如何查看 Series、DataFrame 对象的数据

1. 查看一部分数据
我们可以使用 head() 和 tail() 方法来查看 Series 对象或 DataFrame 对象的一小部分数据,默认查看的元素个数为 5 个,head() 展示头部的 5 个元素,tail() 展示尾部的 5 个元素,也可以自定义展示的元素个数。当 Series 对象或 DataFrame 对象包含的数据较多时,使用 head() 或 tail() 查看数据的结构会非常方便。
1.1 Series 对象
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, -5, 3, 2, np.NaN, 8, 1, -9]))
print(my_series.head())由于没有明确指定展示的元素个数,上面的代码默认输出了 Series 对象头部的 5 个元素。
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, -5, 3, 2, np.NaN, 8, 1, -9]))
print(my_series.head(3))由于指定了展示的元素个数为 3,所以上面的代码输出了 Series 对象头部的 3 个元素。
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, -5, 3, 2, np.NaN, 8, 1, -9]))
print(my_series.tail())由于没有明确指定展示的元素个数,上面的代码默认输出了 Series 对象尾部的 5 个元素。
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, -5, 3, 2, np.NaN, 8, 1, -9]))
print(my_series.tail(3))由于指定了展示的元素个数为 3,所以上面的代码输出了 Series 对象尾部的 3 个元素。
1.2 DataFrame 对象
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, 140, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, 142, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
print(df.head())由于没有明确指定展示的行数,上面的代码默认输出了 DataFrame 对象头部的 5 行元素。
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, 140, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, 142, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
print(df.head(3))由于指定了展示的行数为 3,所以上面的代码输出了 DataFrame 对象头部的 3 行元素。
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, 140, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, 142, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
print(df.tail())由于没有明确指定展示的行数,上面的代码默认输出了 DataFrame 对象尾部的 5 行元素。
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, 140, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, 142, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
print(df.tail(3))由于指定了展示的行数为 3,所以上面的代码输出了 DataFrame 对象尾部的 3 行元素。
2. 查看属性及数据
2.1 属性
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, -5, 3, 2, np.NaN, 8, 1, -9]))
print(my_series.index)
print(my_series.shape)上述代码查看了 Series 对象 my_series 的索引和形状。
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, 140, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, 142, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
print(df.index)
print(df.columns)
print(df.shape)上述代码查看了 DataFrame 对象 df 的行、列索引以及形状。
2.2 数据
在过去,pandas 建议使用 Series.values 或 DataFrame.values 从 Series 对象 或 DataFrame 对象中提取数据。现在,建议避免使用 .values 而改用 .to_numpy(),因为 .values 有一些缺陷。
2.2.1 Series 对象
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, -5, 3, 2, np.NaN, 8, 1, -9]))
print(my_series.to_numpy())
print(type(my_series.to_numpy()))上述代码获取了 Series 对象的数据,类型为 ndarray。
2.2.2 DataFrame 对象
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, 140, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, 142, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
print(df.to_numpy())
print(type(df.to_numpy()))上述代码获取了 DataFrame 对象的数据,类型为 ndarray。
3. 查看统计信息
对于 Series、DataFrame 对象来说,pandas 有许多方法用来计算它们的描述统计。这其中的大多数为聚合类方法,例如:sum()、mean()、cumsum()、cumprod() 等。对于 Series 对象来说,这些方法不需要指定 axis 参数,对于 DataFrame 对象来说,这些方法需要指定 axis 参数,axis 参数的值可以是名字或者数字。当参数的值为 index 或 0 时,表示按列进行计算;当参数的值为 columns 或 1 时,表示按行进行计算。
3.1 Series 对象
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, -5, 3, 2, np.NaN, 8, 1, -9]))
print(my_series.sum())
print(my_series.mean())
print(my_series.cumsum())
print(my_series.cumprod())sum() 函数计算的是所有元素的和(除去 np.NaN)。mean() 函数计算的是所有元素的平均值(除去 np.NaN)。cumsum() 函数计算的是所有元素的累计和(除去 np.NaN)。cumprod() 函数计算的是所有元素的累计积(除去 np.NaN)。当上述函数什么参数都不设置时,在进行计算时,默认是忽略 np.NaN 值的。如果不想忽略 np.NaN 的值,可以设置 skipna 参数。例如:
