Elastic:浅谈倒排索引的两种压缩算法:FOR算法和RBM算法

什么是倒排索引
首先了解mysql的都知道索引的根本目的是为了提高查询效率,类似于目录的作用。所以倒排索引也是这样的作用,想象一下在ES中,有一个索引index1(这里的索引index1与上述的倒排索引中的索引是两个概念,注意区分),其有数据如下
POST index1/_bulk
{"index":{"_id":1}}
{"name":"this is banana"}
{"index":{"_id":2}}
{"name":"this is apple"}
{"index":{"_id":3}}
{"name":"i like apple"}
{"index":{"_id":4}}
{"name":"i like banana"}
为了实现从索引中能够查询某个关键字,那么就需要先对doc进行分词(这里实际是对字段进行分词,但是因为一个doc中只有一个字段,所以简写成对doc进行分词,但概念上要注意区分),结果如下
doc1: this,banana
doc2: this,apple
doc3: i,like,apple
doc4:i,like,banana
如果是这种方式进行查询的话,比如要查询apple,那么就要遍历所有的doc才能找到doc2,doc3符合条件。这种方式就称为正向索引。
但是这已经遍历了全表了,效率自然不高。
那么想想有没有什么方式提高效率呢?
没错,就是直接以分词为主题,列出哪些doc1包含该分词
banana: doc1,doc4
this: doc1,doc2
apple: doc2,doc3
… …
因此这样的话,直接查询前面的分词列表,然后获取对应的doc id即可,很快就能定位到apple的doc是doc2,doc3。这种方式就是倒排索引
倒排索引为什么需要压缩算法
想象一下,针对term(词项)其记录的倒排索引是
banana: 1,4
this: 1,2
apple: 2,3
现在的doc数量不多,如果现在doc一共有10000行,那么term的倒排索引可能就会变成
banana: 1,2,3,4,78,90,1000,1001,1002,1003,9998,9999
所以实际存储的就是一个个有序数组,如果直接存储的话就需要占用4byte * 12 = 48byte(1int占用4byte)
而有序数值数组是比较容易进行压缩处理的,而且一般来说压缩效益也不错,如果能对其进行压缩是能够大大节约空间资源的。
FOR算法(Frame Of Reference)
FOR算法的核心思想是用减法来削减数值大小,从而达到降低空间存储。
假设V(n)表示数组中第n个字段的值,那么经过FOR算法压缩的数值V(n)=V(n)-V(n-1)。也就是说存储的是后一位减去前一位的差值。存储是也不再按照int来计算了,而是看这个数组的最大值需要占用多少bit来计算
