中要包含@timestamp字段,且该字段值要符合时间格式
具体配置可以到深入了解数据流查看,这里不做累述
ps: 什么是doc?
新接触的同学可能会有该疑问,所谓doc就是索引中的每条数据,一条就是一个doc。可以简单理解为mysql中的一行
1.2.3 索引模版是如何与数据流绑定的?
在索引模版中开启数据流后(通过data_stream:{}开启,后续将开启了数据流的索引模版成为数据流模版,方便叙述),通过在索引模版中申明的索引名匹配格式,即index_patterns来绑定。当创建的索引名符合数据流模版时,就会将其转换为数据流并且创建数据流。
如果创建的索引名不匹配数据流模版,就会以普通索引的方式创建
1.2.4 索引与数据流的关系?
包含与被包含的关系,具体查看上述博客
1.2.5 数据流与ILM的关系?
数据流本身与ILM无关,但是数据流的出发点是为了分解单个索引压力,将数据分摊到不同的索引上,因此历史的索引管理就成了问题。
举个例子:数据流中有3000个历史索引,如果不管的话,那么这些索引就会堆积在原节点上,但是实际情况是对于时间较久的历史索引,我们已经不再关系或者不怎么关心,因此访问次数较少,或者需要删除,所以按道理来说应该把这些索引转移到其他集群节点上,把当前节点的资源用在最新的、访问次数更多的索引上。如果人工手动来转移的话,势必很麻烦,因此我们就需要一个自动化的管理工具来帮助我们管理索引的流转,而这个工具就是ILM(索引生命周期管理)
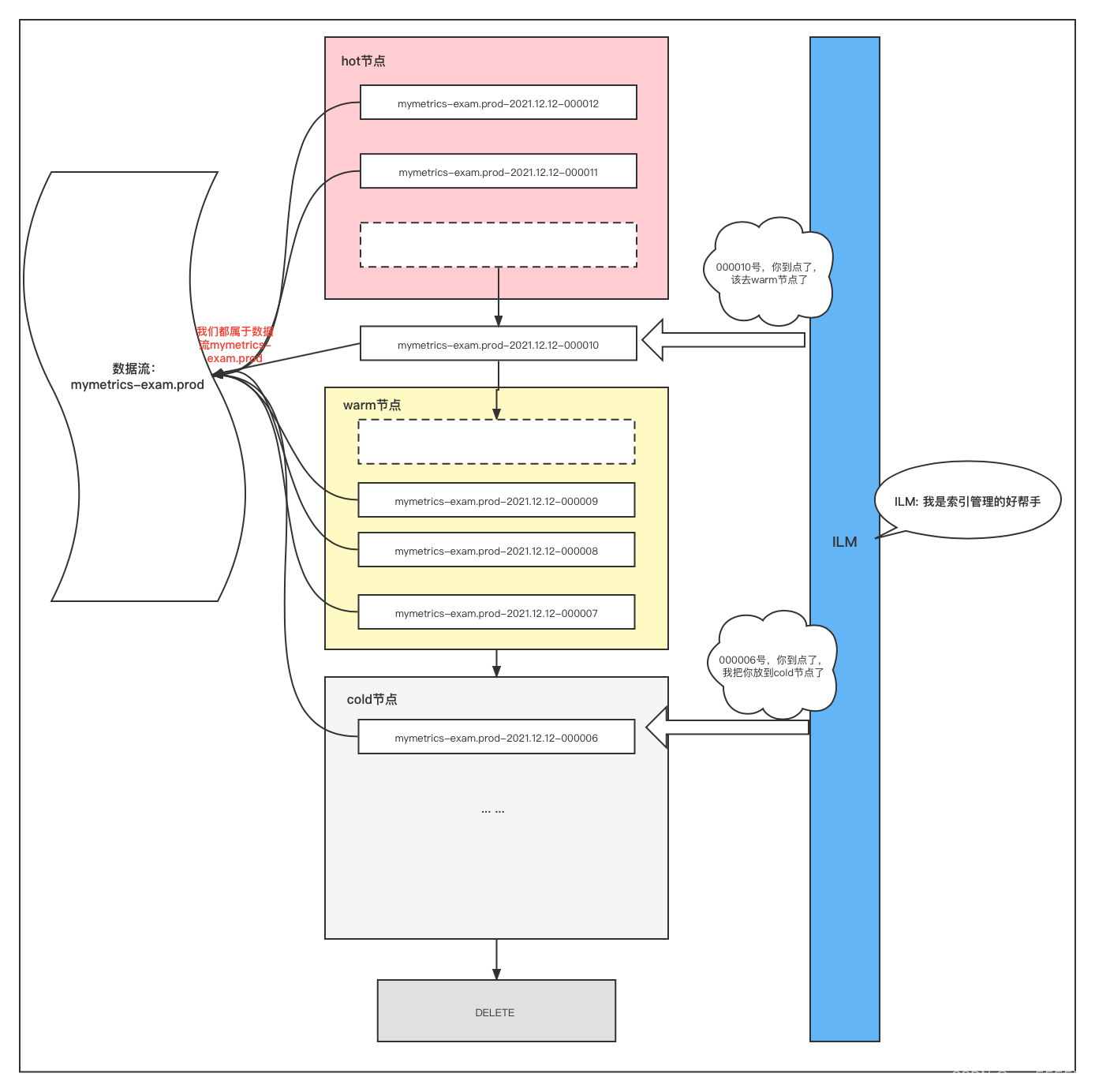
1.2.6 如何通过ILM管理数据流?
