Elastic:深入了解数据流Data Stream

引言
最近看到不少同学反馈数据流的问题,特针对数据流谈谈自己的理解,以供大家参考。
【有错误的地方望指出】
什么是数据流
首先我们来看官方解释:
数据流让你在多个索引中存储仅有附加的时间序列数据,同时给你一个单一的命名资源来进行请求。数据流非常适用于日志、事件、指标和其他连续产生的数据。
你可以直接向数据流提交索引和搜索请求。数据流会自动将请求路由到存储数据流的备份索引。你可以使用索引生命周期管理(ILM)来自动管理这些支持索引
整理一下,数据流的定义就是可以跨多个索引存储,仅限于追加存储的时间序列数据,同时为请求提供单个命名资源
是不是听起来有些模糊,没关系,我们先从定义中抽离出数据流的几个关键点:
1、跨多个索引存储:这个比较好理解,我们在创建数据流的时候就能体现出来了,一个数据流是由多个索引组成的
2、仅限追加存储:针对这句话的理解,我查阅了一些资料,很多的解释是说不能修改和删除,但是针对这点我测试后发现是存在差异的,结论是数据流本身可以删除,数据流中的索引数据也可以修改和删除,只能说你不能直接通过索引修改和删除,具体我们在后续的案例中详解。
3、时间序列数据:数据流实际上就是一串按时间排列的索引数据的集合,这一点我们待会在例子中详细体会
4、提供单个命名资源:数据流中的所有索引数据都可以通过数据流名来访问,因此具备了一个天然的别名
数据流有什么用
好了,以上就是数据流的解释,那么它可以做什么呢?其实官方文档中也给出定义了,数据流非常适用于日志、事件、指标和其他连续产生的数据。也就是说只要你的数据是随着日期连续产生的,那么理论上数据流就可以派上用场了。
数据流和索引有什么区别
我用下面的一张图来表示他们的关系,蓝色部分是数据流,黄色部分是数据流中的索引,所以他们直接的关系就是数据流是索引的集合,索引是数据流的元素。并且数据流中的索引都是按照时间排序的。下面我们具体通过案例来体会他们之间的关系。
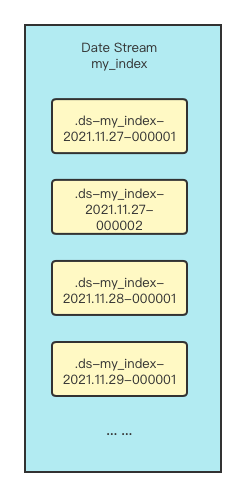
数据流中的索引会以如下的约定命名:
data-stream-name:是数据流名称
yyyy.MM.dd:是当前的日期
generation:是6位自增流水号,从000001开始
.ds-<data-stream-name>-<yyyy.MM.dd>-<generation>
创建数据流
通过ilm管理数据流
官方文档中有对数据流创建的的步骤有详细解析:

