DataFrame 的拼接

在 pandas 中,我们可以使用 concat() 和 merge() 对 DataFrame 进行拼接。
1. concat()
concat() 函数的作用是沿着某个坐标轴对 DataFrame 进行拼接。在 concat() 函数中,有几个常用的参数。
-
axis:指出在哪个坐标轴的方向上进行拼接。可取的值为
0/index,1/columns,默认为 0。 -
join:指出拼接的方式,可取的值为
inner,outer,默认为outer。 -
ignore_index:指出是否使用拼接轴上的索引,可取的值为
False、True,默认为 False。当为 False 时,表示使用拼接轴上的索引;当为 True 时,表示不使用拼接轴上的索引。下面我们就通过例子来看下使用 concat() 函数对 DataFrame 进行的拼接。
1.1 DataFrame 的列索引相同
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([144, 145, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index = ['2021-07-08', '2021-07-09', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2]))在上面的例子中,df1 和 df2 有完全相同的列,所以拼接之后的 DataFrame 的列名也是相同的,拼接的方向为垂直方向。拼接之后使用的索引是原来 DataFrame 的索引。如果不想使用原来的索引可以设置参数 ignore_index。例如:
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([144, 145, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index = ['2021-07-08', '2021-07-09', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2], ignore_index=True))上面代码中,当设置参数 ignore_index=True 时,拼接后的 DataFrame 中便不再使用原来的索引,而是自动生成的索引。
1.2 DataFrame 的列索引有重叠
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Volume": pd.Series([105575500, 99788400, 76299700], index=['2021-07-08', '2021-07-09', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2]))在上面的代码中,df2 比 df1 多了一列 Volume,少了一列 High。在最终拼接的 DataFrame 中,列为 df1 和 df2 列的并集,不存在的数据用 NaN 填充。因为拼接的方式默认为 outer,所以最终结果的列为 df1 和 df2 列的并集。我们还可以将拼接方式改为 inner,这时候最终结果的列为 df1 和 df2 列的交集。例如:
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Volume": pd.Series([105575500, 99788400, 76299700], index=['2021-07-08', '2021-07-09', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2], join='inner'))在上面的代码中,由于将拼接方式设置成 inner,所以最终结果的列为 df1 和 df2 列的交集。上面的拼接方向都是垂直方向,当然我们还可以通过参数的设置进行水平方向的拼接。例如:
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Volume": pd.Series([105575500, 99788400, 76299700], index=['2021-07-08', '2021-07-09', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2], axis=1))上面的代码中,通过设置参数 axis=1 使得进行水平方向的拼接,当进行水平方向的拼接时,是按照行的索引进行拼接的,由于拼接的方式默认为 outer,所以对于进行拼接的 df1 和 df2,不存在的行对应的数据用 NaN 进行填充。我们也可以把拼接的方式设置成 inner,例如:
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index=['2021-07-01', '2021-07-02', '2021-07-12']),
"Volume": pd.Series([105575500, 99788400, 76299700], index=['2021-07-01', '2021-07-02', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2], axis=1, join='inner'))在上面的例子中,df1 和 df2 索引相同的行为 2021-07-01 和 2021-07-02,所以最终的拼接结果中只包含索引 2021-07-01 和 2021-07-02。
2. merge()
merge() 函数的作用和 SQL 里的 join 操作的作用非常类似,都是根据一些条件将行拼接起来。
2.1 数据库风格的拼接
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2))上面的例子是多对一的连接,df1 有多个被标记为 Alice 和 Bob 的行,在 df2 中,name 列的每个值仅对应一行。在进行拼接的过程中,df1 和 df2 中 name 列的值相同的行被连接在一起,不相同的行不在最终的连接结果中。因为默认情况下,merge 做的是内连接,结果中的键是交集。注意,在上面的例子中,我们并没有指明要用哪个列进行连接。如果没有指定,merge 会将重叠列的列名当做键。不过,最好明确指定,例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name'))如果两个 DataFrame 对象的列名不同,也可以分别进行指定。例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'lname': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'rname': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2, left_on='lname', right_on='rname'))上面的连接方式默认为 inner,此外其他的连接方式还有 left、right 以及 outer。它们的连接规则是:
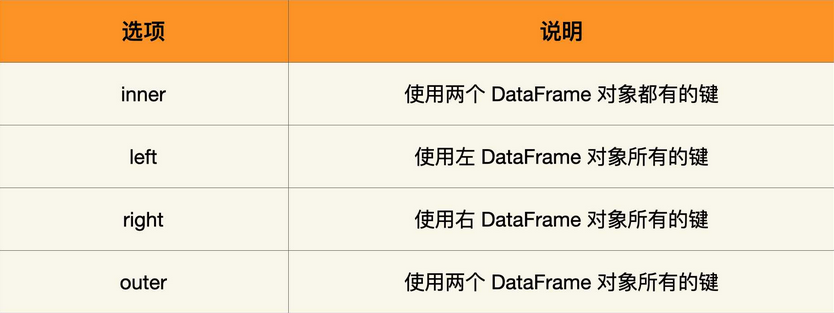
我们以刚才的例子为例,来看看各自的输出结果。
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='left'))左连接以左边的 DataFrame 对象的键为主,右边 DataFrame 对象不存在的键对应的数据用 NaN 填充。
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='right'))右连接以右边的 DataFrame 对象的键为主,左边 DataFrame 对象不存在的键对应的数据用 NaN 填充。