当满足了ILM中的rollover条件就会在该数据流中创建新的索引,达到下个节点的min_age时间后就会转移到下个节点
这里如果不理解rollover与ILM的关系,可以参考我这篇博文rollover与ILM的关系
1.2 练习题
题目1
给出了一条数据,把这条数据插入数据流mylogds.prod,要求使得这条数据再开始5分钟在datahot节点,然后立即滚动到datawarm节点,datawarm节点存在3分钟以后,滚动到datacold节点,在datacold节点保持6分钟删除。匹配模板名称task1 匹配所有mylogds.*
题目2
给出了一条数据,把这条数据插入数据流mylogds.prod,要求使得这条数据再开始5分钟在datahot节点,然后立即滚动到datawarm节点,datawarm节点存在3分钟以后,滚动到datacold节点,rollover后6分钟删除(这里注意与上题的区别)。匹配模板名称task1 匹配所有mylogds.*
题目3
创建一个索引模版my_template,匹配索引名格式my_index-*,通过索引模版创建数据流my_index-prod,并且插入数据{"name":"1"}
题目1、2答案参考:关于ILM的一些试验
题目3答案参考:深入了解数据流
2.索引生命周期管理 ILM
官方文档:Manage the index lifecycle > Configure a lifecycle policy
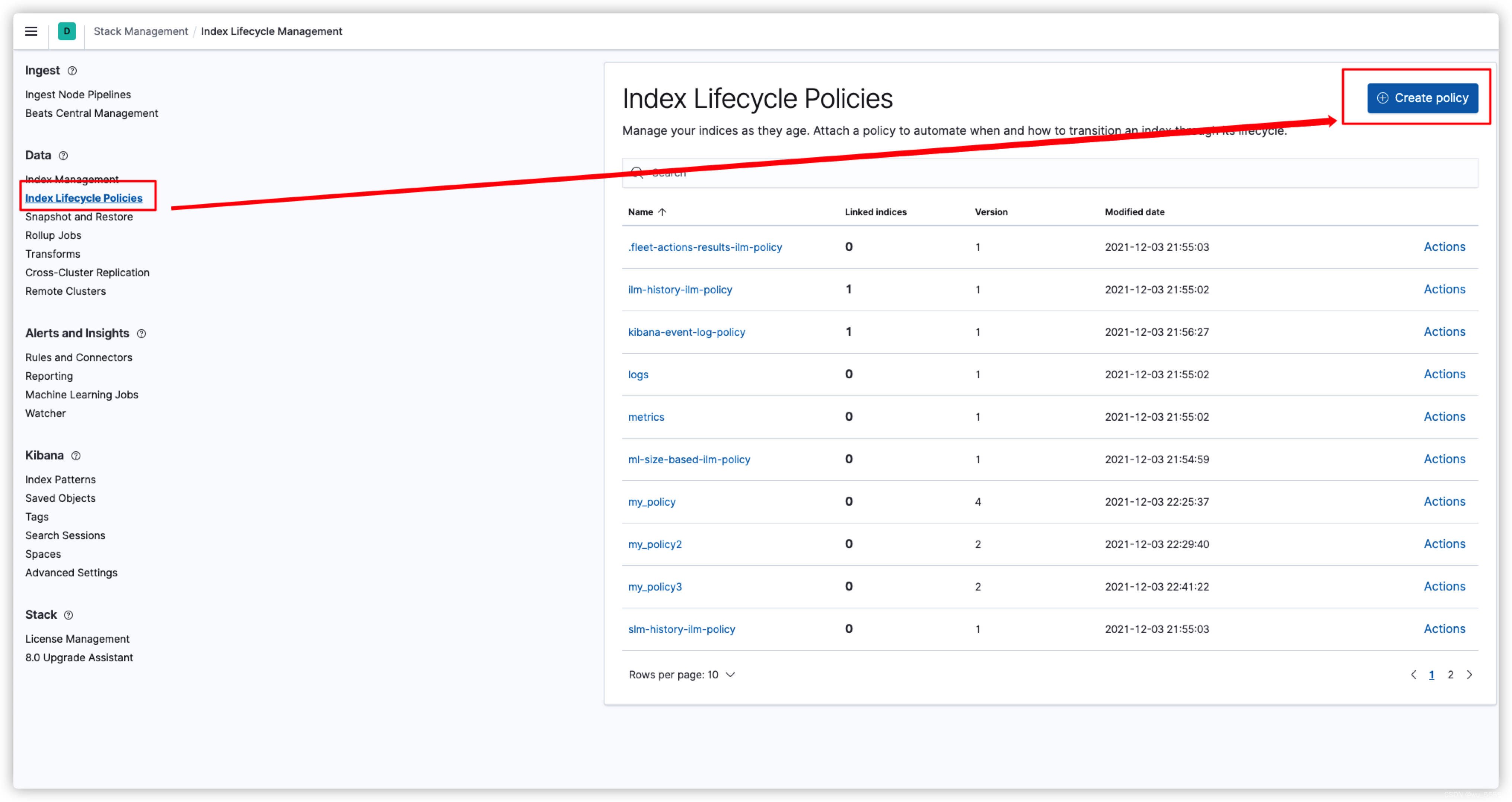
索引生命周期管理(Index Lifecycle Manage)主要用于自动化管理索引,创建ILM策略可以通过DSL(代码api)的方式,也可以通过kibana可视化创建,我们这里以kibana举例
ILM策略在kibana的Stack Management下的Index Lifecycle Policies中
点击创建策略
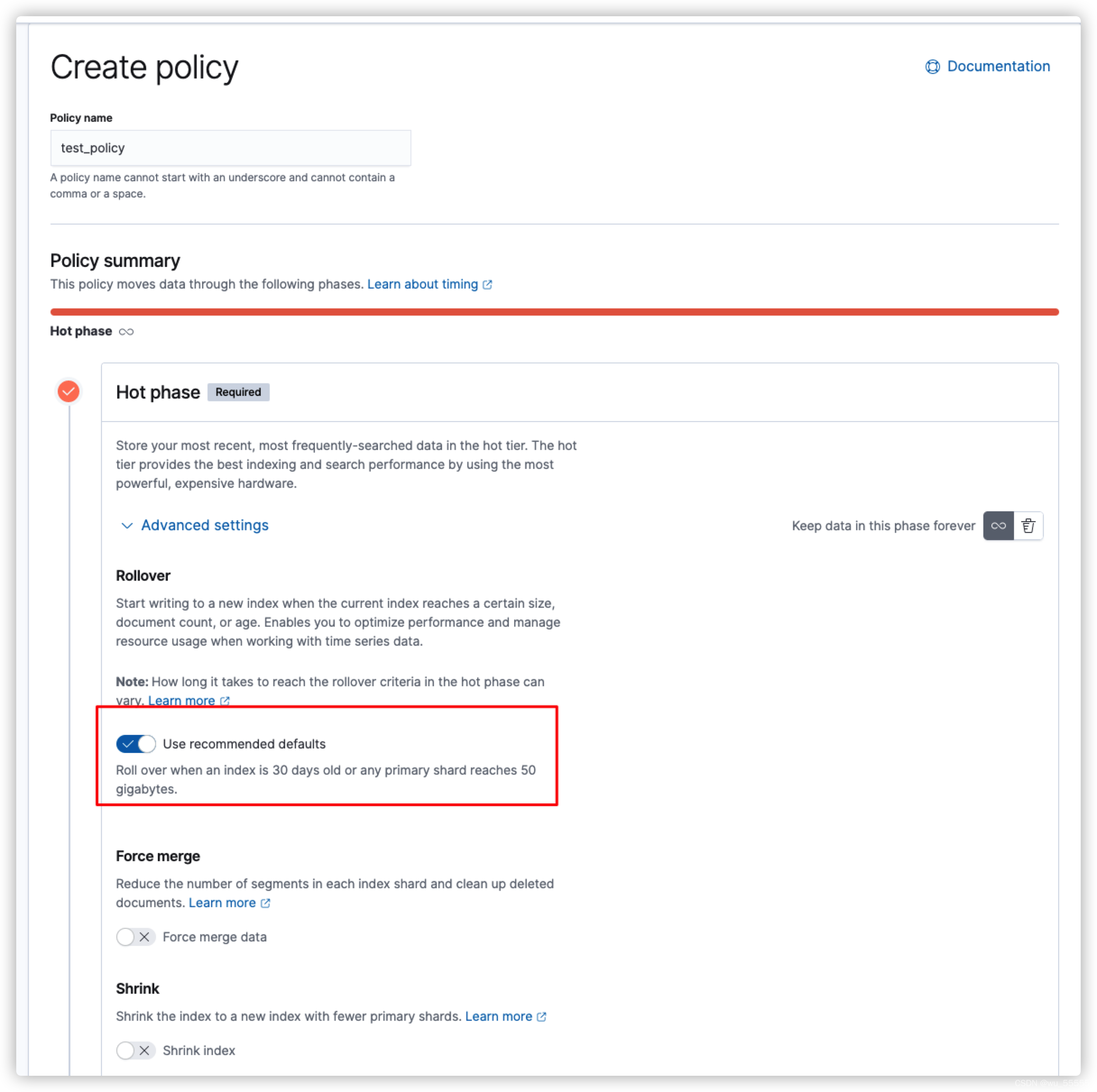
