Elastic:data_hot,data_warm,data_cold角色有什么用

1.角色定义
data_hot:热点数据节点,热点数据节点在进入es时存储时间序列数据,热层必须快速读取和写入,并且需要更多的硬件资源
data_warm;暖数据节点,存储不再定期更新但仍在查询的索引。查询两的频率通常低于索引出于热层时的频率,性能较低的硬件通常可用于此层中的节点
data_cold:冷数据节点,存储访问频率较低的只读索引,磁层使用性能较低的硬件,并且可以利用可搜索快照索引来最小化所需的资源
2.如何使用
当在某节点中添加了角色data_warm,那么该节点就被定义为warm节点
定义了角色该如何使用呢,因为本身涉及到冷热节点,所以需要结合ILM使用
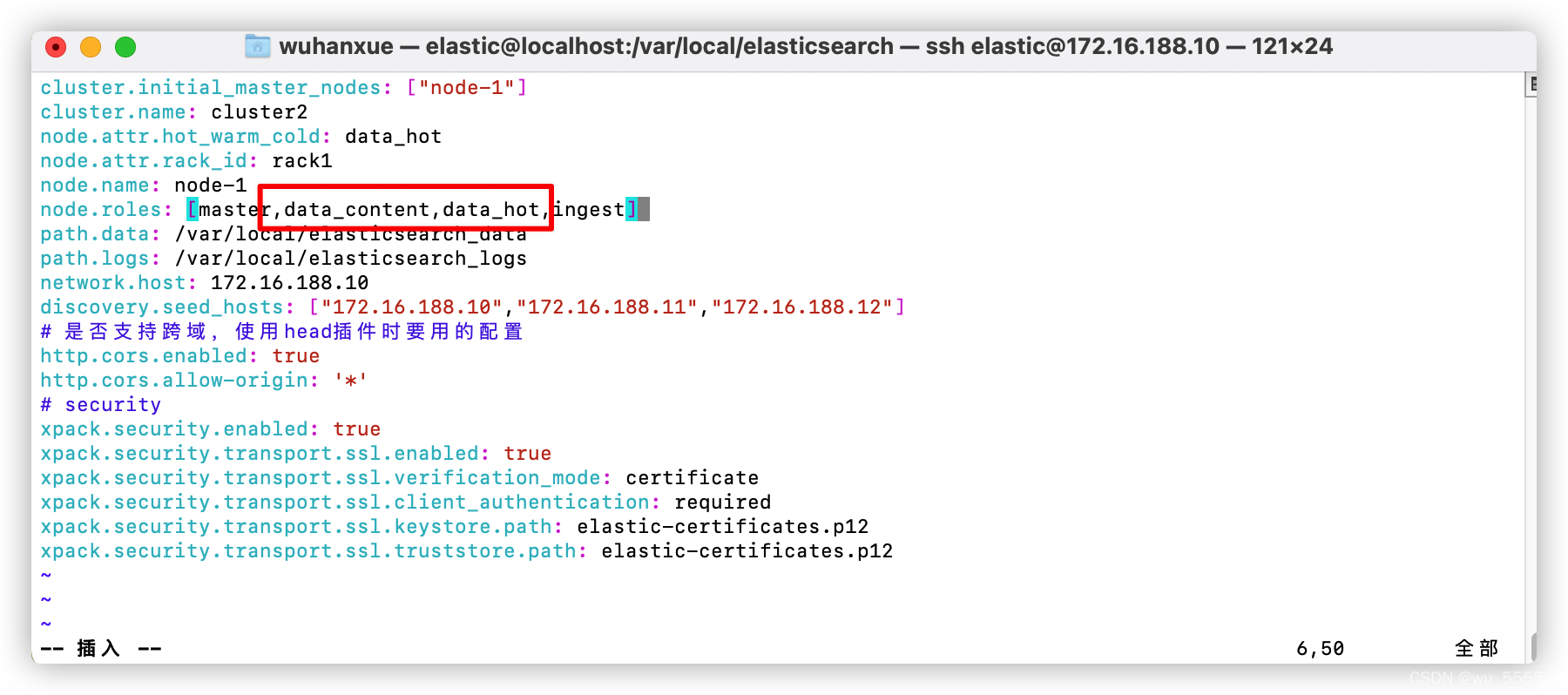
1、首先在es节点配置文件elasticsearch.yml中修改节点角色,我这里分别添加三个节点的角色为data_hot,data_warm,data_cold
这里需要注意,如果你配置了data_hot角色就不要配置data角色,官方的解释是具有专用数据角色(data_hot/warm/cold)的节点不能具有通用data角色。否则的话数据流创建的时候会随机从这些节点中选择一个保存索引
但如果只添加data_hot/warm/cold等角色的话。符合ILM策略的数据流是可以创建并分配成功的。但是普通的索引就不能分配了。因此我们还要再添加一个data_content角色。
