如何在DBNet中加入新的主干网络

【摘要】 摘要这篇文章告诉大家如何在DBnet中加入新的主干网络。通过这篇文章你可以学到如何将现有的主干网络加入到DBNet中,提高DBNet的检测能力 主干网络我加入的网络是ConvNext。代码详见:# Copyright (c) Meta Platforms, Inc. and affiliates.# All rights reserved.# This source code is lic...
摘要
这篇文章告诉大家如何在DBnet中加入新的主干网络。通过这篇文章你可以学到如何将现有的主干网络加入到DBNet中,提高DBNet的检测能力
主干网络
我加入的网络是ConvNext。代码详见:
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPath
from timm.models.registry import register_model
class Block(nn.Module):
r""" ConvNeXt Block. There are two equivalent implementations:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
We use (2) as we find it slightly faster in PyTorch
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class ConvNeXt(nn.Module):
r""" ConvNeXt
A PyTorch impl of : `A ConvNet for the 2020s` -
https://arxiv.org/pdf/2201.03545.pdf
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.,
):
super().__init__()
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward_features(self, x):
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
class LayerNorm(nn.Module):
r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
model_urls = {
"convnext_tiny_1k": "https://dl.fbaipublicfiles.com/convnext/convnext_tiny_1k_224_ema.pth",
"convnext_small_1k": "https://dl.fbaipublicfiles.com/convnext/convnext_small_1k_224_ema.pth",
"convnext_base_1k": "https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_224_ema.pth",
"convnext_large_1k": "https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_224_ema.pth",
"convnext_base_22k": "https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pth",
"convnext_large_22k": "https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_224.pth",
"convnext_xlarge_22k": "https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_224.pth",
}
@register_model
def convnext_tiny(pretrained=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], **kwargs)
if pretrained:
url = model_urls['convnext_tiny_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def convnext_small(pretrained=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[96, 192, 384, 768], **kwargs)
if pretrained:
url = model_urls['convnext_small_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def convnext_base(pretrained=False, in_22k=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024], **kwargs)
if pretrained:
url = model_urls['convnext_base_22k'] if in_22k else model_urls['convnext_base_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def convnext_large(pretrained=False, in_22k=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536], **kwargs)
if pretrained:
url = model_urls['convnext_large_22k'] if in_22k else model_urls['convnext_large_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def convnext_xlarge(pretrained=False, in_22k=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[256, 512, 1024, 2048], **kwargs)
if pretrained:
url = model_urls['convnext_xlarge_22k'] if in_22k else model_urls['convnext_xlarge_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
操作过程
修改主干网络
我们把上面的代码改造成DBNet的主干网络。
DBNet的代码:https://github.com/WenmuZhou/DBNet.pytorch
将其下载下来。
然后在./models/backbone下面新建convnext.py脚本。