具体我们通过一个例子来体会:
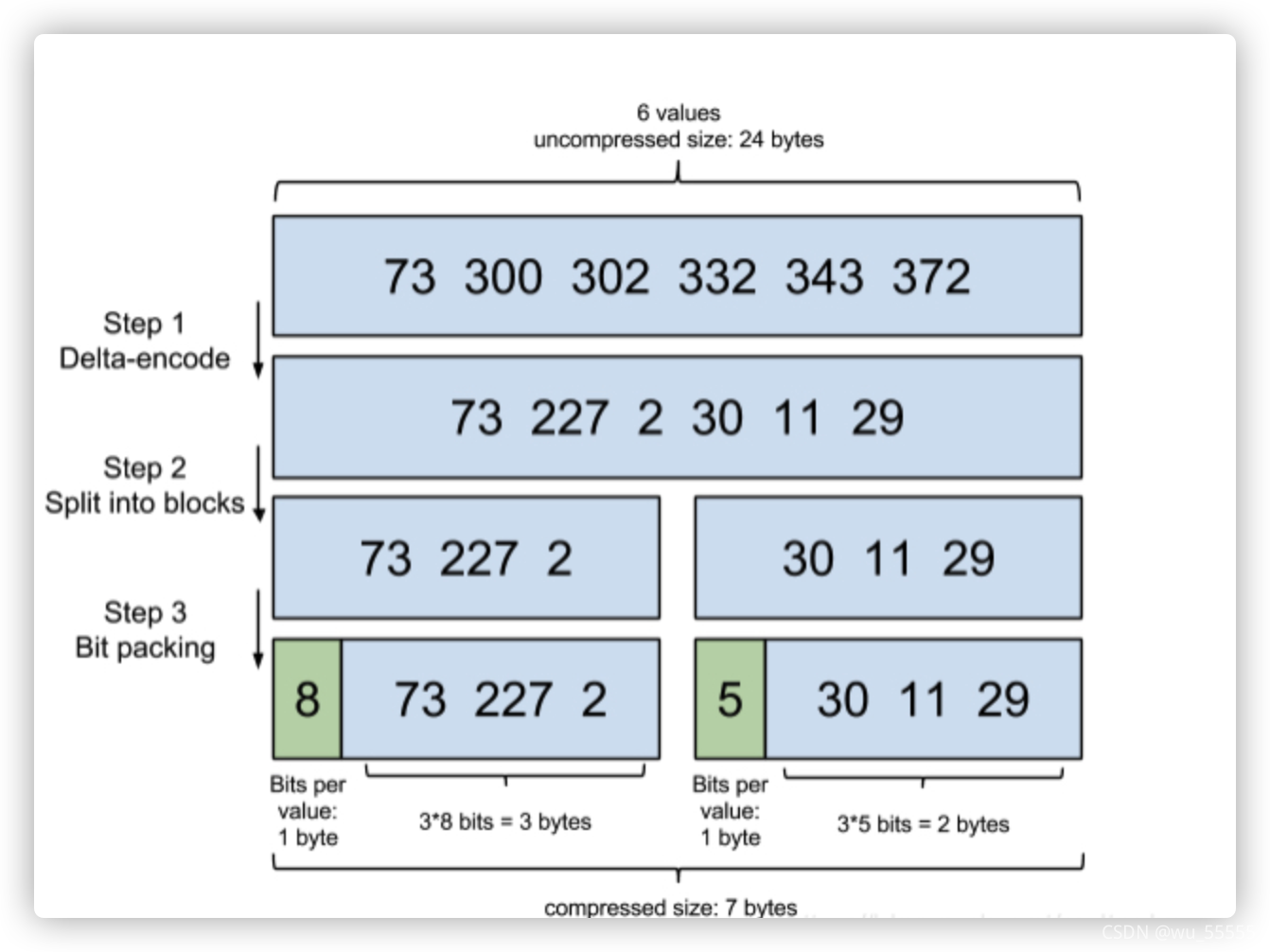
比如数组是73,300,302,332,342,372,原本需要4 * 6 byte = 24byte = 192bit
压缩后:73,227,2,30,11,29
这些数中227是最大的,需要8bit(227 < 2^8)来盛装,那么每个数值都不会超过8bit,所以需要的大小是6 * 8bit=48bit,我们把8bit的容器理解为一个箱子,总共需要6个箱子,所有箱子占48bit,但是这并不是我们的总大小,因为相比较于原数组,我们引入了一个箱子的概念,那么除了箱子数,我们还需要记录每个箱子的大小,所以需要有一个数来记录箱子大小,这里注意我们规定盛装大小不超过256bit,因此箱子大小值最大不超过2^8,即箱子大小值占用不超过8bit,因此总共的大小是48bit+8bit = 56bit
可以看到压缩后大小由192bit降到了56bit,已经有很大改善了,但是这还不是FOR算法的终点,观察这组数中最大值227,后一位最小值是2,两者相差很大,2实际上只需要1bit来盛装,那么能不能进一步压缩呢?答案是可以,只是不再需要做差值,直接将数组分组,将其拆分为:
73,227
2,30,11,29
那么占用空间就变成了73,227箱子大小8bit,2,30,11,29中最大30,箱子大小为5bit
因此数组总大小为28bit + 45bit = 36bit,另外不要忘记这里因为分成两组,还需要单独记录两组箱子的大小值,所以总大小是36bit+2*8bit= 52bit
可以看到大小又变小了,但是思考一个问题:是不是还可以进行压缩?是越小越好吗?
是可以再压缩,但是我们还要考虑解码的问题,数据压缩后是要使用的,因此需要解码,压缩得越深,解码越耗时,因此不是越小越好,那么在哪里取一个平衡,这就是通过计算机动态计算的,计算方法这里不做深一步讨论了,大家理解这个概念即可
以上就是FOR算法的概念,总结一下:
(1)数组元素值为与前一位的差值V(n)=V(n)-V(n-1),n=2,3,4…
(2)计算数组中最大值所需占用的大小
(3)计算数组是否需要拆分,计算拆分后每组的最大值所需占用的大小并记录
RBM算法(RoaringBitMap)
有了FOR算法为什么需要别的算法呢?说明FOR算法本身是有缺陷的,那么思考一下FOR算法的缺陷在哪里?
FOR算法的核心是用减法来缩减数值大小,但是减法一定能缩减大小吗?但数值大小很大时,减法能够达到的效果是不明显的,比如100W,200W,300W,相减后是100W,100W,100W,依然很大,这时的压缩效果很不理想,所以引入了RBM算法
那么大家再思考一下,既然减法不能满足,那么还有什么方法能够更快地减小数值大小呢?