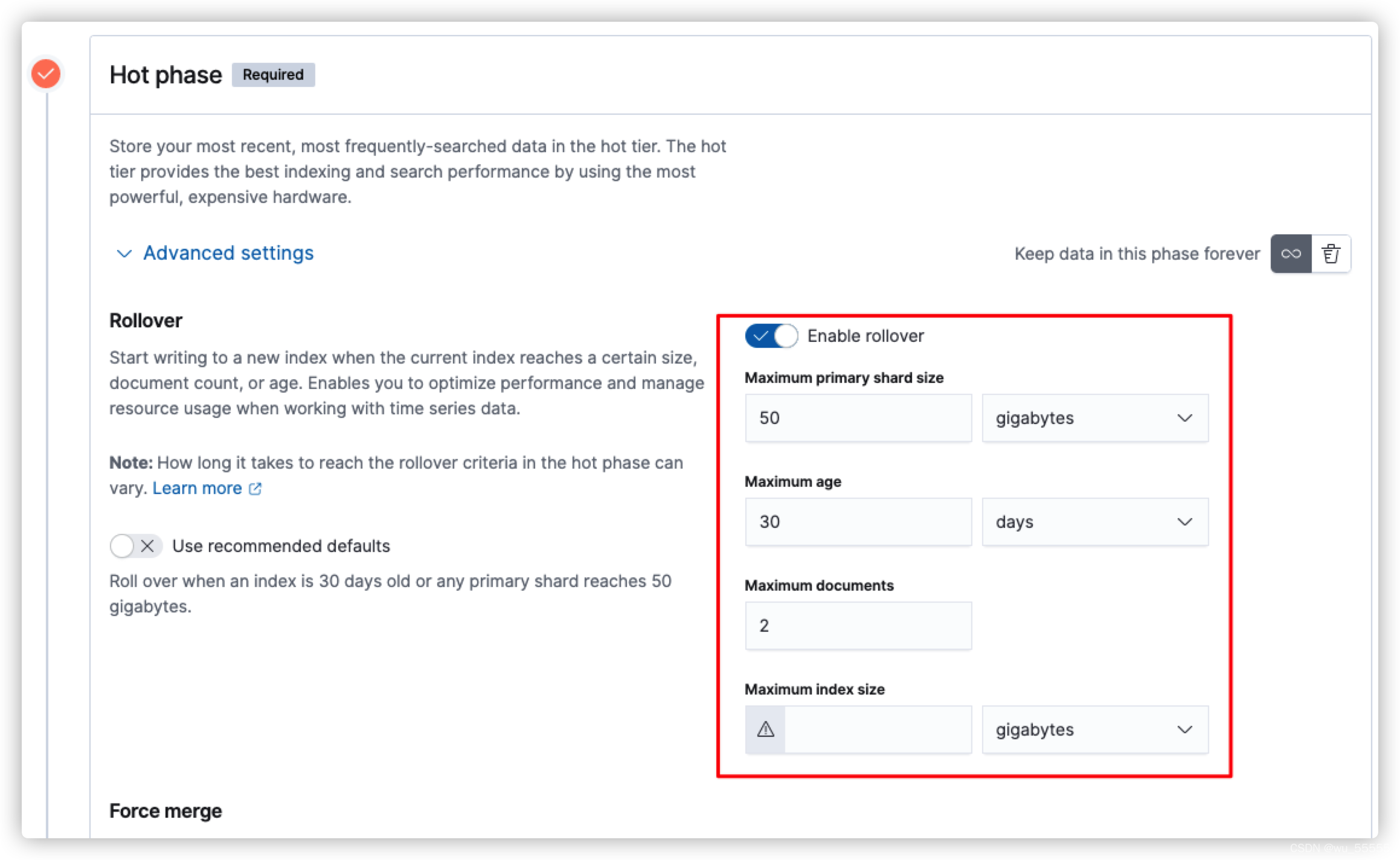
输入策略名,在hot节点中我们可以看到use recommended defaults是默认打开的,也就是说rollover是默认打开的,其默认配置是max age=30,max primary shard size=50GB
所以这里要注意,如果你不需要开启rollover的话,需要手动关闭默认配置,然后再关闭rollover
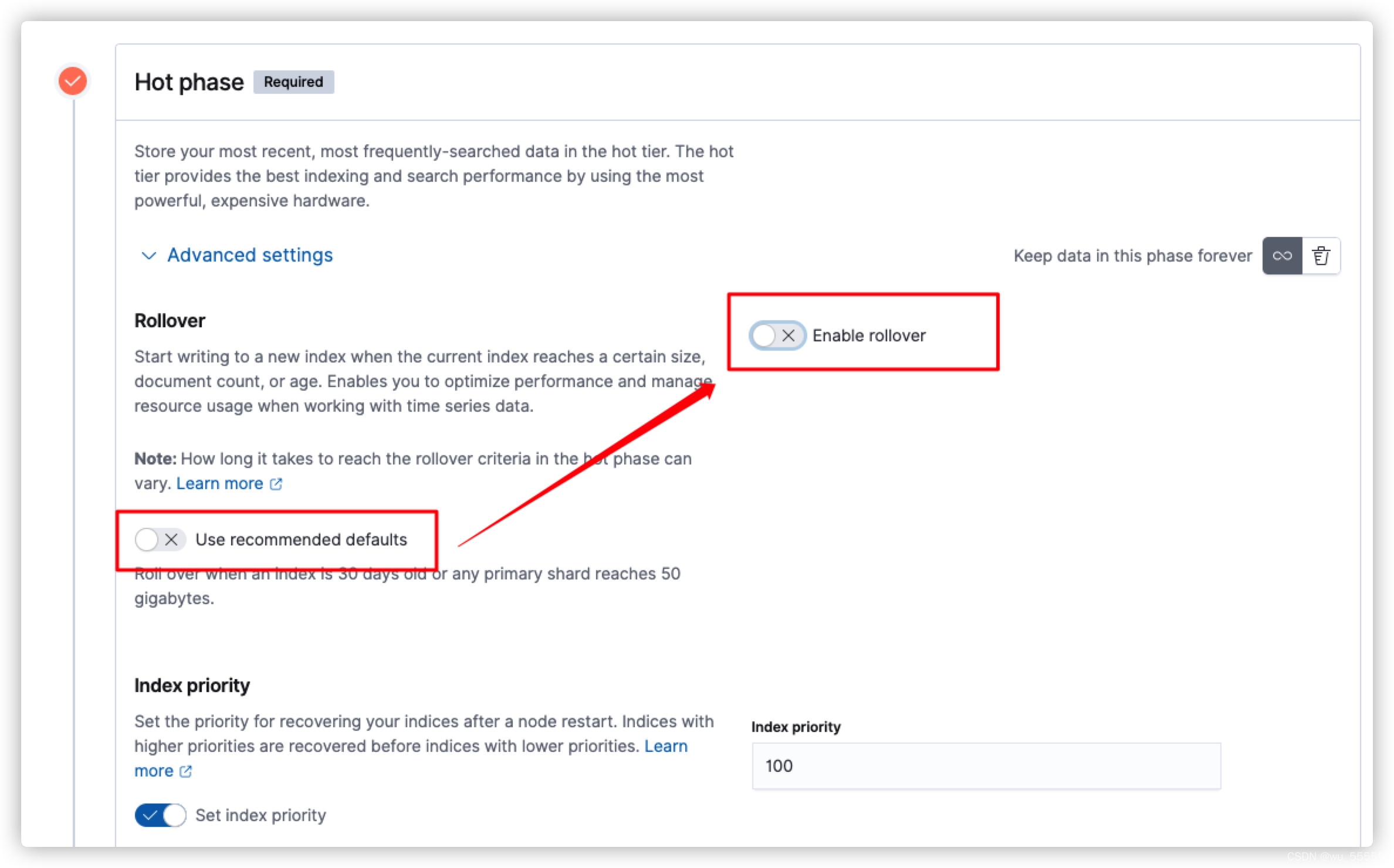
如果需要使用rollover,并且需要自定义rollover条件的话,就要开启rollover并且修改条件
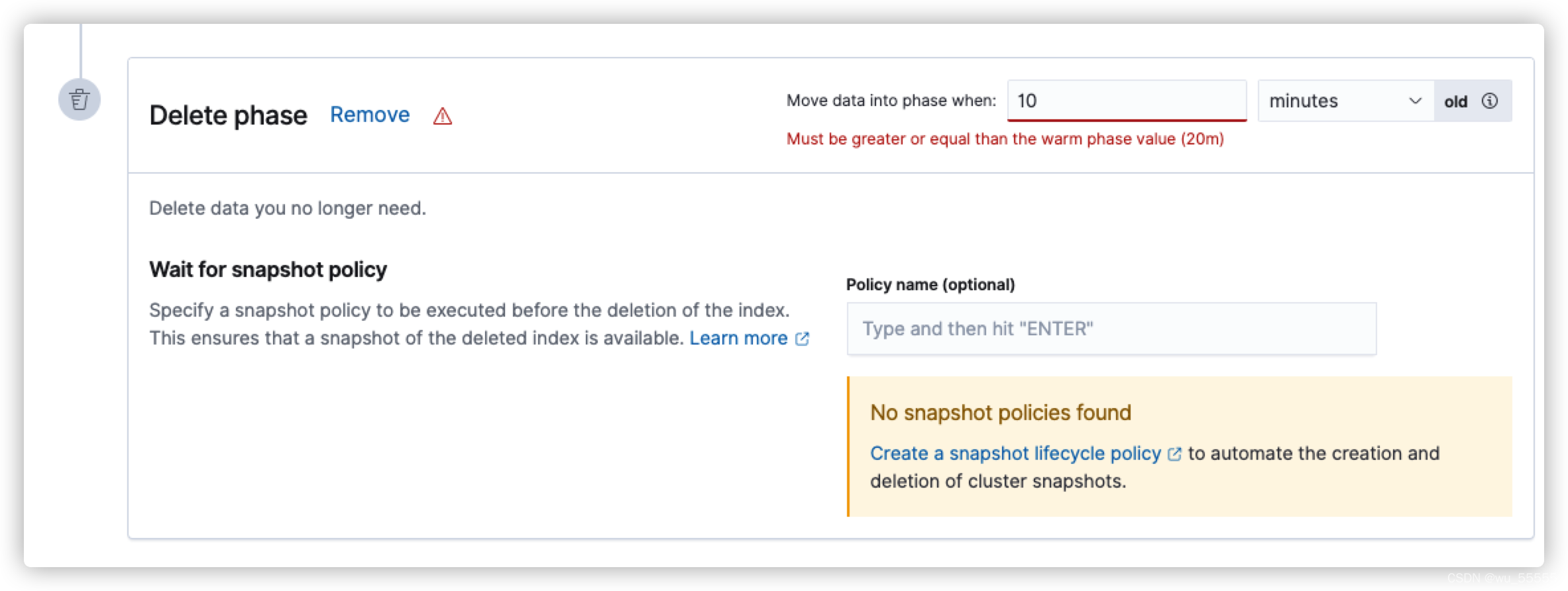
除了hot节点,其他的节点都是默认关闭的,需要手动打开,这里输入的move data into phase when就是该节点的min_age,也就是rollover触发后多少时间后转移到这个节点