将上面的代码,插入进来。
然后修改ConvNeXt的 forward()函数,修改为:
def forward(self, x):
x= self.downsample_layers[0](x)
x2 = self.stages[0](x)
x = self.downsample_layers[1](x2)
x3 = self.stages[1](x)
x = self.downsample_layers[2](x3)
x4 = self.stages[2](x)
x = self.downsample_layers[3](x4)
x5 = self.stages[3](x)
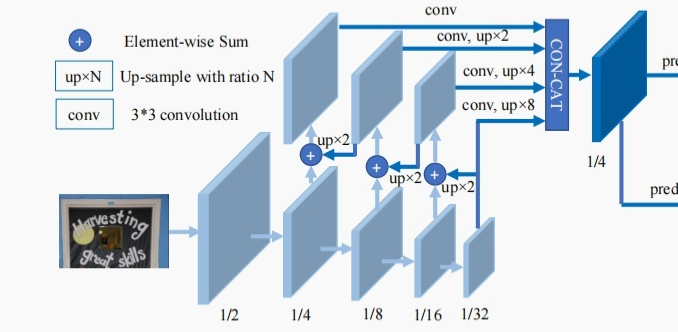
return x2,x3,x4,x5
和网络图对应起来。
在 def __init__函数中 增加out_channels属性
self.out_channels=dims
将in_chans改为in_channels,这样就能和配置文件的字段对上了。
删除@register_model
接下来修改创建模型的部分,用convnext_tiny举例
def convnext_tiny(pretrained=False, **kwargs):
model = ConvNeXt(depths=[2, 2, 3, 3], dims=[96, 192, 384, 768], **kwargs)
if pretrained:
url = model_urls['convnext_tiny_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"],strict=False)
return model
原始的convnext_tiny很大,我在这里把depths做了修改,
将depths=[3, 3, 9, 3]改为depths=[2, 2, 3, 3],设置strict为False,防止预训练权重对不上报错。
在代码的开始部分增加:
__all__ = ['convnext_tiny', 'convnext_small', 'convnext_base']
这样可以访问的方法就这三个了。
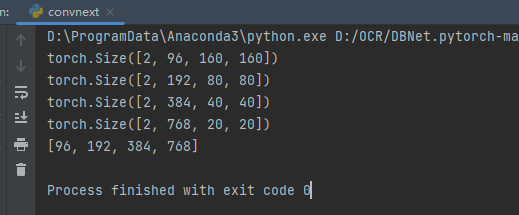
修改完成后测一下:
if __name__ == '__main__':
import torch
x = torch.zeros(2, 3, 640, 640)
net = convnext_tiny(pretrained=False)
y = net(x)
for u in y:
print(u.shape)
print(net.out_channels)
完整代码:
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPath
__all__ = ['convnext_tiny', 'convnext_small', 'convnext_base']
class Block(nn.Module):
r""" ConvNeXt Block. There are two equivalent implementations:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
We use (2) as we find it slightly faster in PyTorch
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class ConvNeXt(nn.Module):
r""" ConvNeXt
A PyTorch impl of : `A ConvNet for the 2020s` -
https://arxiv.org/pdf/2201.03545.pdf
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_channels=3, num_classes=1000,
depths=[3, 3, 3, 3], dims=[96, 192, 384, 768], drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.,
):
super().__init__()
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_channels, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i + 1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
self.out_channels=[96,192,384,768]
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
# def forward_features(self, x):
# for i in range(4):
# x = self.downsample_layers[i](x)
# x = self.stages[i](x)
# return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x= self.downsample_layers[0](x)
x2 = self.stages[0](x)
x = self.downsample_layers[1](x2)
x3 = self.stages[1](x)
x = self.downsample_layers[2](x3)
x4 = self.stages[2](x)
x = self.downsample_layers[3](x4)
x5 = self.stages[3](x)
return x2,x3,x4,x5
class LayerNorm(nn.Module):
r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape,)
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
model_urls = {
"convnext_tiny_1k": "https://dl.fbaipublicfiles.com/convnext/convnext_tiny_1k_224_ema.pth",
"convnext_small_1k": "https://dl.fbaipublicfiles.com/convnext/convnext_small_1k_224_ema.pth",
"convnext_base_1k": "https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_224_ema.pth",
"convnext_large_1k": "https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_224_ema.pth",