没错,就是除法!
RBM的核心就是通过除法来缩减数值大小,但是并不是直接的相除。
比如数组为1000,62101,131385,191173,196658
其中196658的二进制表示为0000 0000 0000 0011 0000 0000 0011 0010
然后将其高16位和低16位分别转换为10进制:
0000 0000 0000 0011 -> 3
0000 0000 0011 0010 -> 50
那么196658就转换成了(3,50)的表示形式,其效果就相当于除以2^16,商3余50
这里的计算用位运算会更快更好理解,除以2^n相当于将这个数的二进制向右位移n位(不含符号位),并且用0补足空位。容易得出196658二进制右移16位后为
0000 0000 0000 0000 0000 0000 0000 0011
也就是其高16位,前面用0补足,而被位移顶替掉的就是其余数0000 0000 0011 0010
因为商和余数都不超过16位,那么我们最大用16bit来存储足够了。也就是short类型
因此商和余数都可以用一个short来盛装,那么所有的商就是一个short[],所有的余数就是一个short[][]
将原数组除以2^16得:
(0,1000),(0,62101),(2,313),(2,980),(2,60101),(3,50)
转化为二维数组盛装
0: 1000,62101
2: 313,980,60101
3: 50

我们把每一个商所对应的余数short[]称之为一个容器Container,使用上述所说的short盛装也称为ArrayContainer
我们也容易观察发现到,每一个Container实际上都是有序数值数组,是不是能够联想到什么?
数组还能进行压缩吗?
数组能用FOR算法再压缩吗?
有别的方式再进行压缩吗?
首先回答前两个问题:数组肯定可以压缩,而且正是我们需要去做的;用FOR算法在这里进行压缩是可以的,不算错,但是我们说不合适,正如在FOR算法中介绍的那样,压缩的同时我们还有考虑解码时的效率,其实这里已经经过除法做了一次处理了,那么再用减法做一次处理,再解码时效率会降低不少,所以我们追求的是一种解码更加容器,但又能具备压缩能力的方法
那么怎么找这种方法呢?在阐明这个方法前,我先抛出一个问题,熟悉java容器的同学应该比较了解:现在有10亿条11位的电话号码,请问如何用2G的空间将他们存储下来?
首先11位的电话号码用int是无法存储的,所以就要考虑用String和Long。显然用String不划算,如果用Long,那么8byte * 10亿 = 80亿byte = 7.45G
所以用Long来存储显然不行,那么有没有一种更加高效的容器?我们知道电话号码虽然不是连续的,但是当数量足够多时,我们可以大概认为他们是连续的,所以11位的电话号码。实际上就是10000000000 ~ 200000000000,那么我们用bit来存储一个数是否存在,现在定义有100亿位数,那么就可以存储100亿个数,用1表示对应位上的数存在。因为电话号码是11位,最小是10000000001,我们把右数第1位定义为10000000001,也就是说13866668888的表示是将第3866668888上设置为1: 0000…0001000.0000