2、无需通过自定义属性来设置节点属性,直接用默认的配置就可以了,因为我们添加了data_warm角色,所以有这个角色的节点已经被申明为了warm节点。所以相比自定义属性的形式这种配置来的更加简单
这里要注意,使用kibana配置的话,如果不需要配置rollover,需要将其关闭,默认是开启的
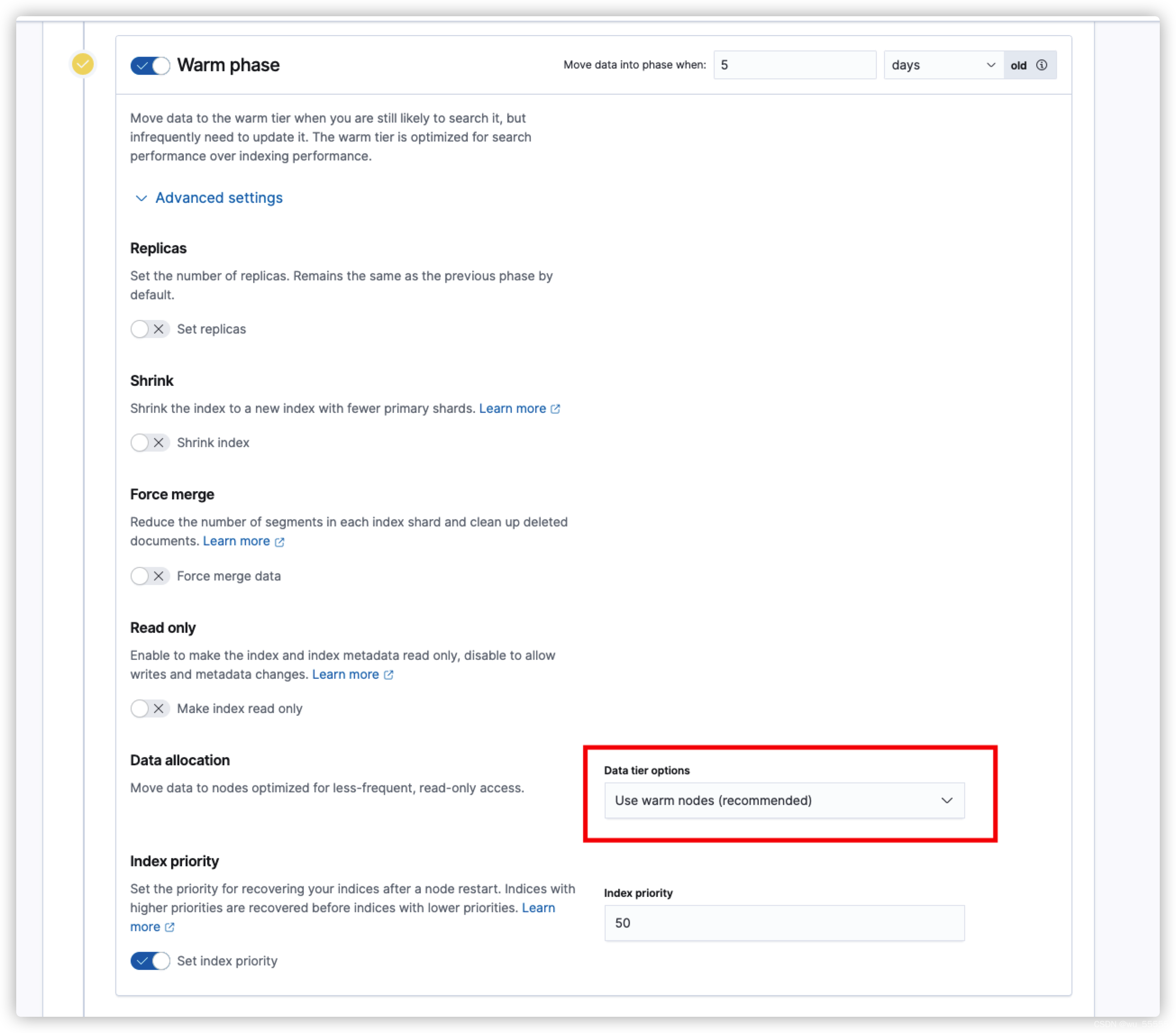
3、ILM配置如下
PUT _ilm/policy/my_policy3
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "5s",
"actions": {