举个例子:rollover里配置了每10分钟触发滚动,而warm节点的min_age配置了20分钟,那么索引需要30分钟后才会转移到warm节点
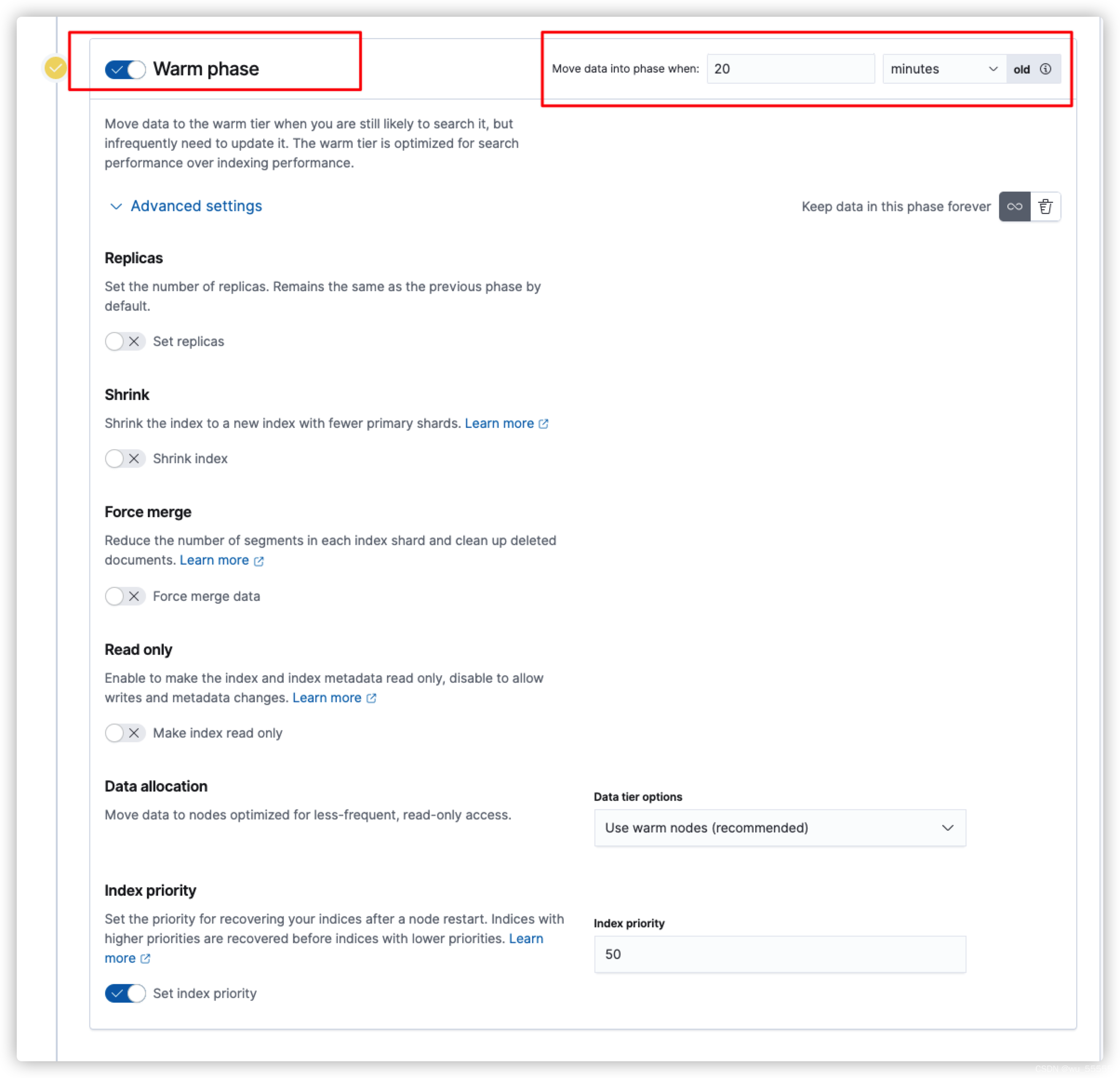
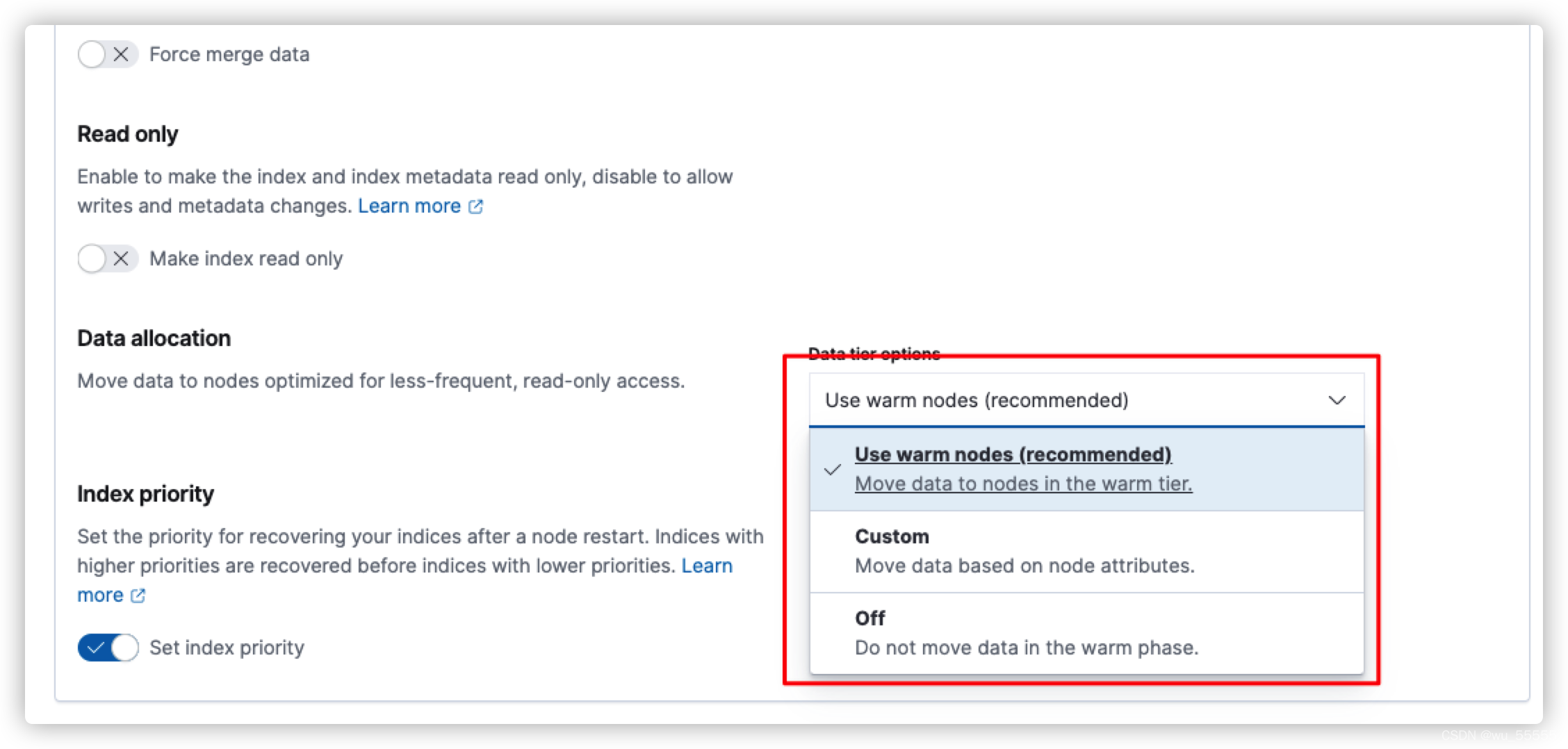
其次需要注意的是数据层data tier options配置,也就是通过什么方式判定哪些节点是warm节点。提供了三个选项:
(1)默认选项,使用这个节点需要在ES节点配置中添加data_warm角色,注意如果添加了data_warm角色,就不能添加data角色
具体可参考我这篇博客data_hot,data_warm,data_cold角色有什么用
(2)使用自定义属性,需要提前在配置文件中添加node.attr.<yyy>=xxx来打开,如下图所示,需要在warm节点中配置node.attr.hot_warm_cold: data_warm来配置
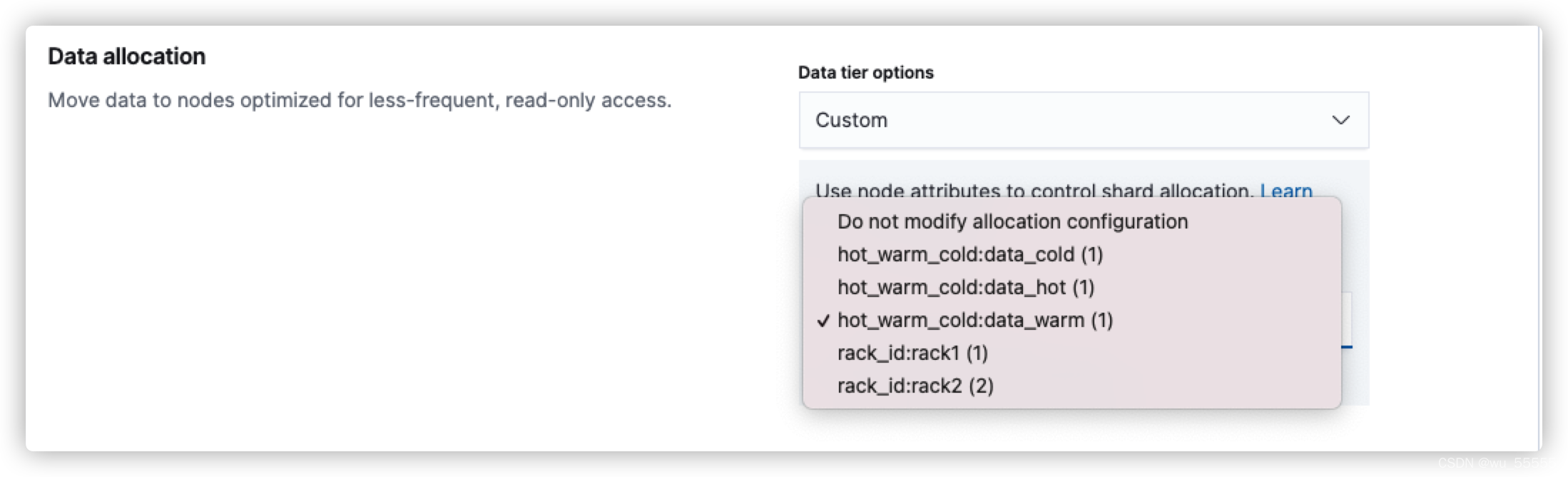