因此电话号码phone的存储方式就是将第N-10000000000位上的数设置为1.判断电话号码是否存在的时候我们只需要判断对应位上的数是否为1即可。这样的话一共使用100亿bit=1192M就可以存下,不到2G满足要求。
当然以上是理想状态,那么我们实际中该怎么存储呢,那就是使用数组,我们知道long占64位,也就是说一个long可以表示64个数,那么100亿个数就需要156250000个long,我们就需要定义一个long[156250000]数组arr
存储电话号码phone: arr[(phone-10000000000)/64] | (1 << ((phone-10000000000)%64))
判断电话号码是否存在:arr[(phone-10000000000)/64] & (1 << ((phone-10000000000)%64)) > 0
通过上述的bit存储的方式来存储数据,就是使用bitmap的形式来存储数据,了解这个知识后我们再来看之前的问题,以下的二维数组,每一个Container中的数据当量足够多时我们认为他是有序连续的:
0: 1000,62101
2: 313,980,60101
3: 50
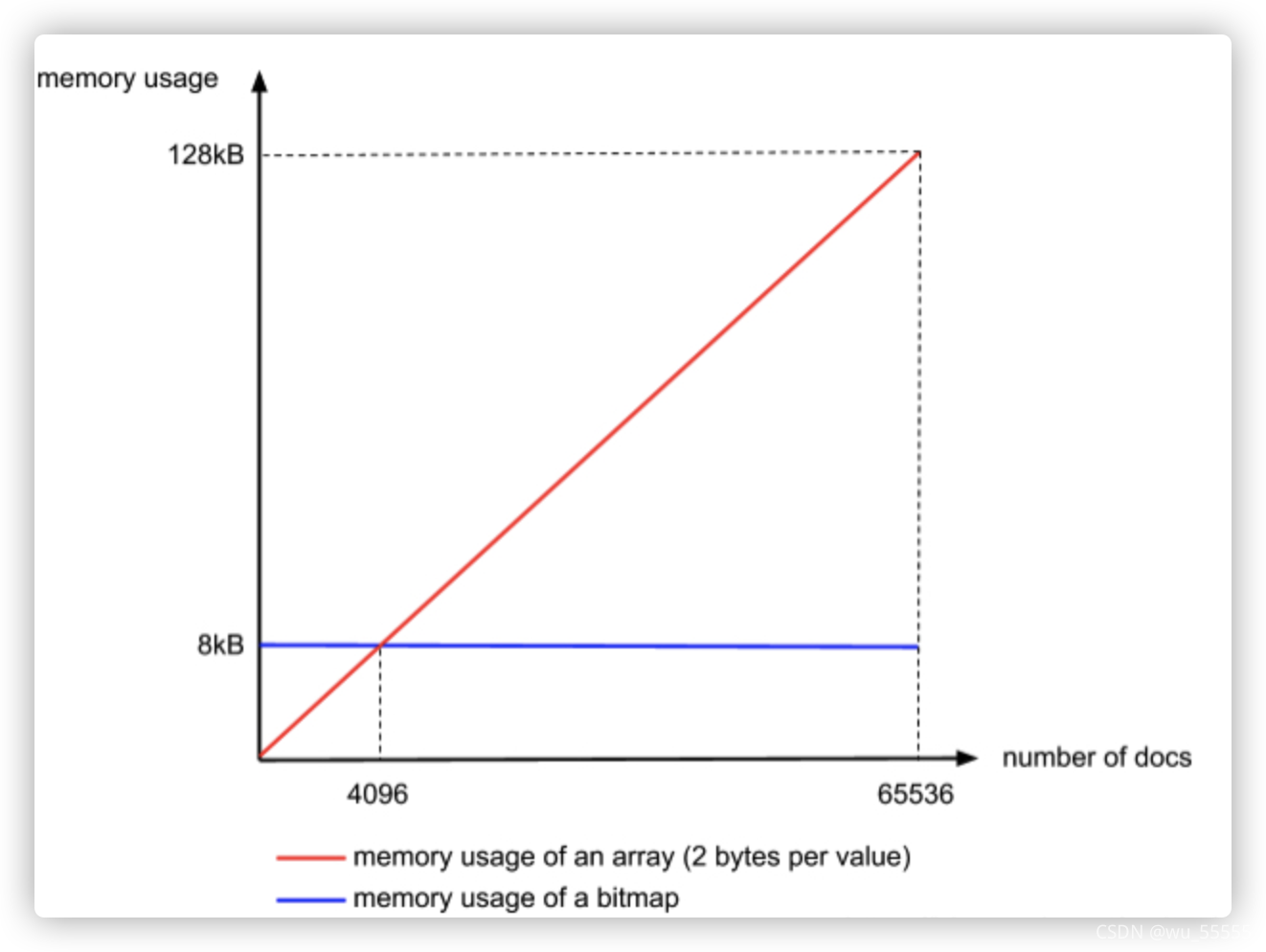
因此我们就可以使用bitmap来存储数据,按照规定一个Container的最大值是65534(这里为什么最大值是65534,思考一下,如果不明白往上看看原数组是怎么处理的),也就需要65535bit=8k的容器来存储,当然bitmap有个很明显的缺点,那就是无论Container中有多少个数,都要占用8k的大小,所以当数量不超过65535bit /16bit = 4096个时,使用short (16bit)来存储更划算,当每个Container的数量超过4096个时使用bitmap更加划算,那么使用bitmap的Container称为BitmapContainer
还有一个Container叫RunContainer,专门用来解决连续数组存储的,比如[1,2,3,100W],那么可以表示为[1,100W],只存储一个最小值和最大值,如果数组是如下形式
[1,2,3,4,5,100,101,102,999,1000,1001]
就会被拆分为三段:[1,5],[100,102],[999,1001]
综上Container有三种:ArrayContainer,BitmapContainer,RunContainer
RBM算法的核心步骤如下:
(1)数组中每个数除以2^16,以商,余数的形式表示出来
(2)将相同商的归在一个Container,如果Contaniner中数值容量超过4096使用bitmap的形式来存储一个Container中的数,如果没有超过那就使用short[]来存储,如果是连续数组那就使用RunContainer来存储

- 点赞
- 收藏
- 关注作者
评论(0)