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "8s",
"actions": {
"set_priority": {
"priority": 0
}
}
},
"delete": {
"min_age": "14s",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}
4、我们来创建数据流测试一下
创建组件模版、索引模版
PUT _component_template/my-settings
{
"template": {
"settings": {
"index.lifecycle.name": "my_policy3",
"number_of_shards": 1,
"number_of_replicas": 0
}
}
}
PUT _index_template/task1
{
"index_patterns": ["mylogds*.*"],
"composed_of": [ "my-settings"],
"data_stream": { }
}
创建数据流
POST mylogds.prod/_doc
{
"message": "1",
"@timestamp": "2021-01-01T00:00:00"
}
3.查看结果
通过指令观察分片状态
GET _cat/shards?v
1s时:索引保存在node1
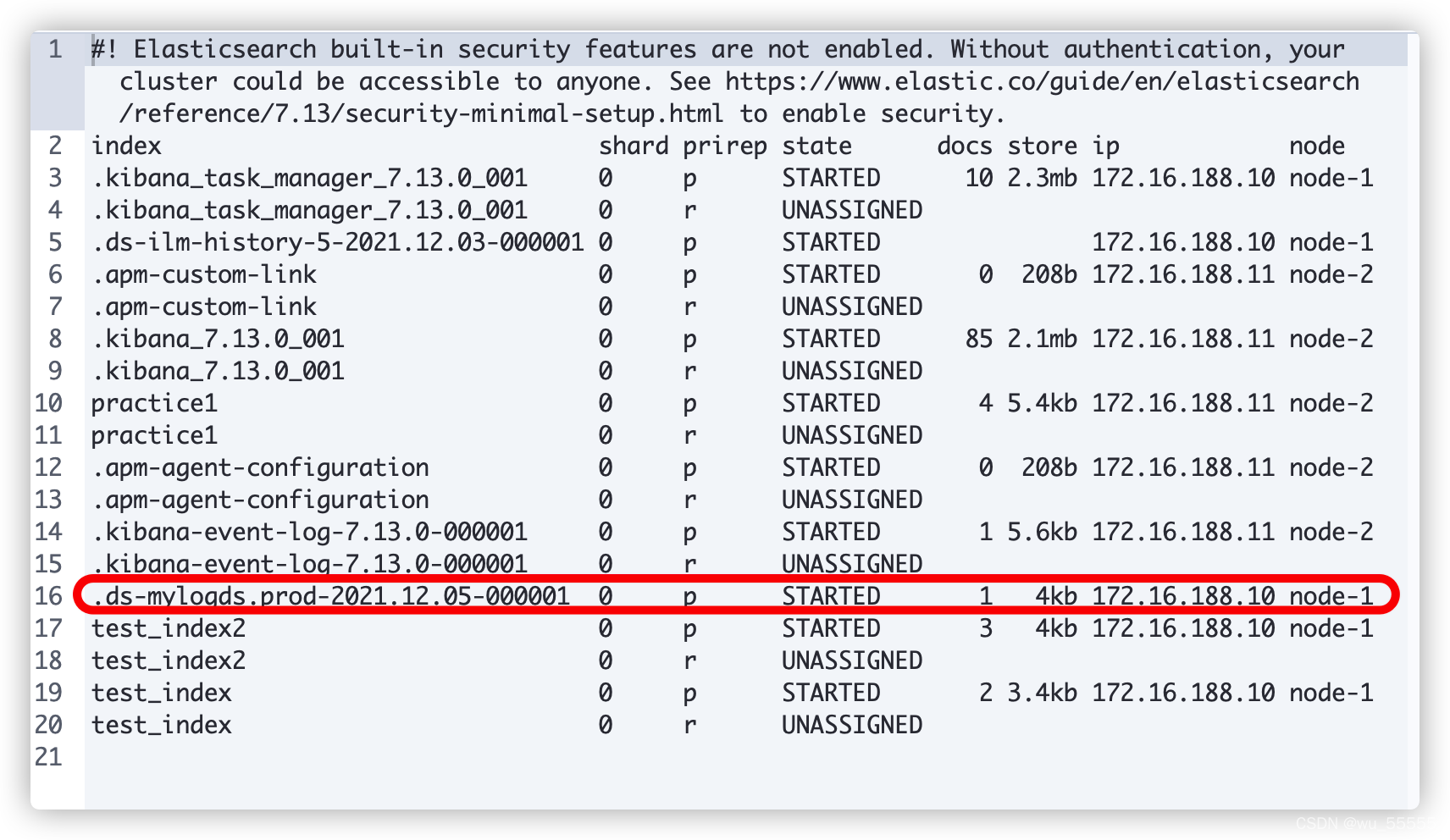