cold节点的配置同warm节点,如果无需冻结数据则不用开启Frozen节点,如果想直接删除则需在cold节点中开启删除
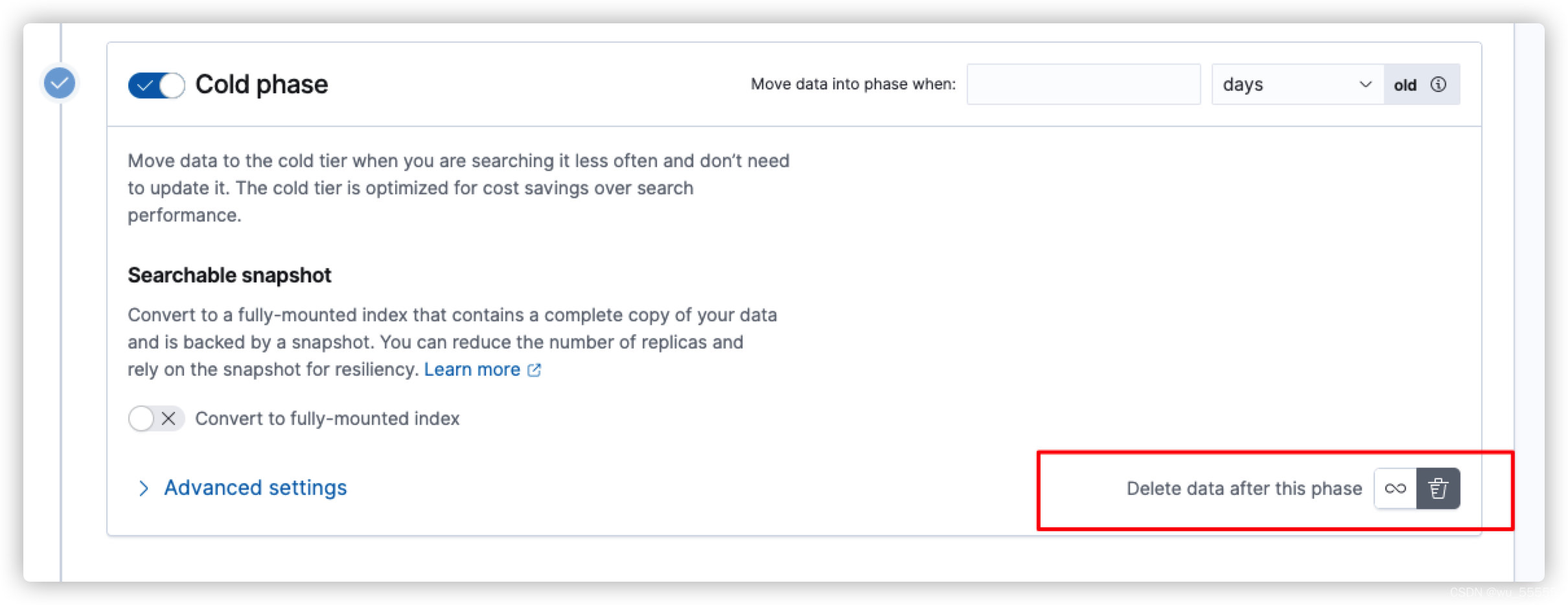
并且输入min_age,需要注意的是因为min_age是全量参数,即rollover触发后min_age时间后转移到该节点,所以每个节点的min_age一定比上一个节点大,否则的话,会如下图所示报错
针对ILM的概述就到这里,如果对他的理解还有些模糊的话,建议实操几道题目来体会,可参考如下博客:
data_hot,data_warm,data_cold角色有什么用
关于索引生命周期ILM的一些试验
3.可搜索快照 searchable snapshots
官方文档:REST APIs > searchable snapshots APIs
可搜索快照功能需要提前开启白金会员,如果是学习的话,可以先开启30天会员试用(到期后可以通过删除es data目录来重置试用)
什么是快照?