"convnext_base_22k": "https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pth",
"convnext_large_22k": "https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_224.pth",
"convnext_xlarge_22k": "https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_224.pth",
}
def convnext_tiny(pretrained=False, **kwargs):
model = ConvNeXt(depths=[2, 2, 3, 3], dims=[96, 192, 384, 768], **kwargs)
if pretrained:
url = model_urls['convnext_tiny_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"],strict=False)
return model
def convnext_small(pretrained=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[96, 192, 384, 768], **kwargs)
if pretrained:
url = model_urls['convnext_small_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
def convnext_base(pretrained=False, in_22k=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024], **kwargs)
if pretrained:
url = model_urls['convnext_base_22k'] if in_22k else model_urls['convnext_base_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
def convnext_large(pretrained=False, in_22k=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536], **kwargs)
if pretrained:
url = model_urls['convnext_large_22k'] if in_22k else model_urls['convnext_large_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
def convnext_xlarge(pretrained=False, in_22k=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[256, 512, 1024, 2048], **kwargs)
if pretrained:
url = model_urls['convnext_xlarge_22k'] if in_22k else model_urls['convnext_xlarge_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
if __name__ == '__main__':
import torch
x = torch.zeros(2, 3, 640, 640)
net = convnext_tiny(pretrained=False)
y = net(x)
for u in y:
print(u.shape)
print(net.out_channels)
将主干网络加到配置列表
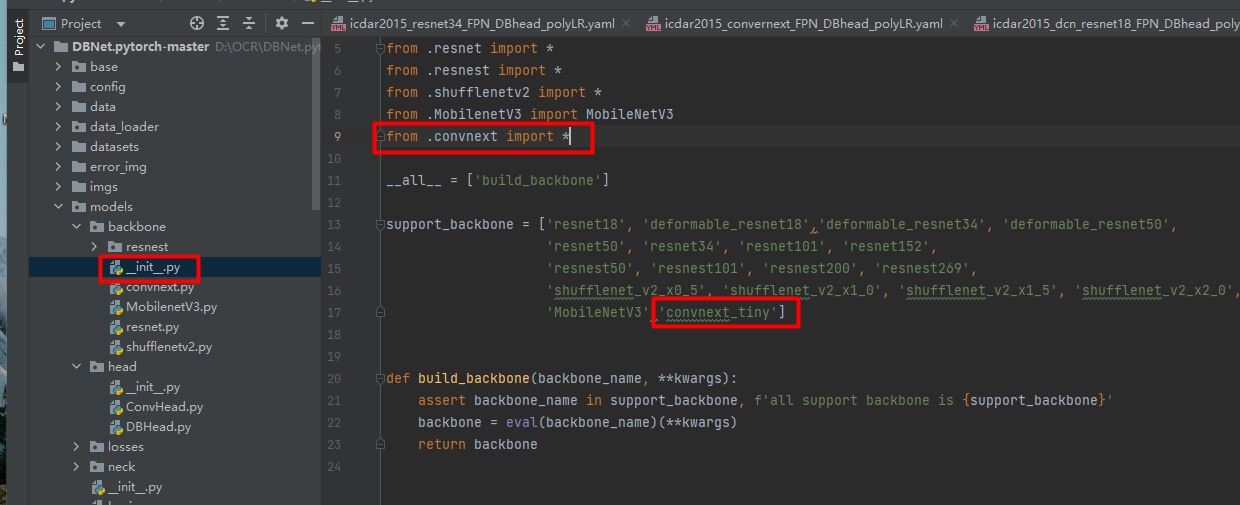
修改完成后,在__init__.py导入convnext,在support_backbone列表中增加convnext_tiny字段,如下图:
接下来在./config文件夹中增加convnext的配置文件,命名为:icdar2015_convnext_FPN_DBhead_polyLR.yaml
从其他的配置文件中复制一份参数,
然后将backbone的type修改为 convnext_tiny
完整代码:
name: DBNet
base: ['config/icdar2015.yaml']
arch:
type: Model
backbone:
type: convnext_tiny
pretrained: true
neck:
type: FPN
inner_channels: 384
head:
type: DBHead
out_channels: 2
k: 50
post_processing:
type: SegDetectorRepresenter
args:
thresh: 0.3
box_thresh: 0.7
max_candidates: 1000
unclip_ratio: 1.5 # from paper
metric:
type: QuadMetric
args:
is_output_polygon: false
loss:
type: DBLoss
alpha: 1
beta: 10
ohem_ratio: 3
optimizer:
type: Adam
args:
lr: 0.001
weight_decay: 0
amsgrad: true
lr_scheduler:
type: WarmupPolyLR
args:
warmup_epoch: 3
trainer:
seed: 2
epochs: 1200
log_iter: 10
show_images_iter: 50
resume_checkpoint: ''
finetune_checkpoint: ''
output_dir: output
tensorboard: true
dataset:
train:
dataset:
args:
data_path:
- ./datasets/train.txt
img_mode: RGB
loader:
batch_size: 2
shuffle: true
pin_memory: true
num_workers: 1
collate_fn: ''
validate:
dataset:
args:
data_path:
- ./datasets/test.txt
pre_processes:
- type: ResizeShortSize
args:
short_size: 736
resize_text_polys: false
img_mode: RGB
loader:
batch_size: 1
shuffle: true
pin_memory: false
num_workers: 1
collate_fn: ICDARCollectFN
然后就可以运行了。


【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)