但是实际上这里有一个点没有交代清楚,从而让大家对数据流产生了知识盲点,那就是第一步中配置ILM,其作用并不是为了创建数据流,数据流的创建与ILM无关,ILM的存在是为了管理数据流,为什么把它放在第一步,是因为我们在创建索引模版的时候要指定数据流的方式,也就是指定ILM策略,所以需要把ILM先创建出来,如果我们只是单纯地把他创建出来,是不需要配置ILM的,但是实际运用中,我们总不至于把数据流“生”下来,却又不管他吧,那“生”它干嘛呢,所以官方文档中把ILM的创建放到了第一步,但是如果我现在让你只创建一个数据流出来,你说还需要创建ILM吗?
通过索引模版创建数据流
为什么单独说明不配置ILM而创建数据流的形式,是因为ECE考题中有一道题目,只要求了创建数据流,而没有要求用ILM管理,所以我们先来看看这道题怎么做:
创建数据流。索引pattern是mymetrics-*.* , 按要求在mappings里增加4个字段,host.name, error.message, timestamp, tags (数组), 而且host.name 和tags是keyword only,error.message是text only并用standard analyzer。 然后根据这个模板创建一个数据流,命名为 mymetrics-exam.prod。题目中给出了一条数据,把这条数据插入该数据流
1 创建组件模版,声明mapping
PUT _component_template/my-mappings
{
"template": {
"mappings": {
"properties": {
"timestamp": {
"type": "date"
},
"error": {
"properties": {
"message": {
"type": "text",
"analyzer": "standard"
}
}
},
"host": {
"properties": {
"name": {
"type": "keyword"
}
}
},
"tags": {
"type": "keyword"
}
}
}
}
}
2 创建索引模版,申明索引匹配格式,引用组件模版
PUT _index_template/my-index-template
{
"index_patterns": ["mymetrics-*.*"],
"data_stream": { },
"composed_of": [ "my-mappings"]
}
这里要重点说明一下:
可能大家会有一个疑问:明明创建的是索引模版,设置的是索引模版的命名匹配格式,和创建数据流有什么关系?"data_stream": { }配置的作用是什么?
针对上述问题,我个人的理解比较简单粗暴,"data_stream": { }的作用就是申明这个索引模版是给数据流用的,而不是给索引用的。匹配到这个模版的都会被创建为数据流。所以这个时候其实把这个模版成为数据流模版更容易理解。
并且因为被申明为了数据流模版,那么插入的数据doc中就必须带有一个date或date_nanos类型的字段,还必须叫@timestamp。这个是硬性规定。
3 创建数据流,并插入数据
POST mymetrics-exam.prod/_doc
{
"@timestamp": "2021-01-01",
"timestamp": "2021-01-01",
"host": {
"name": "xx"
},
"error": {
"message": "xx"
},
"tags": [
"ss",
"ss"
]
}
@timestamp字段的作用/@timestamp字段为什么值都可以吗?
因为数据流是时间序列数据,所以就需要有一个字段来表示当前日期, 而数据流中就是默认了用@timestamp来充当这个日期字段,所以也要求了字段类型必须为日期类型,如果在mappings中指定了这个@timestamp的数据类型及时间格式,那么后续就要按照这个格式传值,如果没有指定@timestamp字段的mapping,那么就会设置为默认的日期类型
下面我们来做一些关于@timestamp这个字段的没什么用但却能加深你理解的测试:
@timestamp不传会怎么样
# @timestamp不传
POST my_index-/_doc
{
"name": "55555"
}
输出结果:报错
{
"error" : {
"root_cause" : [
{
"type" : "mapper_parsing_exception",
"reason" : "failed to parse"
}
],
"type" : "mapper_parsing_exception",
"reason" : "failed to parse",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "data stream timestamp field [@timestamp] is missing"
}
},
"status" : 400
}
@timestamp没有设置mapping,并将值设置为非日期类型
# @timestamp没有设置mapping,并将值设置为非日期类型
POST my_index-/_doc
{
"@timestamp": "5555",
"name": "55555"
}
输出结果:创建成功
{
"_index" : ".ds-my_index--2021.11.27-000001",
"_type" : "_doc",
"_id" : "1_lHYn0BmTzDpXORhxl2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
@timestamp设置了mapping,并将值设置为非日期类型
DELETE _data_stream/my_index-
DELETE _index_template/my-index-template
PUT _component_template/my_com
{
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date",
"format": ["yyyy-MM-dd HH:mm:ss"]
}
}
}
}
}
PUT _index_template/my-index-template
{
"index_patterns": ["my_index-*"],
"data_stream": { },
"composed_of": ["my_com"]
}
POST my_index-/_doc
{
"@timestamp": "5555",
"name": "55555"
}
结果:报错
{
"error" : {
"root_cause" : [
{
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [@timestamp] of type [date] in document with id '2vlQYn0BmTzDpXORCxnM'. Preview of field's value: '5555'"
}
],
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [@timestamp] of type [date] in document with id '2vlQYn0BmTzDpXORCxnM'. Preview of field's value: '5555'",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "failed to parse date field [5555] with format [[yyyy-MM-dd HH:mm:ss]]",
"caused_by" : {
"type" : "date_time_parse_exception",
"reason" : "Text '5555' could not be parsed, unparsed text found at index 0"
}
}
},
"status" : 400
}
建议大家按照上述的例子,实操一遍,体会下实际报错
ILM是如何管理数据流的?
ILM中会设置数据流新索引的创建条件,比如doc数超过10条,内存占用超过200M,存储时间超过5小时等等。
创建组件模版时会指定所使用的ILM
PUT _component_template/my-settings
{
"template": {
"settings": {
"index.lifecycle.name": "my_policy",
"index.routing.allocation.require.hotcoldwarm": "data_hot",
"number_of_shards": 1,
"number_of_replicas": 0
}
}
}
然后组件模版会被索引模版引用,这里的索引模版因为开启了data stream,所以可以理解为数据流模版,当有索引插入数据,其索引名满足数据流模版的匹配格式,那么就认为这条索引数据实际上要创建数据流,自动将其转为数据流,并且匹配上ILM进行自动化管理。
后续继续插入数据时,当满足了ILM策略创建新索引的条件时,就会对该数据流创建一个新的索引进行存储
关于数据流操作的一些问题
数据流可以删吗
可以。使用以下指令即可以删除
DELETE _data_stream/<data-stream-name>
数据流可以修改吗
不能直接修改,可以通过_update_by_query修改数据流索引中的数据
数据流里的索引可以删吗
可以,可以通过_delete_by_query删除,但是不能直接删除
DELETE .ds-my_index--2021.11.27-000001 报错
POST /my_index-/_delete_by_query { "query": { "match": { "name": "55555" } } } 成功
数据流里的索引可以修改吗
可以,通过_update_by_query即可实现
POST /my_index-/_update_by_query
{
"query": {
"match": {
"name": "55555"
}
},
"script": {
"source": "ctx._source.name = '5+++' "
}
}
结论
不要把数据流视为洪水猛兽,你对它模糊害怕,只是因为你接触的少,多写几遍,多翻翻官方文档,你就会发现,数据流就那么点知识点,就是一串时间序列数据。一般用ILM进行管理,而ECE考题中出现的不要ILM管理的情况,不是说你对数据流的掌握有什么没有学完,而是考题中并没有把这个点考全,他仅仅只是让你创建,还没有涉及到管理,所以没有用到ILM,而数据流完整的应用是要结合ILM实现自动化管理的

- 点赞
- 收藏
- 关注作者
评论(0)