所谓快照,可以简单理解为当时数据的一个备份。形象的理解为给当时数据拍摄一个照片,通过照片可以恢复原数据。相较于普通的备份占用空间更小,恢复效率更高。
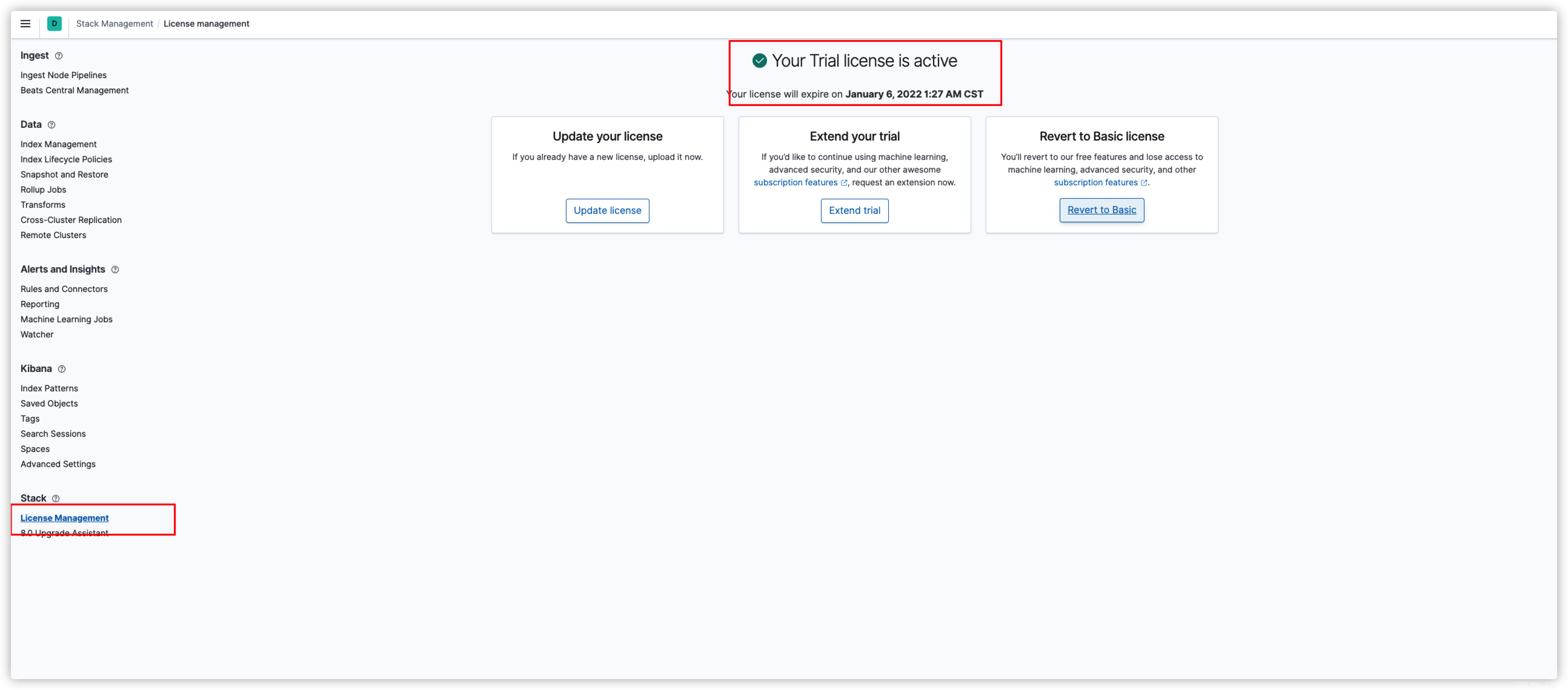
3.1 开启30天会员试用
在kibana中打开Stack Management,然后打开License Management,点击start trial,成功开启后如下所示
3.2 配置普通快照
官方文档:REST APIs > Snapshot and restore APIs
1 注册仓库
需要注意的是这里的仓库路径需要是共享文件夹,或者是在单节点集群上配置快照,如果只是自己学习,可以先在单节点上配置实操。在Elastic认证考试中,会提供给你路径,你需要配置即可
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/var/local/elasticsearch_backup"
}
}
2 创建测试索引
PUT my-index/_doc/1
{
"name": 1
}
3 给索引拍摄快照
PUT /_snapshot/my_backup/snapshot_1?wait_for_completion=true
{
"indices": "my-index",
"ignore_unavailable": true,
"include_global_state": false
}
4 删除索引
DELETE my-index
GET my-index/_search
5 恢复指定索引
POST /_snapshot/my_backup/snapshot_1/_restore
{
"indices": "my-index"
}
6 恢复整个快照
POST /_snapshot/my_backup/snapshot_1/_restore
查询数据,如果快照创建成功,并且恢复成功的话,这里可以正常查询到原数据
GET my-index/_search
3.3 配置可搜索快照
将普通快照挂载为可搜索快照,将内部的my-index索引挂载为my-index-back
这里直接执行会报错,显示当前的认证不支持可搜索快照,需要开通会员
可搜索快照的概念就是直接给快照创建一个索引映射,通过该索引映射,可以查询该快照中备份的索引数据,原本快照可以理解为是一个备份压缩包,而现在可以直接通过一个映射通道访问到内部的数据,所以是非常好用的一个功能。但是需要注意的是,通过可搜索快照映射出来的索引是不允许修改的。
POST /_snapshot/my_backup/snapshot_1/_mount?wait_for_completion=true
{
"index": "my-index",
"renamed_index": "my-index-back",
"index_settings": {
"index.number_of_replicas": 0
},
"ignore_index_settings": [ "index.refresh_interval" ]
}
3 可以通过my-index-back查询到my-index的数据了,但是my-index-back是不允许修改的
GET my-index-back/_search
4.跨集群搜索 CCS
官方文档:Search your data > Search across clusters
实际生产中,我们可能会在多个地方建立数据中心,或者需要汇总在多个集群下的同一个索引数据。这个时候就需要跨集群搜索。
4.1 测试环境准备
为了测试该功能,我们需要先提前准备测试环境:
1、准备2个或以上集群
在集群1上创建索引并插入id=1的doc
PUT index1/_doc/1
{
"name": "1"
}
在集群2上创建索引并插入id=2的doc