6s时:索引转移到node2
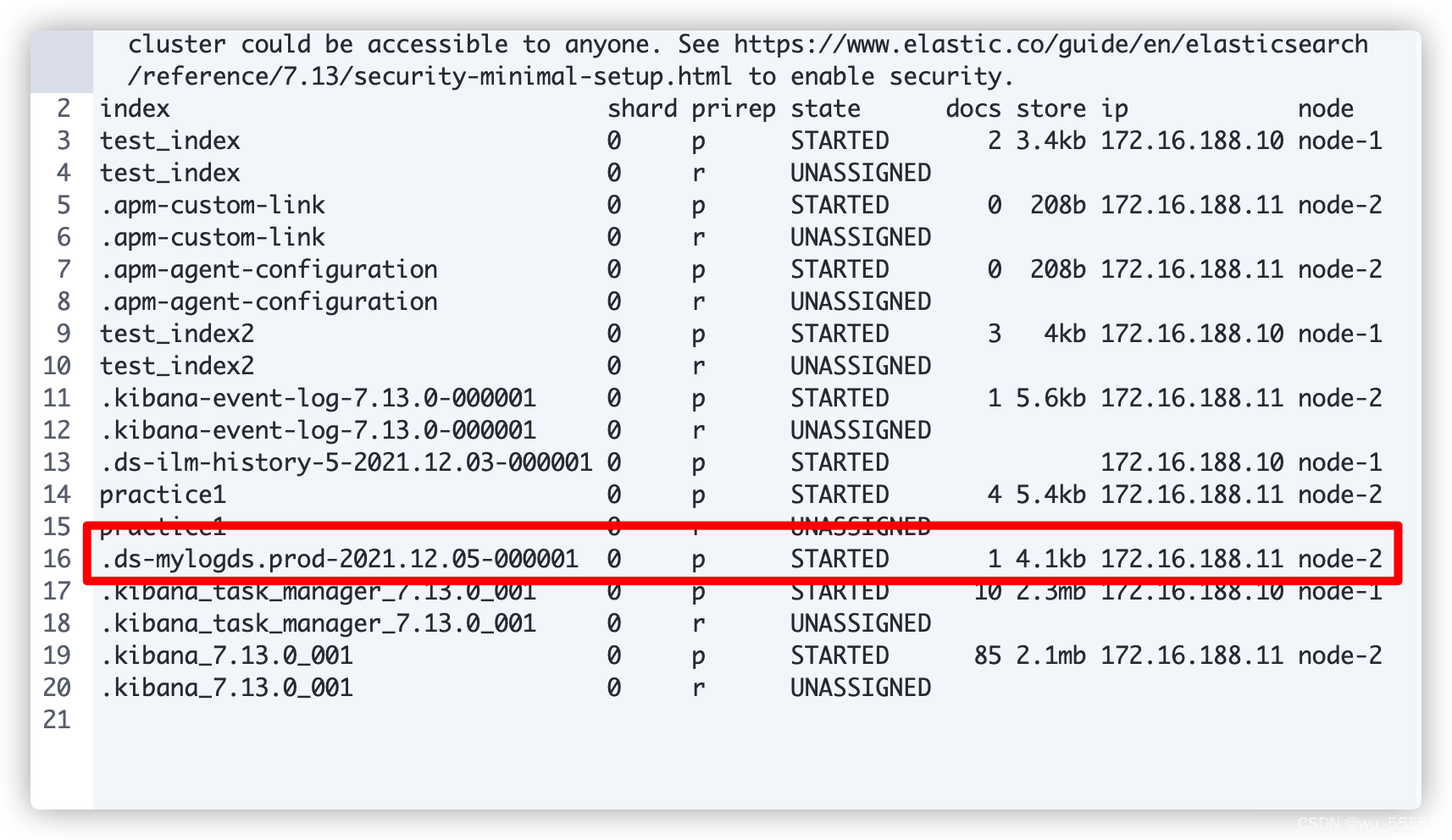
9s时:索引转移到node3
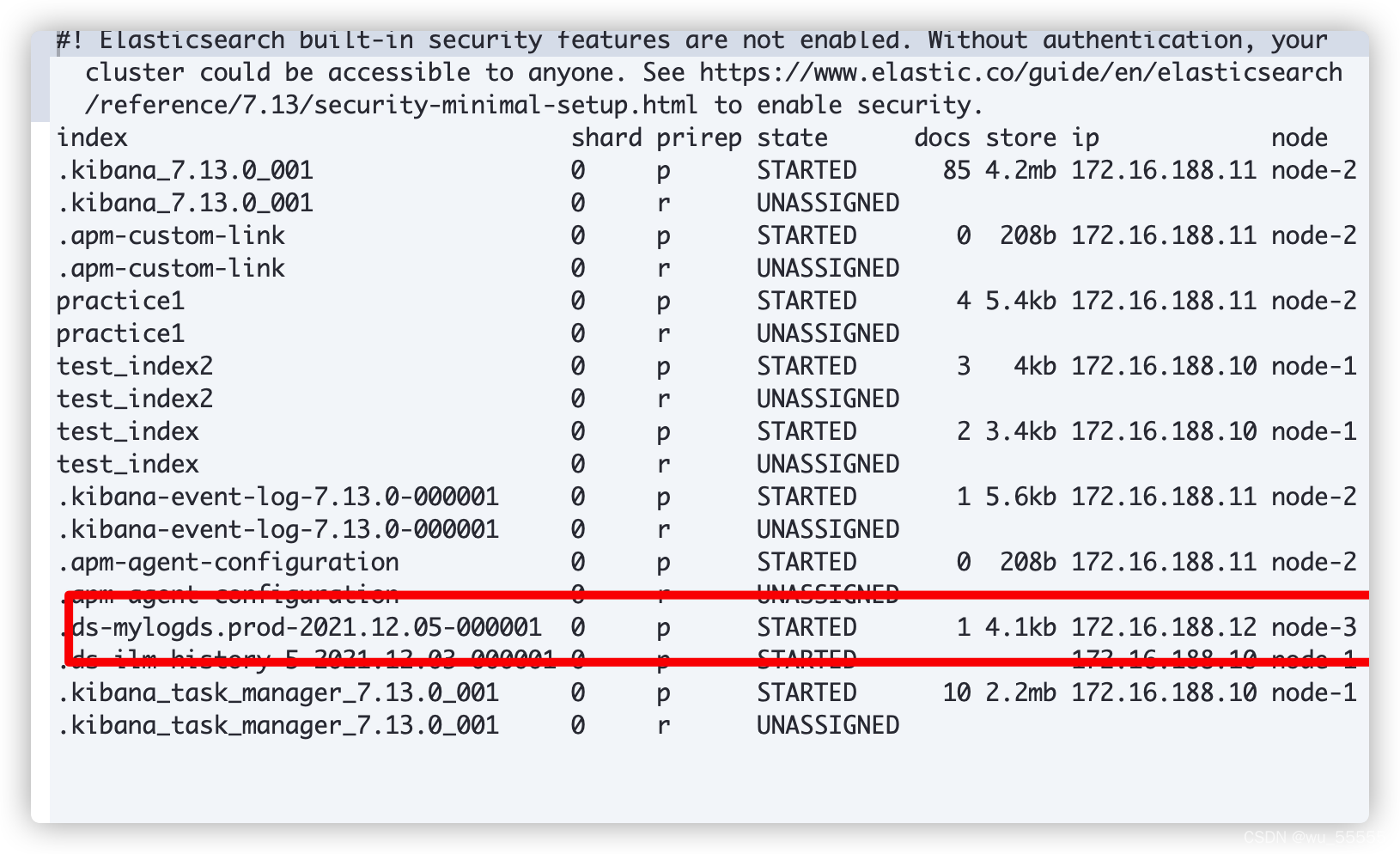
15s时:索引已被删除
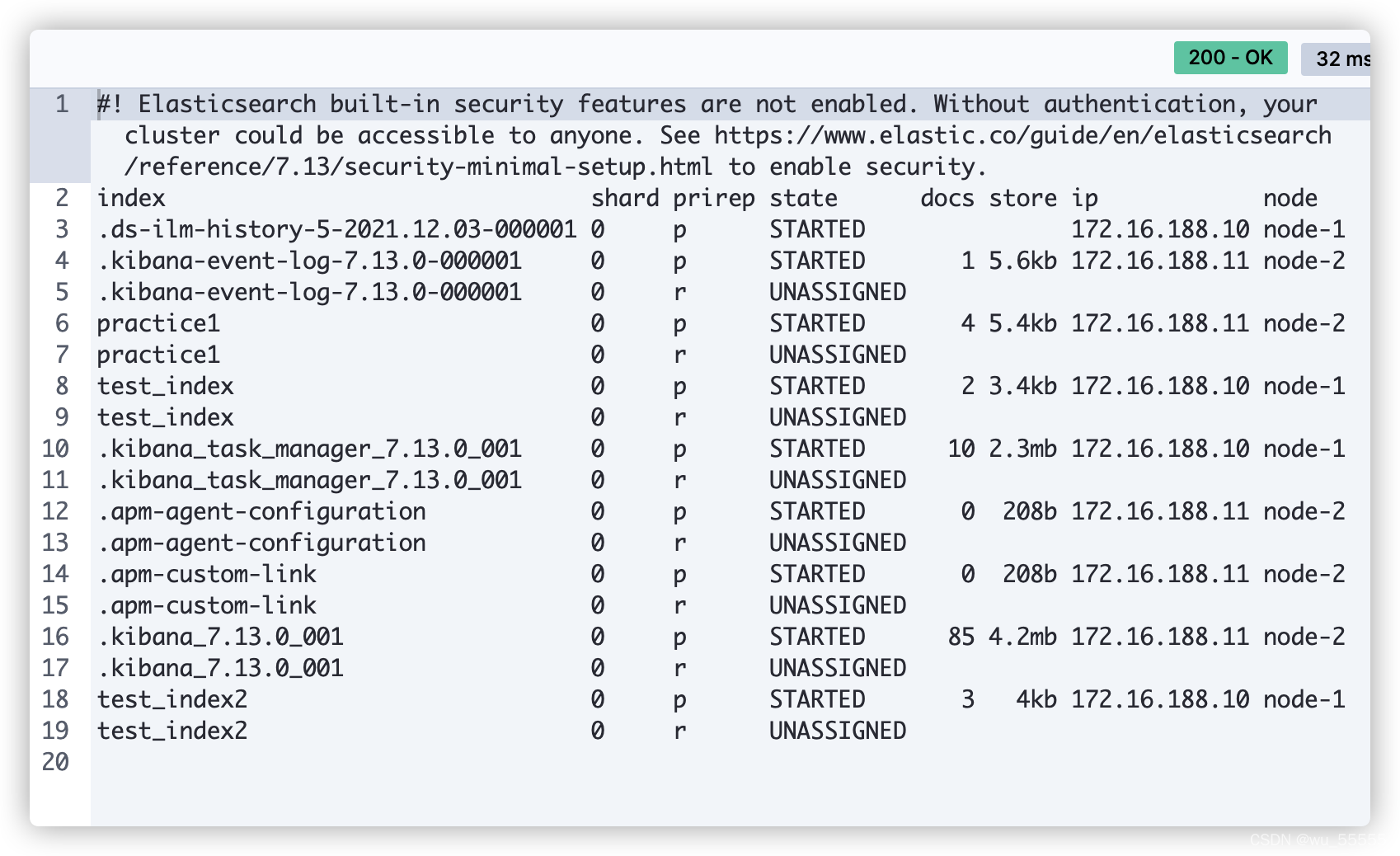
实验结果符合预期
4.易错点
1、配置了data_hot/data_warm/data_cold,还要再配置一个data_content,但不能配置data角色
2、kibana创建ILM时,如果不需要rollover,需要手动关闭
5.推荐阅读

- 点赞
- 收藏
- 关注作者
评论(0)