数据的分组与计算

对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),通常是数据分析工作中的重要环节。在数据集准备好之后,通常就是计算分组统计或生成透视表。pandas 提供了一个灵活高效的 groupby 功能,使我们可以高效地对数据集进行操作。
关系型数据库和 SQL 能够如此流行的原因之一就是其能够方便地对数据进行连接、过滤、转换和聚合。但是,像 SQL 这样的查询语言所能执行的分组运算的种类很有限,而由于 pandas 强大的表达能力,我们可以执行复杂得多的分组运算。
1. 分组
分组操作分为拆分、应用和合并三个阶段。第一个阶段,根据一个或多个键将 pandas 对象中的数据拆分为多组。第二个阶段,将一个函数应用到各个分组并产生一个新值。第三个阶段,将所有函数的执行结果合并到最终的结果对象中。
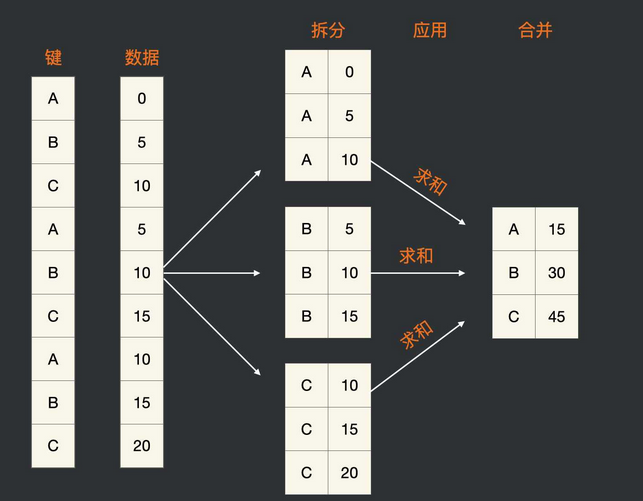
1.1 按单个关键字进行分组
import numpy as np
import pandas as pd
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk = df.groupby("Team")
print(gk.groups)上述代码中,首先按照 Team 对 df 进行分组,然后通过 groups 属性获取到所有的分组。从输出结果可以看出,第 1、2、5 条记录被分到一组,第 3、4 记录被分到一组。如果想看到每个分组的详细数据,我们可以使用循环打印出每个分组。例如:
import numpy as np
import pandas as pd
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk = df.groupby("Team")
for name, grp in gk:
print(name)
print(grp)这样我们便通过循环打印出了每个分组的名称和每个分组的详细数据。如果想获取某一个分组,可以使用 get_group() 方法,调用方法时,只要传入分组的名称即可。例如:
import numpy as np
import pandas as pd
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk = df.groupby("Team")
print(gk.get_group("Bulls"))上面讲的是按照单个关键字进行分组,下面讲一下按照多个关键字进行分组。
1.2 按多个关键字进行分组
按照多个关键字进行分组时,只需要将多个关键字组成一个列表,并将列表作为参数传入到 groupby() 函数中。例如:
import numpy as np
import pandas as pd
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk = df.groupby(["Team", "Position"])
print(gk.groups)从上面代码的输出结果中可以看出,第 2、3、4 条记录各自组成一个分组,第 1 和 5 条记录组成一个分组。分组完成后,像上面按照单个关键字分组一样,我们可以使用循环打印出各个分组的详细信息。例如:
import numpy as np
import pandas as pd
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk = df.groupby(["Team", "Position"])
for name, grp in gk:
print(name)
print(grp)像上面按照单个关键字分组一样,可以使用 get_group() 方法获取某个分组,我们只需要将多个关键字组成一个元组,并把元组作为参数传入到 get_group() 函数中。例如:
import numpy as np
import pandas as pd
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk = df.groupby(["Team", "Position"])
print(gk.get_group(('Bulls', 'PG')))2. 计算
2.1 使用自带函数
上面只是对 pandas 对象进行了分组,还没有进行任何计算,但是已经有了各分组执行运算所需的一切信息。例如,我们可以调用 GroupBy 的 mean() 方法来计算分组平均值:
import numpy as np
import pandas as pd
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk = df.groupby("Team")
print(gk.mean())这样我们便计算了各个分组在 Age 和 Weight 列的平均值。对于按照多个关键字进行的分组,我们同样可以使用 mean() 方法来计算分组平均值。例如:
import numpy as np
import pandas as pd
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk = df.groupby(["Team", "Position"])
print(gk.mean())上面的例子在使用 mean() 方法计算分组平均值时,默认是对所有的数字列都进行求平均值,我们也可以只对部分列求平均值。例如:
import numpy as np
import pandas as pd
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk1 = df.groupby(["Team"])
print(gk1['Age'].mean())
gk2 = df.groupby(["Team", "Position"])
print(gk2['Age'].mean())上面的例子只对 Age 这一列进行求平均值。
2.2 使用自定义函数
上面的例子中,对分组进行求值使用的是 pandas 自带的函数,我们也可以使用自定义的函数。例如:
import numpy as np
import pandas as pd
def peak_to_peak(arr):
return arr.max() - arr.min()
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk1 = df.groupby(["Team"])
print(gk1[['Age', 'Weight']].agg(peak_to_peak))在上面的例子中,我们定义了一个函数 peak_to_peak,并把函数传入到 agg() 中,这样函数 peak_to_peak 便作用到每个分组。agg() 函数不但可以使用自定义的函数,而且可以使用 pandas 自带的函数。例如:
import numpy as np
import pandas as pd
def peak_to_peak(arr):
return arr.max() - arr.min()
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk1 = df.groupby(["Team"])
print(gk1.agg('mean'))使用 pandas 自带函数时,只需要将函数名作为字符串传入到 agg() 函数即可。上面的例子中,当指定一个函数时,这个函数便作用于所有的列,我们还可以对不同的列使用不同的函数,例如:
import numpy as np
import pandas as pd
def peak_to_peak(arr):
return arr.max() - arr.min()
df = pd.DataFrame({
"Team":['Lakers', 'Lakers', 'Bulls', 'Bulls', 'Lakers'],
"Position":['SF', 'PG', 'SF', 'PG', 'SF'],
"Age":[37, 24, 24, 27, 36],
"Weight":[212, 194, 225, 190, 260]
})
gk1 = df.groupby(["Team"])
print(gk1.agg({'Age': 'mean', 'Weight': peak_to_peak}))
- 点赞
- 收藏
- 关注作者
评论(0)