PUT index1/_doc/2
{
"name": "2"
}
4.2 配置跨集群搜索
1、每个集群配置远程集群
注意:这里一定要在每个集群上执行,如果不小心配置错了,可以参考我这篇博客删除配置
集群配置如何删除
其中9300是节点间通信端口,即transport.port,如果你不是默认的9300,注意修改
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_one": {
"seeds": [
"172.16.188.10:9300",
"172.16.188.11:9300"
]
},
"cluster_two": {
"seeds": [
"172.16.188.7:9300",
"172.16.188.8:9300",
"172.16.188.9:9300"
]
}
}
}
}
}
2、从多个集群查询同一索引
GET /cluster_two:index1,cluster_one:index1/_search
3、从单一集群查询索引
GET /cluster_one:index1/_search
这里需要注意的是,如果你在一个集群中配置过了security证书,那么需要在跨集群搜索的集群中使用同一个证书配置security,否则查询会报错
5.跨集群复制 CCR
官方文档:REST APIs > Cross-cluster replication APIs
实际生产中可能会有需要跨集群复制数据的需求,这时就需要使用跨集群复制来实现了。
与跨集群搜索类似,跨集群复制的索引也不允许修改,同时也需要保证:如果开启了security的话,每个集群的证书要一致
5.1 跨集群复制条件
跨集群复制需要满足以下三个条件
(1)提前在同集群任意节点上配置remote_cluster_client角色
(2)需要白金会员或者开启30天试用,每个集群都要开启
(3)集群版本不一致的,新集群(发起复制集群)版本必须高于旧集群(被复制集群),并且满足兼容性条件
5.2 测试环境准备
集群1创建一个索引product
PUT product/_doc/1
{
"name": "1"
}
注意:如果任意集群设置了security那么另外的集群也要用同样的节点证书设置security
5.3 配置跨集群复制
1、在每个集群中执行以下代码配置远程集群:
PUT _cluster/settings
{
"persistent": {
"cluster":{
"remote":{
"cfg-c1":{
"seeds":[
"172.16.188.10:9300",
"172.16.188.11:9300",
"172.16.188.12:9300"
]
},
"cfg-c2":{
"seeds":[
"172.16.188.8:9300"
]
}
}
}
}
}
2、 进入集群2 kibana
进入Stack Management,再进入Cross-Cluster Replication
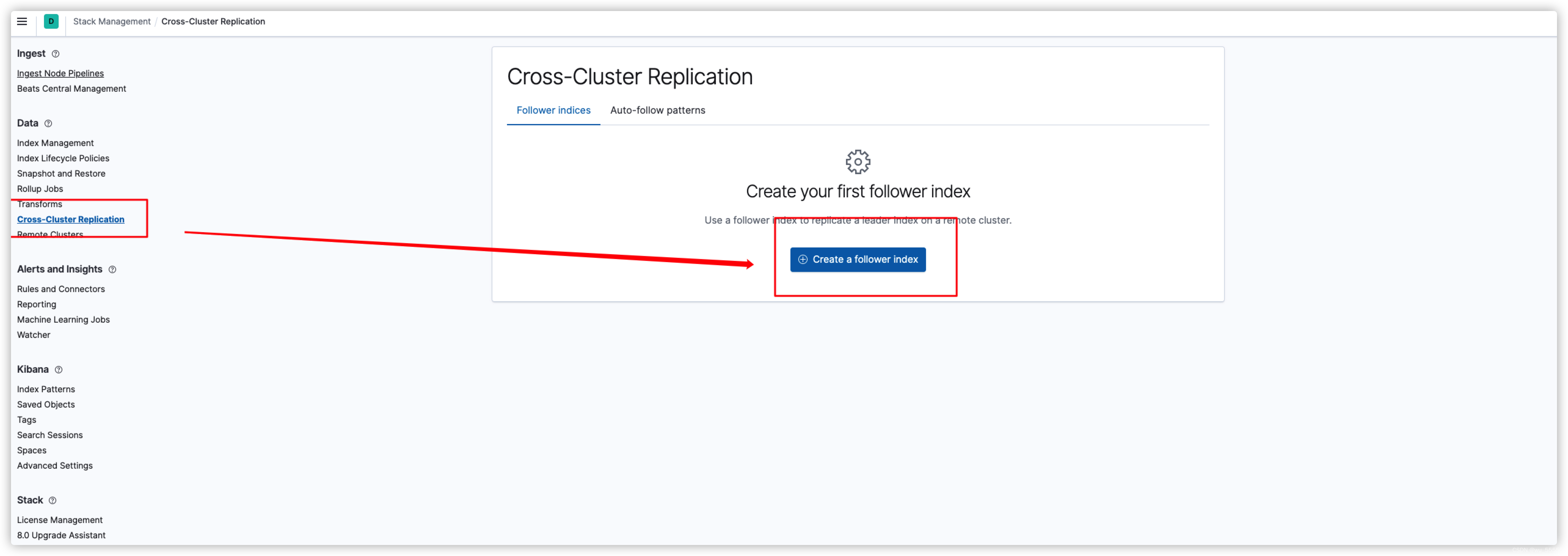
选择Remote cluster: cfg-c2
Leader index输入我们要复制的索引product
Follower index输入复制后的索引名product_copy
最后点击创建Create
3、在集群2中查询product_copy会发现就是product的数据,那么我们的跨集群复制就设置完成了
GET product_copy/_search
但是需要注意的是跨集群复制的索引product_copy,是不允许修改的
6 总结
以上就是集群相关知识点总结一期,下一期将继续讲解集群安全security、角色用户基础权限控制RBAC
【有发现表述不对的地方或者不明白的地方,可以留言告诉我】

- 点赞
- 收藏
- 关注作者
评论(0)