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='outer'))外连接取两个 DataFrame 对象的键的并集,相对并集来说不存在的键对应的值以 NaN 填充。上面讲的是多对一的例子,下面来看下多对多的例子:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'score2': [95, 80, 81, 98, 85]
})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name'))多对多连接产生的是行的笛卡尔积。由于左边的 DataFrame 对象中有 3 个 Bob 行,右边的有 2 个 Bob 行,所以最终结果中就有 6 个 Bob 行。多对多连接同样可以设置连接的方式。例如:
left:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'score2': [95, 80, 81, 98, 85]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='left'))right:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'score2': [95, 80, 81, 98, 85]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='right'))outer:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'score2': [95, 80, 81, 98, 85]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='outer'))如果要根据多个键进行合并,传入一个由列名组成的列表即可,例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'gender': ['Male', 'Male', 'Female', 'Male', 'Female', 'Female', 'Male'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'gender': ['Female', 'Male', 'Female', 'Male', 'Male'],
'score2': [95, 80, 81, 98, 85]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on=['name', 'gender']))当合并后的 DataFrame 对象中有重复列名时,会默认为左边 DataFrame 对象中的列名加上 _x 后缀,为右边 DataFrame 对象中的列名加上 _y 后缀。附加的后缀我们也可以通过参数 suffixes 来设置。例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'gender': ['Male', 'Male', 'Female', 'Male', 'Female', 'Female', 'Male'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'gender': ['Female', 'Male', 'Female', 'Male', 'Male'],
'score2': [95, 80, 81, 98, 85]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', suffixes=('_left', '_right')))2.2基于索引的拼接
有时候,DataFrame 中的连接键位于其索引中。在这种情况下,可以传入 left_index=True 或 right_index=True (或两个都传)以说明索引应该被用作连接键,例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'score2': [96, 82, 97]}, index=['Alice', 'Bob', 'Deniel'])
print(df1)
print(df2)
print(pd.merge(df1, df2, left_on='name', right_index=True))上面的例子中,df1 中用于连接的键为 name,所以指定参数 left_on=name,df2 中用于连接的键位于索引中,所以指定参数 right_index=True。上面的连接默认采用 inner 的方式,当然我们也可以设置其他的连接方式。例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'score2': [96, 82, 97]}, index=['Alice', 'Bob', 'Deniel'])
print(df1)
print(df2)
print(pd.merge(df1, df2, left_on='name', right_index=True, how='outer'))对于层次化索引的数据,事情有点复杂,因为索引的合并默认是多键合并,例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'gender': ['Male', 'Male', 'Female', 'Male', 'Female', 'Female', 'Male'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'score2': [96, 82, 97, 92]},
index=[['Alice', 'Alice', 'Bob', 'Bob'],
['Female', 'Female', 'Male', 'Male']])
print(df1)
print(df2)
print(pd.merge(df1, df2, left_on=['name', 'gender'], right_index=True))上面的连接默认采用 inner 的方式,当然我们也可以设置其他的连接方式。例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'gender': ['Male', 'Male', 'Female', 'Male', 'Female', 'Female', 'Male'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'score2': [96, 82, 97, 92]},
index=[['Alice', 'Alice', 'Bob', 'Bob'],
['Female', 'Female', 'Male', 'Male']])
print(df1)
print(df2)
print(pd.merge(df1, df2, left_on=['name', 'gender'], right_index=True, how='outer'))在进行连接时,双方都使用索引也是可以的。例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'score1': [97, 92, 88, 98, 86, 99, 94]},
index = [['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
['Male', 'Male', 'Female', 'Male', 'Female', 'Female', 'Male']])
df2 = pd.DataFrame({'score2': [96, 82, 97, 92]},
index=[['Alice', 'Alice', 'Bob', 'Bob'],
['Female', 'Female', 'Male', 'Male']])
print(df1)
print(df2)
print(pd.merge(df1, df2, left_index=True, right_index=True))
- 点赞
- 收藏
- 关注作者
评论(0)