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, -5, 3, 2, np.NaN, 8, 1, -9]))
print(my_series.sum(skipna=False))
print(my_series.mean(skipna=False))
print(my_series.cumsum(skipna=False))
print(my_series.cumprod(skipna=False))上述代码在计算时,便没有忽略 np.NaN。
3.2 DataFrame 对象
import numpy as np
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, np.NaN, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, np.NaN, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
# 按列进行计算,忽略 np.NaN
print(df.sum(axis=0))
print(df.sum(axis='index'))
print(df.mean(axis=0))
print(df.mean(axis='index'))
print(df.cumsum(axis=0))
print(df.cumsum(axis='index'))
print(df.cumprod(axis=0))
print(df.cumprod(axis='index'))
# 按行进行计算,忽略 np.NaN
print(df.sum(axis=1))
print(df.sum(axis='columns'))
print(df.mean(axis=1))
print(df.mean(axis='columns'))
print(df.cumsum(axis=1))
print(df.cumsum(axis='columns'))
print(df.cumprod(axis=1))
print(df.cumprod(axis='columns'))上述代码分别按行和列进行了 sum()、mean()、cumsum() 和 cumprod() 运算。在进行计算时,忽略了 np.NaN。如果不想忽略 np.NaN 的值,可以设置 skipna 参数。例如:
import numpy as np
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, np.NaN, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, np.NaN, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
# 按列进行计算,忽略 np.NaN
print(df.sum(axis=0, skipna=False))
print(df.sum(axis='index', skipna=False))
print(df.mean(axis=0, skipna=False))
print(df.mean(axis='index', skipna=False))
print(df.cumsum(axis=0, skipna=False))
print(df.cumsum(axis='index', skipna=False))
print(df.cumprod(axis=0, skipna=False))
print(df.cumprod(axis='index', skipna=False))
# 按行进行计算,忽略 np.NaN
print(df.sum(axis=1, skipna=False))
print(df.sum(axis='columns', skipna=False))
print(df.mean(axis=1, skipna=False))
print(df.mean(axis='columns', skipna=False))
print(df.cumsum(axis=1, skipna=False))
print(df.cumsum(axis='columns', skipna=False))
print(df.cumprod(axis=1, skipna=False))
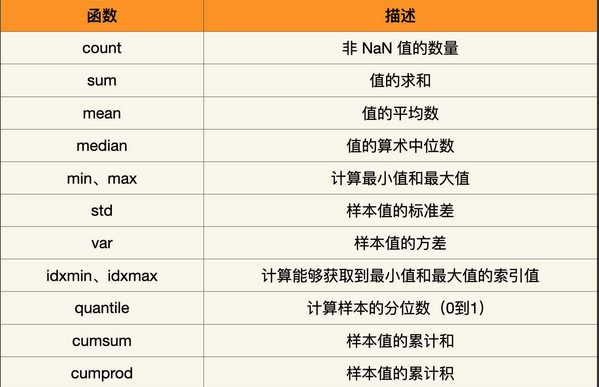
print(df.cumprod(axis='columns', skipna=False))除了上面的函数外,还有一些函数,见下表:
4. describe() 函数
pandas 还有一个方便的函数 describe(),可以一次产生多个汇总统计,在进行计算时,排除了 np.NaN。例如:
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, -5, 3, 2, np.NaN, 8, 1, -9]))
print(my_series.describe())上面代码的输出结果中,count 表示元素的个数;mean 表示元素的平均值;std 表示元素的标准差;min 表示元素的最小值;25% 表示元素的第一四分位数;50% 表示元素的第二四分位数;75% 表示元素的第三四分位数;max 表示元素的最大值。当把 describe() 函数用于 DataFrame 对象时,是对每一列进行汇总统计。例如:
import numpy as np
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, np.NaN, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, np.NaN, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
print(df.describe())上述代码输出了 DataFrame 对象每列的统计信息。当 describe() 没有参数设置时,默认输出了第一四分位数、第二四分位数、第三四分位数。我们还可以通过设置参数 percentiles,来指定输出哪些百分位数。例如:
import numpy as np
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, np.NaN, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, np.NaN, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
print(df.describe(percentiles=[0.05, 0.25, 0.75, 0.95]))在 percentiles 里没有指定 0.5,因为中位数是默认包含的。上面 Series 对象中元素的类型为数字,当元素的类型为非数字时,describe() 函数会给出每个元素的次数以及所有元素中的最高次数。例如:
import numpy as np
import pandas as pd
s = pd.Series(["a", "a", "b", "b", "a", "a", np.NaN, "c", "d", "a"])
print(s.describe())上述代码的输出结果中,count 表示元素的个数;unique 表示不同元素的个数;top 表示出现次数最高的元素;freq 表示出现次数最高的元素的次数。当 DataFrame 对象中既有数字的列也有非数字的列,在不设置参数的情况下,describe() 会只对数字的列进行统计计算,例如:
import numpy as np
import pandas as pd
frame = pd.DataFrame({"a": ["Yes", "Yes", "No", "No"], "b": range(4)})
print(frame.describe())上面代码的输出结果只对 b 列进行了统计计算。当然,对哪些类型的列进行计算,我们也可以用参数进行控制。例如:
import numpy as np
import pandas as pd
frame = pd.DataFrame({"a": ["Yes", "Yes", "No", "No"], "b": range(4)})
print(frame.describe(include=['object']))当 include 参数的值为 object 时,只计算非数字列的统计信息。
import numpy as np
import pandas as pd
frame = pd.DataFrame({"a": ["Yes", "Yes", "No", "No"], "b": range(4)})
print(frame.describe(include=['number']))当 include 参数的值为 number 时,只计算数字列的统计信息。
import numpy as np
import pandas as pd
frame = pd.DataFrame({"a": ["Yes", "Yes", "No", "No"], "b": range(4)})
print(frame.describe(include='all'))当 include 参数的值为 all 时,计算所有列的统计信息,数字列按照数字列的规则,非数字列按照非数字列的规则。
5. 排序
5.1 按索引排序
根据条件对数据集排序是很常见的一种操作,要对行或列索引进行排序(按字典顺序),可使用 sort_index 方法,它将返回一个已排序的新对象,例如:
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, -5, 3, 2]), index=["b", "e", "c", "d", "a", "f"])
# 排序前
print(my_series)
# 排序后
print(my_series.sort_index())上面代码中,调用 sort_index() 之后,索引按照字典序进行了升序排序。我们也可以按照降序进行排序,只需要传入参数 ascending=False,例如:
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, -5, 3, 2]), index=["b", "e", "c", "d", "a", "f"])
# 排序前
print(my_series)
# 排序后
print(my_series.sort_index(ascending=False))对于 DataFrame 对象来说,可以根据任意一个轴上的索引进行排序,例如:
import numpy as np
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, np.NaN, 142, 144], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, np.NaN, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
# 排序前
print(df)
# 排序后
print(df.sort_index())上面代码中,对 DataFrame 对象按照行索引进行了升序排序。当不传入参数时,默认按照行索引进行升序排序,我们也可以通过指定参数来按照列索引进行排序。例如:
import numpy as np
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, np.NaN, 142, 144], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, np.NaN, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
# 排序前
print(df)
# 排序后
print(df.sort_index(axis=1))上面代码中,按照列索引进行了升序排序。上面都是按照升序进行排序,和 Series 对象一样,我们可以通过指定参数,使得按照降序进行排序。例如:
import numpy as np
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, np.NaN, 142, 144], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, np.NaN, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
# 排序前
print(df)
# 排序后
# 按列索引进行降序排序
print(df.sort_index(axis=1, ascending=False))
# 按行索引进行降序排序
print(df.sort_index(ascending=False))5.2 按值进行排序
上面是按索引进行排序,如果要按值进行排序,可以使用 sort_values 方法。例如:
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, np.NaN, 3, 2]), index=["b", "e", "c", "d", "a", "f"])
# 排序前
print(my_series)
# 排序后
print(my_series.sort_values())上面的代码按照值进行了升序排序,在排序时,任何缺失值默认都会被放到末尾。同样地,我们可以通过指定排序的顺序,使得值按照降序进行排序,例如:
import numpy as np
import pandas as pd
my_series = pd.Series(np.array([4, -7, 6, np.NaN, 3, 2]), index=["b", "e", "c", "d", "a", "f"])
# 排序前
print(my_series)
# 排序后
print(my_series.sort_values(ascending=False))上面的代码按照值进行了降序排序。
当对一个 DataFrame 对象进行排序时,你可能希望根据一个或多个列中的值进行排序。将一个或多个列的名字传递给 sort_values 的 by 选项即可达到该目的。例如:
import numpy as np
import pandas as pd
d = {
"Open": pd.Series([136, 137, 140, 143, 141, 142, 146], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([137, 140, 143, 144, 144, 145, 146], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([135, 137, 140, 142, 140, 142, 144], index=['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([137, 139, np.NaN, 144, 143, 145, 144], index = ['2021-07-01', '2021-07-06', '2021-07-02', '2021-07-07', '2021-07-08', '2021-07-09', '2021-07-12'])
}
df = pd.DataFrame(d)
# 排序前
print(df)
# 按open列的值进行排序
print(df.sort_values(by=['Open']))
# 按open列和High列进行排序
print(df.sort_values(by=['High', 'Low']))
- 点赞
- 收藏
- 关注作者
评论(0)